在用机器学习解决问题的一般流程中,有一个重要的步骤----数据预处理,参考下图,
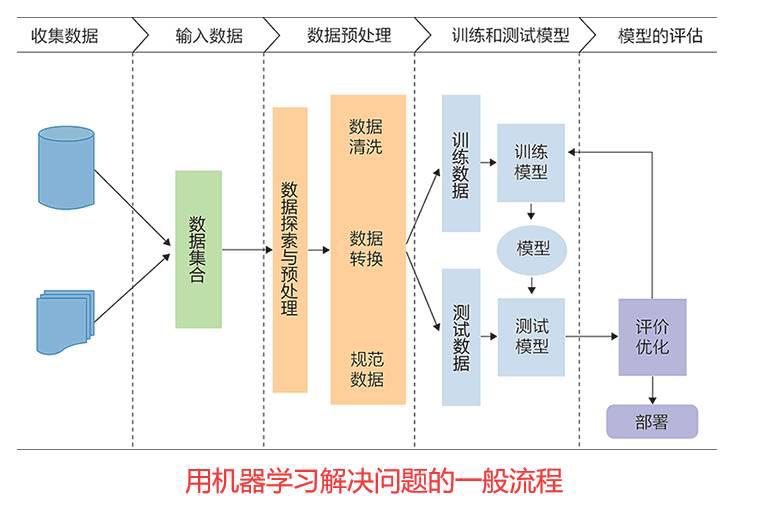
数据预处理 包括数据清洗,数据转换和数据规范化,这个步骤为训练的模型提供规范化的数据。其中数据规范化是一个必不可少的操作,因为在一般情况下,原始数据的各个特征的值并不在一个统一的范围内,这样数据之间就没有可比性,需要在统一的维度来衡量。
本文对机器学习中的数据规范化相关内容做一个总结,内容概要如下,
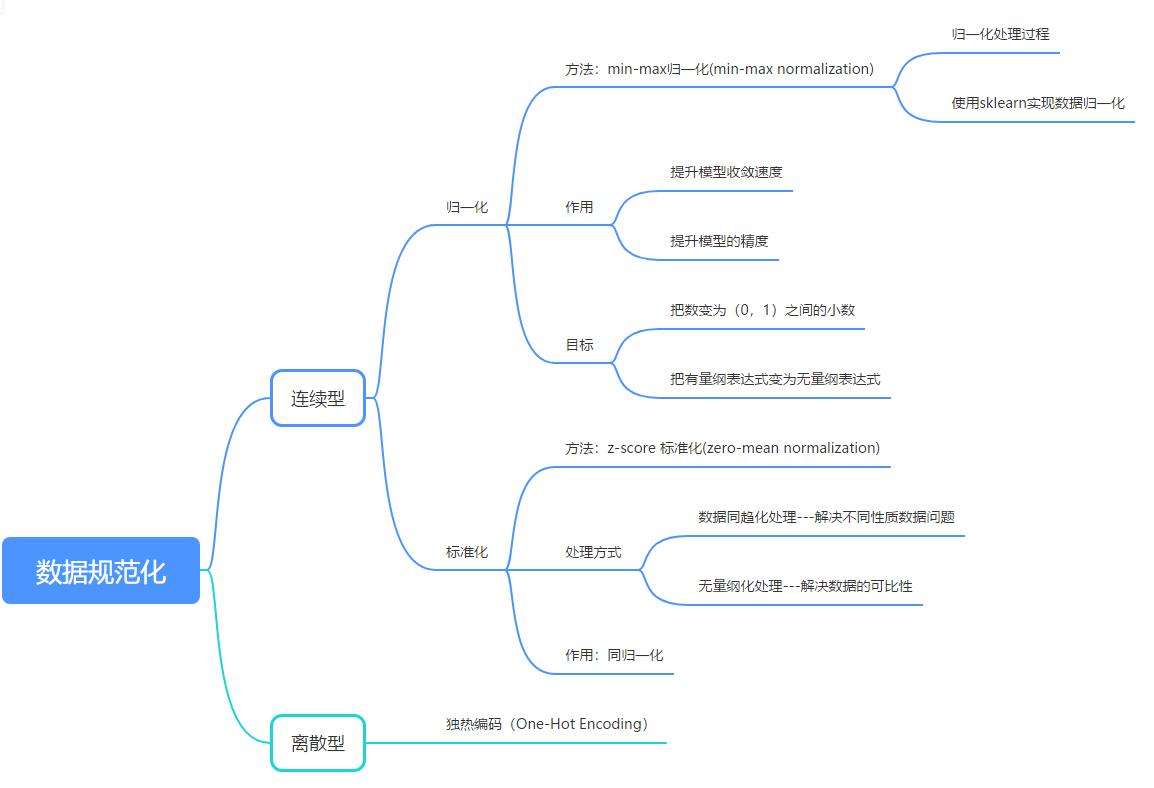
连续型特征归一化的常用方法主要包括归一化和标准化;离散型特征归一化的常用方法是独热编码(One-Hot Encoding)。本文围绕数据归一化,标准化和独热编码这3种主要的数据规范化操作来展开。
1.归一化
数据归一化的方法不止一种,其中最典型的数据的归一化处理方式是将数据统一映射到[0,1]区间上。
1.1 min-max归一化
min-max归一化就是获取原始数据的最大值和最小值,然后把原始值线性变换到 [0,1] 范围之内,变换公式为:

其中:
x 是当前要变换的原始值;
min 是当前特征中的最小值,在同一特征之内,最小值是一样的,而不同特征之间,最小值是不一样的。
max 是当前特征中的最大值,在同一特征之内,最大值是一样的,而不同特征之间,最大值是不一样的。
x' 是变换完之后的新值。
1.2 通过sklearn实现min-max归一化
库:sklearn.preprocessing
API 函数:sklearn.prepocessing.MinMaxScaler
方法:
MinMaxScaler(feature_range=(0,1)...)
每个特征缩放到给定范围(默认[0,1])
MinMaxScalar.fit_transform(x)
x:numpy array格式的数据(n_samples,n_features)
返回值:转换后的形状相同的array
步骤:
- 实例化 MinMaxScalar
- 通过 fit_transform 转换
案例:
# 特征预处理--数据
data = np.array([[5000,2,10,40],[6000,3,15,45],[50000,5,15,40]])
#-----换个方式看这个矩阵数据----#
array([[ 5000, 2, 10, 40],
[ 6000, 3, 15, 45],
[50000, 5, 15, 40]])
在实际的项目中你可能会注意到某些特征比其他特征拥有高得多的跨度值。举个例子,将一个人的 收入和他的 年龄进行比较,通过缩放可以避免某些特征比其他特征获得大小非常悬殊的权重值。即使得某一个特征 不会对结果造成过大的影响。比如这里的第一列,较其他列,数值明显偏大,这种情况就需要做规范化处理。
代码实现,
# 导入接口
from sklearn.preprocessing import MinMaxScaler
# 实例化
mm = MinMaxScaler() # 默认0-1之间
# 对数据进行转换-归一化,操作的是每个特征(列)
res = mm.fit_transform(data)
res

还可以指定范围缩减 :
#设置归一化范围为[0,3]
mm = MinMaxScaler(feature_range=(0,3))
res = mm.fit_transform(data)
res

1.2 归一化的作用
1)提升模型的收敛速度
如下图,x1的取值为0-2000,而x2的取值为1-5,假如只有这两个特征,对其进行优化时,会得到一个窄长的椭圆形,导致在梯度下降时,梯度的方向为垂直等高线的方向而走之字形路线,这样会使迭代很慢,相比之下,右图的迭代就会很快(理解:也就是步长走多走少方向总是对的,不会走偏)
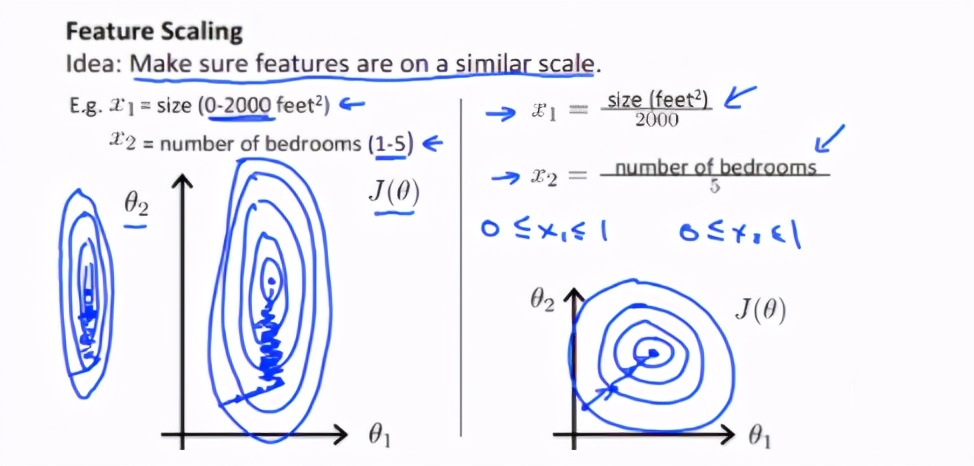
2)提升模型的精度
归一化的另一好处是提高精度,这在涉及到一些距离计算的算法时效果显著,比如算法要计算欧氏距离,上图中x2的取值范围比较小,涉及到距离计算时其对结果的影响远比x1带来的小,所以这就会造成精度的损失。所以归一化很有必要,他可以让各个特征对结果做出的贡献相同。
在多指标评价体系中,由于各评价指标的性质不同,通常具有不同的量纲和数量级。当各指标间的水平相差很大时,如果直接用原始指标值进行分析,就会突出数值较高的指标在综合分析中的作用,相对削弱数值水平较低指标的作用。因此,为了保证结果的可靠性,需要对原始指标数据进行标准化处理。
在数据分析之前,我们通常需要先将数据标准化(normalization),利用标准化后的数据进行数据分析。数据标准化也就是统计数据的指数化。数据标准化处理主要包括数据同趋化处理和无量纲化处理两个方面。数据同趋化处理主要解决不同性质数据问题,对不同性质指标直接加总不能正确反映不同作用力的综合结果,须先考虑改变逆指标数据性质,使所有指标对测评方案的作用力同趋化,再加总才能得出正确结果。数据无量纲化处理主要解决数据的可比性。经过上述标准化处理,原始数据均转换为无量纲化指标测评值,即各指标值都处于同一个数量级别上,可以进行综合测评分析。
从经验上说,归一化是让不同维度之间的特征在数值上有一定比较性,可以大大提高分类器的准确性。
1.3归一化的目标
1)把数变为(0,1)之间的小数
主要是为了数据处理方便提出来的,把数据映射到0~1范围之内处理,更加便捷快速,应该归到数字信号处理范畴之内。
2)把有量纲表达式变为无量纲表达式
归一化是一种简化计算的方式,即将有量纲的表达式,经过变换,化为无量纲的表达式,成为纯量。
1.4归一化的缺点
在特定的场景下大值小值是变化的,另外,大值与小值非常容易受异常点的影响,所以这种方法的鲁棒性(稳定性)较差,只适合传统精确小数据场景。所以一般不会使用,广泛使用的是标准化。
2.标准化
数据标准化的方法也不止一种,这里介绍一下最常用的z-score 标准化。z-score 标准化是基于正态分布的,该方法假设数据呈现标准正态分布。正态分布也叫高斯分布,是连续随机变量概率分布的一种,它的数学公式是:

其中,u 为均值(平均数),σ 为标准差。均值和标准差是正态分布的关键参数,它们会决定分布的具体形态。
特点 : 通过对原始数据进行变换把数据变换到均值为0, 标准差为1的范围内。
z-score 标准化
z-score 标准化利用正态分布的特点,计算一个给定分数距离平均数有多少个标准差。它的转换公式如下:
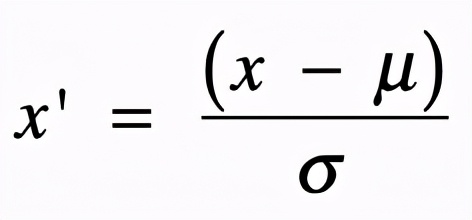
其中 x 为原始值,u 为均值,σ 为标准差,x’ 是变换后的值。经过 z-score 标准化后,高于平均数的分数会得到一个正的标准分,而低于平均数的分数会得到一个负的标准分数。
标准化较归一化的优势: 对于归一化,如果出现异常点,影响了大值和小值,那么结果显然会发生改变;但对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从 而方差改变较小。在已有样本足够多的情况下比较稳定,适合现代嘈杂的大数据场景。
1.2 通过sklearn实现z-score 标准化
库:sklearn.preprocessing
API 函数:sklearn.preprocessing.StandarScaler
方法:
StandardScaler()
处理之后每列所有数据都聚集在均值为0标准差为1附近
StandarScaler.fit_transform(x)
x:numpy array格式的数据(n_samples,n_features)
返回值:转换后的形状相同的array
StandarScaler.mean_
原始数据中每列的平均值中位数
StandarScaler.std_
原始主句每列特征的方差
步骤:
- 实例化 StandarScaler
- 通过 fit_transform 转换
案例:
import numpy as np
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() # 实例化
data = np.array([[5000,2,10,40],[6000,3,15,45],[50000,5,15,40]]) # 数据
res = ss.fit_transform(data)
print(res)

3.独热编码
One-Hot编码,又称为一位有效编码,主要是采用N位状态寄存器来对N个状态进行编码,每个状态都由它独立的寄存器位,并且在任意时候只有一位有效。
One-Hot编码是分类变量作为二进制向量地表示。这首先要求将分类值映射到整数值。然后,每个整数值被表示为二进制向量,除了整数的索引之外,它都是零值,它被标记为1。
为什么使用one-hot编码来处理离散型特征?
在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
而我们使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。
将离散型特征使用one-hot编码,确实会让特征之间的距离计算更加合理。
比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,其表示分别是x_1 = (1), x_2 = (2), x_3 = (3)。两个工作之间的距离是,(x_1, x_2) = 1, d(x_2, x_3) = 1, d(x_1, x_3) = 2。那么x_1和x_3工作之间就越不相似吗?显然这样的表示,计算出来的特征的距离是不合理。那如果使用one-hot编码,则得到x_1 = (1, 0, 0), x_2 = (0, 1, 0), x_3 = (0, 0, 1),那么两个工作之间的距离就都是sqrt(2).即每两个工作之间的距离是一样的,显得更合理。
实例:
性别特征:["男","女"],按照N位状态寄存器来对N个状态进行编码的原理,咱们处理后应该是这样的(这里只有两个特征,所以N=2):
- 男 => 10
- 女 => 01
祖国特征:["中国","美国,"法国"](这里N=3):
- 中国 => 100
- 美国 => 010
- 法国 => 001
运动特征:["足球","篮球","羽毛球","乒乓球"](这里N=4):
- 足球 => 1000
- 篮球 => 0100
- 羽毛球 => 0010
- 乒乓球 => 0001
所以,当一个样本为["男","中国","乒乓球"]的时候,完整的特征数字化的结果为:
[1,0,1,0,0,0,0,0,1]
下图可能会更好理解:

总结
本文从概念,作用以及sklearn的实现步骤和方法等方面详细介绍了机器学习中比较常用的3种数据规范化方法(归一化,标准化和独热编码3种方式)。希望有所帮助!