
由最强大的科技公司积累的图像和视频的视觉数据集一直是一个竞争优势,是一个护城河,使机器学习的进步离不开许多人。这种优势将被合成数据的出现*翻推**。
世界上最有价值的科技公司,如谷歌、脸谱网、Amazon和百度等,都在应用计算机视觉和人工智能来训练他们的电脑。他们从消费者那里获取大量的图像、视频和其他视觉数据的视觉数据集。
这些数据集一直是主要技术公司的竞争优势,与许多机器学习的进步和允许计算机和算法更快学习的过程保持联系。
现在,这种优势正在被任何人创造和利用合成数据来训练计算机的能力所破坏,在许多用例中,包括零售、机器人、自主车辆、商业等等。
合成数据是模拟真实数据的计算机生成数据;换句话说,由计算机创建的数据,而不是人类。软件算法可以被设计成创建逼真的模拟或“合成”数据。
然后,这些合成数据有助于教计算机如何对某些情况或标准作出反应,取代真实世界捕获的训练数据。真实数据或合成数据的最重要的方面之一是要有准确的标签,以便计算机能够翻译视觉数据以产生意义。
自2012以来,我们在LDV Capital一直投资于利用计算机视觉、机器学习和人工智能来分析任何商业领域的视觉数据的深层技术团队,如医疗、机器人、物流、地图、交通、制造业等等。我们遇到的许多初创企业都有“冷启动”问题,没有足够的质量标记数据来训练他们的计算机算法。系统不能为用户或其尚未收集足够信息的项目画任何推论。
创业公司可以收集他们自己的上下文相关数据或合作伙伴收集相关数据,如零售商的数据,人类购物行为或医院的医疗数据。许多早期的初创公司正在解决他们的冷启动问题,通过创建数据模拟器,以产生上下文相关的数据与质量标签,以训练他们的算法。
大型科技公司收集数据并没有同样的挑战,它们以指数的方式扩展其主动性,以收集更多独特的和上下文相关的数据。
康奈尔技术教授Serge Belongie,他在计算机视觉领域做了25多年的研究,他说:
在过去,我们的计算机视觉领域谨慎地关注合成数据的使用,因为它在外观上太假了。尽管免费获得完美的地面实况注解有明显的好处,但我们担心的是,我们会训练一个在模拟中发挥巨大作用的系统,但在野外却会惨败。现在游戏发生了变化:模拟与现实的差距正在迅速消失。在最低限度,我们可以预先训练非常深的卷积神经网络在近逼真的图像和精细调整它仔细选择的真实图像。
AIFI是一个早期启动,建立一个计算机视觉和人工智能平台,以提供一个更有效的免签解决方案,无论是妈妈和流行的便利店和主要零售商。他们正在建立一个与亚马逊网站类似的免税商店解决方案。

亚马逊公司的员工在西雅图的亚马逊商店购物。摄影:米可侃锷/彭博通过GATTY图片
作为一个初创公司,AiFi有一个典型的冷启动挑战,缺乏来自现实世界的视觉数据,开始训练他们的计算机,而亚马逊可能收集真实的数据来训练算法,而Amazon GO则处于隐形模式。

化身有助于训练AIFI购物算法。全自动电抗器
AiFi创造合成数据的解决方案也成为它们的可防御和差异化的技术优势之一。通过AiFi的系统,购物者将能够进入零售商店,在不必使用现金、卡片或扫描条形码的情况下拾取物品。
这些智能系统将需要连续追踪商店中的数百或数千消费者,并在整个购物会话中识别或“重新识别”它们。
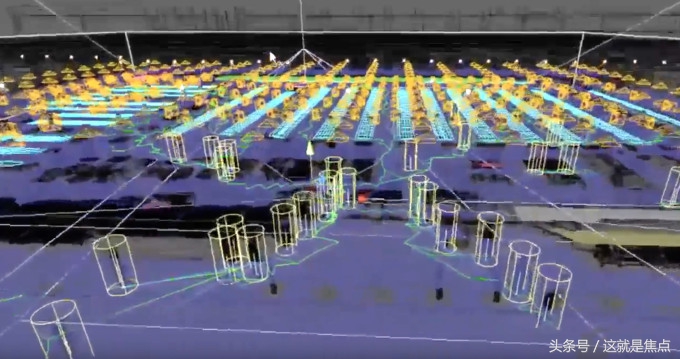
而据大型模拟与合成数据。©aifi
嬴政,公司的创始人和首席科学官,而据此前工作,苹果和谷歌。她说,
大片的冰的世界,和我没described A市的小样品的实时图像和标签。不值得一提,采高质量标签的两个小时的冰和消费扩张,有时infeasible鸭。与合成数据,我们可以捕捉的一个小,但全世界相关方面的完美的零售。在我们的案例中,我们创建了大尺度的模拟运行和高质量的图像和像素完美的标签,并使用他们两个深successfully列车我们的学习模式。而据这两个enables上无创检测解决方案,大规模的尺度。
机器人的另一个部门leveraging冰合成两列数据对各种活动的机器人在工厂和仓储为基础,造福社会。
杰克是一个科学家,托宾的研究来openai,人工智能研究的一个非营利公司的目标是促进和发展友好的AI在这样一种方式,两个效益为人类作为一个整体。托宾冰方,一个团队做建筑,机器人学。他们会说“simulated训练吗?deployed数据和在一个物理的机器人,它可以amazingly,现在,一个新的学习任务后,看到一个动作完成。
他们deployed开发的一个新的算法称为一次模仿学习,allowing(人的沟通如何做一个新任务的城市,它在虚拟现实的表演。给定一个单一的演示中,机器人能够在冰上练习相同的任务从四个出发点,然后继续的任务。

开放式人工智能
他们的目标是在模拟中学习行为,然后将这些学习转移到现实世界。这个假设是为了观察机器人是否能从模拟数据中精确地做事情。他们从100%个模拟数据开始,并认为它不会像使用真实数据那样训练计算机。然而,训练机器人任务的模拟数据比他们预期的要好得多。
托宾说:
创建一个精确的合成数据模拟器真的很难。在一个训练有素的综合数据模型与真实世界数据之间的准确性是3-10倍的因素。还有差距。对于许多任务,性能很好,但是为了极端精度,它不会飞。
Osaro是一家开发基于深度强化学习技术的工业机器人自动化产品的人工智能公司。奥萨罗联合创始人兼首席执行官Derik Pridmore说:“毫无疑问,模拟授权的初创公司。这是工具箱中的另一个工具。我们使用模拟数据,用于快速原型和测试新模型以及在现实世界中使用的训练模型。
许多大型科技公司、汽车制造商和初创公司都在努力实现自主汽车革命。开发人员已经认识到,一天中没有足够的时间来收集足够的真实数据来驱动汽车如何驾驶自己。
一些人正在使用的一种解决方案是来自像侠盗猎车手这样的电子游戏的合成数据,不幸的是,有人说游戏的母公司RokStAR不喜欢无人驾驶汽车从游戏中学习。

GTA V街(左)及其通过捕获数据重建(右)。达姆施塔特科技大学英特尔实验室
五月移动是一个启动建设自驾车微运输服务。他们的首席执行官和创始人Edwin Olson说:
我们综合数据的使用之一是评估我们的系统的性能和安全性。然而,我们不相信任何合理的测试量(真实的或模拟的)足以证明自主车辆的安全性。功能安全起着重要的作用。
仿真的灵活性和通用性使得在这些高度可变的条件下对自主车辆进行训练和测试变得特别有价值和安全得多。模拟数据也可以更容易地标记,因为它是由计算机创建的,因此节省了大量的时间。
Jan Erik Solem是MaPrime*的首席执行官和联合创始人,帮助为智能城市、地理空间服务和汽车创造更好的地图。据索利姆说,
拥有一个数据库和了解世界各地的位置将成为仿真引擎越来越重要的组成部分。随着训练算法的精度的提高,用于仿真的数据的细节和多样性的水平越来越重要。
神经网络正在为深度学习应用构建分布式综合数据平台。他们的首席执行官Yashar Behzadi说:
迄今为止,主要平台公司利用数据壕沟来维持其竞争优势。合成数据是一个主要的干扰因素,因为它显著地降低了开发的成本和速度,允许小型敏捷团队竞争和获胜。
初创企业与固有数据优势竞争的挑战和机遇是利用最佳标签的最佳视觉数据来准确地为不同的使用情况训练计算机。模拟数据将使大型科技公司和初创公司之间的竞争更加激烈。随着时间的推移,大公司也可能会创造综合数据来增加他们的真实数据,总有一天这会再次改变竞争环境。每年5月在纽约举行的LDV视觉峰会上的许多发言者将启发我们如何使用模拟数据来训练算法来解决商业问题,并帮助计算机更接近一般人工智能。
Mapillary是一家LDV资本投资公司。
关注这就是焦点,谢谢,不得转载