引用
Chen S C, Shyu M L, Chen M, et al. A decision tree-based multimodal data mining framework for soccer goal detection[C]//2004 IEEE International Conference on Multimedia and Expo (ICME)(IEEE Cat. No. 04TH8763). IEEE, 2004, 1: 265-268.
摘要
本文提出了一种新的多媒体数据挖掘框架,该方法通过结合多模态分析和决策树逻辑来提取足球视频中的足球进球事件,提取的事件可用于索引足球视频。我们首先采用一种先进的视频镜头检测方法来产生镜头边界和一些重要的视觉特征;然后为每个镜头以不同的粒度提取视觉/音频特征,通过预过滤步骤对丰富的多模式功能集进行过滤,以清除噪声并减少无关数据。决策树模型建立在清理的数据集上,并用于对射门进行分类。最后,实验结果证明了本系统的足球目标提取框架的有效性。
1 介绍
近年来,在体育视频数据,尤其是足球视频中挖掘信息已成为一个活跃的研究主题。对于足球视频分析和事件识别,大多数现有工作都是基于单峰方法。不难看出,在足球目标检测应用领域中,不同的模式有不同的贡献。随着多模态方法显示出其希望,它还提出了如何处理大量多模态特征中包含的丰富语义信息的问题。在现有研究中,提出了一种使用隐马尔可夫模型检测和识别足球亮点的数据挖掘方法。但是,它无法识别目标事件,并且存在处理长视频序列的问题。
长期以来,数据挖掘技术一直被用来从大型数据集中发现有趣的模式。在本文中,我们提出了一种基于决策树的多模态数据挖掘框架,用于足球目标检测。 用于数据挖掘的训练数据是为每个视频镜头提取的多模态特征(视觉和音频)。它是基于镜头的,因为视频镜头是视频内容分析的基本索引单位。此外,我们采用了先进的视频镜头检测方法,其优点是在镜头检测期间会产生一些重要的视觉特征和中层特征(例如,对象信息)。 然后,还提出了一种无监督且鲁棒的草皮区域检测方法,其工作量非常有限,这使我们的框架与大多数其他现有方法区分开来。然而,由于阳性样本(目标镜头)中的百分比很小(例如 1%),而阴性样本(非目标镜头)数量很大,因此在我们的数据预过滤步骤中已使用了利用视觉和音频线索的领域知识 清理原始特征数据集,以便为数据挖掘组件提供合理的输入训练数据集。据我们所知,几乎没有任何工作可以解决这个问题。最后,我们测试了由数据挖掘过程生成的决策树模型,并通过使用大量不同风格的,由不同广播公司制作的长足球视频序列来评估整体性能。根据我们的实验,结果的查全率和查准率均达到 92.3%,这证明了集成数据挖掘和多模态处理的强大功能。
2 框架架构
本文的系统的体系结构如图 1 所示。从该图可以看出,所提出的框架包括以下三个主要组件:
视频解析:通过使用视频镜头检测子组件来解析原始足球视频序列。它不仅可以检测视频镜头边界,还可以在镜头检测过程中产生一些重要的视觉特征。 将检测到的镜头边界传递到特征提取,然后为每个镜头提取完整的多峰特征(视觉和音频)。
数据预过滤:由于目标射门与非目标射门的比率非常小(例如 1 个目标射门),因此使用诸如视觉/音频线索之类的领域知识来消除噪声数据并减少原始功能集中的无关数据 100 张照片中)。通过数据预过滤,可以将阳性样品与阴性样品的比例提高到 1:20。
数据挖掘:以“清理过的”特征数据作为训练数据,并建立适合足球目标检测的决策树模型。
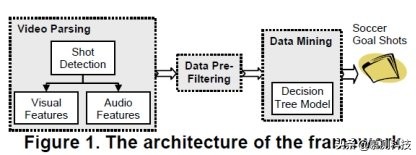
图 1 框架架构
2.1 视频解析
2.1.1 视频镜头检测
视频镜头检测是视频解析的第一步,检测到的镜头边界是视频特征提取的基本单位。在这项研究中,我们通过使用包括像素级比较,直方图比较和分割图技术(如图 2 所示)的多重过滤体系结构,改进了我们以前的工作。前两个滤波器在减少误报和误报的数量上可以相互补偿。此外,由于对象分割和跟踪技术对亮度变化和对象运动的敏感度要低得多,因此它们被用作此多滤镜体系结构中的最后一个滤镜,以帮助确定实际的镜头边界。该方法的优点是:1)它具有高精度(> 92%)和召回率(> 98%)。根据我们在 1000 多个测试镜头中的实验获得的总体性能。 2)在镜头检测过程中,它可以为每个镜头生成一组重要的视觉特征。因此,可以大大减轻提取视觉特征的计算。
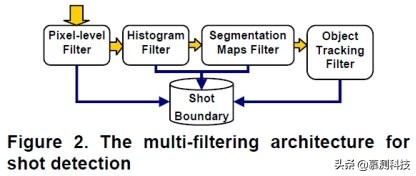
图 2 镜头检测的多重过滤架构
2.1.2 视觉特征提取
除了镜头边界之外,视频镜头检测过程还生成与每个视频镜头相关联的丰富视觉特征集。在这些视觉特征中,pixelchange 表示镜头中各帧之间变化的像素的平均百分比,由第一个滤镜(像素级滤镜)输出。特征 histochange 指示镜头内各帧之间的直方图差异的平均值,并由第二个过滤器(直方图过滤器)输出。这两个全局功能都是相机运动和物体运动的重要指示。其他中级特征,例如背景像素的均值(backmean)和方差(backvar)可以通过分段过滤器获得。如图 3(c)-(d)所示,通过对象分割来检测背景区域(黑色)和前景区域(灰色)。在全局视图中(图 3(a)和(c)),倾向于将草皮区域作为背景,而在特写镜头中(图 3(b)和(d)),背景非常复杂。根据我们的观察,全局视图镜头(包括目标镜头)中存在大量草地区域,而中景或特写镜头中几乎没有草地区域或几乎没有草地区域 镜头(包括进球后的欢呼镜头),这意味着视频镜头中的平均草地面积百分比(grass_ratio)是对镜头类型(全局,近摄等)进行分类的重要指示。

图 3 (a)射门(整体视野)的样本框;(b)在(a)的射门之后,欢呼镜头中的样本框;(c)-(d)(a)和(b)的对象分割结果。
我们观察到,全局拍摄中的草皮区域在颜色和纹理方面都比较平滑。因此,backvar 小于阈值的值将指示可能的草丛面积。然后,我们将所有可能的草地区域的 backmean 值分组到一个候选池中,通过剔除那些镜头太短和 backmean 值超出平均 backmean 合理范围的镜头来滤除异常值,并取平均值剩下的值作为草检测器。还开发了一种强大的方法来处理更复杂的情况,当全局镜头和近摄镜头之间的草色不同时,这些镜头是由相机的拍摄比例和闪电条件引起的。在这种情况下,我们选择候选池中值的直方图峰作为草检测器。应当指出的是,这种草皮区域检测方法是无监督的,并且通过在每个视频序列内通过无监督学习来学习草木值,这对于不同类型的视频是不变的。
2.1.3 音频特征提取
在我们的框架中考虑了时域和频域音频功能。由于音轨的语义含义可以由相对较长时间段的音频特征更好地表示,因此我们还将探讨剪辑级和镜头级音频特征。在这项研究中,我们定义了一个音频剪辑,其固定长度为一秒,通常包含连续的音频帧序列。
通用音频功能分为三组:音量功能(音量),能量功能(能量)和频谱通量功能(sf)。 对于每个通用音频功能,将处理音频文件以获得剪辑级别和镜头级别的音频功能。音频数据以 16,000 HZ 的采样率进行采样。音频帧包含 512 个样本,在 16,000 HZ 的采样率下持续 32ms。在每个剪辑内,相邻帧彼此重叠 128 个样本。 为了更准确地对能量属性进行建模,本研究中还使用了四个能量子带。 在我们的框架中,总共使用了 10 个音频功能(1 个音量功能,5 个能量功能和 4 个频谱通量功能)。
2.2 数据预过滤
由于本研究中的数据量通常很大并且目标射门与非目标射门的比率小于 1:100,因此,一种有效的数据预过滤方法具有以下三个主要方面提出了足球进球事件的观察规则。
规则 1:作为候选目标射击,其音轨的最后三秒(或更少)和其下一击的前三秒(或更少)都应包含至少一个令人兴奋的点。
规则 2:射门得分的草率应大于 40%。
规则 3:在接连射门之后的两次连续射门中,至少有一个射门应该属于特写镜头。
第一条规则来自观察和先验知识,即评论员和观众在射门结束时会感到兴奋。 此外,与其他稀疏的激发声或噪声事件不同,这种刺激通常会持续到下一个击球。 此规则删除了一些噪声数据,因为尽管通常噪声数据量很大,但不会持续很长时间。规则 2 和 3 基于以下观察结果:目标射门属于高草比率的全局射门,并且总是紧随其后的是特写镜头,包括切角球和其他与比赛无关的镜头。
我们的实验表明,通过在我们提出的数据预过滤方法中应用这些规则,可以减少 81%的视频镜头。
2.3 使用决策树挖掘目标镜头
在此框架中,决策树逻辑被用于挖掘足球视频中的射门得分。决策树的构建是通过根据特定条件递归划分训练集来执行的,直到一个分区中的所有实例都具有相同的类标签,或者没有更多的属性可用于进一步的划分。决策树中的内部节点涉及测试特定属性,并且从该节点派生的分支对应于测试的所有可能结果。 最终,形成一个叶节点,该叶节点带有一个类别标签,该标签指示最终分区内的多数类别。分类阶段的工作方式类似于遍历树中的路径。从根开始,某个属性的实例值决定了在每个内部节点处进行哪个分支。只要到达叶节点,就会将其关联的类标签分配给该实例。本研究中使用的算法是从 C4.5 决策树中采用的。
在决策树生成过程中,信息增益比率准则由于其效率和简单性而用于确定最适合进行划分的属性。数值属性是通过双向拆分来容纳的,这意味着将找到一个断点,并将其用作将实例分为两组的阈值。最佳断点的投票基于信息增益值。
3 实验结果
3.1 足球视频数据和特征提取
在我们的实验中,我们通过互联网从各种来源收集了 27 种足球视频文件,这些文件具有不同的风格,并由不同的广播公司制作。总持续时间为 9 小时 28 分钟。在总共 4885 个视频镜头中,只有 41 个是目标镜头,仅占总数的 0.8%。
这些视频文件首先通过使用建议的镜头检测算法进行解析。然后,通过特征提取过程为每个视频镜头计算并归一化视觉和音频特征。我们在每个特征向量中包含 10 个音频特征和 5 个视觉特征,并将特征集传递到预过滤阶段。然后将通过预过滤生成的候选镜头用于数据挖掘阶段,与原始数据集相比,该阶段包含更少的噪声和离群值。预过滤后的结果池大小为 886。
3.2 视频数据挖掘以检测目标球
我们随机选择这 886 个候选镜头作为训练数据(666 个镜头,约占总数据的 75%)或测试数据(剩余的 220 个镜头)。训练数据集包含 28 个射门;而其他 13 个射门包括在测试数据集中。
构造决策树:决策树由 C4.5 方法基于训练数据集生成。视觉特征(histochange 等)和音频特征(volumemean 等)都用于构造决策树。此外,我们还将根据规则 1(在第 2.2 节中指定)探索另外两个有效功能。首先,对于每个镜头,其最后三秒音频轨道和其后镜头的前三秒轨道(简称为 nextfirst3)的峰值音量都被累加为特征 volumesum。第二,其 nextfirst3 的平均音量充当另一个音频特征 volumenextfirst3。正确识别了总共 25 个进球和 637 个非进球(即分别标记为“是”和“非”)。换句话说,只有三个“是”和一个“非”实例被错误分类。
3.3 整体分类表现
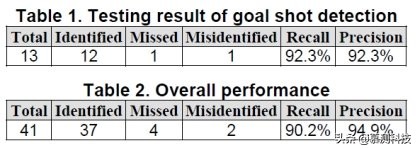
将生成的决策树模型应用于包含 13 个进球和 207 个非进球的测试数据集。 表 1 显示了使用所提出的框架对测试数据集进行的目标射击分类的分类结果,其准确性和召回率均为 92.3%(12/13)。表 2 给出了同时使用训练和测试数据集的总体性能。召回率为 90.2%(37/41),精度为 94.9%(37/39)。如我们所见,结果非常令人满意,令人鼓舞。
4 结论
本文提出了一个框架,该框架使用数据挖掘与多模态处理相结合来从足球视频中提取足球目标事件。它由三个主要部分组成,即视频解析,数据预过滤和数据挖掘。我们对来自不同来源的各种视频数据的实验结果表明,数据挖掘和视频多模态处理的集成是有效,高效地提取足球目标事件的可行且强大的方法。
致谢
本文由*京大南**学软件学院 2020 级硕士生刘子夕翻译转述