OpenCV集成了SVM学习算法,它被包含在ml模块下的SVM类中。本文通过官方提供的数字图像展示SVM模型的训练,分类预测的实现过程,方便进一步理解SVM算法的实现原理。
概要如下,
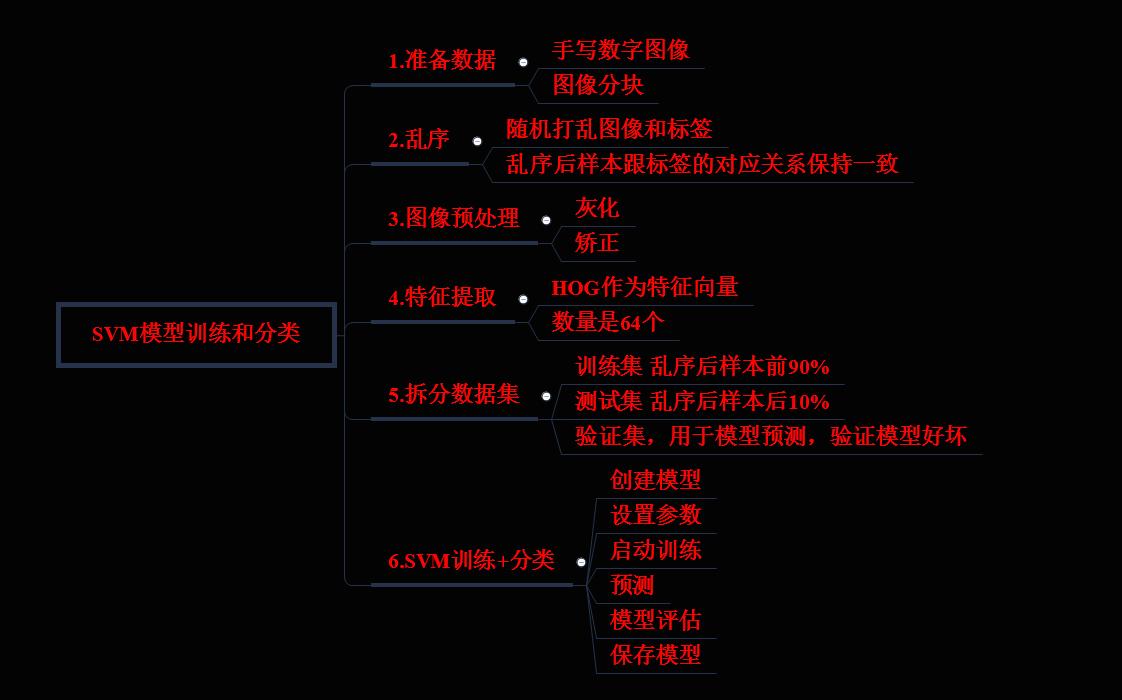
概要
1.数据准备
在OpenCV的安装路径(samples\data)下,digits.png,可以得到一张图片,图片大小为1000*2000,有0-9的10个数字,每5行为一个数字,总共50行,共有5000个手写数字,每个数字块大小为20*20。

digits.png
现在通过OpenCV 图像分块,将样本数据图像取出来。
//加载图像 并分块,得到数字样本图像和标签
void load_digits(const char* fn, vector<Mat>& digits, vector<int>& labels)
{
digits.clear();
labels.clear();
String filename = samples::findFile(fn);
cout << "Loading " << filename << " ..." << endl;
Mat digits_img = imread(filename, IMREAD_GRAYSCALE);
//按20*20 分块,得到数字样本图像
split2d(digits_img, Size(SZ, SZ), digits);
//0---9 共10个类别
for (int i = 0; i < CLASS_N; i++)
{
for (size_t j = 0; j < digits.size() / CLASS_N; j++)
{
labels.push_back(i);
}
}
}
2.乱序
随机打乱样本的顺序,打乱后样本跟标签对应关系保持一致。参考如下实现代码,
void shuffle(vector<Mat>& digits, vector<int>& labels)
{
vector<int> shuffled_indexes(digits.size());
for (size_t i = 0; i < digits.size(); i++)
{
shuffled_indexes[i] = (int)i;
}
//API 函数,函数 cv::randShuffle 通过随机选择元素对和交换他们
randShuffle(shuffled_indexes);
vector<Mat> shuffled_digits(digits.size());
vector<int> shuffled_labels(labels.size());
//保持样本跟标签信息一致
for (size_t i = 0; i < shuffled_indexes.size(); i++)
{
shuffled_digits[shuffled_indexes[i]] = digits[i];
shuffled_labels[shuffled_indexes[i]] = labels[i];
}
digits = shuffled_digits;
labels = shuffled_labels;
}
3.图像预处理
矫正图像 训练数据中有些图像是扭曲的,需要做抗扭曲处理,也就是把歪了的图片摆正。
void deskew(const Mat& img, Mat& deskewed_img)
{
//图像的矩
Moments m = moments(img);
if (abs(m.mu02) < 0.01)
{
deskewed_img = img.clone();
return;
}
float skew = (float)(m.mu11 / m.mu02);
float M_vals[2][3] = { {1, skew, -0.5f * SZ * skew}, {0, 1, 0} };
Mat M(Size(3, 2), CV_32F);
for (int i = 0; i < M.rows; i++)
{
for (int j = 0; j < M.cols; j++)
{
M.at<float>(i, j) = M_vals[i][j];
}
}
//矫正
warpAffine(img, deskewed_img, M, Size(SZ, SZ), WARP_INVERSE_MAP | INTER_LINEAR);
}
4.特征提取
使用HOG作为特征向量,获得每张图片的特征向量(64个)。
/*
计算图像 X 方向和 Y 方向的 Sobel 导数
计算得到每个像素的梯度角度angle和梯度大小magnitude
把这个梯度的角度转换成 0至16 之间的整数
将图像分为4个小的方块,对每一个小方块计算它们梯度角度的直方图histogram(16个 bin),使用梯度的大小做权重。每一个小方块都会得到一个含有16个值的向量,4 个小方块的4个向量就组成了这个图像的特征向量(包含64个值)。
*/
void preprocess_hog(const vector<Mat>& digits, Mat& hog)
{
int bin_n = 16;
int half_cell = SZ / 2;
double eps = 1e-7;
hog = Mat(Size(4 * bin_n, (int)digits.size()), CV_32F);
for (size_t img_index = 0; img_index < digits.size(); img_index++)
{
Mat gx;
Sobel(digits[img_index], gx, CV_32F, 1, 0);
Mat gy;
Sobel(digits[img_index], gy, CV_32F, 0, 1);
Mat mag;
Mat ang;
cartToPolar(gx, gy, mag, ang);
Mat bin(ang.size(), CV_32S);
for (int i = 0; i < ang.rows; i++)
{
for (int j = 0; j < ang.cols; j++)
{
bin.at<int>(i, j) = (int)(bin_n * ang.at<float>(i, j) / (2 * CV_PI));
}
}
Mat bin_cells[] = {
bin(Rect(0, 0, half_cell, half_cell)),
bin(Rect(half_cell, 0, half_cell, half_cell)),
bin(Rect(0, half_cell, half_cell, half_cell)),
bin(Rect(half_cell, half_cell, half_cell, half_cell))
};
Mat mag_cells[] = {
mag(Rect(0, 0, half_cell, half_cell)),
mag(Rect(half_cell, 0, half_cell, half_cell)),
mag(Rect(0, half_cell, half_cell, half_cell)),
mag(Rect(half_cell, half_cell, half_cell, half_cell))
};
vector<double> hist;
hist.reserve(4 * bin_n);
for (int i = 0; i < 4; i++)
{
vector<double> partial_hist;
bincount(bin_cells[i], mag_cells[i], bin_n, partial_hist);
hist.insert(hist.end(), partial_hist.begin(), partial_hist.end());
}
// transform to Hellinger kernel
double sum = 0;
for (size_t i = 0; i < hist.size(); i++)
{
sum += hist[i];
}
for (size_t i = 0; i < hist.size(); i++)
{
hist[i] /= sum + eps;
hist[i] = sqrt(hist[i]);
}
double hist_norm = norm(hist);
for (size_t i = 0; i < hist.size(); i++)
{
hog.at<float>((int)img_index, (int)i) = (float)(hist[i] / (hist_norm + eps));
}
}
}
5.拆分数据集
//设置训练样本的个数 总样本的90% =5000*0.9 = 4500
int train_n = (int)(0.9 * samples.rows);
//最后的500个样本 作为测试集
vector<Mat> digits_test(digits2.begin() + train_n, digits2.end());
//将测试集图像合并
Mat test_set;
//合并分块图像,生成测试图像
mosaic(25, digits_test, test_set);
imshow("test set", test_set);
waitKey(0);
//特征向量---训练集
Mat samples_train = samples(Rect(0, 0, samples.cols, train_n));
//特征向量---测试集
Mat samples_test = samples(Rect(0, train_n, samples.cols, samples.rows - train_n));
//对应的标签
vector<int> labels_train(labels.begin(), labels.begin() + train_n);
vector<int> labels_test(labels.begin() + train_n, labels.end());
合并后的测试图像,
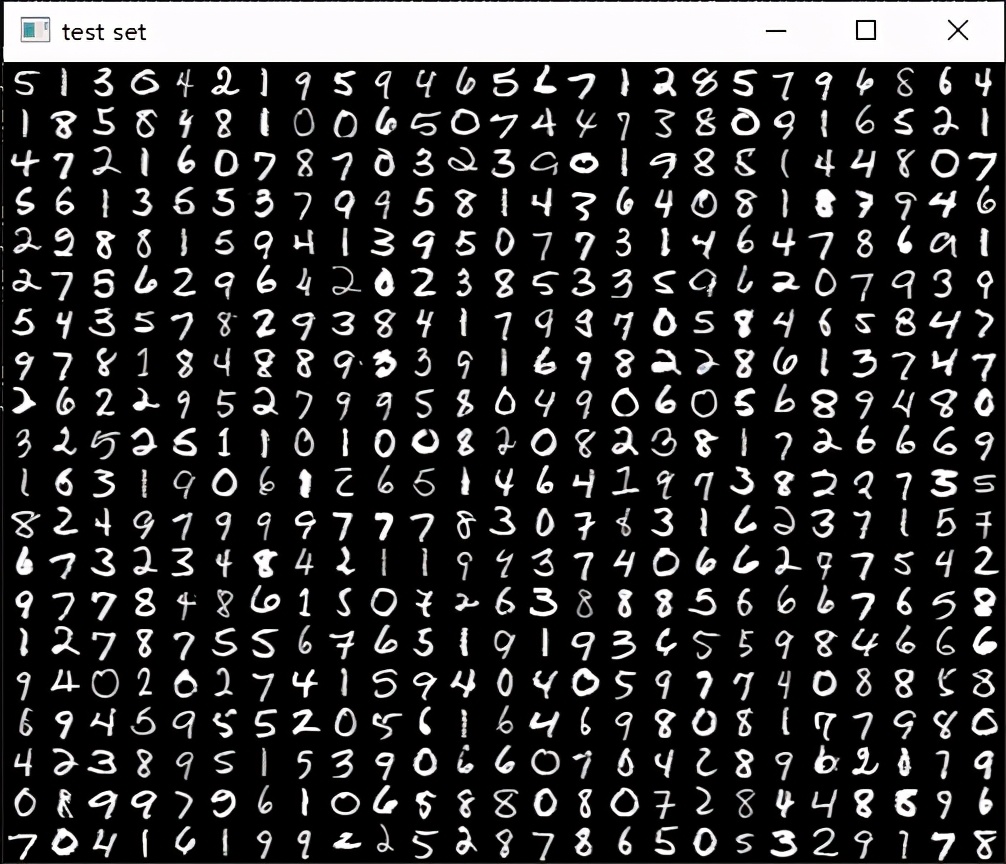
测试集
6.SVM 训练+分类
Ptr<ml::SVM> svm;
vector<float> predictions;
Mat vis;
cout << "training SVM..." << endl;
svm = ml::SVM::create();
svm->setGamma(5.383);
//设置惩罚系数
svm->setC(2.67);
//核函数类型
svm->setKernel(ml::SVM::RBF);
//分类用SVC,回归用SVR
svm->setType(ml::SVM::C_SVC);
//给模型填入训练集数据和标签,送入训练数据集合和标签集合进行机器学习
svm->train(samples_train, ml::ROW_SAMPLE, labels_train);
//SVM预测
//predict digits with SVM
svm->predict(samples_test, predictions);
//SVM模型评估
evaluate_model(predictions, digits_test, labels_test, vis);
//显示预测结果
imshow("SVM test", vis);
cout << "Saving SVM as \"digits_svm.yml\"..." << endl;
//保存SVM训练的模型
svm->save("D:/digits_svm.yml");
//释放资源
svm.release();
模型评估结果:
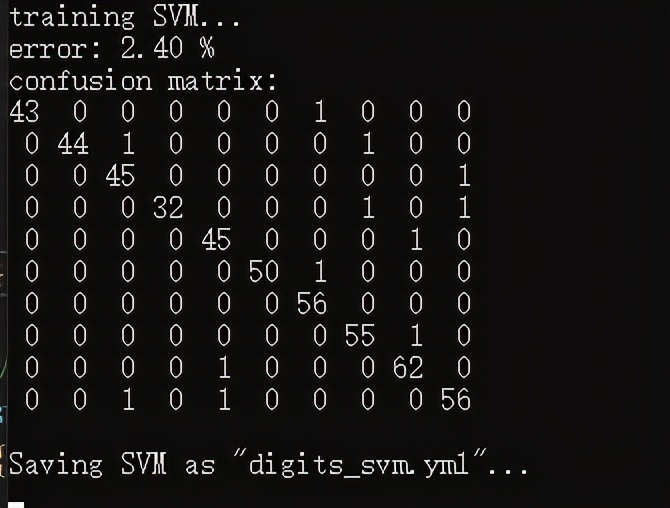
分类结果:
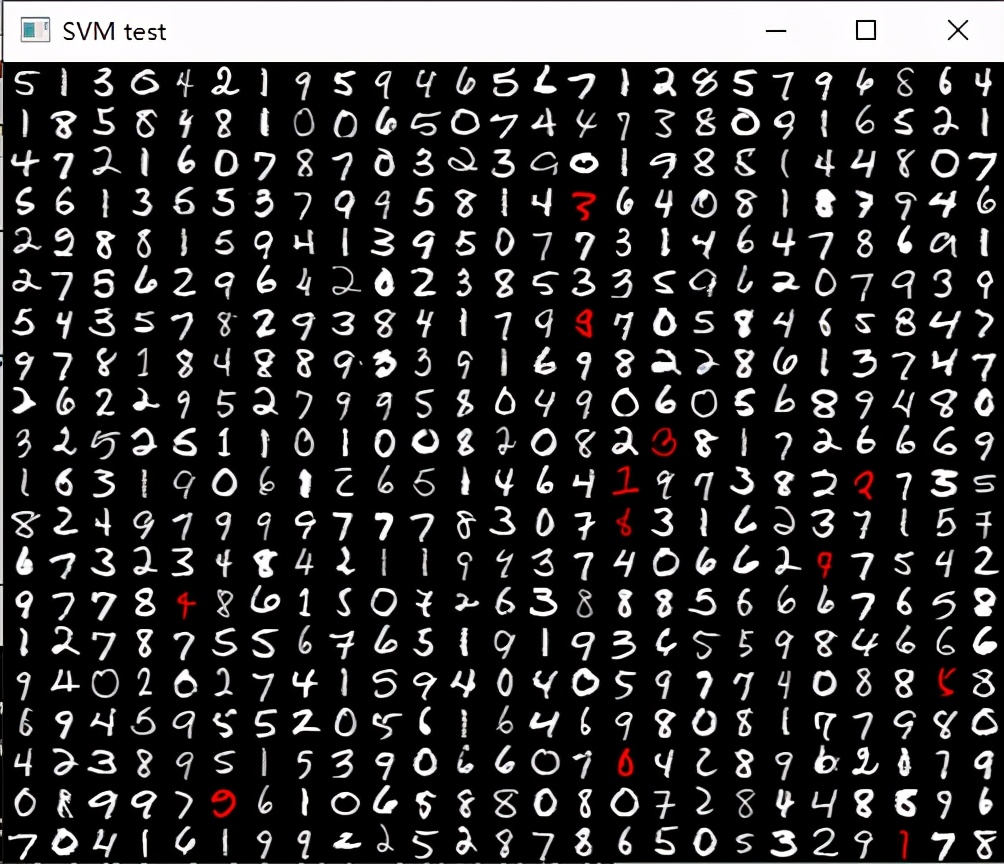
分类结果,红色表示预测值与标签不一致
训练得到的SVM 模型文件
