
神经网络是深度学习的核心软件。 然而,尽管它们如此普遍,人们对它们的了解却真的很少。 研究人员观察了它们的对外特性,却没有真正理解它们为什么会以这种方式工作。
麻省理工学院的一篇新论文[1]在回答这个问题上迈出了重要的一步。 在这个过程中,研究人员得出了一个简单而戏剧性的发现: 我们使用的神经网络比我们实际需要的要大得多。 在某些情况下,它们比实际需要大10倍甚至100倍,所以训练它们需要花费我们更多的时间和计算资源。换句话说,每个神经网络都存在着一个小得多的神经网络,可以通过训练来达到与其过大的主网络相同的性能。 对于人工智能研究者来说,这是个令人兴奋的消息,这一发现有可能开启新的应用程序——其中一些我们还无法理解——但可以改善我们的日常生活 。
首先,让我们深入研究一下神经网络是如何工作,来理解为什么这是可能的。
来自网络
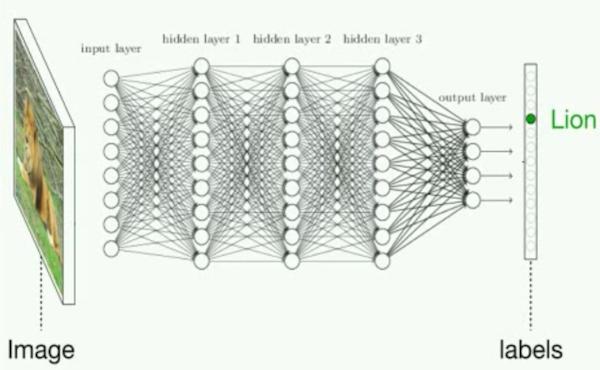
上图为学习识别狮子的神经网络图,其神经网络是由层层叠叠的简单计算节点组成的,为了计算数据中的模式,这些节点被连接起来。联系才是最重要的,在一个神经网络被训练之前,这些连接被分配在0到1之间的随机值,代表它们的强度(这个过程称为"初始化"过程),在训练过程中,当网络接收到一系列动物照片时,它会调整这些强度,这有点像一个人在积累经验和知识时大脑加强或减弱不同神经元连接的方式。 训练结束后,最后的连接强度将被永久地用于识别新照片中的动物。
虽然人们对神经网络的机制已经有了很好的了解,但是它们如此工作的原因仍然是一个谜。 然而,通过大量的实验,研究人员观察到神经网络的两个性质已被证明是有用的。
1.当一个网络在训练过程之前被初始化时,随机分配的连接强度总是有可能最终以不可训练的配置结束。 换句话说,无论你给神经网络输入多少动物照片,它都不会达到一个理想的性能,你只需要重新初始化它到一个新的配置。 网络越大(它拥有的层和节点越多) ,这种可能性就越小。 然而,一个微小的神经网络可能只有五分之一的初始化数据可以训练,而一个更大的神经网络可能只有五分之四可以训练。 为什么会发生这种情况一直是个谜,但这就是为什么研究人员通常使用非常大的网络来完成他们的深度学习任务,他们希望这样能增加实现成功模型的机会。
2.结果就是神经网络开始的时候通常比它需要的要大。 一旦它完成了训练,通常只有一小部分的连接保持强大,而其他的连接则变得相当弱——弱到你实际上可以在不影响网络性能的情况下删除它们。
一直以来,研究人员利用这第二个观察结果,在训练后缩小他们的网络,以降低运行这些网络所需的时间和计算成本,但是没有人认为在训练之前缩小他们的网络是可能的。 它假设你必须从一个超大的网络开始,训练过程必须持续下去,以便将相关的连接从不相关的连接中分离出来。论文的作者之一麻省理工学院的博士生乔纳森 · 弗兰克尔对这一假设提出了质疑。他认为如果你需要的连接比你开始时少得多,为什么我们不能在没有额外连接的情况下训练更小的网络呢?事实证明这是可以的。
该论文的发现取决于这样一个事实,即在初始化过程中分配的随机连接强度实际上并不是随机的,它们在训练发生之前就预先决定了网络的不同部分会失败或成功。 换句话说,初始配置会影响网络到达的最终配置。研究人员发现,如果你在训练之后修剪一个过大的网络,你实际上可以重新使用由此产生的较小的网络来训练新的数据并保持高性能,只要你将这个缩小的网络中的每个连接重新设置为其最初的强度。几位作者提出了他们所谓的"彩票假说",当你随机初始化一个神经网络的连接强度时,就像买一袋彩票一样,你希望你的包里有一张中奖彩票。这也解释了为什么观察1是正确的,从一个更大的网络开始就像买更多的彩票。 你并没有增加你在深度学习问题上投入的力量; 你只是增加了获得成功配置的可能性。一旦找到中奖配置,你就可以重复使用它,而不是继续重新抽签。
这引出了许多问题:首先,你如何找到中奖的彩票? 在他们的论文中,弗兰克尔和卡宾采用了*力暴**破解的方法,通过一个数据集对一个超大型网络进行训练和修剪,从而为另一个数据集提取中奖彩票。 从理论上讲,从一开始就应该有更有效的方法来找到——甚至设计一个成功的配置。其次,成功配置的训练极限是什么? 据推测,不同类型的数据和不同的深度学习任务需要的配置不同。第三,什么是最小的可能的神经网络?你可以得到的同时仍然达到高性能吗? 作者发现通过迭代训练和修剪过程,他能够始终如一地将起始网络减少到原来大小的10% 到20% ,他认为有可能会变得更小。
人工智能领域的许多研究团队已经开始进行后续工作。普林斯顿大学的一位研究人员最近梳理了一篇即将发表的关于第二个问题的论文的结果[2];优步的一个研究小组还发表了一篇关于调查彩票性质的几个实验的新论文[3]。 最令人惊讶的是,他们发现一旦找到了一个成功的配置,在任何训练之前,它已经比原来的未经训练的超大网络达到了更好的性能。 换句话说,修剪网络以提取成功的配置本身就是一种重要的训练方法。
该团队设想未来将拥有一个开源数据库,收集他们发现的所有不同配置,并描述他们擅长的任务,他开玩笑地称之为"神经网络涅槃" 。他相信通过降低训练成本和速度,神经网络的规模将减少10倍,甚至100倍,并允许没有巨型数据服务器的人们直接在小型笔记本电脑甚至手机上进行这项工作,人工智能研究将大大加速和民主化。它还可能改变人工智能应用程序的性质, 如果你可以在一个设备上而不是在云端训练一个神经网络,你可以提高训练过程的速度和数据的安全性。 例如,设想一种基于机器学习的医疗设备,它可以通过使用而不需要将患者数据发送到云服务器上来改进模型。
参考
1.^https://openreview.net/pdf?id=rJl-b3RcF7
2.^https://twitter.com/irregularized/status/1125448462689079297
3.^https://eng.uber.com/deconstructing-lottery-tickets/
文章来源:https://zhuanlan.zhihu.com/p/67073908,北京汇先科技提供新闻资讯