import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import os
import time
import warnings
warnings.filterwarnings('ignore')
#导入数据
train=pd.read_csv('train.csv')
test=pd.read_csv('test.csv')
'''
1、整体来看,存活比例如何?
要求:
① 读取已知生存数据train.csv
② 查看已知存活数据中,存活比例如何?
'''
sns.set_style('ticks')
plt.axis('equal')
train['Survived'].value_counts().plot.pie(autopct='%1.2f%%')

'''
2、结合性别和年龄数据,分析幸存下来的人是哪些人?
要求:
① 年龄数据的分布情况
② 男性和女性存活情况
③ 年龄与存活的关系
④老人和小孩存活情况
'''
#① 年龄数据的分布情况
train_age=train[train['Age'].notnull()]
plt.figure(figsize=(12,5))
plt.subplot(121)
train_age['Age'].hist(bins=80)
plt.xlabel('Age')
plt.ylabel('Fre')
plt.subplot(122)
train_age.boxplot(column='Age')
train_age['Age'].describe()

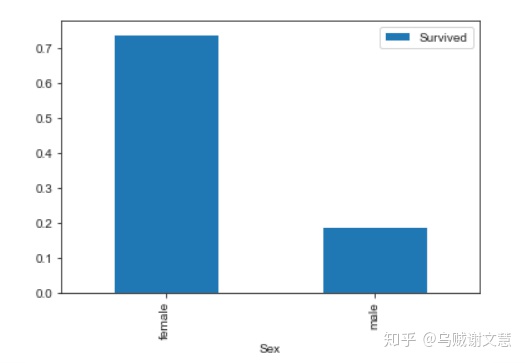
#② 男性和女性存活情况
train[['Sex','Survived']].groupby(['Sex']).mean().plot.bar()
survive_sex = train.groupby(['Sex','Survived'])['Survived'].count()
print(survive_sex)
# 女性生存率较高
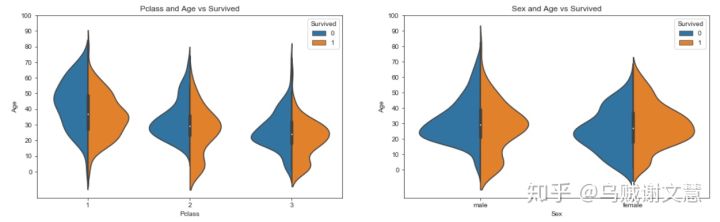
#③ 年龄与存活的关系
fig,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot('Pclass','Age',hue='Survived',data=train_age,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0,110,10))
sns.violinplot("Sex","Age",hue="Survived",data=train_age,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0,110,10))
plt.show()
#按照不同船舱等级划分 → 船舱等级越高,存活者年龄越大,船舱等级1存活年龄集中在20-40岁,船舱等级2/3中有较多低龄乘客存活
#按照性别划分 → 男性女性存活者年龄主要分布在20-40岁,且均有较多低龄乘客,其中女性存活更多
#④老人和小孩存活情况
plt.figure(figsize=(18,4))
train_age['Age_int'] = train_age['Age'].astype(int)
average_age = train_age[["Age_int", "Survived"]].groupby(['Age_int'],as_index=False).mean()
sns.barplot(x='Age_int',y='Survived',data=average_age, palette = 'BuPu')
plt.grid(linestyle = '--',alpha = 0.8)
#灾难中,老人和小孩存活率较高

'''
3、结合 SibSp、Parch字段,研究亲人多少与存活的关系
要求:
① 有无兄弟姐妹/父母子女和存活与否的关系
② 亲戚多少与存活与否的关系
'''
# ①有无兄弟姐妹/父母子女和存活与否的关系
sibsp_df = train[train['SibSp'] != 0]
no_sibsp_df = train[train['SibSp'] == 0]
# 筛选出有无兄弟姐妹数据
parch_df = train[train['Parch'] != 0]
no_parch_df = train[train['Parch'] == 0]
# 筛选出有无父母子女数据
plt.figure(figsize=(12,3))
plt.subplot(141)
plt.axis('equal')
sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct= '%1.1f%%',colormap = 'Blues')
plt.xlabel('sibsp')
plt.subplot(142)
plt.axis('equal')
no_sibsp_df['Survived'].value_counts().plot.pie(labels=['No Survived','Survived'],autopct= '%1.1f%%',colormap = 'Blues')
plt.xlabel('no_sibsp')
plt.subplot(143)
plt.axis('equal')
parch_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct= '%1.1f%%',colormap = 'Reds')
plt.xlabel('parch')
plt.subplot(144)
plt.axis('equal')
no_parch_df['Survived'].value_counts().plot.pie(labels=['No Survived', 'Survived'], autopct = '%1.1f%%',colormap = 'Reds')
plt.xlabel('no_parch')

# ②亲戚多少与存活与否的关系
fig, ax=plt.subplots(1,2,figsize=(15,4))
train[['Parch','Survived']].groupby(['Parch']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Parch and Survived')
train[['SibSp','Survived']].groupby(['SibSp']).mean().plot.bar(ax=ax[1])
ax[1].set_title('SibSp and Survived')
# 查看兄弟姐妹个数与存活率
train['Family_Size'] = train['Parch'] + train['SibSp']+1
train[['Family_Size','Survived']].groupby(['Family_Size']).mean().plot.bar(figsize = (15,4))
# 查看父母子女个数与存活率
#若独自一人,那么其存活率比较低;但是如果亲友太多的话,存活率也会很低

'''
4、结合票的费用情况,研究票价和存活与否的关系
要求:
① 票价分布和存活与否的关系
② 比较研究生还者和未生还者的票价情况
'''
#① 票价分布和存活与否的关系
fig, ax=plt.subplots(1,2,figsize=(15,4))
train['Fare'].hist(bins=70, ax = ax[0])
train.boxplot(column='Fare', by='Pclass', showfliers=False,ax = ax[1])
# 查看票价分布情况
fare_not_survived = train['Fare'][train['Survived'] == 0]
fare_survived = train['Fare'][train['Survived'] == 1]
# 基于票价,筛选出生存与否的数据
average_fare = pd.DataFrame([fare_not_survived.mean(),fare_survived.mean()])
std_fare = pd.DataFrame([fare_not_survived.std(),fare_survived.std()])
average_fare.plot(yerr=std_fare,kind='bar',legend=False,figsize = (15,4),grid = True)
# 查看票价与是否生还的关系
#生还者的平均票价要大于未生还者的平均票价

'''
5、组合训练集和测试集,清洗数据
要求:
① 组合数据集,清洗数据
② 缺失值处理
'''
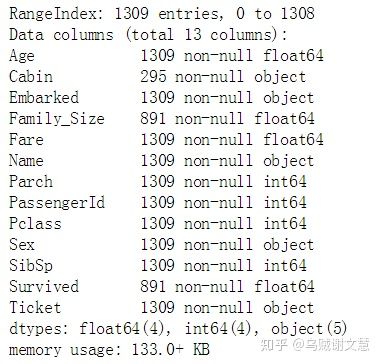
#① 组合数据集,清洗数据
titanic=train.append(test,ignore_index=True)
titanic.info()

#② 缺失值处理
titanic['Age']=titanic['Age'].fillna(titanic['Age'].mean())
titanic['Fare']=titanic['Fare'].fillna(titanic['Fare'].mean())
titanic['Embarked']=titanic['Embarked'].fillna('S')
titanic.info()
'''
6、特征工程
要求:
① 将性别转化为1和0
② 对Embarked、Pclass字段做哑变量处理
③构建新特征Familysize
④提取头衔特征
'''
#① 将性别转化为1和0
titanic.loc[titanic['Sex']=='male','Sex']=0
titanic.loc[titanic['Sex']=='female','Sex']=1
#对Embarked、Pclass字段做哑变量处理
Emdf=pd.DataFrame()
Emdf=pd.get_dummies(titanic['Embarked'],prefix='Em')
titanic=pd.concat([titanic,Emdf],axis=1)
PclassDf = pd.DataFrame()
PclassDf = pd.get_dummies( titanic['Pclass'] , prefix='Pclass' )
titanic=pd.concat([titanic,PclassDf],axis=1)
#③构建新特征Familysize
familydf=pd.DataFrame()
familydf['Familysize']=titanic['Parch']+titanic['SibSp']+1
familydf['Family_Single']=familydf['Familysize'].map(lambda i:1 if i ==1 else 0)
familydf['Family_Small']=familydf['Familysize'].map(lambda i:1 if 2<=i<=3 else 0)
familydf['Family_Big']=familydf['Familysize'].map(lambda i:1 if 4<=i<5 else 0)
titanic=pd.concat([titanic,familydf],axis=1)
#④提取头衔特征
def getTitle(Name):
str1 = Name.split(', ')[1]
str2 = str1.split('. ')[0]
str3 = str2.strip()
return str3
titleDf = pd.DataFrame()
titleDf['Title'] = titanic['Name'].map(getTitle)
titleDf['Title'].value_counts()

title_mapDict={
"Capt":"Officer",
"Col":"Officer",
"Major":"Officer",
"Jonkheer":"Royalty",
"Don":"Royalty",
"Sir":"Royalty",
"Dr":"Officer",
"Rev":"Officer",
"the Countess":"Royalty",
"Dona":"Royalty",
"Mme":"Mrs",
"Mlle":"Miss",
"Ms":"Mrs",
"Mr":"Mr",
"Mrs":"Mrs",
"Miss":"Miss",
"Master":"Master",
"Lady":"Royalty"
}
titleDf['Title']=titleDf.Title.map(title_mapDict)
titleDf=pd.get_dummies(titleDf.Title)
titanic=pd.concat([titanic,titleDf],axis=1)
'''
7、特征筛选
要求:根据相关系数,筛选出用于建模的特征
'''
corrdf=titanic.corr()
corrdf['Survived'].sort_values(ascending=False)

titanic_x=pd.concat([titleDf,PclassDf,familydf,titanic['Fare'],Emdf,titanic['Sex'],titanic['Age']],axis=1)
sourceRow=891
source_x=titanic_x.loc[0:sourceRow-1,:]
source_y=titanic.loc[0:sourceRow-1,'Survived']
pred_x=titanic_x.loc[sourceRow:,:]
#将清洗后的数据集根据训练集和测试集进行拆分
#划分训练集和测试集
from sklearn.model_selection import train_test_split
train_x,test_x,train_y,test_y=train_test_split(source_x,source_y,train_size=0.8)
print(source_x.shape,train_x.shape,test_x.shape)
(891, 19) (712, 19) (179, 19)
'''
8、导入模型算法,对数据进行预测
'''
#导入算法
from sklearn.ensemble import RandomForestClassifier,AdaBoostClassifier,GradientBoostingClassifier,ExtraTreesClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV,cross_val_score,StratifiedKFold
kfold=StratifiedKFold(n_splits=10)#交叉采样拆分数据集
classifiers=[]
classifiers.append(SVC())
classifiers.append(DecisionTreeClassifier())
classifiers.append(RandomForestClassifier())
classifiers.append(ExtraTreesClassifier())
classifiers.append(GradientBoostingClassifier())
classifiers.append(KNeighborsClassifier())
classifiers.append(LogisticRegression())
classifiers.append(LinearDiscriminantAnalysis())
cv_results=[]
for classifier in classifiers:
cv_results.append(cross_val_score(classifier,train_x,train_y,
scoring='accuracy',cv=kfold,n_jobs=-1))
pd.DataFrame(cv_results,index=["SVC","DecisionTreeClassifier","RandomForestClassifier",
"ExtraTreesClassifier","GradientBoostingClassifier",
"KNeighborsClassifier","LogisticRegression","LinearDiscriminantAnalysis"])

cv_means=[]
cv_std=[]
for cv_result in cv_results:
cv_means.append(cv_result.mean())
cv_std.append(cv_result.std())
cvResDf=pd.DataFrame({'cv_mean':cv_means,
'cv_std':cv_std,
'algorithm':["SVC","DecisionTreeClassifier","RandomForestClassifier",
"ExtraTreesClassifier","GradientBoostingClassifier",
"KNeighborsClassifier","LogisticRegression","LinearDiscriminantAnalysis"]})
cvResDf

'''
8、模型调参
'''
#LogisticRegression模型
modelLR=LogisticRegression()
LR_param_grid = {'C' : [1,2,3],
'penalty':['l1','l2']}
modelLR = GridSearchCV(modelLR,param_grid = LR_param_grid, cv=kfold,
scoring="accuracy", n_jobs= -1, verbose = 1)
modelLR.fit(train_x,train_y)
modelLR.score(test_x,test_y)
LRpred_y=modelLR.predict(pred_x)
LRpred_y=LRpred_y.astype(int)
#导出预测结果
LRpreResultDf=pd.DataFrame()
LRpreResultDf['PassengerId']=titanic['PassengerId'][titanic['Survived'].isnull()]
LRpreResultDf['Survived']=LRpred_y
LRpreResultDf
#将预测结果导出为csv文件
LRpreResultDf.to_csv('TitanicLRmodle.csv',index=False)
0.8435754189944135
#GradientBoostingClassifier模型
GBC = GradientBoostingClassifier()
GradientBoostingClassifier(n_estimators=2,min_samples_split=4,min_samples_leaf=2,max_depth=5)
GBC.fit(train_x,train_y)
GBC.score(test_x,test_y)
GBCpred_y=GBC.predict(pred_x)
GBCpred_y=GBCpred_y.astype(int)
#导出预测结果
GBCpreResultDf=pd.DataFrame()
GBCpreResultDf['PassengerId']=titanic['PassengerId'][titanic['Survived'].isnull()]
GBCpreResultDf['Survived']=GBCpred_y
GBCpreResultDf
#将预测结果导出为csv文件
GBCpreResultDf.to_csv('TitanicGBCmodle.csv',index=False)
0.8324022346368715
#LinearDiscriminantAnalysis模型
LDA=LinearDiscriminantAnalysis()
LinearDiscriminantAnalysis(n_components=2, priors=None, shrinkage=None,
solver='svd', store_covariance=False, tol=0.05)
LDA.fit(train_x,train_y)
LDA.score(test_x,test_y)
LDApred_y=LDA.predict(pred_x)
LDApred_y=LDApred_y.astype(int)
#导出预测结果
LDApreResultDf=pd.DataFrame()
LDApreResultDf['PassengerId']=titanic['PassengerId'][titanic['Survived'].isnull()]
LDApreResultDf['Survived']=LDApred_y
LDApreResultDf
#将预测结果导出为csv文件
LDApreResultDf.to_csv('TitanicLDAmodle.csv',index=False)
0.8435754189944135
最后贴上参赛的得分排名:

