
ChatGPT一出,OpenAI名声大震,CEO Sam Altman成为聚光灯下的C位主角。年少成名,Sam不到30岁成为YC总裁,从2019年GPT-3开始,他开始主导OpenAI运营事务,取得非凡成就。
Sam擅长将企业发展从1放大到1,000,但自2015年OpenAI创立,到2019年GPT-2发布期间,还有很多故事。
Greg Brockman是将OpenAI从0到1拉扯到大的关键先生,是OpenAI联合创始人,从2015年开始,Greg和首席科学家Ilya Sutskever主导OpenAI创建,以及日常运营和研究工作。
Greg现在也是OpenAI董事长和总裁,2022年前一直担任CTO,从企业权力结构来看,Greg是OpenAI背后的一号人物。
Greg履历非凡,2009年,本科哈佛大学数学与计算机科学系毕业,2010年MIT计算机科学读博,期间维护XVM、Linerva、scripts.mit.edu等知名项目。
毕业后成为互联网支付平台Stripe CTO,帮助团队实现员工人数从4人~250人增长,在公司发展蒸蒸日上之际,选择急流勇退,继续追逐伟大事业,由此才有OpenAI创业历程。
OpenAI诞生源自一群非凡投资人。OpenAI起源于2015年门洛帕克一顿晚饭,大佬云集,在基于构建安全的人工智能以造福人类的愿景下,他们决定创建非营利性机构,最终获得包括Greg Brockman、Sam Altman、马斯克、Peter Thiel、YC创始合伙人Jessica Livingston、LinkedIn联合创始人Reid Hoffman等企业家,以及亚马逊的AWS等知名企业和机构的十亿美元投资。
光有钱还不够,负责创建OpenAI团队的Greg,还要找到能实现这一愿景的技术人才。
通过搜寻人际网络,Greg希望邀请一批顶级人才组建队伍,这个网络上的节点人物很是惊人,包括深度学习领域三巨头Geoffrey Hinton、Yann LeCun、Yoshua Bengio等大牛,这些大牛又给Greg推荐了人工智能领域顶尖技术人才,包括机器人与强化学习领域大牛Pieter Abbeel、Andrej Karpathy(特斯拉前AI总监,最近回归OpenAI)、Ian Goodfellow(GAN网络发明者)、Wojciech Zaremba(Yann Lecun学生)等。
Greg认为,团队的成功需要招募到对的人。尽管OpenAI成立不久,但经过Greg和Ilya Sutskever共同努力,吸引不少业内顶级大牛加入,而这更多依靠的是对OpenAI使命愿景的认同,以及与聪明人一起工作的环境。
在Greg Brockman主导OpenAI的最初2年里,2016年4月,OpenAI发布了强化学习研究平台OpenAI Gym的公测版,同年12月,发布了软件平台Universe,用于衡量和训练人工智能在全球游戏、网站、其他应用程序中的通用智能。
2016年,AlphaGo刚问世,新一轮AI黄金时*开代**启。与此同时,AI领域尚不存在大型语言模型LLM这个概念,刚成立2年的OpenAI也没有发布GPT模型,他们似乎只有模糊的想法,不过这个新组织每天都在为新技术探索而激动。
本期【长期主义】,选择OpenAI联合创始人Greg Brockman 2016年5月发布的博客、2019年4月接受知名科技博主Lex Fridman访谈纪要,分别由OneFlow、海外独角兽编译发布,*合六**商业研选精校,分享给大家,Enjoy!
正文:
全文16,240字
预计阅读33分钟

ChatGPT背后:从0到1,OpenAI创立之路
作者:Greg Brockman
博客发表时间:2016年5月
来源:OneFlow编译
字数:8,254
高中毕业后的间隔年里,我曾认真学过编程。我读过图灵《计算机器与智能》一书,并深受启发:代码能理解那些编写代码者所不能理解的东西。
于是我准备着手写一个聊天机器人。那么写出来有多难?我想创建的是能与人正常对话的机器人,但找了很久,似乎没有人能做出这种机器人。我很快便搁置了这个想法,转而专注于创建那些能真正产生影响的系统。
大学研究项目
读大学时,我对编程语言很感兴趣,由此进入AI大门。编译器和静态分析器能理解那些我理解不了的程序,于是我便常用其来做一些非常有用的事情,比如快速生成代码并检验其是否正确。
我一直想潜下心来做编程语言研究,却总是受到新的创业点子和新同事影响。我同事人都还不错,但这些创业想法就不敢恭维。无论在哈佛,还是麻省理工,我都努力向优秀的人看齐,主动融入他们,并与之共建有用的东西。

Greg Brockman
大三那年,我发现在校创业没有意义,我就和创业者面谈,汲取经验。与此同时,我终于开始编程语言研究之旅。
我从一位教授那里获得研究经费,招募一些朋友进行静态缓冲超时检测项目。几周后,帕洛阿托Palo Alto一家尚未启动的初创公司联系我。一般情况我会直接删除这种邮件,但此时我正准备与初创公司会面,我们团队就立即点开邮件,此时我也发现,他们正是我一直在寻找的那种人。于是我离开学校,这也意味着我们的缓冲超时检测项目就此搁置。
Stripe生涯
那家公司就是现在的Stripe。在我帮助下,公司规模从4人扩大到250人;在我离开后的1年里,又继续扩大到450人(当然这份功劳与我无关)。
此时公司发展正蒸蒸日上,无论有我没我,都会继续做伟大的事情,我准备离开Stripe。
我想做的是与优秀之人同行,做些有意义的事情,但开发者基础架构并不是我想穷尽余生之力去解决的问题。
我终于还是找到那个我想解决的问题:创造出安全的人类级别的AI(human-level AI)。 只要这项技术能真正为人类所用,我想一定会引起轰动,并给世界带来积极影响。
在我最终决定离职之前,Patrick说Sam Altman有很好的局外人视角,而且见过很多跟我情况类似的人,应该能给我一些好的建议,让我去和他谈。
在与Sam交谈5分钟后,他说,看来你是完全准备好离职了,后续事宜有什么需要我帮助的?
我说AI是我的首选,这绝对是我的人生目标,但还不确定现在是否就是做这件事的最佳时机,我也不知道最佳的贡献方式是什么。他回答:我们一直在考虑通过YC建立AI实验室,你或许可以跟我们合作。
研究深度学习
大约在这一两周后,我离开Stripe,开始着手深入研究AI,想要更好了解该领域正在发生的事情。仅从Hacker News上的帖子(例如http://karpathy.github.io/2015/05/21/rnn-effectiveness/)就可以看出:人们对AI,尤其是对深度学习关注度越来越高。
但在进入该领域时,我仍然是持有合理怀疑,在投身AI之前,我想确定一切都是可行的。
我第一个目标,是弄清楚深度学习到底是什么,然而事实证明这并非易事。例如,deeplearning.net上只是说,深度学习是机器学习研究的新领域,引入深度学习目的是使其更接近最初的人工智能目标。这听起来很令人兴奋,却并没有说清楚到底什么是深度学习。
幸运的是,我有一些从事AI行业的朋友:Dario Amodei(曾任OpenAI研究主管,现Anthropic创始人和CEO)和Chris Olah(曾任OpenAI技术主管,现为Anthropic联合创始人)。我向他们征求一些意见,他们给我一些很好的入门资源,最有用的是Michael Nielsen写的书。我读完后还在Kaggle上练习了新学到的技能(在第一次比赛时我就拿到了第一名)。
一路走来,我不断遇到AI领域中超级聪明的人,并与我大学时最聪明的一些朋友重新建立联系,例如现在该领域工作的Paul Christiano(曾任OpenAI研究员,现Alignment Research Center创始人)和Jacob Steinhardt(加州伯克利分校助理教授),我觉得这是一个强烈的信号。
我了解得越多,就越相信AI已准备好散发自己光芒。深度学习的能力,简直令人难以置信,比如,我们现在可以极其准确对图像中目标进行分类(2014年的XKCD就已实现),语音识别非常精准,还可生成十分逼真的图像。
不过虽然这些技术足够新,但到现在为止,还没有改变人们生活方式,它们如今的影响,还仅限于支持某些产品实现特定功能。
有位朋友曾开发过Facebook News Feed。还记得我曾对他说过这样一句话: 简单的算法,大量的数据。每个人都试图兜售很酷的新AI算法,但实际上只需要扩展逻辑回归(logistic regression)就会非常奏效。
而他对此持怀疑态度。然后我就拿出了谷歌翻译APP,将其设置为飞行模式,并向他演示了如何直接翻译图片上文字。他对此印象颇深,并承认简单的算法对此无济于事(这背后主要是深度学习在发挥作用,不过这不是重点,重点是它有效。)
创业想法诞生
Sam Altman在2015年6月联系我,问我是否想好下一步该做什么,我告诉他目前计划是2016年开一家AI公司。然后我们打了通电话,他提到他们正在推进YC的AI项目。我问:实验室目的是什么?他说, 建立安全的人类级AI。
在那一刻我就知道,他很适合当我下一家公司的合作伙伴。 现在很少有人敢于明确尝试构建人类级AI。我意识到,有时候一项成就只需要有个胆大的人宣布目标,然后合适的人就会加入其中。
大约1个月后,Sam在门洛帕克Menlo Park举办一场晚宴,参加宴会的有Dario、Chris、Paul、Ilya Sutskever、Elon Musk、Sam和其他一些人。
我们讨论了AI领域现状、目前离人类级AI还有多远,以及实现人类级AI还需要的东西等。整场对话围绕着“什么样的组织可以最好确保AI的有益性”展开。
答案很明显:必须是非营利组织,因为没有任何利益冲突来影响其使命。此外,这样组织还必须保持在研究的前沿(根据Alan Kay的名言,预测未来的最好方法就是创造未来)。为此,该组织需要有世界上最好的AI研究人员。
所以问题变成:是否有可能从头开始,创建拥有最优秀AI研究人员的实验室?我们结论:还是有机会。
这是我第一次见到Elon和Ilya,我对他们印象非常深刻。Elon充满好奇心,他真诚征求他人意见,并用心倾听每一份回答;Ilya是技术基础的源泉,他是头脑清晰的技术专家,知识广博,视野开阔,并且总是能深入到当前系统局限性和功能的具体细节。
我请Ilya对深度学习给出好的定义,以下是他的回答:有监督深度学习的目标,是解决几乎所有“将X映射到Y”形式的问题。X包括图像、语音或文本,Y包括类别甚至句子。将图像映射到类别、将语音映射到文本、将文本映射到类别等,如此种种,深度学习都是非常有用的,而且其他方法无法做到。
深度学习一大吸引人的特点,是它在很大程度上是独立于其他领域之外:在一个领域中学到的许多东西可以适用于其他领域。
深度学习模型中建立了抽象层,这些抽象可以完成工作,但很难理解它们究竟是如何做到的。模型通过使用反向传播算法(简单、高效),逐渐改变神经网络的突触强度来学习。
因此,我们可以用极少代码,来构建出大规模复杂的系统,因为我们只需要编写模型和学习算法的代码,而非最终结果。
晚宴结束后,Sam送我回城里。我们都认同值得在AI领域做点什么。我知道,只有当有人愿意全心全意弄清楚这究竟是什么,谁又能够加入其中,我们的愿景才会成为现实,那就让我来当这样的人吧。所以,我明天又要构建一些有影响力的东西。
OpenAI的愿景
那次晚宴上,我们谈论了成立OpenAI实验室。虽然每个来参加晚宴的人都各抒己见,但并没有一个清晰的愿景,Elon和Sam提出自己的想法:OpenAI旨在构建安全的人工智能以造福人类。我也想尽可能贡献自己的力量,为了如愿以偿,便开始和Sam一起组建团队。
不过我们缺少 核心要素,即一位AI技术远见者,其直觉和想法可以帮助我们取得突破。

从左至右依次为Ilya Sutskever、Alex Krizhevsky、Geoffrey Hinton
Ilya Sutskever是最佳人选。Ilya可以说是一位艺术家,他常通过机器学习来表达自己感受(有时也会通过绘画来表达)。
深度学习教父Geoffrey Hinton曾告诉我,AlexNet之所以能引发一场计算机视觉深度学习革命,在于Alex Krizhevsky高超的GPU编码技能及Ilya的信念,即深度神经网络必定会在ImageNet竞赛中获胜。
Geoff对自己贡献的管理技巧感到无比自豪。Alex非常讨厌写论文,Geoff告诉他,他在ImageNet上的性能每提高1%,他就可以把论文推迟一周,结果Alex拖延了15周。
一直以来,我都认为自己只能与相识多年的朋友共创公司,事实并非如此。
2015年8月下旬,我和Ilya在山景城共进晚餐,当时我就知道我们会一起合作,在此之前,我们也只在7月见过一次。
我和Ilya聊得十分投机,尽管我对机器学习了解不多,他对工程和团队建设的认识也没有那么深入,但我们对彼此的成就印象十分深刻,也希望能够相互学习。我们交流彼此看法、汲取彼此长处。
Ilya认为,顶级研究人员希望在人工智能组织工作,而该组织致力于为世界创造最佳成果。在我看来,要想解决一些棘手问题,需将私营企业资源与学术界使命相结合。
若无外界干预,人工智能将会像自动驾驶汽车一样发挥自身作用。一旦人工智能潜力得以证实,人们就会与之展开合作,而后是一场场技术竞赛。不过,人类级别的人工智能,将会是一种与众不同的变革性技术,有其独特的风险和收益。
我们看到了这一机遇:在人工智能领域展开合作,汇集众多顶尖研究人员,以取得史上最重大的科技突破。Ilya和我一直在讨论团队组建方案,直到该方案得以落实。期间,我们讨论了战略(即将从事什么工作)、文化(想雇用的人员,同等重视工程和研究的人员)、策略(举办每日阅读小组)。
Alan Kay与我们共进晚餐时,向我们讲述了施乐帕洛阿尔托研究中心Xerox PARC的故事,包括Alto的诞生及用硬件在未来生存,这些硬件在10年内将花费1,000美元。
事后,Ilya对用餐期间的谈话做了巧妙总结:虽然Alan的话我只听懂一半,但令人振奋不已。不过这顿饭帮我们验证了许多假设,即怎样才能构建一支能将工程与研究相结合的有影响力的团队。
早期团队的招募
由于Ilya还在谷歌工作,因此无法帮忙招聘,这一工作落到我身上。2015年8月~11月,由我负责创办团队。不过,我对人工智能并不熟悉,不清楚如何招募优秀的研究人员。
我首先关注的是7月参加过晚宴的人,但不能确认具体人选。下一步,便是通过人际网络与这些人取得联系,并依次寻求他们推荐,这与我以往招聘方式有所不同。
对于初创公司而言,首要挑战总是要向候选人兜售使命,但在OpenAI,使命立刻引发大家共鸣。于我而言,挑战在于如何说服候选人相信这个未成形的组织。

人工智能领域顶尖人才的人际网络,对我帮助很大。一位朋友引荐我认识Andrej Karpathy和OpenAI联合创始人Wojciech Zaremba,由于我并未从事该领域工作,他们对我说的话表示怀疑。
Yoshua Bengio又将我引荐给曾任OpenAI研究科学家的Durk Kingma(现在谷歌研究团队),当时后者对我的提议表示很感兴趣,不过这种兴趣转瞬即逝。真正的转折点是OpenAI联合创始人、研究科学家John Schulman的评价,我跟他聊到这一组织的成立,他表示这样的组织正是他所追寻的,能将学术界的开放和使命,与私企的资源相结合,因此加入我们。
John的支持,也引起了Andrej和Wojciech关注。招聘工程师相对容易一些。Trevor Blackwell是机器人专家,也是YC合伙人,他一直在与Sam讨论我们正在计划的疯狂想法。
Vicki Cheung(现Gantry联合创始人),是在我们成立赞助机构“YC Research(现为OpenResearch)”之后申请加入的。那时,我们虽未表明研究领域是AI,但她深受YC Research构架鼓舞,并表示很乐意参与我们团队所有工作。
2015年11月初,虽然我们对创始团队有了更深入了解,但仍然需要让大家正式加入进来。在Sam建议下,我们邀请了所有候选人户外漫步。期间,人人都真切表达内心想法、观点,才思泉涌(实际上,该地也是Andrej提出Universe之地)。回程中,一路上交通堵塞。不过几乎没人留意到这一点,因为大家聊得太投入了。

我们给此次活动的参与者,都发了offer,并将offer截止日期设置为2015年12月1日,这样我们就可以在12月初NIPS(NeurIPS)机器学习会议上发布成员加入的消息。
“月末”就这样开始了。Sam、Elon,还有我,和每个人都聊了聊,主要是让大家相信这件事的真实性。除了一名完全无意涉足人工智能的工程师外,其他候选人都接受了我们offer。
Fred Brooks在《人月神话》一书中,提及了Robert Heinlein的故事,该故事讲述了登月项目。该项目的总工程师,总会被运营任务分散注意力,例如关于运输车或电话的决策,这种情况一直持续到他收到一份报告,据报告显示不再让他负责所有与技术无关的任务。
这一故事给我留下印象深刻,我认为它同样适用于构建人工智能项目。 技术领导,除了做实际技术工作以外,同时还应该亲自做决策。 我不知道自己的工程技能何时才能派上用场,不过在此期间,我决定尽我所能帮Ilya分担与研究无关的任务。
2016年1月4日,我们整个团队来到第一间办公室(也就是我的公寓)开始工作。讨论中,John和Ilya转身打算在白板上写点些什么,却发现这儿没有白板。我立即给他们买了一块白板,还有一些办公用品。

我们第一间办公室(配有白板)
2016年1月剩下时间里,我负责组织团队,帮忙确定哪些人负责哪些工作,以及团队想达成的目标。我们讨论了研究人员需要具备什么品质,践行公司理念,设计并确保面试顺利进行。
我们还谈论了愿景、工作方式,以及想要达成的目标。我和Vicki购买服务器,创建Google Apps帐户,同时对我们12月启动的Kubernetes集群进行维护。
余下时间,我阅读了GAN网络发明者Ian Goodfellow的深度学习书籍,并写下书评,由于我评论比其官方评审员评论更加全面,给他留下深刻印象。因此,这也不失为一种招聘策略。
Gym库
比起使用新的数据集,使用新的算法,通常能解决机器学习中的问题,Wojciech建议构建一个库来形成强化学习环境的标准(实际上是动态数据集),现在称之为Gym,这个代码库的质量,很快成为我们迭代速度的高阶位high-order bit。
2016年2月底,我和John讨论了Gym的公开发布时间。按照目前发展情况,他认为可能要到2016年底才能发布。

我们正在用机器学习训练Fetch机器人,Gym支持控制物理机器人和*拟机模**器人
一时之间,工程学成了研究进展瓶颈。Ilya与我互换角色,由他负责行政工作,我可以专注技术工作。和John考察了这项工作之后,我们知道在2016年4月底之前就能构建好Gym。
在Stripe时,我发现能够直接创建软件系统的可重复模式,专注于软件,排除一切干扰,从早工作到晚。
这样一来,便能激励大家贡献自己最好的作品,重要的是,是以输出质量来衡量,而不是工作时间。
这是我感觉最有活力的时候:编程就如魔法变成现实一般,我所想象和描述的事情都将成为可能。这种模式产生了Stripe信用卡保险库(2010年构建完毕,也就是在我假期回家的2周内完成)、信用卡授权流程(在3周内就能建成,而银行构建周期需要6~12个月)、夺旗赛(通常我和其他人都要花3周时间)。
从战术上讲,我可以选择一个试发行日期、和正式发布日期,间隔一两周;我从未选择过试发行日期,但从未错过正式发布日期。
随之而来的,是从未面临过的挑战。由于我并非该领域专家,起初,引起很多摩擦。我会构造一个抽象的框架来帮助Wojciech工作顺利进行,而John会发现这一举动阻碍了他工作进程。
但很快,我就了解到哪些决定,会影响研究的工作流程(例如人们如何记录指标),以及哪些细节,研究人员不会关注(例如人们如何录制视频)。
在确定了案例对研究的重要性之后,要保持一定的谦逊,才能做出最佳选择。 我通常会提出5个可能的备选方案,John会指出其中有4个方案都不行。但大多数设计决策可以通过软件工程的直觉做出,而无需深入了解相关领域。
幸运的是,我不是一个人。大约在Gym发布的前6周,曾与我在Stripe一起研究CTF 3的Jonas Schneider联系我。短短几天时间,我们就在Gym上建立合作关系。
因为他人在德国,所以我们通过每日交接,最终成功完成该项目。对于已经建立好工作关系的人来说,这真的很奇妙,若一切从头开始,我们不会保持如此紧密的工作关系。

Gym发布后不久,我们在国际表征学习大会ICLR上分发OpenAI T恤
总的来说,机器学习系统可视为机器学习的核心之一,通常是一种高级算法,要想理解该算法,至少需要阅读过几章Ian的书,涉及大量软件工程内容。工程可以围绕数据进行改组,提供输入和输出的封装器,或调度分布式代码,这些都会以黑盒形式与核心core连接。
我们在工程和研究方面作出的努力达到一定程度时,机器学习就会取得进步。工程方面每多一分努力(例如减少Universe延迟),我们模型问题就会逐渐变得更容易,并且有机会完成当前研究。
Universe平台
2016年4月Gym上线后,我和Ilya开始调整组织流程。Sam和Elon都会到访公司,提出一些指导意见,我们会根据其指导来确定团队结构与目标。

团队在第一间办公室工作的场景,当时办公室有白板,只是图片中未显示
多样、复杂的AI环境必不可少。Andrej提出一个不错的建议,创建一个Agent来控制Web浏览器,但这与Selenium测试工具有所冲突。我开始考虑使用VNC,以允许Agent从像素驱动整个桌面。
但我们发现,这种方法存在许多风险。例如,2013年DeepMind发布的Atari文章提出,他们花了50小时从像素训练Pong游戏,我们环境将比Pong更难。即使是做小规模实验,我们也需要花几天时间,而且不会取得任何进展。
因此,我们设定降低内部风险的目标,让Agent在1小时内学会Pong(如今我们已取得突破:10分钟内便能解决Pong遇到的问题)。
就像构建Gym时那样,我专注构建VNC系统,现称之为Universe。与Gym不同的是,该项目并非旨在支持我们现有的研究方式,而是提出全新问题。关于这一点,我们每个团队都有负责人,他们负责照顾自身团队成员,我们工程师Jie Tang已开始带头招聘。因此,行政这一重担并没有完全落在Ilya身上。这十分幸运,因为这样Ilya就能为该风险项目的首个版本构建Agent。
一个从整个动作空间随机抽样的Universe Agent(即随意点击、按键)。更多表现良好的Agent请参阅Universe发布的帖子。
Universe项目耗时相当长,因此,需要合理分配时间来运营项目。我找到一个平衡点,编码时,我会将时间进行划分。一次会议,会扼杀整个上午/下午的生产力,若上午和下午都有会议,我将精疲力竭,从而导致晚间编码效率大大降低。
我开始将会议时间,限制在清晨或午餐后,每天会议次数低于3次,隔天会议次数不超过一次。
搭建Universe本身,就是一项系统研究工作:虽然高级规范很简单(允许Agent使用键盘/鼠标/屏幕),但从来没有人尝试过构建类似的系统。长期以来,人类一直可以用VNC控制一台远程机器,但还无法实现以编程方式同时控制数十台机器。
当我们需要衡量系统的端到端延迟时,Catherine Olsson和我构建了一个系统来将时间戳嵌入图像中。有时挑战不是技术上的:当研究因为训练数据有限而受阻时,Tom Brown在24小时内就组建了一个外包团队来玩游戏。有时候挑战也可能很难以理解,比如当Jonathan Gray注意到由于外包人员的笔记本电脑CPU较低端,游戏动态可能会与AI有所不同。
一天,当我正在努力重组一些JSON基准规范时,我意识到:我们需要重新构建这些规范,因为没有人从未尝试过在数千个游戏中对单个Agent进行基准测试。
在OpenAI,做艰苦的工作也是最基本的。 在接下来几个月里,由Dario Amodei和Rafał Józefowicz负责Universe研究工作。他们都是夜猫子,我也和他们一起熬过很多个夜晚,解决研究中遇到的问题。有时我也想躺在床上睡觉,但每修复一个Bug都会使研究加速几个小时。
每个人的工作中都有一些非常有用的东西,能让研究人员提出人类此前从未有过的问题。

Universe团队在办公室开会
到发布时,Universe团队已经有约20人。Universe现在是一个旗舰项目,也是我们研究战略的核心部分。Universe的例子,恰好说明工程是如何成为当今ML研究的瓶颈,这也让我知道为什么有那么几天只想读Ian的书。
下一步发展方向
我们现在是拥有40人的公司,需要有人全力来优化团队。自OpenAI成立以来,我们一直在寻找合适的首任技术经理。几个月前,Sam向我介绍了一位特别出色的工程执行人Erika Reinhardt。
Erika曾在Planet Labs担任产品工程总监,现在和Sam一起运营voteplz.org。在Planet Labs时,Erika是对端到端卫星成像系统了解最深的人之一。她工作努力,自驱力强,总能把事情做好,前同事都说她是所能遇到的最聪明的人。Sam和我就准备邀请她加入公司。

2016年10月公司团建
但在选举会和Universe发布会上,与我们合作时,才是她最具魅力的时刻,她发现她的领导技能在这种环境中非常适用。她告诉我:在看到OpenAI在参议院举办的首次AI听证会上发言的那一刻,她就下定决定要加入OpenAI。当时OpenAI说: 我们正处于重大技术变革的开端,此时最重要就是要把握时机。
在Stripe时,Marc Hedlund和我常会遇到他在之前的许多公司中都遇到的问题,所以他喜欢开玩笑说所有公司都一样。就这一点而言,确实有现实依据: 如果将范围缩小一点,就会发现公司都是围绕一个目标来把人组织起来。但每个公司要解决的问题又不一样,这又决定了公司之间会有所差异。
大多数初创公司都是先创造出一种技术,然后随着时间推移,对其进行运营和扩展。 OpenAI是创造新技术的工厂,这意味着我们必须构建公司来创造新事物。 我们需要维护基础设施和大型代码库,但它们又满足了我们快速行动、创新和通过结合软件工程和机器学习研究来达到新高度的需求。
在OpenAI当CTO这段时光里,我做的正好是我最喜欢做的事,写代码。 但即便如此,人仍然是我关注的焦点,所以我在OpenAI的故事,是与社会的故事,而不是与技术的故事。
在未来,我们团队要继续携手并进,共同应对海因莱因短篇小说中“卡车或电话”的挑战,OpenAI才能持续发展。
在此,我向Ilya、Sam、Elon,以及为OpenAI付出过的每个人表示衷心的感谢。

OpenAI创始人的AGI预言:AI Safety、Scaling laws与GPT-20
作者:Lex Fridman、Greg Brockman
时间:2023年3月8日
来源:海外独角兽编译
字数:7,986
LLM、AIGC浪潮,将OpenAI推到台前,这家创立不到10年的公司,肉眼可见的将整个科技界卷入新范式迁移之中。OpenAI可以说是几个天才科学家、工程师,在资本支持下坚定不移探索AGI的结果。
本篇文章编译自Greg Brockman和Lex Fridman在2019年4月的一次访谈。Gerg Brockman,既是OpenAI的核心创始人之一,也是OpenAI重要灵魂人物,在OpenAI人才招聘、愿景塑造、内部Infra构建、工程文化打造等方面,提供了决定性作用。
这篇访谈的2个月前,OpenAI刚推出GPT-2,Greg认为GPT-2还可以在未来被扩大到上千倍,虽然不确定最终会得到什么,但GPT-20能力一定是实质性的。
AGI的发展,要比Greg预测得更快:3年后,GPT-3就已经将AGI愿景带入现实。除了惊讶于Greg Brockman的预言,在回看历史的过程中,我们也能够对OpenAI内部是如何认知AGI、以及如何一步步实现AGI这件事的理解更加深刻。
AGI是由人类创造的最具变革性的技术
Lex Fridman: 你如何看待人类大脑?它是一个信息处理系统、不可知的魔法或者生物化学的视角?
Greg Brockman: 把人类看作是信息处理系统,是非常有趣的视角,这也是很好的视角描述世界如何运作、大脑怎么工作。
比如目前最具变革性的创新,计算机或互联网,并不只是光缆等物理结构,而是我可以立即跟地球上任何一个人联系,能够立即检索到人类图书馆里存在的任何信息。
Lex Fridman: 所以作为人类智慧的延伸,整个社会也可以被看作是智能系统?
Greg Brockman: 这也是非常有趣的视角,经济本身也是能自我优化的超级机器,每家公司都有自己意志,每个人也有自己追求的目标。某种程度上,人类总觉得自己是地球上最聪明、最强大的生物,但有些东西比我们更重要,就是我们所组成的系统。
阿西莫夫《基地系列》有心理史学Psychohistory的概念,如果有数万亿或数千万亿生物,那么我们也许可以从宏观上预测这个生物系统会做什么,这几乎跟个人想要什么无关。
技术决定论Technological determinism也是很有趣的角度,没有人能发明出别人发明不出的技术,最多改变的是变革发生的时间。对于同类产品,某一个最终能成功的原因,可能在于初始条件不同。
比如电话是2个人在同一天发明,这意味着什么?大家都同样在巨人肩膀上创造,你不会真的创造出别人永远创造不出来的东西。如果爱因斯坦没有出生,那也会有其他人提出相对论,只是时间线不一样,可能还需要20年,但这并不会改变人类注定发现这些真理的事实。
人们正在进入通用智能技术快速发展的时代,革命性的变革一定会在某个时间点发生。我认为核心是要保证AI在正确方向上发展,放大正面效应。这也是我们在设定 OpenAI的非营利属性、以及提出OpenAI LP结构的出发点,我们需要保证AGI发生。
Lex Fridman: AGI将如何影响世界?
Greg Brockman: 回顾AI发展史,基本上在过去60~70年中,人们一直在思考,如果人类智力劳动可以自动化,会发生什么?
如果我们可以创建这样的计算机系统,世界会变成什么样?很多科幻小说讲述各种反乌托邦Anti-Utopia的故事,也有越来越多像“Her”这样的电影像我们展现乌托邦视角。

在思考AI可以带给世界什么样影响之前,我们可以先想想自行车、计算机对人类世界产生的影响,尤其是计算机对互联网影响远超过我们所能预测的,所以,如果能构建AGI,它将是人类所创造的最具变革性的技术,但我们还在寻找创建AGI系统的方法。
60~70年来,人们普遍对AI愿景感到兴奋,但现实进展并不顺利,经过两个AI寒冬后,人们似乎不再谈论AGI,但我认为这并不是AGI不存在,而是因为人们从过去AI发展的历史上吸取了足够多教训,变得更加审慎。
1959年,世界上最早的神经网络之一感知器Perceptron诞生,随即引起大规模关注,当时纽约时报发布一篇文章,认为感知器有一天可以识别人类,喊出他们名字,可以在不同语言间来回翻译。当时人们都不相信,甚至花了10年时间反对感知器发展方向,最后结果是资金枯竭、大家开始转向其他技术方向。
感知器Perceptron,是弗兰克·罗森布拉特在1957年就职于康奈尔航空实验室时,所发明的一种人工神经网络,它可被视为最简单形式的前馈神经网络,是二元线性分类器。
一直到20世纪80年代,开始新一轮技术复兴,有人说这种复兴是因为反向传播Backpropagation等算法的出现,但实际上是因为我们计算能力更加强大。
从80年代文章可以看到,计算能力民主化,意味着我们可以运行更大的神经网络,进行更多尝试,反向传播算法因此诞生。 当时运行的神经网络很小,可能只有20个神经元,因此系统的学习效果并不好。直到2012年,这种在50年代就提出的最简单、最自然的方法,才突然成为解决问题的最佳方式。
反向传播Backpropagation:误差反向传播的简称,常见的人工神经网络训练方法,在1986年提出,缺点是所需计算量较大,会随网络层数加深呈平方级提高。
20世纪80年代,是计算元器件发展的重要时期,英特尔系列微处理器与内存条技术广泛应用,让神经网络逐渐步入繁荣,并出现深度学习、卷积神经网络、循环神经网络等新技术和应用。
我认为深度学习有3个值得关注的核心属性:
1、泛化Generality, 我们用少数几个深度学习方法解决大部分问题,比如梯度下降、深度神经网络,以及一些强化学习,解决语音识别、机器翻译、游戏等所有问题。
2、能力Competence, 深度神经网络可以解决计算机视觉40年研究中的任何问题,甚至有更好效果。
3、可扩展性Scalability, 实验一次又一次向我们证明,如果有一个更大的神经网络,有更多训练数据,它工作效果会更好。
这三个属性是建立AGI基础,但并不代表只要扩大神经网络规模就能实现AGI。 但重点在于,这让我们第一次感受到AGI是可以实现,虽然时间点并不确定,但我认为肯定在我们有生之年内,并且会比人们预期早很多。
在这样远景之下,我们2015年创立OpenAI。我认为AGI可能比人们想象中更快到来,我们需要尽最大努力确保一切顺利进行,所以我们花了几年时间试图弄清楚我们需要怎么做。
OpenAI的创立与设计:确保AGI顺利发生
Lex Fridman: OpenAI如何成立?
Greg Brockman: 通常情况下,一家公司发展路径,往往先需要联合创始人构建并推出自己产品,基于产品积累到一些用户,得到相应市场反馈,如果发展顺利的话,可以通过融资,雇佣更多人,来扩大公司规模。这个过程中,几乎每家创业公司都需要面对大公司带来的潜在威胁,大公司注意到你的存在,并试图杀死你。
但OpenAI完全把这条路反过来,这和OpenAI在起步时的现实情况有关。
第一个问题,OpenAI起步太晚。
2015年OpenAI成立时,AI已经从纯粹的学术研究转变为商业领域所期待的某种具体产品或工具,和业界结合得很深。因此即便有很多优秀的学者都想建立自己实验室,但他们作为个人所积累的资源不论到达怎样的高度,都很难跟大公司相媲美,OpenAI作为初创团队更要考虑这样的问题。
我们也在担心一个现实问题,OpenAI想要建立的东西,是否真能落地?这需要一个临界质量critical mass(核物理学术语,刚好可以产生连锁反应的组合,称为已达临界点),而不只是由我和联合创始人们,合作推出一个产品即可,需要至少5~10人团队,这可能不容易,但值得尝试。
Lex Fridman: 如何看待在AGI发展中,不同公司间的竞争以及合作?
Greg Brockman: 做AGI的开发工作,弄清楚如何部署它,让它继续下去,要回答一个关键问题。
第一个是构建第一个AGI的过程。 拿自动驾驶作为对比,自动驾驶是竞争非常激烈的赛道,该领域内玩家在选择自己技术路线时面对极大压力。如果要保证技术安全性,就意味着技术实现周期会被拉长,导致的直接结果,就是很大可能落后于其他竞争者,所以大部分参与者选择相对更快的方式。
OpenAI的选择是不竞争,即便其他人领先,我们也不会走快速而危险的道路去试图跨越。 只要他们想做的和我们使命一致,我们就承诺与他们合作,帮助他们成功。如果大家都认为AGI是让每个人都受益的东西,那么哪个公司构建它并不重要。 从而形成良性的合作,实现AGI。
Lex Fridman: 如果OpenAI成功创建AGI系统,你会问它的第一个问题是什么?
Greg Brockman: 如果我们真的建立了强大到足以影响人类未来的AGI系统,我会问它的第一个问题是,如何确保AGI诞生之后,世界仍旧在正常轨道上运转。
就像核*器武**诞生后,全世界面临的最重要问题,是它会给世界带来什么样变化?如何保证核*器武**时代世界和平?
对于AGI来说,虽然它和核*器武**不同,但作为全新的变革性技术,我们同样也要确保它不会给既定的世界和社会秩序带来负面影响。
在关注新技术负面性同时,人们常常也会忽略正面影响。
既然如果我们有足够强大的AGI系统,我们肯定也需要它为我们提供建议,询问AGI,并不代表必须听从AGI的建议,但当AGI足够强大时,它所输出的信息可以被人类作为参考。
如果它像人类一样聪明,甚至它能力可扩展,人们肯定也希望它能阅读并吸收人类所有的科学文献、为绝症治疗提供方案、利用新技术创造更加丰富的物质、在保护环境等重要问题上给出建议、甚至方案。
Lex Fridman: 如何看待关于AGI可能带来的负面效应?
Greg Brockman: 这里涉及到2个问题.
首先是,如何向大众描绘新技术带来的新世界。
放在1950年,我们要向别人介绍什么是Uber,是相当困难的事情。因为我们首先需要让对方理解什么是互联网、什么是GPS,以及每个人都拥有一部智能手机这些基础前提。
所以要让大众客观评价某个变革性技术的第一个难点是,如何让他们想象出这些变革性的技术,如何在世界上发挥作用。而AGI会比之前出现过的技术都更具变革性,这一定程度上提高了人们理解门槛。
第二点,人们天然更倾向支持负面,摧毁新事物总比创造容易,不仅是在物理层面,更在思想层面,大部分人可能一看到负面消息就走进死胡同。
所以面对AGI负面效用的更积极心态,或者办法,是坦然承认AGI优点和缺点,这也是OpenAI看待AGI的态度,我们根据现实来判断风险,并基于这些判断来构建我们组织和系统。
为保证AI能够更多发挥积极效应,在OpenAI构建中,我们主要关注三方面:
第一、推进系统迭代更新能力。
在Sam Altman的AGI宣言中,Sam提到,短期内,采用快速学习和谨慎迭代的紧密反馈循环,长期看,过渡到拥有超级智能的世界。
第二、确保安全AI Safety。
OpenAI正在研究技术机制,来确保AGI系统符合人类价值观。
OpenAI一直对外强调使命是确保AGI造福全人类,AGI如果被成功创造出来,可增加世界丰富度,推动全球经济发展,帮助发现改变可能性极限的新科学知识,来帮助提升人类。
第三、政策Policy。
确保我们有一个治理机制,来反馈系统可能出现的问题。技术安全,可能是人们谈论最多的问题,比如那些反乌托邦的AI电影,很多都是由于没有良好的技术安全导致的问题。
很多人之所以认为技术安全是个棘手的问题,是因为安全本身很难被精确定义和描述的问题,在人类社会治理中,我们有很多明确的规则,例如法律、国际条约等,但同时也有一些无形的规则。 如何告诉系统哪些是安全的信息、哪些是不安全的信息,变得十分困难。
这也是OpenAI技术安全团队的重点,让系统能从数据中学习人类价值观,从而与人类伦理道德观念保持一致。可以类比到人类个体成长,婴儿会成长成好人还是坏人,很大程度取决于成长环境,以及接收到的信息质量,如果看到正面榜样,就会接收到正面反馈。我认为AGI也一样,系统可以从数据中学习,以得到符合人类伦理道德的价值观。
目前,OpenAI系统已经可以学习人类自己也无法明确描述的规则,虽然仍处于概念验证早期阶段,但OpenAI模型已经具备学习人类偏好的能力,它能够从数据中了解人类想要什么。
Lex Fridman: 《人类简史》书中一个观点,是人类世界并不存在客观真理,如果没有绝对的对与错的标准,要如何保证模型、算法持续正确?
Greg Brockman: OpenAI政策团队Policy Team,在做的工作是让模型更了解什么是对的。
GPT的确已经强大到可以回答任何用户想要知道的问题,但最重要的问题是,我们用户是谁,他们想要什么,这又会如何影响到其他人?
我们只需要类比到现实世界,就知道这件事情有多难。现实世界中不同国家、人种、文化背景的人,对世界如何运作和所崇尚的价值观,都有着不同理解。
所以对OpenAI团队,这件事不亚于新的社会治理议题,但一个强大的系统也会赋予人类更多权利。
这种情况正以不同方式发生,有一些定律也正在被改变,比如摩尔定律,摩尔定律被工业界整整信奉了50年,但最后发现还是失效。
2018年,OpenAI发布 AI and Compute,这篇研究中,提出2012年以来,最大的AI训练运行中使用的计算量呈指数级增长,从2012年到2018年研究提出该指标,增长了30多万倍,3.4个月翻一倍,摩尔定律翻倍期为2年,如果按2年翻一番,AI训练的计算量只会产生7倍增长。
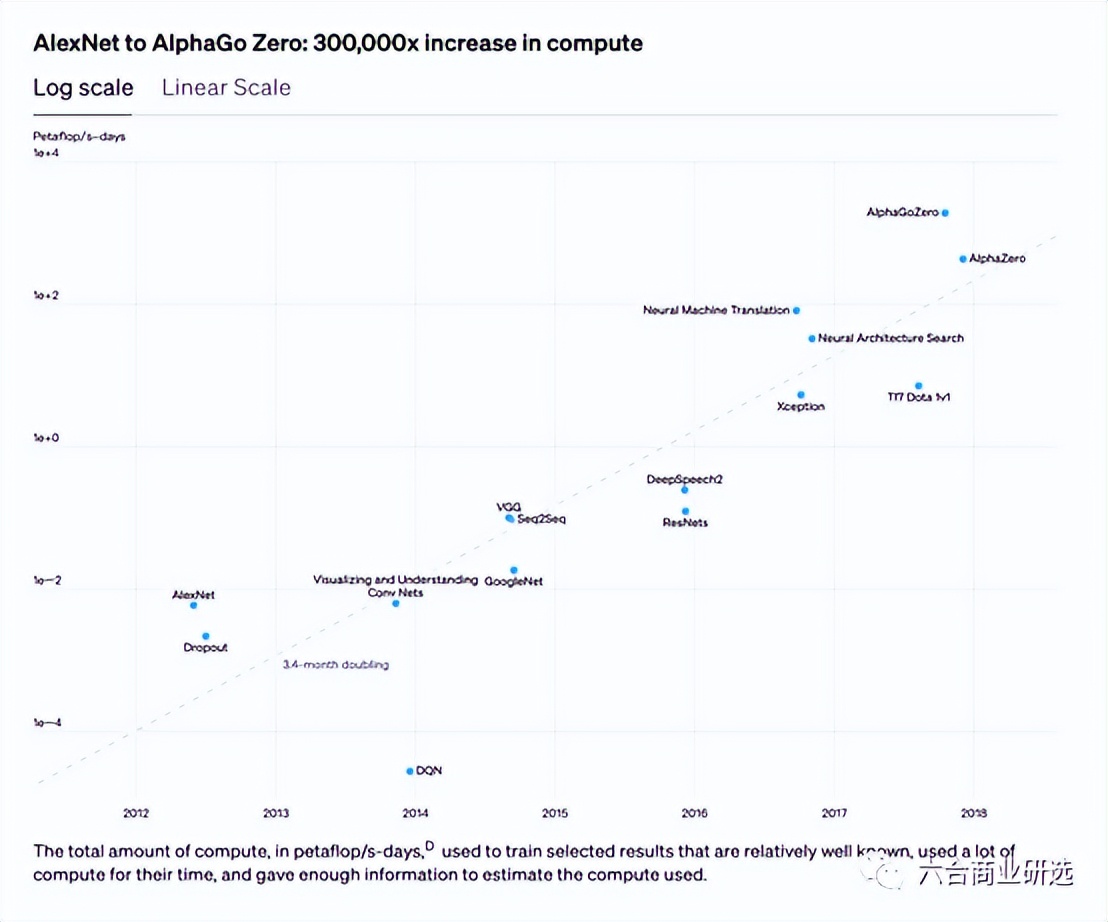
我们不能抱希望自己能发明出别人发明不出的东西,最多只能改变时间线。如果你真的想有所作为,唯一能做的就是在技术诞生之初,设定一些初始条件来确保它顺利发生。
比如,在互联网刚被发明时,也有很多竞争对手发明出类似于互联网的产品,但互联网之所以能成功,离不开它最初设定的初始条件,互联网允许人们成为任何人,以非常开放的心态联系沟通。我相信下一个40年也会继续这样发展,或许过程中也会转向,但这些初设条件对互联网成功非常重要。

如何构建真正的AGI
Lex Fridman: OpenAI最近发布GPT-2,但没有发布完整的模型,官方说明是因为担心可能会产生负面影响,这也引发社会层面讨论,这里的负面影响和积极影响分别是什么?
Greg Brockman: 我们现在正处于扩大模型的道路上,并且随着模型规模扩大而实现更好性能,GPT-2只是2018年6月GPT-1放大版。我们未来要扩大它到上千倍,不知道最终会得到什么。可能GPT-2不具有负面应用,但GPT-20能力会是实质性的。
GPT-2潜在负面影响,在于它可能会导致产生假新闻或滥用内容。 比如一定会有人尝试在GPT-2基础上使用自己Facebook消息历史记录,来生成更多Facebook消息,进一步,这种行为就会带来生成制作虚假的社会性、政治性议题政治家内容的可能性。
正面影响是,GPT-2的确带来有很多很棒的应用程序。 开发者可以使用GPT-2来衍生出很多很酷的想法。很多人写信给我们,希望能把它用于各种不同创意应用。
GPT-2推出后带来的应用场景包括:
1、文本生成: GPT-2 Poetry;GPT-2 Dungeons and Dragons character bios。
2、聊天机器人: Thomas Wolf团队在PERSONA-CHAT数据集上微调了GPT-2,建立了带有角色个性的聊天机器人。
3、机器翻译。
4、文字总结: 在CNN、《每日邮报》的数据集上进行测试。
所以如果要真正考虑安全性,对于GPT-2,是否公开发布各有利弊,但未来模型的到来可能比预期要快,扩大模型并不需要很长时间,未来模型是绝对不能公开发布的内容。我们把不公开发布GPT-2视为测试,实现社会心智的过渡。
GPT-20是Greg在当时对模型能力能够达到质变节点的预测,从后视镜视角来看,Greg对于模型参数量扩大后的能力提升预测还是相对保守,因为在3年后,GPT-3就已实现这样的目标。
Lex Fridman: 你认为到GPT-20的时候,世界是什么样?就像在20世纪50年代,人们试图描述互联网或智能手机。 我们将成功设计识别机器人与人类系统,还是人类不得不接受并习惯充斥着假新闻的世界?
Greg Brockman: 有个十分流行meme可以用来回答这个问题:一只机器人物理手臂,正在点击我不是机器人的身份验证按钮。
我认为人类最终无法区分机器人和人类。 不可否认的是,人们在未来所获取的信息中,有一部分一定是通过自动生成的,因为AI足够强大,以至人们无法分辨出人类和人工智能分别产出的信息间的差异,甚至最有说服力的论点反而是由AI提出。

Lex Fridman: 你认为语言模型最终可以发展到什么程度?类似于电影Her里面。人类与AI通过自然语言的多轮对话,可以通过这种无监督模型来实现吗?
Greg Brockman: 大语言模型应该能真正理解微积分,并解决新的微积分问题。 我们需要的不仅是语言模型,而是解释和推理的方法。
语言建模实际上已经走得比许多人预期的要远。GPT-2还没有来自于自身的动态经验,只是一些可供学习的静态数据,所以它对物理世界的理解程度很浅。 如果我们能让它真实理解物理世界,就已经相当常令人兴奋。
但如果仅只是扩大GPT-2,也并不足够让模型具备推理能力。 人类是通过思考产生新的想法、获得更好答案,并且思考的过程一定会花费大量计算能力,这种模式没有被编码在GPT中。分布式泛化distribution generalization也很有趣。对人类来说,即便有些时候没有经历过某件事,但也会对这件事有基本的思考与理解,这与推理有关。
为真正构建AGI,一方面需要在计算规模上尽可能推进,另一方面还需要在人类自身思考和认知的实质性推进。
我们应该找到可扩展的方式,投入更多计算、更多数据,让它变得更好。 我们之所以对深度学习、构建AGI潜力感到兴奋,部分原因是因为我们研究出了最成功的AI系统,并且意识到如果扩大这些系统的规模,它们会更好工作。可扩展性给了我们构建变革性系统的希望。
Lex Fridman: 创建AGI或一些新的模型过程中,如何在它们还只是原型阶段时,就发现它们潜在价值?如何能够在没有规模化情况下坚持这些想法?
Greg Brockman: 我们自己就是很好的案例。OpenAI在2018年6月28日发布GPT,后来我们将其放大到GPT-2。在小范围内,GPT创造了一些记录,它不像GPT-2那样令人惊艳,但它很有希望。
但有时规模化后,与我们在小范围内看到的内容有质的不同。 最初发明者会说,我不认为它能做到这一点,这就是在Dota看到的。Dota基本上只是大规模运行近端策略优化算法PPO(Proximal Policy Optimizaion,PPO提出了新的目标函数,可以在多个训练步骤实现小批量更新,解决了Policy Gradient算法中步长难以确定的问题)。 长期来看,这些行为在我们认为不可能的时间尺度上真正发挥作用。
Lex Fridman: 随着GPT规模不断扩大,可能人们会看到更加令人惊讶的结果,很难看到一个想法在规模化后会走多远。
Greg Brockman: Dota和PPO是一个非常具体的例子。关于Dota,有一件事非常令人激动,人们并没有真正注意到,那就是分布中泛化的法令(the decree of generalization out of distribution),它被训练来对抗其他AI玩家。
Lex Fridman: 未来几年,深度学习将走向何方?强化学习的方向在哪?对于OpenAI,2019年你会更关注哪些方面?
Greg Brockman: 规模化的开展更多创新的项目。
OpenAI内部有一个项目的生命周期。 先从几个人开始,基于一个小的idea展开工作,语言模型就是好的例子。一旦在过程中得到一些有意思的发现和反馈,我们就扩大规模,让更多人参与其中,同时投入更多计算资源。最终状态会像Dota,由10或15人组成的大型团队,以非常大的规模运行事情。将工程和机器学习科学结合在一起,形成一个系统,展开工作,并获得实质性结果。整个生命周期,端到端,需要2年左右时间才能完成。
OpenAI内部也有更长生命周期项目。我们正在组建一个推理团队去解决神经网络推理这件事,这会是长期、但一定有超预期回报的项目。
Lex Fridman: 讲讲Dota的训练过程。
Greg Brockman: Dota项目,是我们迈向现实世界的重要一步,相对象棋、围棋等其他游戏,Dota作为一个复杂游戏,连续性更强,在45分钟游戏中,玩家可以进行不同动作和策略组合。Dota的所有硬编码(hard coding,将数据直接嵌入到程序或其他可执行对象的源代码中的软件开发实践,而不是从外部获得数据或在运行时生成数据),机器人都很糟糕,因为它太复杂了。所以这是一个推动强化学习最新技术的好方向。
我们在2017年在Dota 1V1对战中,成功击败世界冠军。
学习技能曲线,是一个指数函数,我们一直在扩大规模,修复错误,从而获得稳定的指数级进展。
Lex Fridman: Dota是非常受欢迎的游戏,在全世界有很多资深的人类玩家,所以在OpenAI和人类的Dota 1V1对战中,要获得成功的基准,是非常高的,最初是怎么训练这些AI的?
Greg Brockman:我们使用的方法是自训练。 我们设置了两个没有任何经验的Dota AI玩家,他们互相争斗,不断发现新的对战技巧、继续斗争。之后我们从1V1扩大到5V5,继续学习团队行动中需要做的协调,在5V5版本游戏中达到专业水平,难度指数级上升。
这件事与昆虫的训练方式有很多共同点。但昆虫在这种环境中生活了很长时间,并且有很多经验。站在人类角度看,昆虫并不聪明,但昆虫其实能够很好驾驭它所处的环境,甚至处理周围环境中从未见过的意外事情,我们在AI Dota玩家上,看到了同样事情。这个游戏中,他们能够与人类对战,这在其进化环境中从未存在过。
人类与AI的游戏风格完全不同,但AI依然能很好处理这些情况。这没有从较小规模的PPO中出现。之后,我们运行10万个CPU内核、数百个GPU,这个规模是巨大的,我们开始从算法中看到非常不同的行为。
Lex Fridman: Dota在1V1比赛中打败世界冠军,但目前还没有赢得5V5的多人比赛。2019年接下来几个月,会有什么变化?
Greg Brockman: OpenAI Dota团队,一直在与比我们模型更好的玩家进行比赛,虽然我们最终输掉两场比赛,但这也确实表明我们已处于专业水平。我们内部很相信它在未来会取得进一步胜利。
但其实赢或输,与我们思考即将发生事情的方式无关。因为我们目标并不是在Dota比赛中击败人类,而是推动强化学习达到最先进水平,所以某种程度上我们已经做到这一点。
【长期主义】栏目每周六、与长假更新,分以下系列:
宏观说:全球各大国政要、商业领袖等
社会说:比尔·盖茨等
成长说:洛克菲勒、卡内基等
科学说:历年诺奖获得者、腾讯科学WE大会等
科技说:马斯克、贝索斯、拉里·佩奇/谢尔盖·布林、扎克伯格、黄仁勋、Vitalik Buterin、Brian Armstorng、Jack Dorsey、孙正义、华为、马化腾、张小龙、张一鸣、王兴等
投资说:巴菲特、芒格、Baillie Giffrod、霍华德·马克斯、彼得·蒂尔、马克·安德森、凯瑟琳·伍德等
管理说:任正非、稻盛和夫等
能源说:曾毓群等
汽车说:李想、何小鹏、王传福、魏建军、李书福等
智能说:DeepMind、OpenAI等
元宇宙说:Meta/Facebk、苹果、微软、英伟达、迪士尼、腾讯、字节跳动、EpicGames、Roblox、哔哩哔哩/B站等
星际说:中国国家航天局、NASA、历年国际宇航大会,SpaceX、Starlink、蓝色起源、维珍银河等
军事说:全球主要航空航天展等
消费说:亚马逊、沃尔玛、阿里、京东、拼多多、美团、东方甄选等
每个系列聚焦各领域全球顶尖高手、产业领军人物,搜集整理他们的致股东信、公开演讲/交流、媒体采访等一手信息,一起学习经典,汲取思想养分,做时间的朋友,做长期主义者。
相关研报:
人类未来文明三部曲之一:元宇宙专题预售开启,59期45万字
九宇资本赵宇杰:1.5万字头号玩家年度思考集,科技创新,无尽前沿
九宇资本赵宇杰:1.5万字智能电动汽车年度思考集,软件定义,重塑一切
【重磅】前沿周报:拥抱科技,洞见未来,70期合集打包送上
【重磅】*合六**年度报告全库会员正式上线,5年多研究成果系统*交性**付
【智能电动汽车专题预售】百年汽车产业加速变革,智能电动汽车时代大幕开启
【头号玩家第一季预售】:科技巨头探索未来,头号玩家梯队式崛起
【头号玩家第二季预售】:科技创新带来范式转换,拓展无尽新边疆
【首份付费报告+年度会员】直播电商14万字深度报告:万亿级GMV风口下,巨头混战与合纵连横
【重磅】科技体育系列报告合集上线,“科技+体育”深度融合,全方位变革体育运动
【重磅】365家明星公司,近600篇报告,*合六**君4年多研究成果全景呈现
九宇资本赵宇杰:CES见闻录,开个脑洞,超级科技巨头将接管一切
【万字长文】九宇资本赵宇杰:5G开启新周期,进入在线世界的大航海时代|GBAT 2019 大湾区5G峰会
九宇资本赵宇杰:抓住*子烟电**这一巨大的趋势红利,抓住产业变革中的变与不变
【IPO观察】第一季:中芯国际、寒武纪、思摩尔、泡泡玛特、安克创新等11家深度研报合集
【IPO观察】第二季:理想、小鹏、贝壳、蚂蚁、Snowflake、Palantir等12家公司深度研报合集
【IPO观察】第三季:Coinbase、Roblox、快手、雾芯科技等12家公司深度研报合集
【重磅】年度观察2019系列合集:历时3个多月,超20万字近500页,复盘过去,展望未来,洞悉变与不变
【珍藏版】*合六**宝典:300家明星公司全景扫描,历时3年,210万字超5,000页,重磅推荐
九宇资本赵宇杰:对智能电动汽车产业的碎片化思考
九宇资本赵宇杰:九宫格分析法,语数外教育培训领域的道与术
【2023回乡见闻录】90、00后小伙伴们万字记录,生活回归正轨,春节年味更浓
【2022回乡见闻录】20位90、00后2万字,4国13地,全方位展现国内外疫情防疫、春节氛围、发展现状差异
【2021回乡见闻录】22位90后2万字,就地过年与返乡过年碰撞,展现真实、立体、变革的中国
【2020回乡见闻录】20位90后2万字,特殊的春节,时代的集体记忆
【重磅】22位“90后”2万字回乡见闻录,讲述他们眼中的中国县城、乡镇、农村
*合六**君3周岁生日,TOP 60篇经典研报重磅推荐
下午茶,互联网世界的三国杀
5G助推AR开启新产业周期,AR眼镜开启专用AR终端时代
新商业基础设施持续丰富完善,赋能新品牌、新模式、新产品崛起,打造新型多元生活方式
【重磅】中国新经济龙头,赴港赴美上市报告合辑20篇
知识服务+付费+音频,开启内容生产新的产业级机遇,知识经济10年千亿级市场规模可期
从APP Store畅销榜4年更替,看内容付费崛起
新三板,我们有个九宇会家族
新三板破万思考:新三板日交易量10年100倍?
九宇资本赵宇杰:科技改变消费,让生活更美好|2017 GNEC 新经济新消费峰会
九宇资本赵宇杰:创业时代的时间法则,开发用户平行时间|2016 GNEC 新经济新智能峰会
九宇资本赵宇杰:互联网引领新经济,内容创业连接新生态|2016 GNEC 新经济新营销峰会
请务必阅读免责声明与风险提示
