Steven-Hewitt著fastai马老师译
引言
我们邀请您在GitHub*访上**问相应的Python代码和iPython笔记本。
https://github.com/Steven-Hewitt/QA-with-Tensorflow
定义超参数
现在,我们已经充分准备了我们的训练数据和我们的测试数据。接下来的任务是构建我们将用来理解数据的网络。让我们从清除TensorFlow默认图表开始,所以如果我们想改变某些东西,我们总是可以选择再次运行网络。

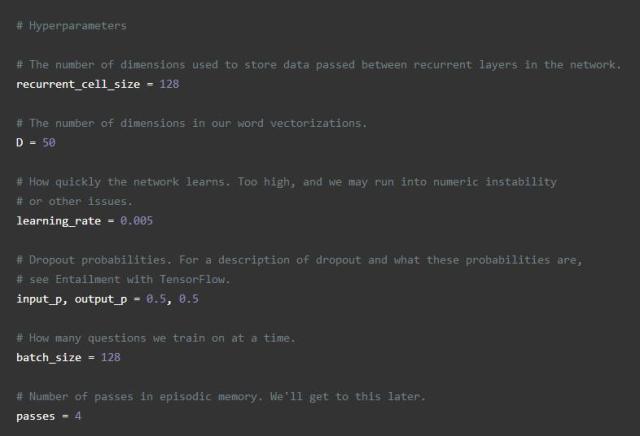
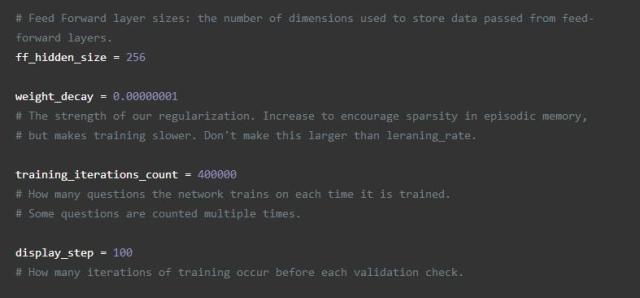
由于这是实际网络的开始,我们还要定义网络所需的所有常量。我们称之为“超参数”,因为它们定义了网络的外观和训练方式:
网络结构
通过超参数,我们来描述网络结构。这个网络的结构松散地分成四个模块,并且在Ask Me Anything:Dynamic Memory Networks for Natural Language Processing中有描述。
该网络的设计是基于文本中的其他信息来动态设置循环图层的内存,因此名称为动态存储网络(DMN)。DMN松散地基于对人类如何回答阅读理解型问题的理解。首先,人们有机会阅读上下文,并产生对事实的回忆。考虑到这些事实,然后他们阅读这个问题,重新审视上下文来寻找这个问题的答案,把这个问题与每个事实进行比较。
有时,一个事实引导我们到另一个。在bAbI数据集中,网络可能想要找到足球的位置。它可能会搜索有关足球的句子,发现John是最后一个接触足球的人,然后搜索关于John的句子,发现John已经在卧室和走廊里。一旦意识到John一直在走廊里,那么就可以回答这个问题,自信地说足球就在走廊里。
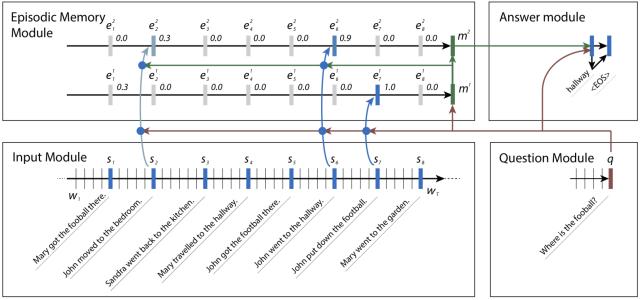
图3.网络中的模块一起工作以解决bAbI问题。在每一集中,都有新的事实,所以他们可以帮助想出答案。Kumar指出,网络不正确地把一些权重放在第2句,这是有道理的,因为John已经在那里,即使当时他没有足球。
输入
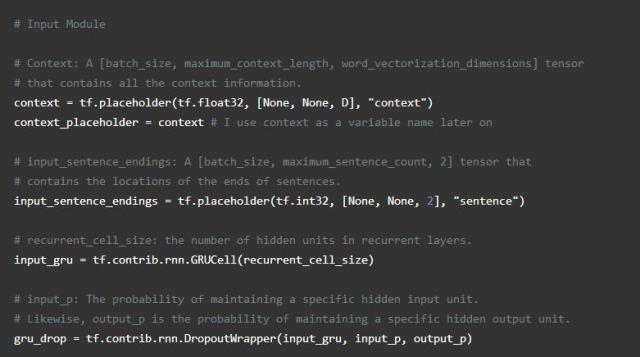
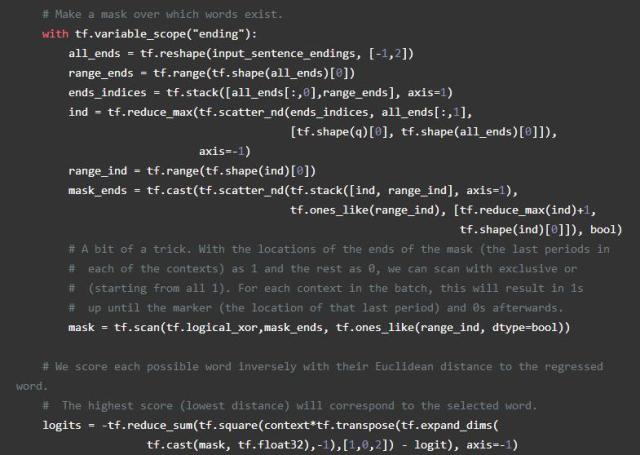
输入模块是一个动态存储网络使用来给出答案的四个模块的第一个,用门控循环单元简单地传递输入,或GRU(tf.contrib.nn.GRUCell)收集证据。每条证据或事实都对应于上下文中的单个句子,并由该时间步的输出表示。这需要一些非TensorFlow预处理,所以我们可以收集句子末尾的位置,并将其传递给TensorFlow,以便在以后的模块中使用。
稍后,我们将在训练时关注外部处理。我们可以使用处理过的数据调用TensorFlow中的gather_nd来选择相应的输出。函数gather_nd是一个非常有用的工具,我建议您查看API文档以了解它是如何工作的。

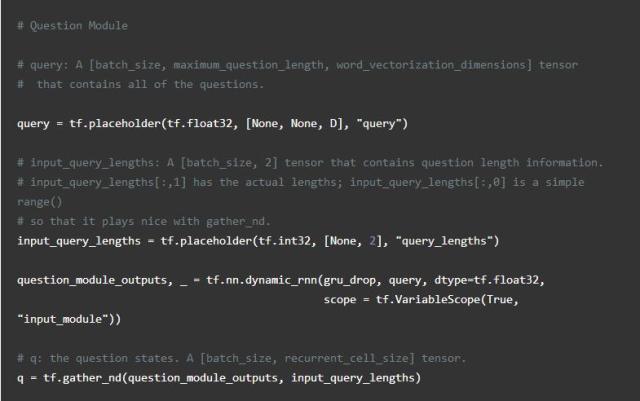
问题
问题模块是第二个模块,可以说是最简单的。它由另一个GRU传递,是这个问题的文本。我们可以简单地传递最终状态,而不是一些证据,因为问题由数据集保证是一个句子长。
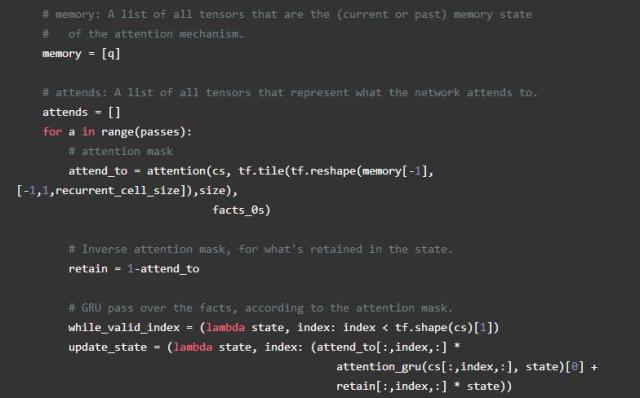
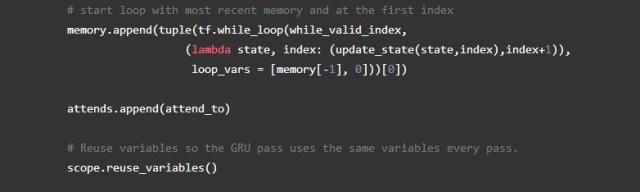
情节记忆
我们的第三个模块,情节记忆模块,是事情开始变得有趣的地方。它使用注意力进行多次传递,每次传递由GRU组成,迭代输入。根据当时对相应事实的关注程度,在每次传递中每次迭代都会对当前记忆进行加权更新。
注意
神经网络中的注意力最初是为图像分析而设计的,特别是在图像中某些部分比其他部分更相关的情况下。网络使用注意力来确定执行任务时进行进一步分析的最佳位置,例如查找图像中的对象位置,跟踪在图像之间移动的对象,面部识别或其他从查找最相关信息中受益的图像中的任务。
主要的问题是注意力,或者至少是硬注意力(注意到一个输入位置)不容易优化。与大多数其他神经网络一样,我们的优化方案是计算关于输入和权重的损失函数的导数,由于其二元性质,硬注意力根本不可微分。相反,我们被迫使用被称为“软注意”的实值版本,它使用某种形式的权重将所有可能被关注的输入位置结合起来。谢天谢地,权重是完全可以区分的,可以正常训练。虽然有可能学习注意力,但比软注意力要困难得多,有时甚至更糟糕。因此,我们会坚持这种模式的软注意力。不要担心编码衍生物,TensorFlow的优化方案为我们做这些。
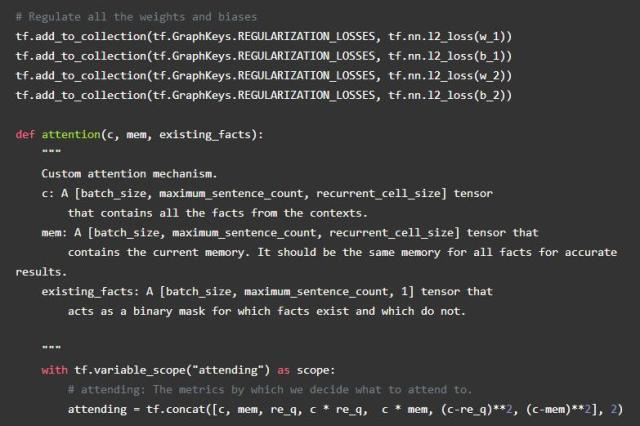
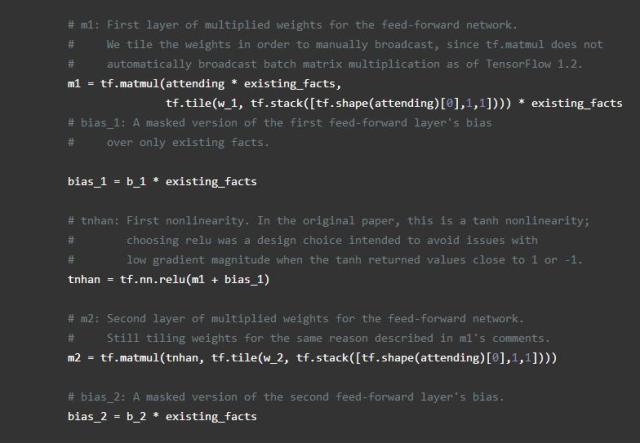
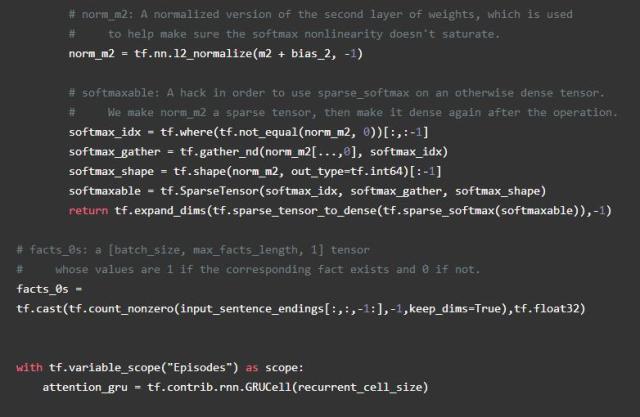
我们通过构建每个事实,当前的记忆和原始问题之间的相似似度量来计算这个模型中的注意力。(请注意,这与正常注意力不同,它只构成事实与当前记忆之间的相似性度量)。我们将结果通过双层前馈网络传递给每个事实以获得注意力常量。然后,我们通过GRU对输入事实进行加权传递来修改存储(由相应的注意力常数加权)。为了避免当上下文短于矩阵的全部长度时将不正确的信息添加到存储中,我们创建了一个事实存在的掩码,并且当事实不存在的时候根本不参加(即保留相同的存储)。
另一个值得注意的方面是注意力掩码几乎总是围绕在一个图层使用的表示。对于图像来说,这个围绕最有可能发生在卷积层(很可能是一个直接映射到图像中的位置),对于自然语言来说,这个围绕最可能发生在一个循环层周围。在技术上可能的情况下,围绕前馈层的注意力通常是无用的—至少是一个能通过其他前馈层更容易模拟的方式。

答案
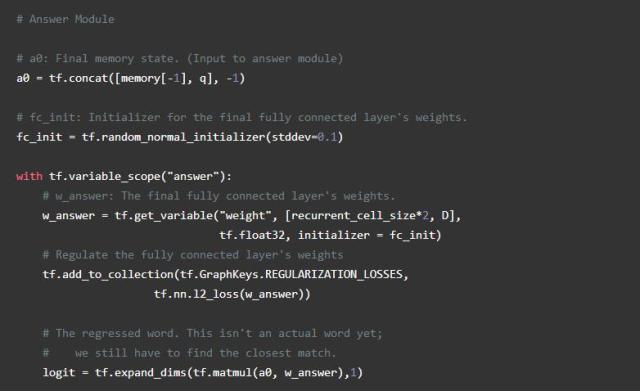
最后的模块是答案模块,从问题和情节记忆模块的输出中使用全连接层到“最终结果”单词向量,并且距离结果最近的单词是我们的最终结果输出(保证结果是一个实际的字)。我们通过为每个单词创建一个“分数”来计算最接近的单词,这表示最终结果与单词的距离。虽然您可以设计一个可以返回多个单词的答案模块,但是在本文中尝试的bAbI任务中并不是必需的。
未完待续ing
fastai深度学习社区