
Source: TheDigitalArtist at pixabay.com
我正在进行的有关在创业公司建立数据科学学科的系列文章的第三部分。 您可以找到引言中所有文章的链接,以及在亚马逊上基于该系列的书籍。
建立数据管道是创业公司数据科学的核心组成部分。 为了构建数据产品,您需要能够从数百万个用户那里收集数据点并以接近实时的方式处理结果。 在我之前的博客文章中讨论了要收集什么类型的数据以及如何将数据发送到端点时,本文将讨论如何处理已收集的数据,从而使数据科学家能够处理数据。 即将发布的有关模型生产的博客文章将讨论如何在此数据平台上部署模型。
通常,数据管道的目标是数据湖,例如Hadoop或S3上的Parquet文件,或关系数据库,例如Redshift。 理想的数据管道应具有以下属性:
· 低事件延迟:在事件被发送到数据收集端点的几分钟或几秒钟之内,数据科学家应该能够查询管道中的最新事件数据。 这对于测试目的和构建需要近实时更新的数据产品很有用。
· 可扩展性:数据管道应能够扩展到数十亿个数据点,并且随着产品规模的扩展可能达到数万亿个。 一个高性能的系统不仅应该能够存储此数据,而且还应使完整的数据集可用于查询。
· 交互式查询:功能强大的数据管道应支持长期运行的批处理查询和较小的交互式查询,使数据科学家能够浏览表并了解架构,而无需在采样数据时花费数分钟或数小时。
· 版本控制:您应该能够对数据管道和事件定义进行更改,而不会降低管道和造成数据丢失。 这篇文章将讨论在更改事件模式的情况下如何构建支持不同事件定义的管道。
· 监视:如果不再接收事件,或不再接收特定区域的跟踪数据,则数据管道应通过诸如PagerDuty之类的工具生成警报。
· 测试:您应该能够使用测试事件来测试数据管道,这些事件不会出现在数据湖或数据库中,但是会测试管道中的组件。
数据管道应具有许多其他有用的属性,但这是启动的良好起点。 当您开始构建依赖于数据管道的其他组件时,您将需要设置工具来实现容错和自动化任务。
这篇文章将展示如何建立可伸缩的数据管道,该管道将跟踪数据发送到数据湖,数据库和订阅服务以供数据产品使用。 我将讨论管道中不同类型的数据,数据管道的演变,并逐步介绍在GCP上使用PubSub,DataFlow和BigQuery实施的示例管道。
在部署数据管道之前,您需要回答以下问题,这些问题类似于我们有关跟踪规范的问题:
· 谁拥有数据管道?
· 哪些团队将使用数据?
· 谁将对管道进行质量检查?
在小型组织中,数据科学家可能负责管道,而大型组织通常具有负责保持管道正常运转的基础架构团队。 了解哪些团队将使用数据也很有用,这样您就可以将数据流传输到适当的团队。 例如,营销可能需要登陆页面访问的实时数据来执行营销活动的归因。 最后,应定期检查传递给管道的事件的数据质量。 有时,产品更新会导致跟踪事件删除相关数据,因此应该设置一个过程来捕获这些类型的数据更改。
数据类型
管道中的数据通常基于已执行的修改量以不同的名称引用。 数据通常使用以下标签进行分类:
· 原始数据:正在跟踪数据,未应用任何处理。 这是以消息编码格式存储的数据,该消息编码格式用于发送跟踪事件,例如JSON。 原始数据尚未应用架构。 通常将所有跟踪事件作为原始事件发送,因为所有事件都可以发送到单个端点,并且架构可以稍后在管道中应用。
· 处理的数据:处理的数据是原始数据,已将其解码为事件特定格式,并应用了模式。 例如,已转换为具有固定模式的会话开始事件的JSON跟踪事件被视为已处理数据。 处理后的事件通常存储在数据管道中的不同事件表/目标中。
· 煮熟的数据:已汇总或汇总的处理过的数据称为煮熟的数据。 例如,处理后的数据可以包括会话开始和会话结束事件,并且可以用作摘要用户的日常活动(例如会话数和网页的网站总时间)的摘要数据的输入。
数据科学家通常将处理已处理的数据,并使用工具为其他团队创建已煮熟的数据。 这篇文章将讨论如何构建输出处理过的数据的数据管道,而商业智能文章将讨论如何将熟数据添加到管道中。
数据管道的演变
在过去的二十年中,收集和分析数据的格局发生了巨大变化。 现代系统无需通过日志文件在本地存储数据,而是可以实时跟踪活动并应用机器学习。 初创企业可能希望使用较早的方法之一进行初始测试,但实际上应该使用更新的方法来构建数据管道。 根据我的经验,我注意到了四种不同的管道方法:
· 平面文件时代:数据保存在游戏服务器本地
· 数据库时代:将数据暂存在平面文件中,然后加载到数据库中
· 数据湖时代:数据存储在Hadoop / S3中,然后加载到数据库中
· 无服务器时代:托管服务用于存储和查询
此演变过程中的每个步骤都支持收集更大的数据集,但可能会带来额外的操作复杂性。 对于初创公司而言,目标是能够在不扩展运营资源的情况下扩展数据收集,并且向托管服务的演进为增长提供了一个不错的解决方案。
我们将在本文的下一部分中介绍的数据管道基于最新的数据管道时代,但是通过不同的方法进行导航很有用,因为针对不同公司的需求可能更适合于不同的体系结构。
平面文件时代
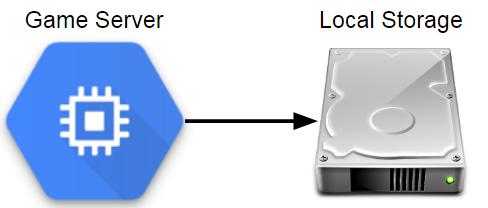
Components in a pre-database Analytics Architecture
在EA建立围绕数据的组织之前,我于2010年开始在Electronic Arts从事数据科学工作。 尽管许多游戏公司已经在收集有关游戏玩法的大量数据,但大多数遥测是以日志文件或其他平面文件格式存储在游戏服务器本地的。 无法直接查询任何内容,因此计算基本指标(例如月活跃用户(MAU))花费了大量精力。
在Electronic Arts,Madden NFL 11内置了重播功能,该功能提供了游戏遥测的意外来源。 每个游戏结束后,将XML格式的游戏摘要发送到游戏服务器,该服务器列出了每个被调用的游戏,在游戏过程中采取的动作以及失败的结果。 这产生了数百万个文件,可以对其进行分析,以了解更多有关球员在野外如何与Madden足球互动的信息。
到目前为止,在收集游戏数据时,将数据存储在本地是最简单的方法。 例如,上一篇文章中介绍的PHP方法对于设置轻量级分析端点很有用。 但是这种方法确实有明显的缺点。
这种方法很简单,使团队能够以所需的任何格式保存数据,但是没有容错能力,不会将数据存储在中央位置,数据可用性具有显着的延迟,并且具有用于构建用于分析的生态系统的标准工具。 如果您只有几个服务器,则平面文件可以正常工作,但是,除非您将文件移动到中央位置,否则它实际上不是分析管道。 您可以编写脚本将数据从日志服务器提取到中央位置,但这通常不是可扩展的方法。
数据库时代
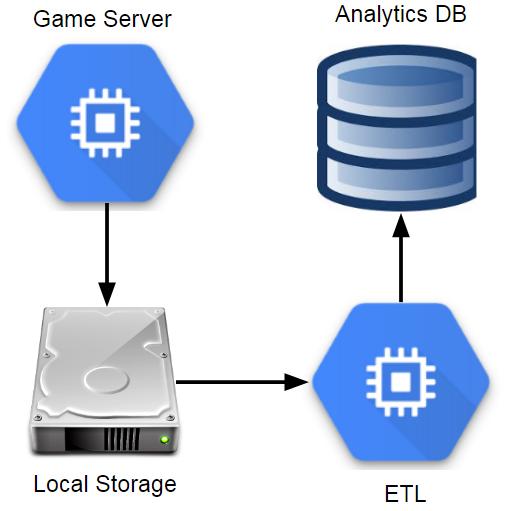
Components in an ETL-based Analytics Architecture
当我在索尼在线娱乐公司时,我们让游戏服务器每隔几分钟将事件文件保存到一个中央文件服务器中。 然后,文件服务器大约每小时进行一次ETL流程,以将这些事件文件快速加载到我们的分析数据库中,该数据库当时为Vertica。 从游戏客户端向我们的分析数据库中可查询的数据发送事件到游戏客户端大约一个小时后,此过程就有一个合理的延迟。 它也可以扩展到大量数据,但是需要为事件数据使用固定的架构。
当我还是Twitch时,我们对其中一个分析数据库使用了类似的流程。 与SOE的方法的主要区别在于,我们使用Amazon Kinesis将事件从服务器流式传输到S3上的暂存区域,而不是将游戏服务器的scp文件存储到中央位置。 然后,我们使用ETL流程将数据快速加载到Redshift中进行分析。 从那时起,Twitch开始转向数据湖方法,以便扩展到更大的数据量并提供更多的选项来查询数据集。
SOE和Twitch所使用的数据库对两家公司都非常有价值,但是在扩展存储的数据量时,我们确实遇到了挑战。 随着我们收集有关游戏玩法的更多详细信息,我们不再能够在表中保留完整的事件历史记录,而需要截断几个月前的数据。 如果您可以设置汇总表来维护有关这些事件的最重要的详细信息,那很好,但这不是理想的情况。
这种方法的问题之一是登台服务器成为故障的中心点。 一个游戏发送太多事件,导致事件在所有游戏中被丢弃的情况下,也可能出现瓶颈。 另一个问题是随着您扩大使用数据库的分析师数量,查询性能。 一个由数名分析师组成的团队使用几个月的游戏数据可能会很好,但是在收集了数年的数据并增加了分析师的数量之后,查询性能可能会成为一个严重的问题,导致某些查询要花费数小时才能完成。
这种方法的主要优点是,所有事件数据都可以在一个位置使用SQL查询,并且可以使用诸如Tableau和DataGrip之类的强大工具来处理关系数据库。 缺点是将所有数据加载到Vertica或Redshift这样的数据库中非常昂贵,事件需要具有固定的架构,并且可能需要截断表以保持服务器的性能。
使用数据库作为数据的主要接口的另一个问题是,无法有效使用机器学习工具(例如Spark的MLlib),因为需要先从数据库中加载相关数据,然后才能对其进行操作。 克服此限制的方法之一是将游戏数据以与大数据工具配合使用的格式和存储层存储,例如将事件另存为S3上的Parquet文件。 在下一个时代,这种类型的配置变得越来越普遍,并且摆脱了需要截断表的限制,并降低了保留所有数据的成本。
数据湖时代
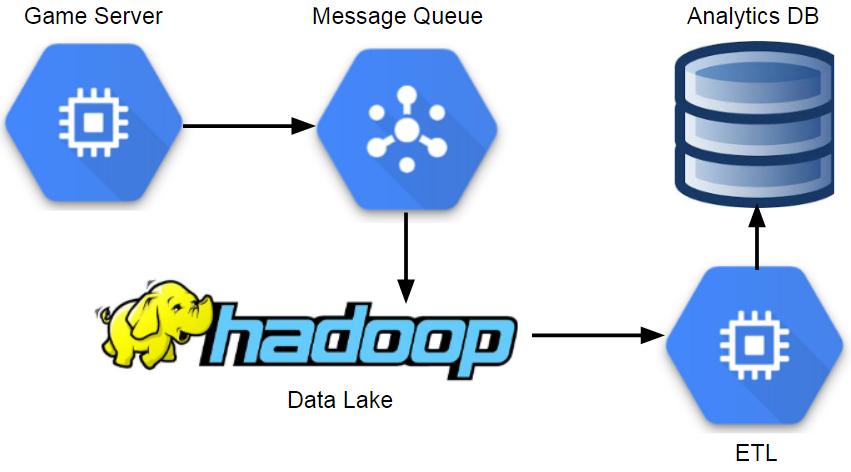
Components in a Data Lake Analytics Architecture
我在游戏行业担任数据科学家时最常见的数据存储模式是数据湖。 一般模式是将半结构化数据存储在分布式数据库中,并运行ETL流程以将最相关的数据提取到分析数据库。 分布式数据库可以使用许多不同的工具:在Electronic Arts中,我们使用Hadoop;在Microsoft Studios中,我们使用Cosmos;在Twitch中,我们使用S3。
这种方法使团队可以扩展到海量数据,并提供额外的容错能力。 主要缺点是,它引入了额外的复杂性,并且由于缺少工具或访问策略,与使用传统数据库方法相比,可能导致分析师访问的数据更少。 大多数分析师将使用从数据湖ETL填充的分析数据库,以该模型中的相同方式与数据进行交互。
这种方法的优点之一是它支持各种不同的事件模式,并且您可以更改事件的属性而不会影响分析数据库。 另一个优势是分析团队可以使用Spark SQL等工具直接与数据湖合作。 但是,在我工作的大多数地方,都只能访问数据湖,这消除了此模型的许多好处。
这种方法可扩展到大量数据,支持灵活的事件模式,并为长时间运行的批处理查询提供了很好的解决方案。 不利的一面是,这可能会涉及大量的运营开销,可能会引入大事件延迟,并且可能缺少面向数据湖最终用户的成熟工具。 这种方法的另一个缺点是通常只需要一个团队来保持系统正常运行。 这对于大型组织来说是有意义的,但对小型公司而言可能是过大了。 在不增加运营开销的情况下利用数据湖的一种方法是使用托管服务。
无服务器时代
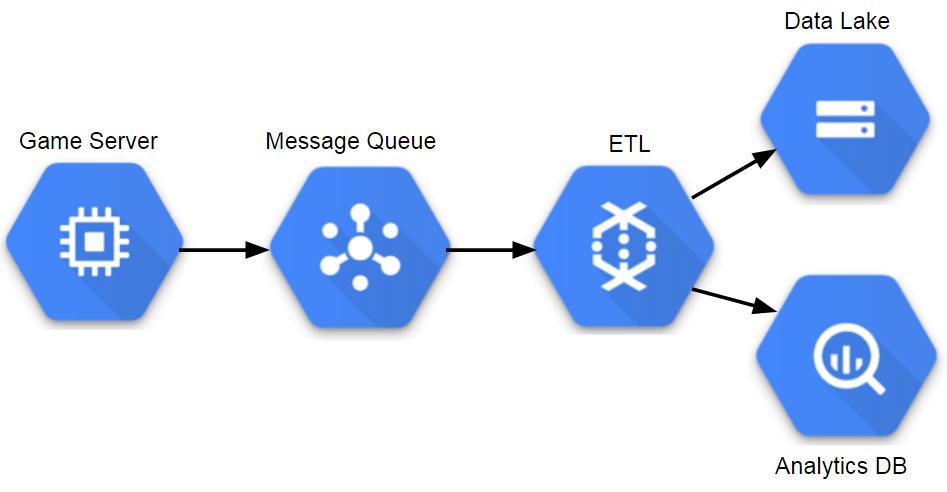
Components in a managed Analytics Architecture (GCP)
在当前时代,分析平台集成了许多托管服务,这些服务使团队能够近乎实时地处理数据,根据需要扩展系统并减少维护服务器的开销。 在游戏行业工作时,我从未经历过这个时代,但看到了这种转变的迹象。 Riot Games正在将Spark用于ETL流程和机器学习,并且需要按需扩展基础架构。 一些游戏团队正在将弹性计算方法用于游戏服务,并且也可以将这种方法用于分析。
这种方法具有与使用数据湖相同的许多优点,可以基于查询和存储需求自动扩展,并且具有最小的运营开销。 主要缺点是托管服务可能很昂贵,采用这种方法很可能会导致使用无法移植到其他云提供商的特定于平台的工具。
在我的职业生涯中,使用数据库时代方法取得了最大的成功,因为它为分析团队提供了访问所有相关数据的权限。 但是,这并不是一个可以继续扩展的设置,自那以后,我工作的大多数团队都转移到了数据湖环境中。 为了使数据湖环境成功,分析团队需要访问基础数据和成熟的工具以支持其流程。 对于初创企业而言,无服务器方法通常是开始建立数据管道的最佳方法,因为它可以扩展以适应需求,并且需要最少的人员来维护数据管道。 下一节将逐步构建带有托管服务的示例管道。
可扩展的管道
我们将建立一个数据管道,以Google的PuSub作为端点来接收事件,并将事件保存到数据湖和数据库中。 这里介绍的方法会将事件另存为原始数据,但我还将讨论将事件转换为已处理数据的方法。
执行所有这些功能的数据管道相对简单。 管道从PubSub读取消息,然后将事件转换为持久性:管道的BigQuery部分将消息转换为TableRow对象,并直接流至BigQuery,而管道的AVRO部分将事件批处理为离散的窗口,然后将事件保存到Google 存储。 操作图如下图所示。
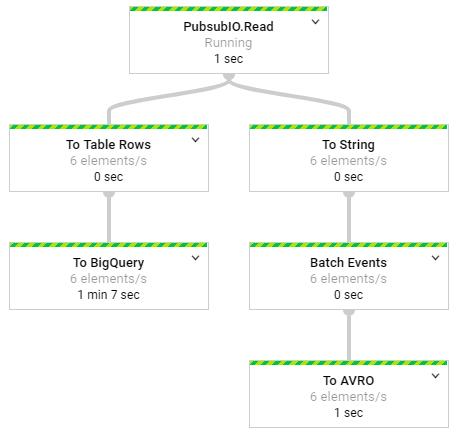
The streaming pipeline deployed to Google Cloud
设置环境建立数据管道的第一步是设置编译和部署项目所需的依赖项。 我使用以下maven依赖项来设置用于将事件发送到管道的跟踪API以及用于处理事件的数据管道的环境。
<!-- Dependencies for the Tracking API ->
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-pubsub</artifactId>
<version>0.32.0-beta</version>
</dependency>
</dependencies>
<!-- Dependencies for the data pipeline ->
<dependency>
<groupId>com.google.cloud.dataflow</groupId>
<artifactId>google-cloud-dataflow-java-sdk-all</artifactId>
<version>2.2.0</version>
</dependency>
由于它是开源的,因此我使用Eclipse编写和编译了本教程的代码。 但是,其他IDE(例如IntelliJ)提供了用于部署和监视DataFlow任务的其他功能。 在将作业部署到Google Cloud之前,您需要为PubSub和DataFlow设置一个服务帐户。 设置这些凭据不在本文讨论范围之内,有关更多详细信息,请参阅Google文档。
运行此数据管道的另一个前提条件是在GCP上设置PubSub主题。 我定义了一个原始事件主题,该主题用于发布和使用数据管道的消息。 有关创建PubSub主题的其他详细信息,请参见此处。
要部署此数据管道,您需要使用上面列出的maven依赖项设置一个Java环境,设置一个Google Cloud项目并启用计费功能,对存储和BigQuery服务启用计费功能,并创建一个PubSub主题以进行发送和 接收消息。 所有这些托管服务的确要花钱,但是有一个免费层可以用来制作数据管道原型。
Sending events from a server to a PubSub topic
发布事件为了构建可用的数据管道,构建用于封装发送事件数据的详细信息的API很有用。 Tracking API类提供了此功能,可用于将生成的事件数据发送到数据管道。 下面的代码显示了发送事件的方法签名,并显示了如何生成示例数据。
/** Event Signature for the Tracking API
public void sendEvent(String eventType, String eventVersion, HashMap<String, String> attributes);
*/
// send a batch of events
for (int i=0; i<10000; i++) {
// generate event names
String eventType = Math.random() < 0.5 ?
"Session" : (Math.random() < 0.5 ? "Login" : "MatchStart");
// create attributes to send
HashMap<String, String> attributes = new HashMap<String,String>();
attributes.put("userID", "" + (int)(Math.random()*10000));
attributes.put("deviceType", Math.random() < 0.5 ?
"Android" : (Math.random() < 0.5 ? "iOS" : "Web"));
// send the event
tracking.sendEvent(eventType, "V1", attributes);
}
跟踪API建立与PubSub主题的连接,以JSON格式传递事件,并实现用于通知传递失败的回调。 下面提供了用于发送事件的代码,该代码基于此处提供的Google的PubSub示例。
// Setup a PubSub connection
TopicName topicName = TopicName.of(projectID, topicID);
Publisher publisher = Publisher.newBuilder(topicName).build();
// Specify an event to send
String event = {\"eventType\":\"session\",\"eventVersion\":\"1\"}";
// Convert the event to bytes
ByteString data = ByteString.copyFromUtf8(event.toString());
//schedule a message to be published
PubsubMessage pubsubMessage =
PubsubMessage.newBuilder().setData(data).build();
// publish the message, and add this class as a callback listener
ApiFuture<String> future = publisher.publish(pubsubMessage); ApiFutures.addCallback(future, this);
上面的代码使应用程序可以将事件发送到PubSub主题。 下一步是在完全托管的环境中处理此事件,该环境可以根据需要扩展以满足需求。
存储事件数据管道的关键功能之一是使检测到的事件可供数据科学和分析团队进行分析。 用作端点的数据源应具有低延迟,并能够扩展到大量事件。 本教程中定义的数据管道显示了如何将事件同时输出到BigQuery和可用于支持大量分析业务用户的数据湖。
Streaming event data from PubSub to DataFlow
该数据管道的第一步是从PubSub主题中读取事件,并将摄取的消息传递给DataFlow流程。 DataFlow提供了一个PubSub连接器,该连接器允许将PubSub消息流传输到其他DataFlow组件。 下面的代码显示了如何实例化数据管道,指定流模式以及如何使用来自特定PubSub主题的消息。 此过程的输出是PubSub消息的集合,可以将其存储以供以后分析。
// set up pipeline options
Options options = PipelineOptionsFactory.fromArgs(args)
.withValidation().as(Options.class);
options.setStreaming(true);
Pipeline pipeline = Pipeline.create(options);
// read game events from PubSub
PCollection<PubsubMessage> events = pipeline
.apply(PubsubIO.readMessages().fromTopic(topic));
我们要存储事件的第一种方法是采用可用于构建数据湖的列格式。 尽管这篇文章没有显示如何在下游ETL中利用这些文件,但是拥有数据湖是一种很好的方式来维护数据集的副本,以防万一您需要对数据库进行更改。 由于架构或数据摄取问题的更改,数据湖提供了一种在必要时回载数据的方法。 分配给该过程的数据管道部分如下所示。

Batching events to AVRO format and saving to Google Storage
对于AVRO,我们不能使用直接流式传输方法。 我们需要先将事件分组,然后才能保存到平面文件中。 在DataFlow中可以实现此目的的方法是应用窗口功能,将事件分为固定的批次。 下面的代码应用了一些转换,这些转换将PubSub消息转换为String对象,将消息分组为5分钟的间隔,然后将生成的批次输出到Google Storage上的AVRO文件。
// AVRO output portion of the pipeline
events
.apply("To String", ParDo.of(new DoFn<PubsubMessage, String>() {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
String message = new String(c.element().getPayload());
c.output(message);
}
}))
// Batch events into 5 minute windows
.apply("Batch Events", Window.<String>into(
FixedWindows.of(Duration.standardMinutes(5)))
.triggering(AfterWatermark.pastEndOfWindow())
.discardingFiredPanes()
.withAllowedLateness(Duration.standardMinutes(5)))
// Save the events in ARVO format
.apply("To AVRO", AvroIO.write(String.class)
.to("gs://your_gs_bucket/avro/raw-events.avro")
.withWindowedWrites()
.withNumShards(8)
.withSuffix(".avro"));
总而言之,以上代码将事件批处理到5分钟的窗口中,然后将事件导出到Google Storage上的AVRO文件中。
数据管道这部分的结果是Google存储器上的AVRO文件的集合,可用于构建数据湖。 每隔5分钟就会产生一个新的AVRO输出,下游ETL可以将原始事件解析为特定于事件的已处理表模式。 下图显示了AVRO文件的示例输出。
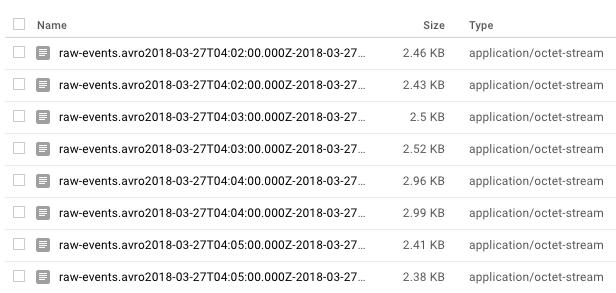
AVRO files saved to Google Storage
除了创建数据湖外,我们还希望事件可以在查询环境中立即访问。 DataFlow提供了一个BigQuery连接器,该连接器可提供此功能,并且流到该端点的数据可在短时间后用于分析。 数据管道的这一部分如下图所示。
Streaming events from DataFlow to BigQuery
数据管道将PubSub消息转换为TableRow对象,可以将其直接插入BigQuery中。 下面的代码包含两个套用方法:数据转换和IO编写器。 转换步骤从PubSub读取消息负载,将消息解析为JSON对象,提取eventType和eventVersion属性,并创建一个带有时间戳和消息负载以及这些属性的TableRow对象。 第二个apply方法告诉管道将记录写入BigQuery并将事件附加到现有表。
// parse the PubSub events and create rows to insert into BigQuery events.apply("To Table Rows", new
PTransform<PCollection<PubsubMessage>, PCollection<TableRow>>() {
public PCollection<TableRow> expand(
PCollection<PubsubMessage> input) {
return input.apply("To Predictions", ParDo.of(new
DoFn<PubsubMessage, TableRow>() {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
String message = new String(c.element().getPayload());
// parse the json message for attributes
JsonObject jsonObject =
new JsonParser().parse(message).getAsJsonObject();
String eventType = jsonObject.get("eventType").getAsString();
String eventVersion = jsonObject.
get("eventVersion").getAsString();
String serverTime = dateFormat.format(new Date());
// create and output the table row
TableRow record = new TableRow();
record.set("eventType", eventType);
record.set("eventVersion", eventVersion);
record.set("serverTime", serverTime);
record.set("message", message);
c.output(record);
}}));
}})
//stream the events to Big Query
.apply("To BigQuery",BigQueryIO.writeTableRows()
.to(table)
.withSchema(schema)
.withCreateDisposition(CreateDisposition.CREATE_IF_NEEDED)
.withWriteDisposition(WriteDisposition.WRITE_APPEND));
总结上面的代码,将从PubSub消耗的每个消息转换为带有时间戳的TableRow对象,然后将其流式传输到BigQuery进行存储。
数据流水线这部分的结果是事件将被流式传输到BigQuery,并可在DataFlow任务指定的输出表中进行分析。 为了有效地使用这些事件进行查询,您需要构建其他ETL以创建具有模式化记录的已处理事件表,但是现在您已经有了一种数据收集机制来存储跟踪事件。
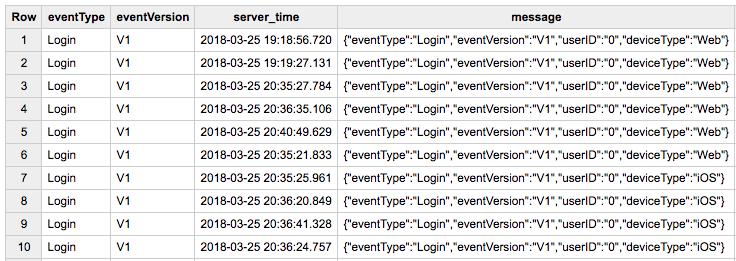
Game event records queried from the raw-events table in BigQuery
部署和自动扩展使用DataFlow,您可以在本地测试数据管道或部署到云。 如果运行代码示例时未指定其他属性,则数据管道将在本地计算机上执行。 为了部署到云并利用此数据管道的自动扩展功能,您需要在运行时参数中指定一个新的运行器类。 为了运行数据管道,我使用了以下运行时参数:
--runner=org.apache.beam.runners.dataflow.DataflowRunner
--jobName=game-analytics
--project=your_project_id
--tempLocation=gs://temp-bucket
部署作业后,您应该看到一条消息,说明作业已提交。 然后,您可以单击DataFlow控制台以查看任务:

The steaming data pipeline running on Google Cloud
上面指定的运行时配置不会默认为自动缩放配置。 为了部署可根据需求扩展的作业,您需要指定其他属性,例如:
--autoscalingAlgorithm=THROUGHPUT_BASED--maxNumWorkers=30
这篇Google文章以及Spotify的这篇文章都提供了有关设置DataFlow任务以适应繁重的工作量条件的其他详细信息。 下图显示了DataFlow如何扩展以根据需要满足需求。
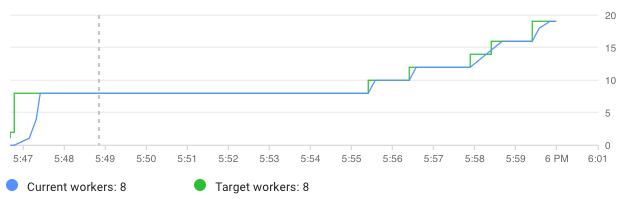
An example of Dataflow auto scaling. The pipeline will scale up and down as necessary to match deman
原始事件到处理后的事件到目前为止介绍的管道将跟踪事件保存为原始数据。 要将这些事件转换为已处理的数据,我们需要应用事件特定的架构。 我们可以采用以下几种不同的方法:
· 在当前DataFlow管道中应用模式,然后保存到BigQuery
· 在当前管道中应用模式并将其发送到新的PubSub
· 将其他属性应用于原始事件,然后发送到新的PubSub
· 使用下游ETL来应用架构
第一种方法是最简单的方法,但是如果需要的话,它不能提供一个很好的解决方案来更新事件定义。 可以如下面的代码所示实现该方法,该代码显示了如何过滤和解析MatchStart事件以输入到BigQuery中。
events.apply("To MatchStart Events", ParDo.of(
new DoFn<PubsubMessage, TableRow>() {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
String message = new String(c.element().getPayload());
JsonObject jsonObject = new
JsonParser().parse(message).getAsJsonObject();
String eventType = jsonObject.get("eventType").getAsString();
String version = jsonObject.get("eventVersion").getAsString();
String serverTime = dateFormat.format(new Date());
// Filter for MatchStart events
if (eventType.equals("MatchStart")) {
TableRow record = new TableRow();
record.set("eventType", eventType);
record.set("eventVersion", version);
record.set("server_time", serverTime);
// event specifc attributes
record.set("userID", jsonObject.get("userID").getAsString());
record.set("type", jsonObject.get("deviceType").getAsString());
c.output(record);
}
}}))
.apply("To BigQuery",BigQueryIO.writeTableRows()
为了实施此方法,您需要为每种事件创建一个新的DoFn实现。 第二种方法与第一种相似,但是没有将解析的事件传递给BigQuery,而是将它们传递给新的PubSub主题。 您可以将多种类型的事件发送到一个主题,也可以为每个事件创建一个主题。 使用前两种方法的缺点是消息解析逻辑是原始事件管道的一部分。 这意味着更改事件定义涉及重新启动管道。
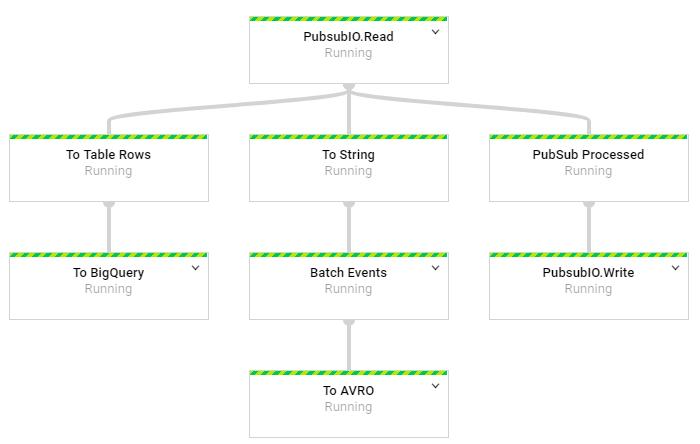
The streaming pipeline with an additional output:
可以使用的第三种方法是将具有附加属性的原始事件发送到另一个PubSub主题。 然后可以设置第二个DataFlow作业以根据需要解析事件。 下面的代码显示了如何解析原始事件,如何向PubSub消息添加其他属性以进行过滤以及如何将事件发布到第二个主题。 这种方法使事件定义可以更改,而无需重新启动原始事件管道。
# topic for raw events with additional attributes
private static String processed =
"projects/your_project_id/topics/processed-events";
events.apply("PubSub Processed",
ParDo.of(new DoFn<PubsubMessage, PubsubMessage>() {
@ProcessElement
public void processElement(ProcessContext c) throws Exception {
String message = new String(c.element().getPayload());
// parse the JSON message for attributes
JsonObject jsonObject = new
JsonParser().parse(message).getAsJsonObject();
String eventType = jsonObject.get("eventType").getAsString();
// Add additional attributes for filtering
HashMap<String, String> atts = new HashMap();
atts.put("EventType", eventType);
PubsubMessage out = new PubsubMessage(message.getBytes(), atts);
c.output(out);
}
}))
.apply(PubsubIO.writeMessages().to(processed));
可以使用的第四种方法是让下游ETL流程将模式应用于原始事件,并将原始事件表分解为特定于事件的表。 我们将在下一篇文章中介绍这种方法。
结论
这篇文章介绍了如何为启动建立数据管道。 我们介绍了管道中的数据类型,功能强大的数据管道的所需属性,数据管道的演进以及基于GCP构建的示例管道。
现在有各种各样的工具可用,可以以最小的努力为应用程序建立分析管道。 使用托管资源可使小型团队利用无服务器和自动扩展的基础架构,以最少的基础架构管理将其扩展到大量事件。 您可以使用应用程序记录所有相关数据,而不必使用数据供应商的现成解决方案来收集数据。 尽管此处介绍的方法不能直接移植到其他云中,但是用于实现此数据管道核心功能的Apache Beam库是可移植的,并且可以利用类似的工具在其他云提供商上构建可扩展的数据管道。
(本文翻译自Ben Weber的文章《Data Science for Startups: Data Pipelines》,参考:https://towardsdatascience.com/data-science-for-startups-data-pipelines-786f6746a59a)