
作者 | 听不来喊麦的C君
来源 | CSDN博客
惊雷/通天修为/天塌地陷紫金锤
紫电/玄真火焰/九天玄剑惊天变
这看起来不着边际的歌词,配上简单粗暴的蹦迪音乐。
最近,一首《惊雷》的喊麦歌曲在短视频平台火了,震惊了整个音乐圈。
但4月10日歌手杨坤却在直播中批评《惊雷》“要歌没歌,要旋律没旋律,要节奏没节奏,要律动没律动”,评价其“难听”、“俗气”。
4月11日,MC六道以原唱者的身份对杨坤的指责做出回应表示,音乐没有高低之分,称《惊雷》现在比杨坤的任何一首歌都火。一时间更是把《惊雷》推上了风口浪尖。
那么《惊雷》这首歌到底怎么样?都是哪些人在听?今天我们就用Python来给你解读。

拿下60亿流量,喊麦歌曲《惊雷》火了!
说道喊麦,作为近年来一种新兴的表演形式,其内容和表达方式则比较简单和浮夸,主要形式是在网上*载下**一些伴奏(以电音伴奏为主),跟着伴奏以简单的节奏和朗朗上口的押韵手法进行的语言表演。
更简单的说法就是,演唱时不讲究什么技法,带着伴奏对着麦喊就完事。比如之前爆火的《一人我饮酒醉》就是很具代表性的喊麦歌曲。
而喊麦歌曲也因为一味堆积看似没有关联的词,闹腾的电音,简单粗暴的唱法等,让大家各种吐槽。而在“全民*制抵**”喊麦的背景下,《惊雷》却火了。
从今年3月起,以《惊雷》为BGM的短视频在各大平台上迅速走红。截止到4月24日,在抖音的#惊雷#的标签页下显示共有23w个视频作品使用,产生64.1亿次*放播**。

一些网友更是跟风录制了各种翻唱版本。温柔版、方言版、戏腔版、小黄人版、种类之多,只有你想不到,没有网友做不到。瞬间《惊雷》就成了今年度的网络爆款神曲之一。在B站上搜索《惊雷》更是可以看到大量的相关视频。

我们对B站上《惊雷》的各类视频进行整理分析发现:

在3月底,《惊雷》就在B站小火了一把,总*放播**量突破50万。接着到了4月12日,随着杨坤和MC六道的“隔空互掐”,大量《惊雷》相关视频如雨后春笋一般爆发出来,无论是音乐、游戏、生活、影视和鬼畜各视频分区产生的相关视频突破300个,*放播**量更是水涨船高。

“精神小伙”专属歌曲,都是哪些人在听《惊雷》?
我们使用Python获取并分析了网易云音乐上,MC六道的这首《惊雷》相关的评论数据。
经过去重得到1534条样本,从而来分析一下《惊雷》这首歌的用户和评价信息。
先看到结论:
评论时间趋势图
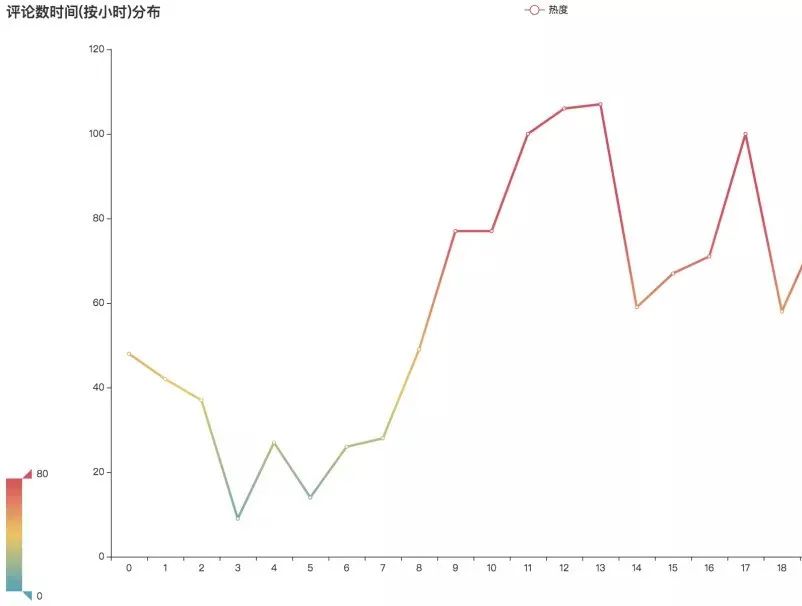
首先看到评论的时间,可以发现评论的高峰时间主要集中在:
-
中午12-13点左右;
-
下午5点之后的下班下课时间;
-
以及傍晚睡前9-10点
看来主要的听歌时间是在忙完工作的午休时,下班后的路上,以及睡前,刷着手机听听歌写写评论,也比较符合用户的听歌习惯。
评论用户性别分布
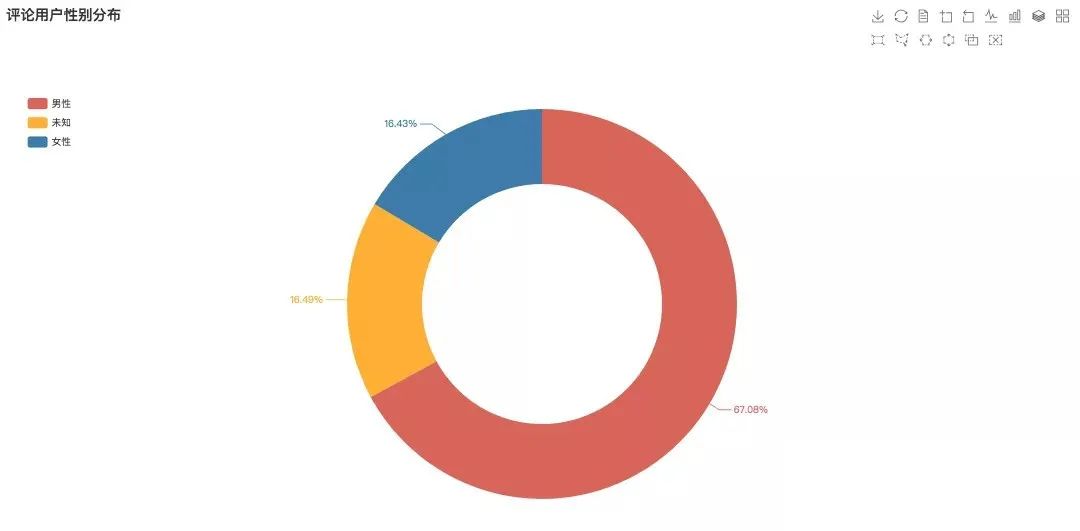
听歌的人群性别分布是如何的呢?经过分析发现,男性占比达到压倒性的67.08%,女性占比较少为16.43%,另外16.49%的用户没有标注性别。可见听《惊雷》的更多是男性群体。
评论用户年龄分布
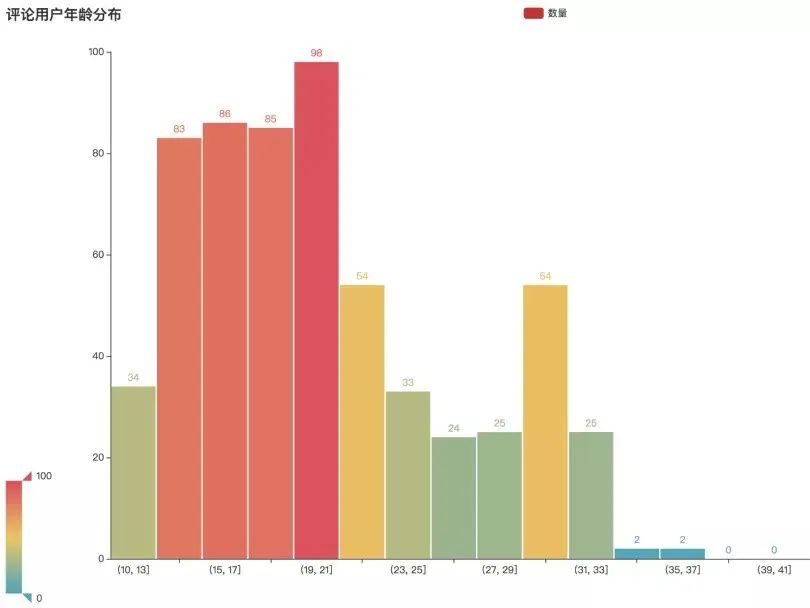
分析发现,用户大多集中在14-30岁之间,以20岁左右居多,除去异常和虚假年龄之外,这个年龄分布也符合网易云用户的年龄段。
评论用户地区分布

从城市分布图中可以看出,评论用户涵盖了全国各大省份,其中广东的评论用户排名第一,其次是山东、河北、河南等省份。

根据网易云曾发布的音乐数据,北上广深等发达地带的用户对小众音乐情有独钟,这些城市聚集了大量的小众音乐用户,其中广东也是聚集了众多热爱电音的用户,堪称“最电音省份”。
同时我们查询了2019年全国各省份的人口排名,排名前三的省份是:广东、山东、河南,这个结果也与分布图较为吻合,果然还是人多力量大。
评论情感正负分布
那么评论中大家对《惊雷》更多是称赞还是吐槽呢?接着我们对评论区的留言进行了情感分析,使用的是百度的API。
我们定义了一个函数获取情感评分正向和负向的概率值,值介于[0,1]之前,越接近1,情感越偏向于积极,反之则越消极。

通过评论情感得分分布图,可以发现:
在1534条数据中,有780条数据评分分值在[0,0.05]之间,占比50.08%,有一半以上的用户对这首歌表达了非常厌恶的情绪。我们还看到,有227个样本的评分在0.95以上,属于非常正向,这些正向评论真的正向吗?
我们不妨看几条这些评论:
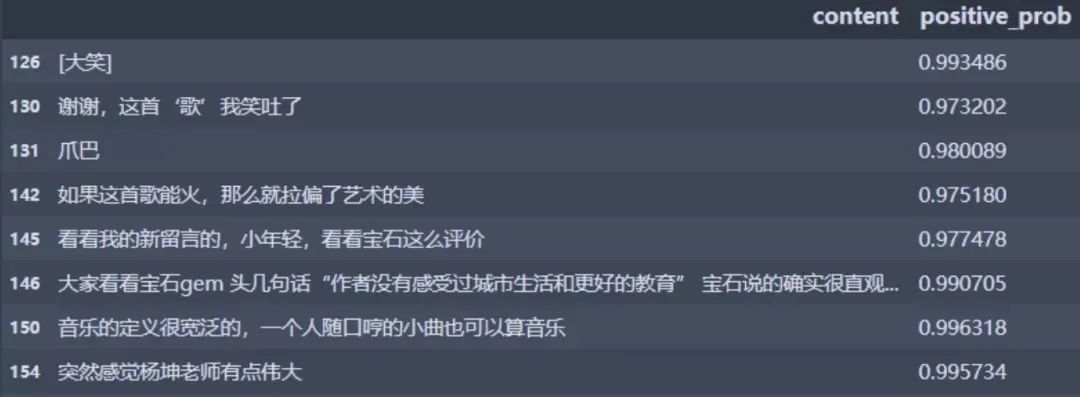
比如这一条:
谢谢,这首‘歌’我笑吐了
明显是属于负向的情绪,但是因为正向的关键词比较多,百度的情感分析程序给了0.97分,所以可以看出这里的正向评分也是有误差。
还有这一条:
突然感觉杨坤老师有点伟大
这首歌虽然是赞扬杨坤老师,但是放到这里是表达贬义,但是程序并没有判断出来,间接说明程序还是没有人聪明啊(拟合能力不足+汉语语境情况复杂)。
所以实际上大部分评论带着反讽的口吻,我们可以大胆推断,这首歌的负向情绪占比至少上升10~15%个百分点。
评论词云分布:

通过文本分析,可以看出大家对这首歌的评论集中对杨坤和MC六道的讨论上,吐槽点主要集中在关于歌曲的“难听”、“俗气”、"抄袭"等。同时也表达了对于“喊麦”和"音乐"的讨论上。

用Python分析《惊雷》的评论
我们使用Python获取并分析了网易云音乐上《惊雷2020》相关的评论数据并进行了以下部分处理和分析,整个分析过程分为以下几个步骤:数据获取、数据读入与数据预处理、数据分析和可视化。
1、数据获取
此次爬虫部分主要是调用官方API,本次用到的API主要是:
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit={每页限制数量}&offset={评论数总偏移}
参数说明如下:
{歌曲ID}:歌曲ID
limit:限制每页获取的数据条数
offset:翻页参数偏移量,offset需要是limit的倍数
返回的数据格式为json,通过此接口目前每天获取的数据量限制是1000条,代码思路如下:
-
先获取一页的数据,并封装成解析函数parse_one_page
-
变化offset参数,循环构建URL,并调用解析函数
具体代码如下:
# 导入库import requestsimport jsonimport timeimport pandas as pd
def parse_one_page(comment_url):"""功能:给定一页的评论接口,获取一页的数据。"""# 添加headersheaders = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.113 Safari/537.36'}
# 发起请求r = requests.get(comment_url, headers=headers)
# 解析数据comment_data = r.json['comments']
# 获取用户IDuser_id = [i['user']['userId'] for i in comment_data]# 获取用户昵称nick_name = [i['user']['nickname'] for i in comment_data]# 获取评论IDcomment_id = [i['commentId'] for i in comment_data]# 获取评论内容content = [i['content'] for i in comment_data]# 获取评论时间content_time = [i['time'] for i in comment_data]# 获取点赞liked_Count = [i['likedCount'] for i in comment_data]
df_one = pd.DataFrame({'user_id': user_id,'nick_name': nick_name,'comment_id': comment_id,'content': content,'content_time': content_time,'liked_Count': liked_Count})
return df_one
def get_all_page(song_id):"""功能:获取100页短评:目前接口一天最多获取数据量"""df_all = pd.DataFrame
for i in range(101): # 最多100页url = 'http://music.163.com/api/v1/resource/comments/R_SO_4_{}?limit=10&offset={}'.format(song_id, i*10)# 调用函数df = parse_one_page(comment_url=url)# 循环追加df_all = df_all.append(df, ignore_index=True)# 打印进度print('我正在获取第{}页的信息'.format(i + 1))# 休眠一秒time.sleep(1)
return df_all
if __name__ == '__main__':# 惊雷song_id = '1431580747'# 运行函数df_jl = get_all_page(song_id)获取到的数据如下所示,此次我们一共获取了两天的数据,经过去重得到1534条样本,来分析一下《惊雷》这首歌的用户和评价信息。
获取的数据集主要包含了以下的信息:评论ID、用户ID、用户昵称、用户评论、评论时间、评论点赞。根据用户ID可以获取评论用户相关信息,此处暂不做赘述。
df_comment.head

2、数据读入与数据预处理
此处,我们将对获取的评论数据集进行以下的处理以方便后续的分析:
-
读入数据和数据合并,去除重复值
-
评论时间:将评论时间转换为标准时间
-
用户评论:使用jieba分词对评论数据进行分词处理。
代码实现如下:
读入数据、合并、去重
# 导入包import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport jsonimport timeimport requests
# 读入数据df_comment_1 = pd.read_excel('jinglei.xlsx')df_comment_2 = pd.read_excel('jinglei_2.xlsx')
# 数据合并df_comment = pd.concat([df_comment_1, df_comment_2])
# 去除重复值df_comment.drop_duplicates(inplace=True)print(df_comment.info)
<class 'pandas.core.frame.DataFrame'>Int64Index: 1534 entries, 0 to 983Data columns (total 6 columns):user_id 1534 non- int64nick_name 1534 non- objectcomment_id 1534 non- int64content 1534 non- objectcontent_time 1534 non- int64liked_Count 1534 non- int64dtypes: int64(4), object(2)memory usage: 83.9+ KBNone
评论时间处理
def timeStamp(timeNum): '''功能:转换毫秒为标准时间'''timeStamp = float(timeNum/1000) # 转换为秒timeArray = time.localtime(timeStamp)otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray) # 转换字符串return otherStyleTimedf_comment['content_time'] = df_comment['content_time'].apply(lambda x:timeStamp(x))
3、使用百度API进行情感分析
情感分析是NLP的重要部分。这里我们使用百度的API,来进行情感分析,经测试这个API接口结果相对比较准确。我们定义了一个函数获取情感评分正向和负向的概率值。返回结果解释:以正向概率positive_prob为例,值介于[0,1]之前,越接近1,情感越偏向于积极。
代码和结果如下:
百度情感分析的地址见下,点击立即使用就可以了
http://ai.baidu.com/tech/nlp/sentiment_classify
# 异常值处理df_comment['content'] = df_comment['content'].replace('🕴🏿🕴🏿⚰️🕴🏿🕴🏿', '黑人抬棺')
# 输入API Key和Secret Keyak = '你的API Key'sk = '你的Secret Key'
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(ak, sk)
# 发起请求r = requests.post(host)# 获取tokentoken = r.json['access_token']
def get_sentiment_score(text):"""输入文本,返回情感倾向得分"""url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/sentiment_classify?charset=UTF-8&access_token={}'.format(token)data = {'text': text}data = json.dumps(data)try:res = requests.post(url, data=data, timeout=3)items_score = res.json['items']except Exception as e:time.sleep(1)res = requests.post(url, data=data, timeout=3)items_score = res.json['items']return items_score
# 获取情感倾向分值并存入列表score_list =step = 0for i in df_comment['content']:score = get_sentiment_score(i)# 打印进度step += 1print('我正在获取第{}个评分'.format(step), end='\r')score_list.append(score)
最后提取正负向的概率,并添加标签。将positive_prob>0.5定义为正向。
# 提取正负概率positive_prob = [i[0]['positive_prob'] for i in score_list]negative_prob = [i[0]['negative_prob'] for i in score_list] # 增加列df_comment['positive_prob'] = positive_probdf_comment['negative_prob'] = negative_prob # 添加正向1 负向-1标签df_comment['score_label'] = df_comment['positive_prob'].apply(lambda x:1 if x>0.5 else -1)df_comment.head

4、数据可视化
我们将进行以下的数据可视化
-
评论数时间(按小时)分布
-
评论用户性别占比
-
评论用户年龄分布
-
评论用户地区分布
-
评论情感得分正负向标签占比分析-基于百度自然语言处理API
-
评论情感得分分布
-
评论词云分析
评论数时间(按小时)分布
df_comment['content_time'] = pd.to_datetime(df_comment['content_time'])df_comment['content_hour'] = df_comment.content_time.dt.hourhour_num = df_comment.content_hour.value_counts.sort_index
# 折线图from pyecharts.charts import Linefrom pyecharts import options as opts
line1 = Line(init_opts=opts.InitOpts(width='1350px', height='750px'))line1.add_xaxis(hour_num.index.tolist)line1.add_yaxis('热度', hour_num.values.tolist,label_opts=opts.LabelOpts(is_show=False))line1.set_global_opts(title_opts=opts.TitleOpts(title='评论数时间(按小时)分布'),visualmap_opts=opts.VisualMapOpts(max_=80))line1.set_series_opts(linestyle_opts=opts.LineStyleOpts(width=3))line1.render
经过统计,此次数据采样日期来自4.22~4.24日。
通过评论时间按小时分布图可以看出,评论数在一天当中从5点开始一路攀升,一天有三个小高峰:13点-17点-21点。
评论用户性别占比
# 计算占比gender_perc = df_user['gender'].value_counts / df_user['gender'].value_counts .sumgender_perc = np.round(gender_perc*100,2)
from pyecharts.charts import Pie
# 绘制饼图pie1 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))pie1.add("",[*zip(gender_perc.index, gender_perc.values)],radius=["40%","65%"])pie1.set_global_opts(title_opts=opts.TitleOpts(title='评论用户性别分布'),legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),toolbox_opts=opts.ToolboxOpts)pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%"))pie1.set_colors(['#D7655A', '#FFAF34', '#3B7BA9', '#EF9050', '#6FB27C'])pie1.render
通过评论用户性别分布图可以看出,在评论用户中男性用户占到了67.08%。
评论用户年龄分布
age_num = pd.Series(df_user.age.value_counts)# 删除异常值age_num = age_num.drop(['未知',-5, -9, 0, 1, 6, 7])age_num = pd.DataFrame(age_num).reset_index.rename({'index':'age', 'age':'num'}, axis=1)
# 分箱age_num['age_cut'] = pd.cut(age_num.age, bins=[10,15,20,25,30,35])
# 分组汇总age_cut_num = age_num.groupby('age_cut')['num'].sum
from pyecharts.charts import Bar
# 绘制柱形图bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))bar1.add_xaxis(age_cut_num.index.astype('str').tolist)bar1.add_yaxis("数量", age_cut_num.values.tolist, category_gap='20%')bar1.set_global_opts(title_opts=opts.TitleOpts(title="评论用户年龄分布"),visualmap_opts=opts.VisualMapOpts(max_=180),toolbox_opts=opts.ToolboxOpts)bar1.render
用户年龄分布图可以看出,用户大多集中在14-30岁之间,以20岁左右居多,除去异常和虚假年龄之外,这个年龄分布也符合网易云用户的年龄段。
评论用户城市分布Top10
province_num = df_user.province_name.value_countsprovince_num.index = province_num.index.str[:2]province_top10 = province_num[:10]
# 柱形图bar2 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))bar2.add_xaxis(province_top10.index.tolist)bar2.add_yaxis("城市", province_top10.values.tolist)bar2.set_global_opts(title_opts=opts.TitleOpts(title="评论者Top10城市分布"),visualmap_opts=opts.VisualMapOpts(max_=120),toolbox_opts=opts.ToolboxOpts)bar2.render
from pyecharts.charts import Geofrom pyecharts.globals import ChartType
# 地图geo1 = Geo(init_opts=opts.InitOpts(width='1350px', height='750px'))geo1.add_schema(maptype='china')geo1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],type_=ChartType.EFFECT_SCATTER,blur_size=15)geo1.set_global_opts(title_opts=opts.TitleOpts(title='评论者国内城市分布'),visualmap_opts=opts.VisualMapOpts(max_=120))geo1.set_series_opts(label_opts=opts.LabelOpts(is_show=False))geo1.render
# 地图map1 = Map(init_opts=opts.InitOpts(width='1350px', height='750px'))map1.add("", [list(z) for z in zip(province_num.index.tolist(), province_num.values.tolist())],maptype='china')map1.set_global_opts(title_opts=opts.TitleOpts(title='评论者国内城市分布'),visualmap_opts=opts.VisualMapOpts(max_=120),toolbox_opts=opts.ToolboxOpts)map1.render
城市分布图中可以看出,评论用户涵盖了全国各大省份,其中广东的评论用户排名第一。
评论情感得分正负向标签占比分析
label_num = df_comment.score_label.value_counts / df_comment.score_label.value_counts.sumlabel_perc = np.round(label_num,3)label_perc.index = ['负向', '正向']label_perc
负向 0.701正向 0.299Name: score_label, dtype: float64
# 绘制饼图pie2 = Pie(init_opts=opts.InitOpts(width='1350px', height='750px'))pie2.add("",[*zip(label_perc.index, label_perc.values)],radius=["40%","65%"])pie2.set_global_opts(title_opts=opts.TitleOpts(title='评论情感标签正负向分布'),legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"),toolbox_opts=opts.ToolboxOpts)pie2.set_series_opts(label_opts=opts.LabelOpts(formatter="{c}%"))pie2.set_colors(['#3B7BA9', '#EF9050'])pie2.render
通过分布图可以看出,评论内容中70%左右的内容表达了负向的情绪,说明对于《惊雷》这首喊麦的歌曲,大众主要持批判的观点。
情感评论得分分布
# 定义分隔区间bins = [0, 0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5,0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0]positive_num = pd.cut(df_comment.positive_prob, bins).value_countspositive_num = positive_num.sort_index# 柱形图bar3 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))bar3.add_xaxis(positive_num.index.astype('str').tolist)bar3.add_yaxis("", positive_num.values.tolist, category_gap='5%')bar3.set_global_opts(title_opts=opts.TitleOpts(title="评论情感得分"),visualmap_opts=opts.VisualMapOpts(max_=500),toolbox_opts=opts.ToolboxOpts)bar3.render
通过评论情感得分分布图,可以发现,在1534条数据中,有780条数据评分分值在[0,0.05]之间,占比50.08%。
评论词云分析
此处数据处理主要使用jieba分词,步骤暂略。
from pyecharts.charts import WordCloudfrom pyecharts.globals import SymbolType
word1 = WordCloud(init_opts=opts.InitOpts(width='1350px', height='750px'))word1.add("", [*zip(key_words.words, key_words.num)],word_size_range=[20, 200],shape=SymbolType.DIAMOND)word1.set_global_opts(title_opts=opts.TitleOpts('网易云音乐关于惊雷评论词云'),toolbox_opts=opts.ToolboxOpts,)word1.render
原文:
https://blog.csdn.net/qq_46614154/article/details/105752359

☞十六位顶尖专家齐聚,解密阿里云最新核心技术竞争力!
☞华为回应美新规:不涉及产品买卖;微软 GitHub 帐户疑被黑;GCC 10.1 发布 | 极客头条
☞微服务太杂乱难以管理?一站式服务治理平台来袭!
☞干货 | 时间序列预测类问题下的建模方案探索实践
☞利用 Docker 在不同宿主机做 CentOS 系统容器 | 原力计划
☞从货币历史,看可编程货币的升级