
如前所述的博客文章所述,数据基础架构团队开始寻找Pocket Gems数据仓库解决方案的Redshift替代品。这篇文章将经历三个流行的比较分析:Redshift,BigQuery和Snowflake。
要求
在实现AWS Redshift后对我们的用例并不最佳,我们决定衡量其他可用解决方案的性能。在Pocket Gems上,重要的是让我们的玩家喜欢游戏。其中的一大部分是检查我们的游戏的性能数据,包括每个人的崩溃报告,FPS,延迟,玩家参与等。我们使用Redshift作为我们性能分析的基准。
我们决定优先考虑以下功能/性能,以便我们的决定:
查询运行时性能:毫无疑问,这是我们的主要标准之一。我们希望确保我们的下一代仓库可以比我们环境中的Redshift更好地表现更好。请注意,我们专注于测量环境中的性能。因此,我们的基准测试与标准性能测试不同。
可扩展性:我们的大多数分析使用量是尖峰。以前,我们为数据和图表的预处理创建了多个系统。这具有一定的维护成本,许多人更喜欢查看新数据。虽然我们的需求并不太高,但我们希望同时运行15-20个计算密集型查询。
长期存储:Pocket Gems每天处理大约400M的数据。我公司拥有强大的数据驱动文化。我们鼓励我们的产品经理记录他们稍后分析的任何数据。缺点是,与计算和分析相比,我们具有大的存储要求。我们希望找到一个可以廉价存储数据并运行DML(数据操作语言)查询的解决方案。我们需要在存档数据中运行DML,以获得GDPR和其他法规均匀。
数据加载:作为一家依赖于数据的公司,我们希望保持快速有效的ETL(提取,变换,负载)系统。我们希望将数据摄入时间降低到<= 10分钟。
SQL支持:最后,我们想要一个符合ANSI SQL的解决方案。Pocket Gems有分散目的的分散方法。我们所有人都运行SQL查询进行分析。符合SQL的解决方案自然会使转变更容易。(这也帮助我们建立了我们内部客户的迁移系统。)
成本:服务器成本是我们决定的另一个重要因素。我们希望确保我们可以在没有显着增加与Redshift 相比的情况下实现以前的物品。
查询运行时性能
我们希望衡量竞争性跨系统的表现。请注意,所有三种产品都有折扣价格,因此在决定这些配置方面存在一些主观性。
Redshift:16节点DS2.8xlarge
BigQuery:1500节点(保留实例)
Snowflake:2xL节点(可扩展到10个实例。我们几乎不需要4个实例为我们的基准测试)
如前所述,我们专注于寻找Pocket Gems的最佳解决方案,避免进行通用分析。我们决定不使用TPC-DS数据集,并专注于查询的Gemmers定期运行。接下来,我们根据所花费的时间和处理的数据量分类查询。我们确定了来自这些不同类别的数百个查询以运行性能测试。
接下来,我们转换了这些查询,使它们与Snowflake和BigQuery兼容。他们都符合SQL,但每个人都有轻微的语法差异。最后,我们能够自动迁移〜60%的查询。我们能够为一个仓库迁移一些查询,但不是另一个仓库,反之亦然。然后,我们通过单独查询运行性能测试,以确保在两个仓库中成功地运行。
对于每个测试,我们总共有〜80个查询。我们跑了五次查询,并采取了中位值以避免一次性波动。为了模拟真实用法,我们在任何给定时间同时运行10个查询。
在我们的测试中,Redshift有三个的最糟糕的执行时间。我们还观察到,Google Bigquery大多数查询都超越了Snowflake。然而,一个有趣的观察是在加入1M +物品时与其他两个相比表现得非常相比。
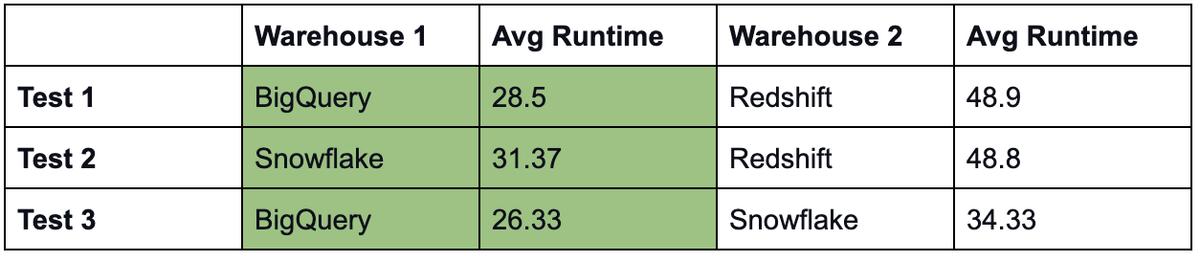
总的来说,BigQuery表现不错。
接下来,我将通过我们考虑的其余部分来完成我们的决定。
可扩展性
Snowflake可以根据配置自动扩展。您还可以使用其API或管理面板轻松更改配置。Redshift现在可以使用弹性调整扩展,但AWS费用对此有关的按需定价明显高。基于您的使用情况,BigQuery按需将自动扩展 - 它有一个上限,但我们看到它需要在需要时移动过去的2,000个Slot。您可以为固定定价模型中的100个Slot尺度扩展,但此过程是手动。
我会把胜利的奖杯发给Snowflake。
长期储存
数据存储
Redshift Spectrum允许查询S3的数据,非常便宜。但是,您无法轻松运行它们上的DML查询。这可能导致GDPR,COPPA和CCPA的并发症。
Snowflake和BigQuery都提供数据存储和计算的分离。Snowflake提供压缩数据存储,每月〜27 $ / TB。BigQuery提供了未压缩的数据存储,每月〜20 $ / TB,但每月提供〜10 $ / TB,数据未修改90天。
备份和检索
RedShift提供可自动或手动进行的快照服务。然后,您可以恢复整个快照或特定表格。与其他两个系统相比,粒度非常弱。
BigQuery允许您从特定时间点恢复表的数据。但是,如果您删除表并使用不同的表结构重新创建它,则无法恢复数据。此外,如果您删除数据库,则数据将不错。
Snowflake具有全面的数据恢复系统。您可以撤消表甚至数据库丢弃。
Snowflake绝对是这里的胜利者。
数据加载
批量装载
Redshift共享计算数据加载和分析的功率。您可以创建单独的队列以加载余额。Snowflake如果您计划连续加载数据,请您运行一个小型装载机。这与Redshift不同。
BigQuery是这里的奇怪。令人惊讶的是,无需向您收取数据加载的费用,并且根本不会使用计算资源。
我们把它放在这里,因为这会影响我们关心的定价和可扩展性。
流数据
Redshift和Snowflake没有本机支持流数据处理。对于Redshift,您可以使用AWS Kinesis进行流式传输,但负载将压倒Redshift。Snowflake的Snowflow不提供流媒体服务,并不能保证加载数据的时间。
另一方面,BigQuery提供了少量费用的本机流API。我们发现服务将简单使用和高度性能。
BigQuery是这里的明确胜利者。
SQL支持
半结构化数据类型
Redshift可以存储JSON值,但支持仍然有限。尚未支持阵列和结构。
Snowflake和BigQuery支持JSON数据,阵列和对象存储,遍历和查询。
SQL语法
所有三个系统都是符合ANSI SQL的。它们都有一些自定义功能,但相对相似。
价钱
定价难以评估。所有公司都根据您的承诺级别提供各种折扣:
Redshift*绑捆**包存储和计算在一起。他们的定价模型是迄今为止最简单的三个。如果您获得了三年的承诺,您可以获得巨大的折扣(〜75%)。
BigQuery提供了按需(Query)和固定定价模型,以一年的承诺折扣15%。存储单独收费。但是,他们提供免费加载数据。您还可以使用DRY_RUN功能估计使用按需模式运行查询的成本。
Snowflake定价模型有点令人困惑。您可以购买用于实例的信用。难以估计信用使用量,因为我们发现它根据查询类型和已处理的数据而异。储存价格以平价价格收费。
由于Snowflake提供的灵活性,我倾向它。
概要图表
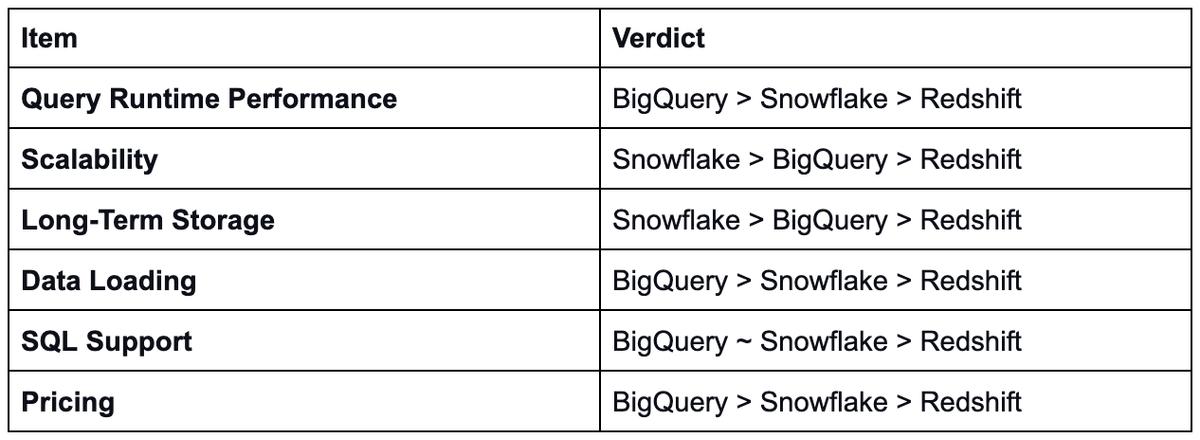
好的,这是最好的数据库?
老实说,这取决于个人用例。在我们的分析中,BigQuery和Snowflake都竞争地执行。Redshift有一些追赶,但在特定场景中可以强大(例如数据和计算平衡)。
我们最终根据我们的需求决定了我们未来的数据仓库解决方案的Google Buequery。希望这个比较分析将帮助您了解您的数据需求的理想选择。
作为数据基础架构工程的一部分,我们开发和优化了ETL系统,BI工具和许多其他业务关键系统的表现,包括Pocket Gems(包括CRM,AB测试,数据建模)。
(本文由闻数起舞翻译自undefined的文章《A comparative analysis between BigQuery, Redshift, and Snowflake》,转载请注明出处,原文链接:https://medium.com/pocket-gems/a-comparative-analysis-between-bigquery-redshift-and-snowflake-8d194fdf5693)