★★前篇★★不想看计算方法,可以直接拉到文末看结果。
基本思路:以决赛两支球队本届欧洲杯决赛前的6场比赛数据作为训练样本,预测两支球队决赛时常规时间内的进球数,谁进球多谁胜。
算法选择:线性回归、KNN、随机森林、GBRT和SVM
恐怕很难遇到训练样本数量如此少的案例,尽管很多资料里都喜欢把之前的比赛样本大量堆积,但我们仍然直觉的、倔强的、任性的、随便的认为,本届杯赛之外的数据,毫无意义![石化][石化]
先拿2016年欧洲杯练练手,使用17个特征。
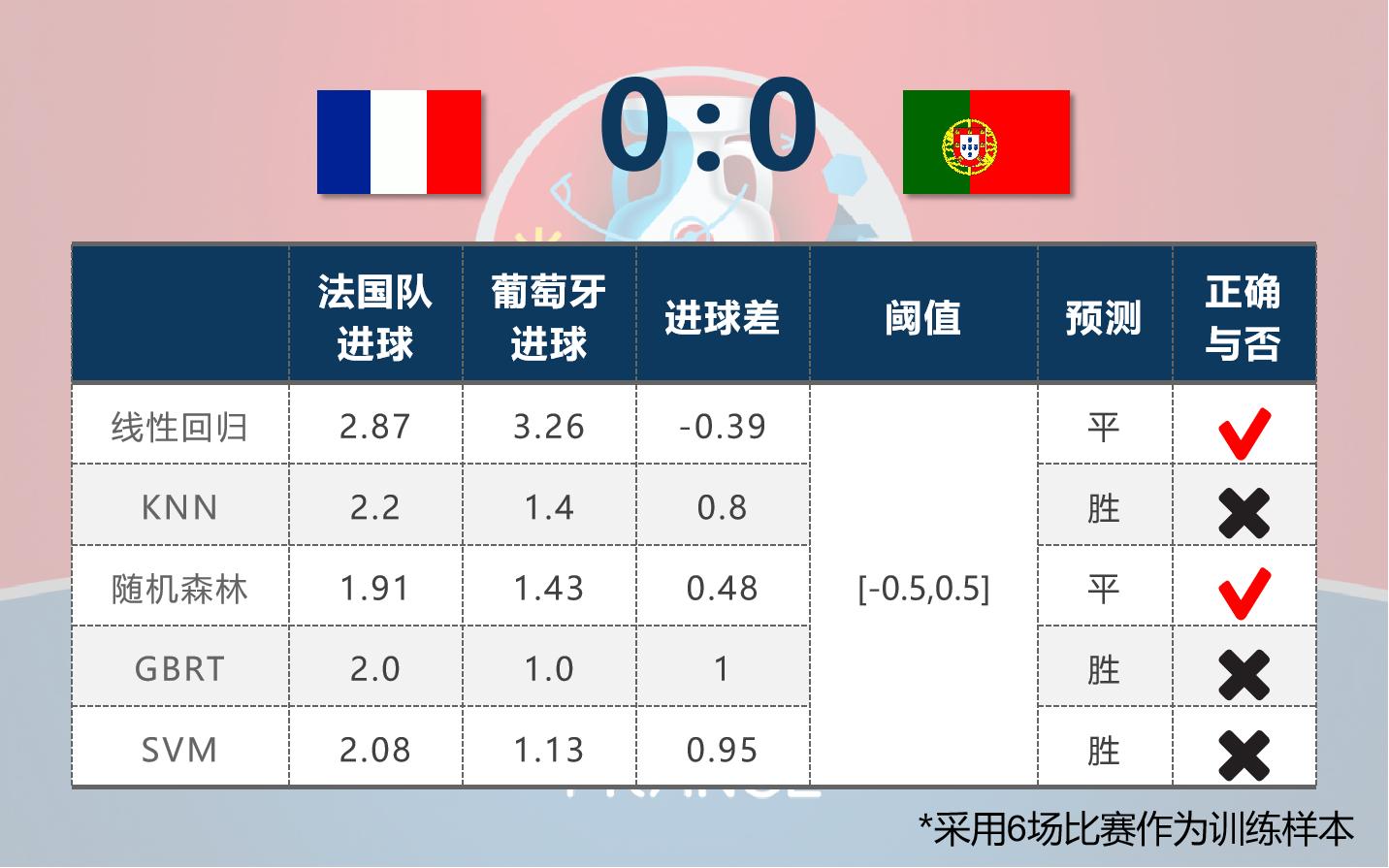
随机森林在进球数和结果的预测上和实际比赛结果最接近,线性回归虽然也预测对了结果,但进球数的预测实在太离谱。另外,6组训练样本的确太少了,于是考虑将整届欧洲杯比赛作为训练样本(决赛除外),共100组。这样可以大幅度增加训练样本的数量,但两个队将使用同一套样本,训练出同一套模型。
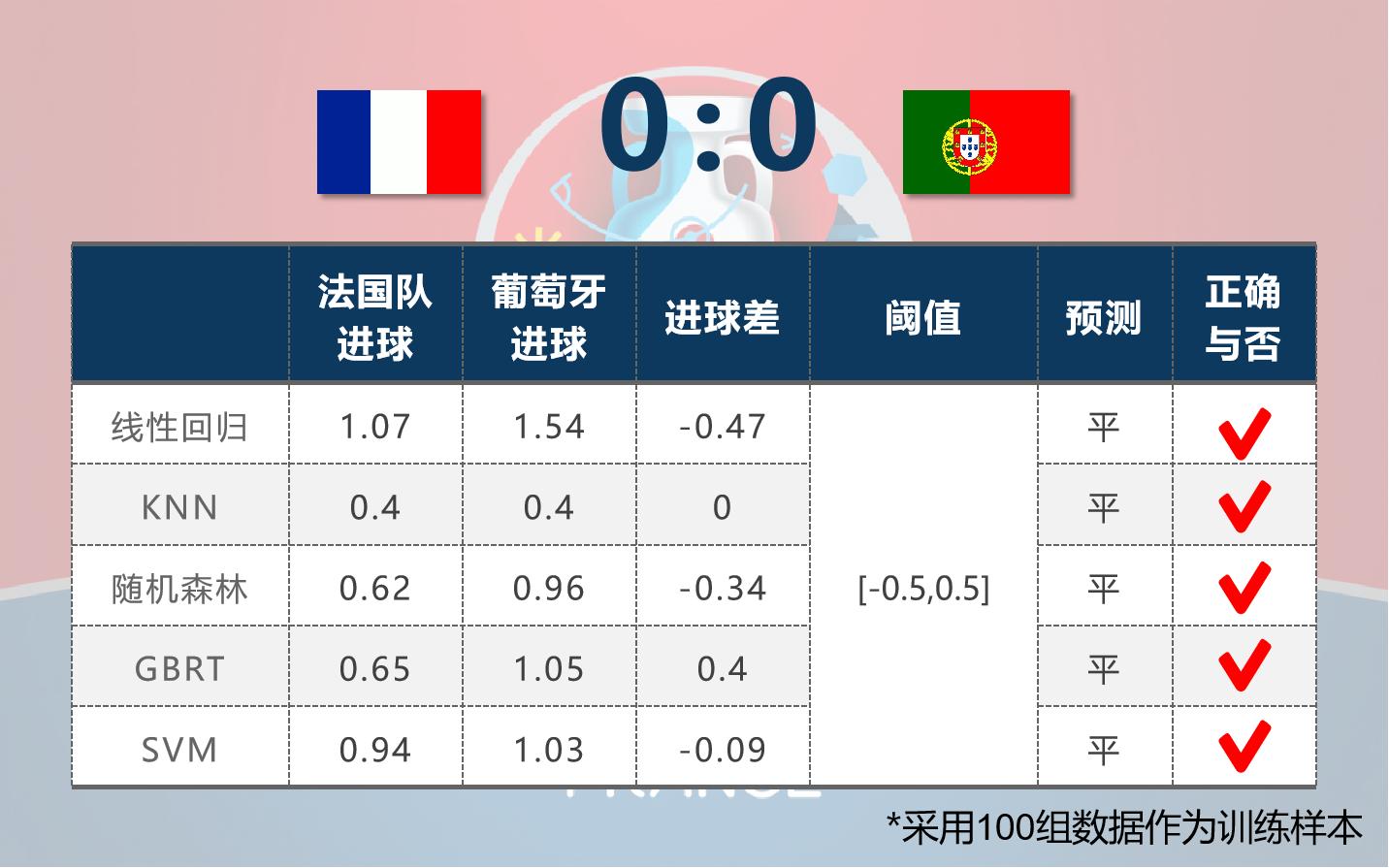
按照预先设定的阈值,所有算法都预测对了结果,KNN在进球数和比赛结果方面预测效果都是最佳的。所有算法预测效果都非常好,反倒让我们产生了怀疑,如果进一步缩小阈值范围至[-0.2,0.2],则仍然只有两种算法预测准确。因为这毕竟是“事后诸葛亮”,所以,还是看看本届杯赛的预测情况吧。
本届欧洲杯,特征数量有所增加,共24个,如下表。

OK,6组和100组训练样本的预测结果分别如下。
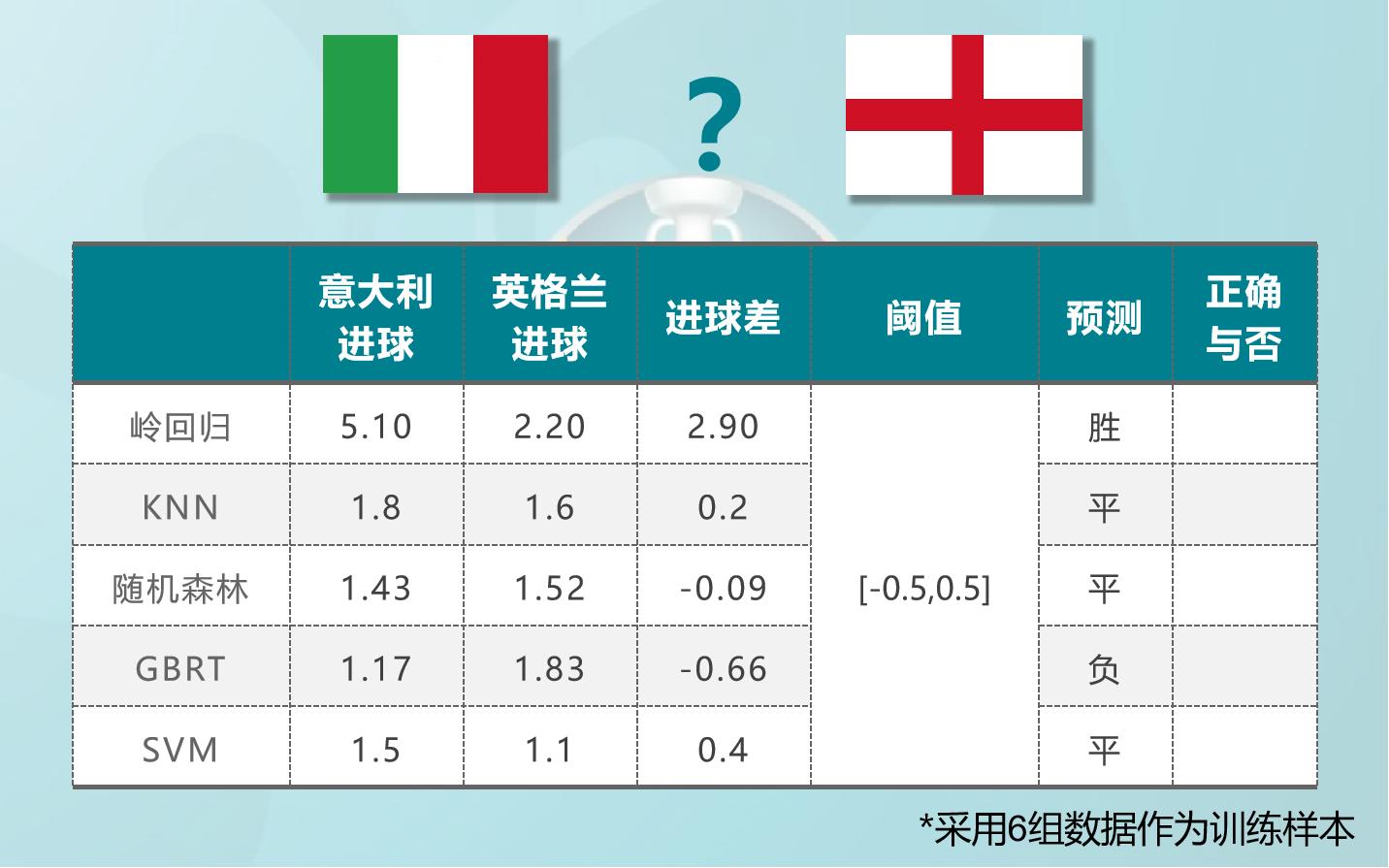
6组数据作为训练样本
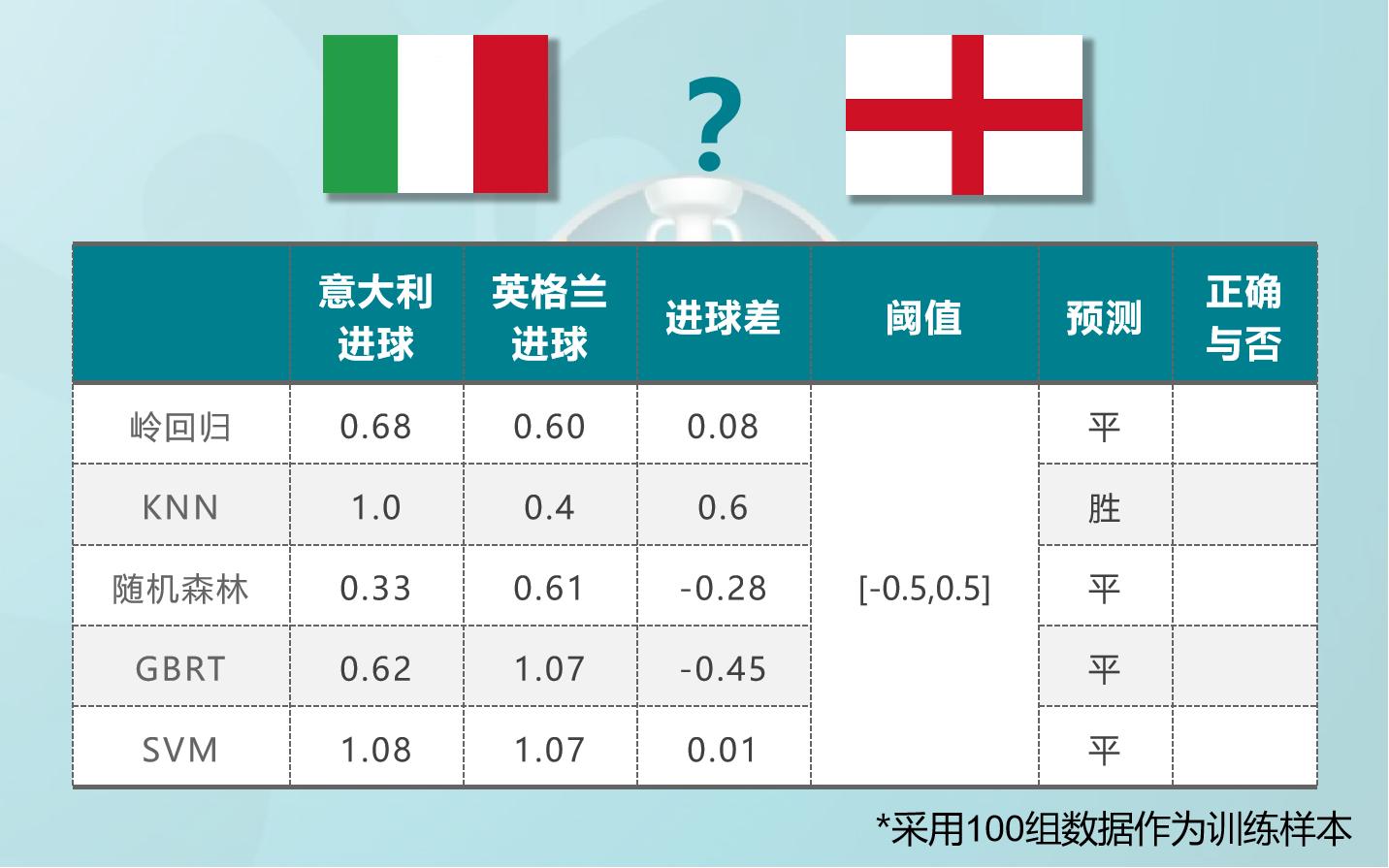
100组数据作为训练样本
按照事先划定的阈值,有2组预测意大利胜,1组预测英格兰胜,剩余7组预测平局。随机森林和SVM前后两次预测结果一致,岭回归有点离谱了。
纯属娱乐,误差极大,请谨慎参考。
更多体育领域的数据话题,点个赞,关注一下呗。