(本号正在连续推出以Python官网文档为主线的完整的系统的学习Python的系列文章和视频,感兴趣的朋友们欢迎搜索关注。本文及后续文章如无特别声明均以Windows平台作为演示平台,Python版本为:3.8.1)
【注意:开始学习“Python学习进阶教程”系列内容前须已经学习过“Python学习入门教程”系列内容】
本部分内容由笔者参照Python英文版文档编写整理,较之官网中文版更加符合中文的语法习惯,且修正了其中出现的所有错误。可以作为参考文档收藏!
static str.maketrans(x[, y[, z]])
该方法是静态方法,返回一个str.translate()可以使用的dict类型的转换表。对参数要求如下:
- 如果只提供了一个参数,则该参数必须是一个字典类型的对象,其中每一对键值对中的键必须为unicode码点序号(整数)或单字符,对应的值必须为unicode码点序号(整数),任意长度字符串,或None。注意:在结果字典对象中原单字符键将被转换成unicode码点序号(整数)。
- 如果提供了两个参数,则它们必须都是字符串,并且长度相等。结果字典对象中元素为依次以第一个字符串中字符对应的Unicode码点序号为键,第二个字符串中对应位置上的字符的码点序号为值的键值对。注意:如果第一个字符串中有重复的字符,则在结果字典对象中只有一个对应的键,该键对应的值为最后一个重复字符对应的值,例如str.maketrans("aaaa","sdfg")结果为{97:103},其中97对应"a"的Unicode码点序号,103对应"g"的Unicode码点序号。
- 如果提供三个参数,则必须都为字符串,且前两个必须等长,第三个不作要求。假设三个参数依次为s1,s2,s3,则结果同执行如下操作得到的result:
>>>result =str.maketrans(s1,s2)
>>>result.update([(ord(x),y) for x,y in zip(s3,[None]*len(s3))])
str.partition(sep)
在原字符串上从首到尾查找 sep,在sep首次出现的位置将原字符串分成三部分:sep之前的部分、sep,以及sep之后的部分,并将这三部分以一个三元组返回。如果原字符串中不包含sep,则返回的三元组中元素依次为原字符以及两个空字符串。
str.replace(old, new[, count])
返回将原字符串中old替换成new之后的字符串,如果指定count,则只替换count次,否则全部替换。
str.rfind(sub[, start[, end]])
如果原字符串区间[start,end)上的子字符串包含sub,则返回出现在该子字符串最右端的sub的索引值,如果原字符串区间[start,end)上的子字符串不包含sub,则返回-1。默认start为0,end为原字符串长度。
str.rindex(sub[, start[, end]])
与str.rfind()类似,不同的是该方法当在原字符串中未找到sub时,会引发ValueError。
str.rjust(width[, fillchar])
如果原字符串的长度小于width,则返回原字符串内容位于其右端的长度为width的字符串,其左端使用fillchar填充,如果没指定fillchar,则使用空格填充。如果原字串的长度大于等于width,则结果就为原字串。
str.rpartition(sep)
如果原字符串包含sep,则在最靠尾端出现的sep的位置将原字符串分成三部分:sep之前的部分、sep,以及sep之后的部分,并将这三部分以一个三元组返回。如果原字符串中不包含sep,则返回的三元组中元素依次为原字符串以及两个空字符串。
str.rsplit(sep=None, maxsplit=-1)
从右开始以sep为分隔符对原字符串进行maxsplit次分割,返回由分割后部分组成的列表对象。如果sep未指定或指定为None,则字符串中出现的任何空白字符都作为分隔符。如果未指定maxsplit,则不限定分割次数。注意:1.如果指定了sep的值,则对原字符串中连续出现的sep,作sep间隔的空字符串来处理的,例如,"ab@@a".rsplit()的结果是['ab', '', 'a'],而不是['ab', 'a']。2. 如果未指定sep,则原字符串中连续出现的空白字符按一个分隔符来处理,如" a b ".rsplit()的结果为['a', 'b']。
str.rstrip([chars])
返回将原字符串的尾端字符串chars去除后的字符串,如果没有指定chars,则默认移除原字符串所有的尾端空白字符。
str.split(sep=None, maxsplit=-1)
与rsplit类似,不同的是该方法是从左开始对原字符串分割的。
str.splitlines([keepends])
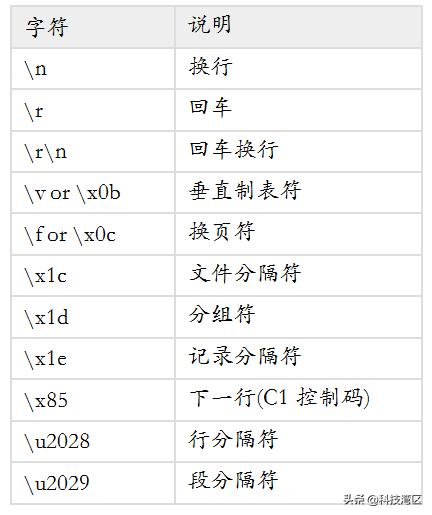
返回由原字符串中的行组成的列表对象。如果指定keepends为True,则每行包含行尾分隔符(如果有的话),否则不包含。下面列出了被视为行分隔符的字符:
str.startswith(prefix[, start[, end]])
如果原字符串中区间[start,end-1]上的字符串以prefix开头,则返回True,否则返回False。默认情况下,start为0,end为原字符串长度。
str.strip([chars])
返回原字符串首尾去掉chars中字符后的字符串。chars默认为空白字符。
str.swapcase()
返回原字符串中小写字符转换为大写字符,大写字符转换为小写字符后的字符串。注意:对于一个字符串s,s.swapcase().swapcase() == s不一定总是成立的,例如'ß'.swapcase().swapcase() =='ß'结果为False。
str.title()
返回原字符串中每个单词首字母大写其余字符小写的字符串。注意:该方法使用的算法是将一组连续字母作为一个单词,这样一来那些字符串中的表示缩写或所有格的撇号'就被作为单词分界符了。
str.translate(table)
返回一个原字符串按照table中指定的映射规则产生的字符串,其中table必须通过__getitem__()方法实现了索引功能对象,通常为映射对象。
注意:1. table中的键必须Unicode码点序号时映射转换才起作用。 2. 由str.maketrans()生成的dict对象可用于该方法.
str.upper()
返回原字符串所有区分大小写字符转换为大写字符后的字符串。注意:如果原字符串中含有不区分大小写的字符或者结果中含有Unicode分类不是"Lu"字符,例如分类是"Li"的字符,则对结果字符串调用isupper()为False。
str.zfill(width)
如果原字符串长度小于width,则返回在原字符串左侧填充0(如果原字符串首字符为+或+,则填充位置在首字符后)至长度为width的字符串。如果原字符串长度大于等于width,则返回原字符串。
【至此关于str的方法全部介绍完毕】
python基础教程教材 Python编程从零基础到项目实战实例
¥59
购买
【结束】
篇尾寄语:万丈高楼平地起,是否具有扎实的基础决定一个人能否走远以及能走多远。Python的学习也是同样的道理!