导读
第30届的神经信息处理系统(Neural Information Processing Systems,简称NIPS)大会在12月初召开,地点位于欧洲最美的城市之一 —— 西班牙巴塞罗那。Google Brain 的 Eric Jang 在参会后做出了如下几方面的总结:
-
2016年对 AI 研究的现状和趋势
-
我喜欢的演讲和论文
-
对2017年的预测
-
杂谈
人工智能研究的现状:2016年的主要趋势
学术界,工业界以及广大民众对人工智能的关注度的增长就像坐着火箭一样直线上升,2016年的 NIPS 大会的注册人数整整提高了50%。
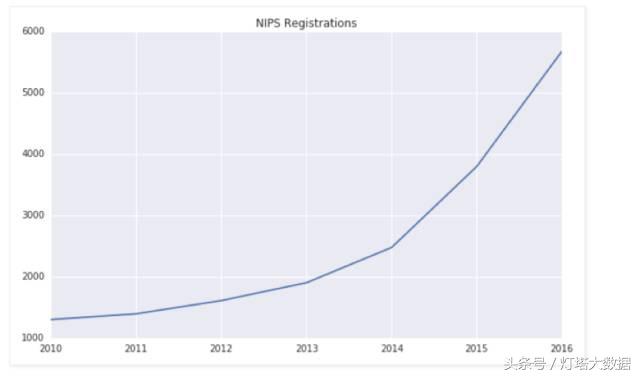
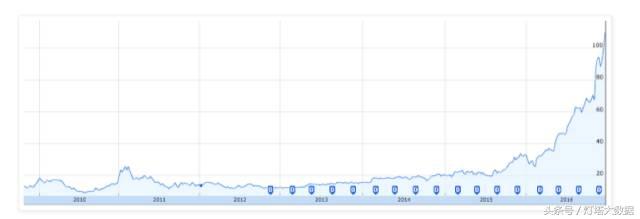
而 Nvidia,这个给深度学习提供基础硬件能力的公司,在2016年股票涨了很多也就不是一个偶然了。
我们看到,在2016年,深度学习接连在各个领域取得了成功:超越人类的围棋程序,超越人类的语音识别,超越人类的翻译水平,和超越人类的唇语阅读,还可能有超越人类的驾驶技术(在这个领域并没一个衡量标准)。这些成果引人注目,因为很多 AI 研究者们相信,要解决相关问题,需要先解决基础机器智能问题。
现在比较流行的研究主题(GANs,RL,生成模型,非监督学习,机器人,替代训练 DNN 的技术),在我们创造出全能 AI 之前,都是亟待解决的非常重要的问题。然而,他们现在还没有在工业界产生很大的商业价值,所以传统的监督学习还是发挥着不可替代的作用。
传递学习(Transfer learning),采用域适应和半监督的方法缓解了深度学习对数据的渴求,现在发展的也很好。
2016年发布的各种(论文,软件等),无论在质量还是数量上都是惊人的,我甚至不知道还有新想法值得研究者们进行进一步的工作,在大会上,我感觉很多论文和 poster 的想法都很相似。
GANs
我无法想象还有比 Yann Lecun 对 GANs 更高的评价,在 Ian Goodfellow 提出生成对抗模型(GANs)后,他说:“GANs 是在10-20年来机器学习领域最大的突破。”
如果你对 GANs 还不太熟悉,这里有一个简单的对 GANs 的解读。GANs 最初的想法是用来生成图片,但是研究者们已经把它应用到了比如增强学习,领域适应,安全 ML,压缩等等算法上。GANs 的核心是“对抗方法”,我们在训练网络的时候,不仅仅要有一个生层模型,还需要一个判别模型或者策略模型。
那为什么 GANs 这么火呢?在它还没有普及开来之前,很多研究者将机器学习视为一个优化过程,比如:最小化 loss 或者最大化 reward。GANs 摆脱了这种范式,它至少解决了两个“模型”之间的纳什均衡问题,使得这两个“模型”之间能够互相适应。
研究届对 GANs 如此重视,是因为很多模型的损失函数非常难设计。在很多过参数化的问题中,优化过程瞄准设计缺陷,并且使得结果达到最小化,但是结果往往并不是我们想要的。
例如,如果我们要对图片压缩/重构的模型中的错误进行最小化,我们通常会提出一个很简单的损失函数(例如,结果与真实值之间的欧氏距离),这会导致非常差的结果。这个设计缺陷是我们对整体图像空间并有一个良好的感知,而 GANs 可以做到利用“对抗学习”逼近最佳的隐形函数(理论上)。
Ian Goodfellow 提供了一个针对 GANs 的非常好的教程。GANs 现在主要挑战是防止判别器和生成器之间的简并平衡。这类问题通常表现为模式崩溃(生成器在单个样本中学习单个紧密模式),或者判别器对生成器的“超压”现象。但我并不担心这个问题,我相信随着时间的推移,那些经验丰富的研究人员会让 GANs 变的好用。就像以前人们认为只有 Geoff Hinton 能够训练DNNs,但是现在并不是这样。
Maciej Ceglowski 在一篇热门文章中说指出了对于 AI 的定义:我们没有办法定义智能(除了对我们自己),我们甚至都不知道到底它能不能被量化。我们仅仅知道,人类的智能可以是一个权衡手段,可能所有超越人类智能的东西都会被人类削弱,让他们把时间都花在悟佛上。
智能来自于优化还是平衡?或者我们可以引用 Yann 的话:“一群黑客真的只是碰巧在一起工作?”AI 的研究现在还没有准备好回答这个问题,但是我乐观的认为,GANs 的研究将会弄清楚什么样的问题是平衡发现还是最小化问题。
Deep RL
人们通常认为增强学习(RL)只能用来玩电脑游戏或者控制机器人,但是RL方法远远不止这些用途——所有有空间和时间连续性的 ML 问题都能从 RL 技术中获得好处(例如,像素序列)。RL可以创新的去解决很多问题,比如翻译。
PieterAbbel 和 JohnSchulman 给出了关于策略梯度的教程。John 还针对深度RL研究的细节做了演讲。这篇演讲中包含了非常多的细节,如果没有这个演讲,我可能要花费很多年才能弄明白一些问题,所以我强烈推荐那些从事RL研究的人看看这个演讲。
让人惊讶的是,ChelseaFinn 在最近发表的一篇论文中指出,逆向 RL 问题中的一些类别在数学上拥有和 GANs 等价的公式。
有些人问深度 RL 研究小组,RL 有哪些最具挑战性的问题?RichSutton 和 RaiaHadsell 表示,最具挑战性的问题是子任务和子目标的学习,比如现有任务的分层表示。最后,ChelseaFinn 讨论了样本复杂性问题:我们得不断重新训练 RL,或者进行迁移学习。毕竟,人类可以快速上手新游戏,因为他玩过其他游戏。
Bayesian DeepLearning(贝叶斯深度学习)
我认为现在最有希望的研究项目是深度神经网路和图模型的结合,被称为“贝叶斯深度学习”。是离应用最近的一个项目。
KyleCranmer 对利用可能性推断方法找到 Higgs Boson 存在证据的演讲让我感到震撼,根据我的理解,它用了变分模型来逼近模拟11层粒子探测器:
在会议中,还出现了很多有趣的变分推断技术:
-
对称变量推断——一种防止模型陷入 Gaussian VAEs 的方法
-
拒绝性抽样变量推断——利用拒绝性抽样进行重参数化的方法,可以训练 gamma,beta,Dirichlet 等等多种分布。可以说,这是巨大的进步。
-
利用变分贝叶斯的鲁棒推理——提升变分后验的鲁棒性,用以选择先验和 likelihood。
-
ELBO 手术——ELBO 是训练 VAEs 时最常见的变分下届,在这片文章中提出了一种改进的 ELBO 方法:将 KL(q(z|x)|p(z)) 项分解成索引码互信息项和边际 KL 项 KL(q(z)|p(z))。实验表明,后者的作用是相当大的,这表明我们将注意力集中在改进先验上。这项工作之所以这么重要,是因为它为训练 VAEs 的人提供了一个方便的调试工具。
-
运算符变量推断,流归一化和Real-NVP给了我们得到更丰富的后验的方法。
-
变化有损自动编码器
开放研究
今年的 NIPS 出现了非常多的令人振奋的软件。首先是 OpenAI 发布了自己的Universe,是一个可以让所有程序访问 OpenAI Gym 的接口。这意味我们可以让 RL 与 Chrome 浏览器或者 Photoshop 之类的软件交互。
DeepMind 发布了 DeepMind Lab,提供了 FPS+3D 的实验环境,年初,微软发布了 Malmo 项目,可以在 Minecraft 里训练 AI。这些软件可以让我们体验一些有趣的实验环境,可以让初学者和学生们实现他们自己的想法。
以上这些是宣传做的比较好的软件,还有一些公司和学术机构发布了一些基准软件,深度学习框架,和训练数据等等。
深度学习能够这么火,是因为人们有了更多的计算资源,数据和更好的算法,但是我认为还应该再增加一个:前所未有的无障碍的对 ML 的研究。非常多的人已经在用 OpenAI gym 做 RL 项目,还有很多研究代码被公布出来,以供其他人使用。这些工作让学生们不再需要些那些实验环境的代码,让他们专注于学术研究。
大科技公司向社区开放自己软件,这真的很棒,我认为比那些在会议上发表的论文更让人印象深刻。
我喜欢的演讲和论文
我没有精力去看所有的论文和演讲,我把我看过的论文,演讲和海报都做了笔记,我从中挑选了一些我喜欢的,如下面的列表所示:
-
Andrew Ng 做了一个关于怎样找 ML 模型的问题的教程,我认为这是初学者必看视频。我给大家一个他在深度学习夏令营里面讲的和本次演讲内容类似的视频。
-
固定点的信念传播——作者将信念传播的收敛条件制定为多项式的解。这是我想到是否可以利用这个方法让非线性动力系统和统计推断结合起来。
-
随机深度的深度网络——用逐层的 dropout 方法,可以训练大于1000层的 ResNets。
-
层标准化——类似于批标准化(batch norm),这种方法可以防止连续隐层之间的协方差偏移。此方法的优点是层范数不引进层内变量的梯度变化。
-
深度继承增强学习——我很喜欢这篇论文,因为集成了 model-based 和 model-free 这两种想法。像 DQN 这样的 model-free 的方法要花费很长的时间来学习足够的低级特征,因为我们经常要用一个与图像特征不直接相关的标量去训练一个 CNN 网络。这片论文的思想是,用无监督的方式来学习后继特征,然后基于这些特征单独的学习简单的线性函数。这边论文虽然很多但是相当不错。
-
Drew Purves 的智能生物圈。这个演讲在NIPS中略显奇怪(我想是因为 PPT 中的图片太好了分散了注意力,使我没办法理解 Drew 说的一些细节),但是我想,这个演讲,对于那些想要退一步,去思考什么是“智能”的研究员们非常重要。他的基本思想是,“智力”是超越大脑之上,一种简单到像自我复制的 RNA 一样的,在进化过程中表现出智力的一种东西。大自然是分裂的,循环的和模糊的,不是我们现在使用的模拟环境中的简单性的 AI。Drew 提出的一个非常有趣的观点是,在生物圈中,没一个有机体都是另一个有机体的资源,也就是说,每一个有机体的学习和适应并不是独立于其他有机体的(让我想起了 GANs)!如果你也对这个环境+智力的想法感兴趣,相似的论点已经在语言学和神经学中出现了,你可以看相关论文。
-
输入凸神经网络——作者在 Deep RL workshop 环节中贴出的一个非常有趣的海报。他们能够通过将 Q 函数相对于动作向量进行参数化(并且相对输入状态是非凸的),利用其求解连续的 Q 函数。这让我们可以在连续动作问题里面找到高效的 DQN 策略。
-
为过去引入快速参数——可以视作 LSTM 的替代品,貌似表现的更好一些。
-
阶段性 LSTM——LSTM 结构中学习自适应时间尺度的方式,隐藏状态在学好的频率下进行更新。这对于在任意采样率的数据中进行学习时是有效的,例如,从基于事件的视频传感器中采集的数据(可以自动解决一些计算机视觉中的难题,比如混叠和带宽约束)。Zurich lab 研究了一款基于事件的相机,我很想看到他们是怎样应用 ML 的。
-
最小化定时二次函数——当我看到这个海报的标题时我困惑了。我不太理解这其中的数学原理,但是他们的算法非常简单:从一个矩阵中进行亚采样然后解这个矩阵,所得到的最小化值即为原始系统的最小化目标的近似。当我们遇到一个需要在很大的搜索空间中求解的问题时,例如寻找最佳组合问题,我们可能会发现,解决方案的值比解决方案本身更具信息量。
2017年的预测
-
SGD+后向传播仍然是训练深度网络的最好方法。
-
好的传播学习,域适应,或者多任务学习会是一个重大进展。
-
聚合方法(例如,训练10个不同的网络然后将预测结果做均值)会提高所有ML任务的2%-5%性能。
-
集合 model-based+model-free 思想的RL方法会普及。
杂谈
-
这些都是一些转述专家和发言人的意见。如果你认为我歪曲了您的意思,希望您不要犹豫,您可以用任何方式指出我的错误,我都会改正,
-
波士顿动力公司展示了一系列非常有趣和令人印象深刻的机器人演示。他们的主要方法大概是使用行为忠于固定模拟规划模型的高精度硬件再加上一个强大的控制机制来处理缺陷。虽然说现在看来机器学习似乎并不是一个高优先级的机器人控制方法,但我仍认为有相关的学术研究是一件不错的事情.。很难说最终哪一个会做得最好。我真心希望 Alphabet 永远不会把它们卖掉。他们的东西真的很棒。
-
苹果已公开宣布将开放他们的研究成果。我认为,一个产品驱动的研究文化可能面临的最大问题是如何跟进其研究进度(而不仅是最大限度地引用,如在学术界)。
-
某些支柱贸易公司利用神经网络进行价格预测。我曾认为所有的贸易公司在使用神经网络时,都过于在意模型的可解释性。
-
说到对冲基金,很多顶尖的对冲基金和交易商店来NIPS来经营生意,但令人吃惊的是与会者对神经网络方面相关的内容并不是很感兴趣(他们看起来对苹果,Facebook,谷歌,DeepMind 等更感兴趣)。然而在东海岸的大学招聘会上,这些角色又被对调了。NIPS 人才库似乎对于技术和开放式的研究的兴趣要远远地高于赚钱。
-
鹿,尽管是“食草动物”,有时会吃幼鸟的头来补充钙元素(这是 Drew Purves 说的)。人类,拒绝命运给你们贴上的标签!
-
工程原理源于稳定发展的大脑(Saket Navlakha)-有趣的是,修剪无用的神经元似乎往往比种植其他神经元更有利于学习。
-
Yoshua Bengio ——当给生成模型一个隐码时,他们会具有更好的范化性。
-
在 Brains and Bits 环节有人提出为什么我们要花费如此多的精力来研究人类,而不是更简单的动物,例如章鱼和鸟。Yoshua 说,将重点放在简单的模型可能会导致研究人员忽视如何才能更智能的一些基本原则。我同意这个观点,但不同意其说法——我认为很简单,这是我们人类的 AI,而不是章鱼和鸟的 AI。我认为我们在建议一个人类AI前,应该先建立一个章鱼的 AI。
-
Yann Lecun 认为模型的可解释性被高估了:我们有解释的算法很多,但我们仍然缺乏一个能建立可以用于浏览我们的自然世界的复杂性的通用学习系统的基本原理。
-
Yann 不喜欢 log-likehood 方法。Log-likehood 在一些特定模型下才能得到好结果,例如 PixelCNN,但是一开始模型就不是很好,那么 log-likehood 会变得无意义。
-
Andrew Saxe 在 Brain and Bits 问了一个非常好的问题:在人工智能的研究领域里的边缘问题是什么?Demis hassabis 回答他,人们认为对想象力,做梦和意识的研究是不科学的,但是他们可能在5年内变成很实际的问题。Terry Sejnowski 回答说,了解睡眠是至关重要的,因为它更可能是一个可计算的现象。Yoshua 想知道怎样做到“理解某事”,比如,神经网络和其他模型可以对计算和统计进行学习,但是如果做到提取语义?
编译:TalkingData
作者:Eric Jang,Google Brain research engineer,从事机器人方面的研究工作。
个人主页:http://evjang.com
来源:TalkingNews
【灯塔大数据】微信公众号介绍:中国电信北京研究院通过大数据技术创新,自主研发了业内领先的“灯塔”大数据行业应用创新平台,灯塔面向市场研究、广告营销、商业地理、金融征信、人力资源等诸多行业领域,提供零售研究、消费者研究、店铺选址、精准营销、泛义征信,背景调查等服务,助力企业在大数据时代扬帆远航。
微信公众号【灯塔大数据】关 键字信息:
【IDC】 *载下**IDC报告原文
【六个关键词】 *载下**运营商大数据PPT
【大数据日】 *载下**演讲材料
【十月融资】*载下**2016年10月投融资月报
【网络安全】获取国民网络安全报告全文
【23个理由】*载下**《大数据让你兴奋的23个理由》电子书
【思维导图】*载下**12种工具的获取方式
【 灯塔 】 查看更多关键字回复
