
文字/夏有喃风
编辑/夏有喃风

引言
保护以深海珊瑚为基础的脆弱海洋生态系统(VME)免受人类影响,这些生态系统的管理过程因关键的不确定性而受到削弱,特别是底拖网捕捞,是全球海洋保护所面临的一项重大挑战。
在本文中,我们提出了一个解决方案:一个深度学习系统,能够在比以往更多的海底图像中自动识别其他海底基质中的珊瑚礁。

通过使用先前注释的数据集,我们对大约70,000个分类图像("片段")进行了训练,这些图像包括六个底栖基质类别,其中包括珊瑚礁的一类——"珊瑚矩阵"。
本实验中,在数据集的清理、迁移学习和超参数优化后,我们改进了模型的性能,最终训练的模型达到了98.19%的验证准确率。

这些自动注释的图像衍生数据的大量可用性将在以下方面改善对深海珊瑚脆弱海洋生态系统影响的空间管理:
(1)通过交叉验证和性能管理区域,改进预测珊瑚分布和丰度所需的空间模型;
(2)建立海底珊瑚丰度与捕鱼作业期间上岸的珊瑚副渔获物之间的经验关系。

一、VME研究进展
脆弱的海洋生态系统(VME)具有独特或稀有的海底栖息地特征,对生态功能至关重要,同时也非常脆弱,而且动物群体的生活史特征使其难以从干扰中恢复。
深海硬珊瑚形成的"珊瑚礁"体现了这些特征的脆弱性和恢复缓慢性,这些生态系统的空间范围只识相对有限的环境中,管理干扰的有效解决方案仍然难以确定。

使用相机调查提供了一种改善VME分布知识的前瞻性方法,因为基于图像的调查为很少采样的深海生态系统提供了对动物群体和栖息地的宝贵见解,并可用于为预测其在广阔区域分布的空间模型提供信息。
图像衍生数据具有多种吸引人的特点,包括非侵入性、定量性、可扩展性以及能够广泛吸引利益相关方参与。
获取大量高质量的原始图像相对容易处理,但对图像进行定量注释以识别、一致分类和记录甚至相对简单的感兴趣特征(如底栖基质或VME)是耗时且劳动密集的过程,这严重限制了分析数据量的瓶颈。

由于过去十年机器学习(ML)领域的巨大进展,现在有一种有效且可靠的方法可以克服注释瓶颈。
深度学习(DL)是ML的一个子领域,它使用由多层人工神经元组成的深度神经网络,逐步从输入数据中提取越来越复杂的模式。
在本文中,我们详细介绍了如何开发和应用现代深度学习方法来识别石质珊瑚礁生态系统,并将其与深海海山上的其他底栖基质类型进行区分。

由基质形成的巩膜珊瑚构建的深海珊瑚礁被全球公认为重要的脆弱海洋生态系统,因为与周围海底栖息地相比,它们增加了结构的复杂性,并支持了更高的生物多样性和生物量。
形成珊瑚礁的珊瑚通常限于特定的深度范围,如丘陵、"山丘"和海山等海床上升特征,它们从局部加速洋流中增加的食物供应中受益,但并不在所有具有这些特征的地方都有珊瑚礁存在。

由于深海底拖网渔业的影响,珊瑚礁栖息地引起了国际保护的关注,这些渔业通常以与具有相同特征的橙色粗糙Hoplostethus atlanticus的密集聚集相关联。
尽管已经有几项研究探索了深度学习在包含珊瑚的海洋环境中的应用,如珊瑚图像分类和珊瑚调查图像的语义分割,但我们的研究是首次将深度学习系统应用于基于珊瑚的VME的深海图像。

二、数据集与预处理
本项研究采用了由CSIRO设计和建造的深度拖曳相机系统,每隔5秒收集一对立体静止图像和视频数据,沿着通常长约2公里的横断面,在600至1800米的深度范围内进行采集。
该调查的主要目的之一是收集数据,以记录和定量模拟珊瑚礁栖息地的空间范围。
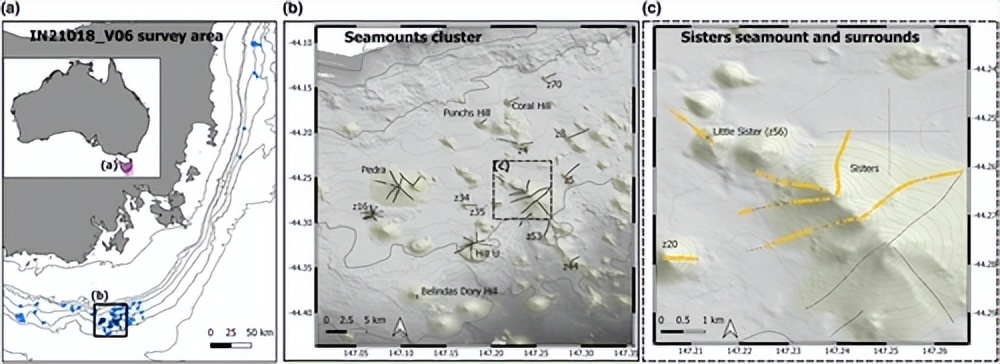
我们对5949张静止图像(约占总数的9%)进行了手动注释,通过对测量样方内随机分配的点进行分类来确定底物覆盖率的百分比(包括巩膜珊瑚基质和非生物底物类型),并计算了每个类别的相对比例。
我们使用SeaGIS开发的EventMeasure软件中的摄影测量方法,在每对立体图像的端口侧图像上生成样方,并将其导入TransectMeasure软件中。

我们对每平方米的点数进行了标准化,因为图像的视野和样方大小会随着相机系统的高度变化。
在最终的注释集中,80%的样方大小在2到8米之间。
深海珊瑚礁主要由一种名为Solenosmilia variabilis的石珊瑚形成,它通过连续发育和分支的新珊瑚虫生长而形成,形成生物源的"珊瑚基质",并逐渐积累形成高出海床的"珊瑚礁",长度可能达数公里。

点注释方法用于注释基质和珊瑚基质,以生成覆盖率的测量值。
我们注释了一个单独的生物群数据集,用于识别和计数个体形态分类,但该数据集不适用于我们在本研究中使用的深度学习方法。
所有数据点都由一个注释者进行标记,以确保一致性。

重新利用IN2018_V06的图像数据进行机器学习(Machine Learning)训练可以轻松获取大规模标记图像分类的训练集。
原始数据集中的点注释之间存在内在差异,并且使用包括注释点周围区域的片段可能会导致嘈杂的机器学习数据集。

为了减少训练数据集中的噪声,进行了手动清理过程,删除了具有多个底物类别模糊、动物群或阴影/高光在剪断中产生噪声的剪断。
清洁过程对于天然异质基质类别的影响更为显著,这些基质类别代表了中等碎屑大小的未固结材料(生物成因碎石、鹅卵石/砾石 + 鹅卵石),它们通常同时出现和/或作为岩石或沉积物上的单板存在。
在图像领域,卷积神经网络(CNN)能够利用多个卷积层和池化层提取出具有区别性的图像特征,这些卷积层和池化层通常与全连接层构成一个典型的分类网络。
分类网络利用图像特征来预测输入图像的类别,这是通过最小化损失函数来实现的,损失函数在模型做出错误预测时对其进行惩罚,并通过改变惩罚程度和调整模型权重来鼓励模型做出更好的预测。
基于CNN的图像分类模型取得高精度的主要因素有两个。

首先是多样化的大规模图像数据集:我们获得的数据集相对较大,原始版本包含约140,000个图像片段,经过清理后版本包含约70,000个图像片段,并且包含六个预定义类别的不同示例。
这为模型提供了足够大的训练集,以学习区分复杂示例,并在具有相似数据分布的验证集上进行稳健的性能评估,验证集对模型性能进行了可靠的基准测试。

其次,CNN特征提取器的优化与模型目标和数据集相关:在基准数据集上实现最先进性能的特征提取器可能在特定领域的图像上表现次优。
复杂的特征提取模型会带来很高的计算成本,而只能获得较小的精度提升。
特征提取模型的选择和优化通常是经验性的,并受到模型目标和可用数据集的限制。

我们采用迁移学习的方法,通过使用在包含超过14,000,000张图像的ImageNet数据集上预训练得到的权重初始化CNN特征提取网络。
预训练数据集的规模明显大于目标数据集,这使得模型可以通过从大量数据中学习高级图像特征(如形状、边缘、颜色变化等)来获得更好的性能。
为了证明迁移学习对我们的数据集的有效性,我们选择了 ResNet50 网络架构并训练了2个具有不同迁移学习阶段的模型。

随机初始化:在目标数据集上使用随机初始化的权重进行模型训练,而不应用迁移学习。这种方法的训练时间较快,因为只更新最终分类层的权重,但特征提取模型对于目标数据集来说并不是最优的。
固定预训练:模型使用预训练的ImageNet权重进行初始化 ,且在整个训练过程中保持所有特征提取权重不变。只有最终的分类层在目标数据集上进行训练。这种方法的训练时间较快,因为只更新最终分类层的权重,但特征提取模型对于目标数据集来说不是最优的。

对于这些横断面,我们使用人工注释者标记的经过清理的片段集合进行分类,并直接与人工标记进行比较。
我们将由人与机器得出的基板覆盖百分比沿这些横断面生成的图像可视化在采样的海山特*地征**图上,包括六种基质类型中任何一种的最大覆盖差异。
对于海山集群比较,我们比较了原始人类和机器生成的注释在同一组图像上珊瑚矩阵的深度分布。

我们选择了来自IN2018_V06数据集的注释图像的一个子集,我们在每个图像样方内以每平方米五个点的相同密度生成了一组新的随机分布点,并通过以这些点为中心裁剪224×224像素的图像块来创建一组新的片段。
我们通过随机旋转这些片段,从经过训练的深度学习模型中获取预测,并选择预测数量最多的类别,对这组新片段进行了五次分类。

三、深海珊瑚模型性能与数据集清洗
我们在原始(未清理)和清理后的深海珊瑚分类数据集上训练了两个 ResNet50 模型,以衡量数据清理过程的影响。
每个模型都使用 Adam 优化器训练了 100 个 epoch,学习率为,并且所有模型权重都是在训练期间随机初始化和更新的。
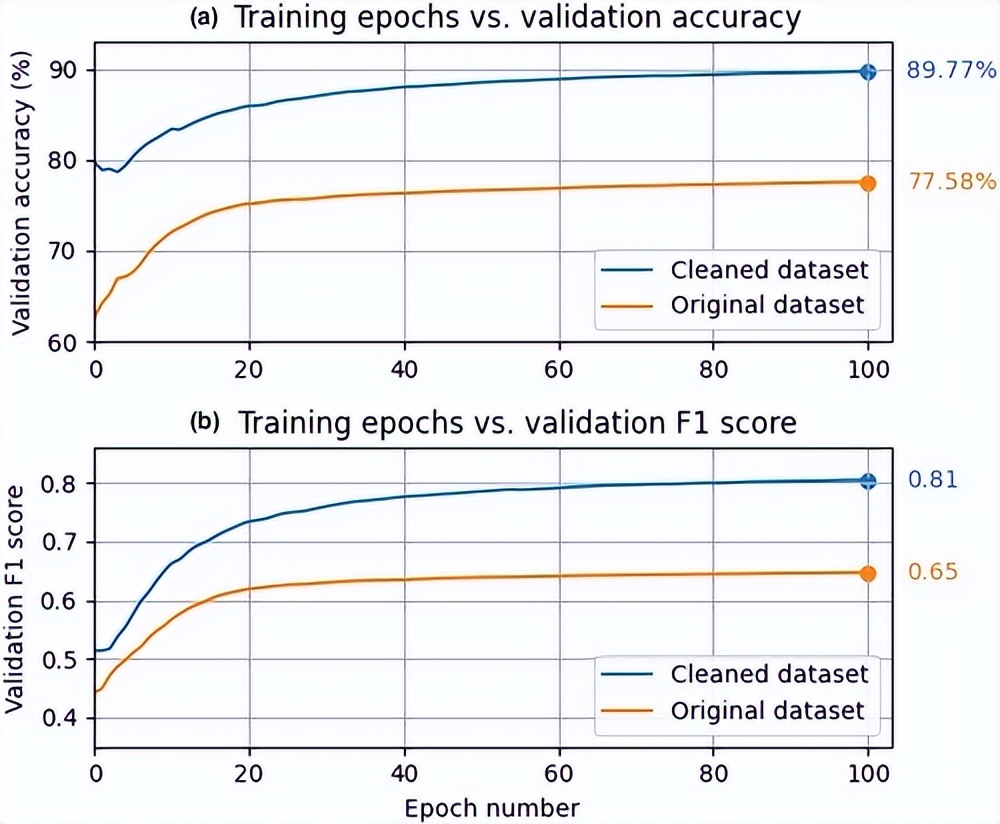
在原始数据集上训练的模型在验证数据集上的最终分类准确率(以下称为“验证准确率”)达到 77.58%,而在清理后的数据集上训练的模型显示出 12.19% 的改进,最终验证准确率达到 89.77 %。
两个模型的 F1 分数显示出相似的响应,清理后的数据集模型优于原始数据集模型,最终验证 F1 分数达到 0.81。
数据集清理过程提供了卓越的分类性能,因此所有进一步的实验都是使用清理后的深海珊瑚分类数据集进行的。

固定预训练方法在学习效率方面表现较低,经过 200 个 epoch 后,最大验证准确率为 92.05%。
在整个训练过程中,训练准确率始终落后于验证准确率。
这是由于训练集和验证集的大小差异(80%/20% 划分)以及仅更新分类网络权重的限制所导致的。
相比之下,预训练和微调方法比随机初始化和固定预训练方法更有效地学习,在最高验证准确率达到了96.82%。

这种学习加速是因为整个网络从大规模的 ImageNet 数据集中学习的预训练权重开始,然后微调整个模型到目标数据集。
我们比较了 Torchvision 中的 16 个基线 CNN 模型架构,并在清洁的深海珊瑚分类数据集上对每个模型进行了 100 个时期的训练。
许多经过训练的网络架构都产生了高度准确的模型,其中 InceptionV3 和 ResNeXt50 获得了最准确的结果。

比较了四种 ResNet 网络架构的准确性结果后发现,增加网络深度对该数据集的分类准确性没有显著影响。
这是因为底栖基质图像中所包含的二维结构信息有限,而浅层网络已能充分表示这些图像特征。
超参数是控制模型训练过程的配置值,对于 ML 模型的质量具有重要影响。

使用 InceptionV3 网络架构,我们优化了学习率的范围,并同时使用了三个反向传播优化器,包括随机梯度下降 (SGD)。
根据整体效率和性能,我们选择了静态学习率,并采用了 Adam 优化器作为后续实验的默认选择。
最终的增强策略中包含了五种最重要的增强方法,我们发现这种策略在最大化分类精度和减轻模型过度拟合之间取得了良好的平衡。

来自七个清理横断面的所有片段都由最终训练的 DL 模型进行分类,并与地面实况人类注释进行比较。
在这个 hold-out 测试数据集上,经过训练的模型的准确率为 94.91%,F1 分数为 0.87,表明人工注释和机器预测之间具有良好的一致性。
Cohen 的 kappa 度量显示 六个类别中的四个类别的人机注释之间接近完美的一致性( k > 0.85),并且 对于碎石类(支持信息 B )基本一致( k > 0.72)。

经过训练的模型用于对来自海山集群的 2361 张图像的 74,551 个新生成的片段进行分类,无需人工检查任何图像片段(无清理过程),以*拟机模**器分类的真实应用。
三类材质显示出始终如一的高模型预测置信度,在自然异质的三个碎石/砾石基质类别中报告了显著更广泛的预测置信度分布,并且受应用于训练数据集的清洁过程的影响更严重。

总结
为现实世界的应用程序构建有效的 DL 系统需要从系统设计的许多可能元素中进行深思熟虑的选择。
此过程中的挑战包括确保输入数据质量足够高且符合目的,确定最佳的 DL 架构和模型训练超参数,以及设计适当的方法来评估系统。
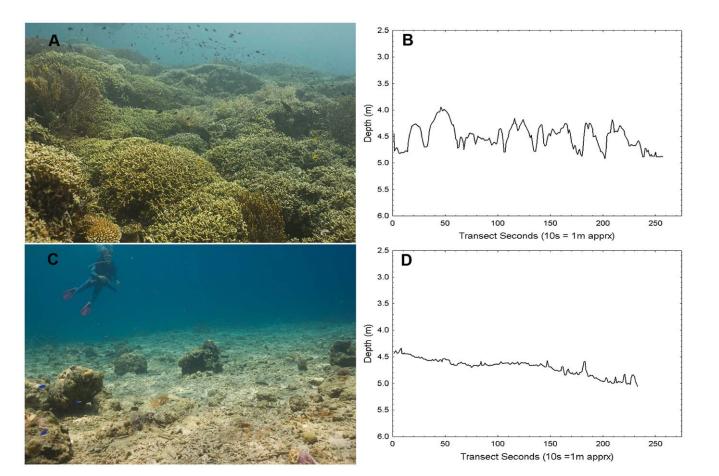
使用 snip 方法重新利用点注释非常适合形成广泛栖息地和/或在整个图像大小内没有清晰可辨形态的类——基质类型、结壳或扩散、无定形分类群、海草草甸、珊瑚基质。
网络架构选择和其他模型超参数的优化进一步提高了模型性能,导致最终训练的模型在验证数据集上达到了非常高的准确度水平和 F1 分数(分别为 98.19% 和 0.96)。

预测的覆盖百分比显示与该本地化测试数据集上的人工注释高度一致,其中包含海山基质类型的良好分布。
与模型训练期间验证数据集的结果相比,模型预测的准确性 (94.91%) 和 F1 分数 (0.87) 有所降低。
海山集群评估提供了一个重要的机会来测试经过训练的模型在未清理数据、质量图像和真实世界数据中预期的可变性上的性能。

即使在这些条件下,经过训练的模型也能做出一致的预测,根据独立观察准确识别已知珊瑚礁发生区域和深度的珊瑚礁。
对图像片段的重新检查表明,虽然鉴定了Solenosmilia在注释点下是正确的,截图显示退化的、充填的珊瑚礁已经失去了其独特的三维性质,因此它作为 VME 的功能更像是固结的碎石而不是珊瑚礁。

定量相机图像(以立体对或激光校准测量视野)是绘制海洋栖息地和动物群分布和丰度的环境数据的重要来源。
这些数据揭示了精细空间尺度(米到千米)的海床地质结构,并且对其他遥感数据(例如以相对较大尺度收集的多波束声纳)的地面实况有用。
定量图像数据提供了一种有效且非提取的方式来测量海洋生态系统(物理栖息地及其生物居民)的特性,包括由于人为影响和对管理干预的响应而随时间发生的状态变化。

在用于开发我们的 DL 系统的数据集中,,由于支持人工注释者的资源有限,所收集的图像中只有不到 10% 被注释(65,555 个图像对中的 5949 个)。
虽然对 5949 张图像完成的注释很复杂(所有 VME 动物群的数量),但现在可以以相对微不足道的成本(20 分钟对 3 个月)对整个数据进行注释以了解珊瑚礁的相对密度。

栖息地适宜性与动物群流行率和密度的弱相关性往往导致高估基于珊瑚的脆弱海洋生态系统的空间范围, 有时甚至是高估, 以及管理吸收过程中的错误解释,即较高的预测栖息地适宜性对应于较高的丰度。
需要提高对在适当空间尺度下的预测可靠性的信心,以便管理计划有效,并降低保护举措对解释和挑战开放的可能性。

提高对模型预测的信心需要交叉验证方法,这些方法可以解释使用相机调查等方法收集的独立样本数据中的空间结构,这些方法可以有效地对目标分类群进行采样。
该解决方案的一个关键要素是通过应用我们的 DL 方法快速、廉价且可靠地处理大量图像数据。

改进渔业对脆弱海洋生态系统影响的管理的另一个主要挑战是减少“可捕获性”的不确定性——上岸兼捕量在多大程度上反映了海底动物群的丰度。
与科学调查相比,自动图像处理对于处理以这种方式收集的可能大量增加的数据量至关重要。

我们对在商业拖网网上使用定制加固相机收集的数据进行的初步评估表明,我们的 DL 系统能够可靠地处理这些数据的质量合适。
这一步骤将大大扩展生成数据的可能性,这些数据将有助于实现管理深海珊瑚礁系统的各种改进成果。
参考文献
[1]花明珠,《基于网络资源的大规模珊瑚数据集构建》
[2]史存存,《基于深度学习的珊瑚礁鱼类检测与识别研究》
[3]徐兵,《珊瑚礁遥感监测方法研究》
[4]徐慧,《多时相Sentinel-2遥感影像珊瑚礁地貌分类与变化分析》