深度神经网络已被发现容易受到对抗性样本的影响,即一个人眼不可见的扰动会让神经网络做出错误的预测,对抗训练也因此被提出,通过在原始训练图片中混入即时生成的对抗性样本来提升模型的鲁棒性。我们的工作首次发现了一个有趣的现象:在随机初始化的神经网络中,隐藏着据有天生鲁棒性和准确率的子网络,即使没有经历过对抗训练,它们也能够和类似参数量且对抗训练后的模型达到一致的鲁棒性。这个现象反映出对抗训练对于提升模型的鲁棒性并不是不可或缺的,我们把这种子网络叫做鲁棒彩票(Robust Scratch Ticket)。为了更好的研究和应用鲁棒彩票现象,我们做了大量的实验去研究鲁棒彩票的存在性和性质,来理解神经网络鲁棒性和初始化和过参数化的关系。我们进一步发现了不同鲁棒彩票之间较差的对抗样本迁移性,并利用鲁棒彩票构造了一个简单有效的防御手段。我们的工作为研究神经网络彩票现象和鲁棒性的关系提供了一个新的角度。我们发现在随机初始化的神经网络中存在一些子网络具有天生的鲁棒性,即他们不需要太多的训练便可以获得不错的表现。
本期AI TIME PhD直播间,我们邀请到美国莱斯大学博士生——傅泳淦,为我们带来报告分享《鲁棒彩票现象:藏在随机初始化神经网络中的鲁棒子网络》。
傅泳淦:美国莱斯大学的三年级博士生,本科毕业于中国科学技术大学少年班学院,现导师为Yingyan Lin教授。他的研究方向是通过协同设计AI算法(剪枝,量化,神经网络搜索,对抗训练)和加速器架构,提升AI应用(分类,超分辨,语音识别)的高效性和鲁棒性。他在NeurIPS, ICML, ICLR, ICCV, MICRO等AI算法和架构会议中发表过10+篇一作论文。
01
Background and Motivation
在网络中加入一些人为构造的noise,会使得模型做出全然错误的预测。人们在解决这种问题的时候,最好的解决办法之一便是adversarial training,即人们会在训练模型的时候混入一些adversarial example。这样可以让我们训练的model获得较高的robustness。
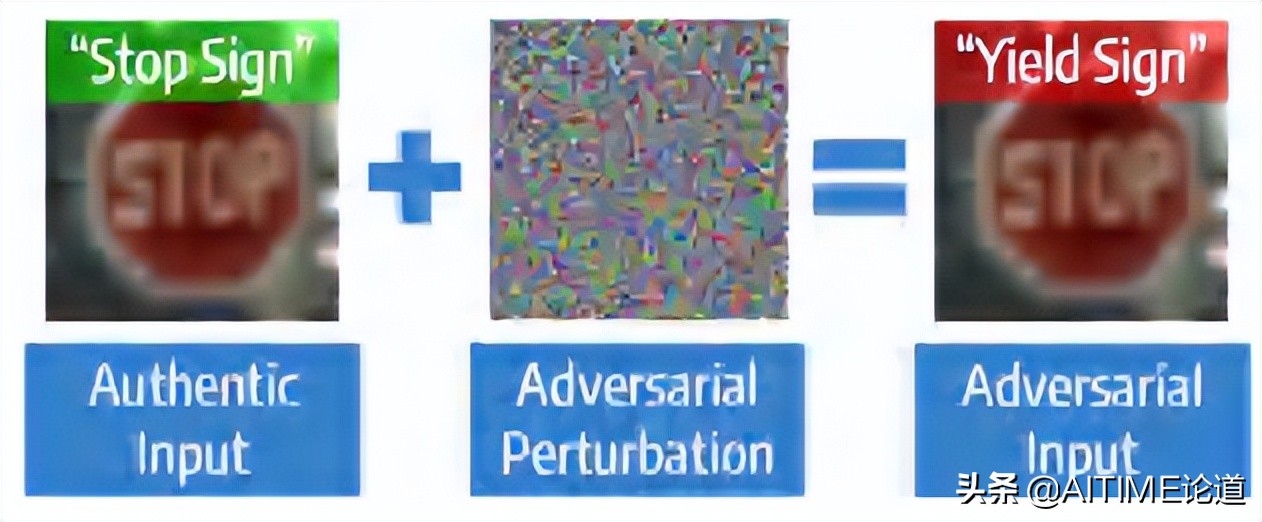
人们同时发现过参数化是实现model robustness的一个重要条件。越大的model越不容易被attack。这样就造成一个困境——神经网络的robustness和efficiency看起来是矛盾的。因为越大的网络会具有更高的robustness,但是他的efficiency会越差。比如,当我们把这些网络deploy到我们现实生活中的硬件设备上的时候,在Limited on-device resources条件下我们是没办法扩大神经网络的。
我们想要通过构造一个robust sparse network去同时保证robustness和efficiency。我们启发性的工作如下:
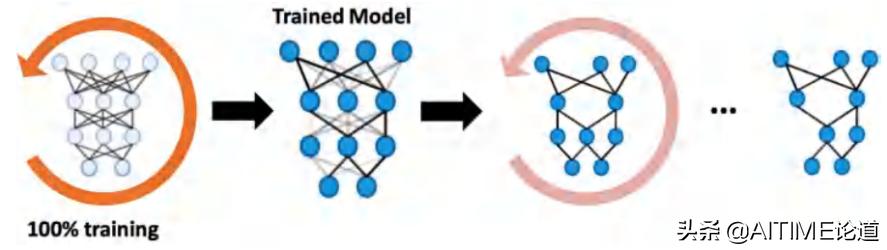
在DNN网络中天然存在着一些子网络,可以被独立训练出来并与DNN有着接近的准确率。
找出来这些Subnetworks (LTs) 需要对模型进行反复训练和pruning,得到最终的LTs
我们是否有可能在一个随机初始化的网络中找到一个Subnetwork,而且具有天生的鲁棒性不需任何的训练?
02
Key Findings
我们发现了在一个随机初始化的神经网络中存在一些Subnetworks,并具有天生的鲁棒性。这和LTs是截然不同的,因为LTs需要经历一些列的training和pruning才能找到。但是我们提出的RSTs并不需要如此繁琐。
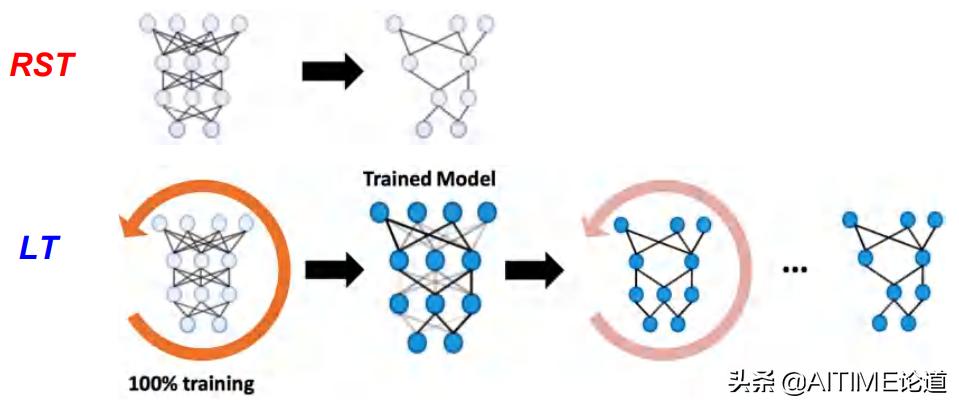
- RSTs和LTs的不同之处:
- 初始的dense网络和找出来的RSTs都不需要被训练
- RSTs存在的有趣之处:
Random networks → Random prediction
Naturally trained models → Near-zero robustness
但是RSTs既是从随即网络中找到的且没经过任何训练,就能具有decent natural 和 robust accuracy。
03
Adversarial Search: 找出RSTs
我们如果要从随机初始化的网络中找到robust subnetworks,需要满足两点条件:
- Make the search process aware of robust training objective
- Ensure the sparsity of the drawn subnetworks
因此,我们提出了一个Adversarial Search,其目标函数如下所示:

M^就是我们的目标。
04
Robust Scratch Ticket: The Existence
实验设定
- 我们在3个datasets和4个networks上进行了Robust Scratch Ticket的实验:
- ResNet-18/WideResNet-32 on CIFAR-10/100
- ResNet-50/101 on ImageNet
- Model initialization: Signed Kaiming Constant Initialization (by default
- Sparsity pattern: element wise (by default)
- Attack setting: PGD-20 with ε=8 (by default)
我们可以发现在各种network和datasets都可以发现RSTs的存在。
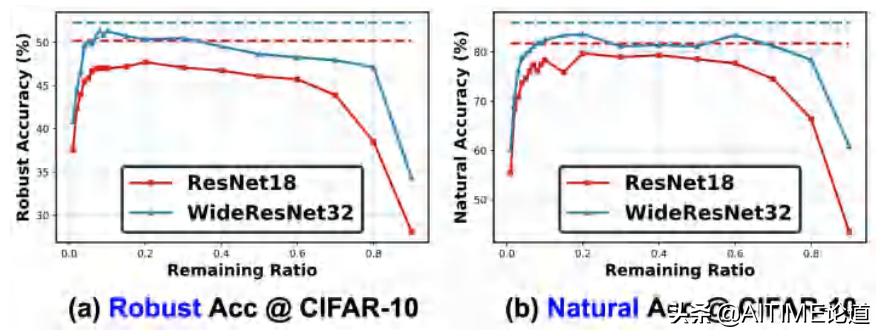
横轴:代表在一个network中有多少的位置被保留了下来
纵轴:不同颜色的线代表了不同的network,虚线代表着dense network在做了adversarial training后能达到的最高Robust Accuracy。
在很广泛范围内,我们的RSTs与虚线代表的结果保持了相差无几的Robust Accuracy。
我们也随之发现在很广的范围中找到的RSTs与做过adversarial training的network相比,有更好的鲁棒性和准确率表现。
- RST (90% sparsity) @ WideResNet-32: +1.14%/+1.72% robust/natural accuracy with -60% parameters vs. the adversarially trained ResNet-18
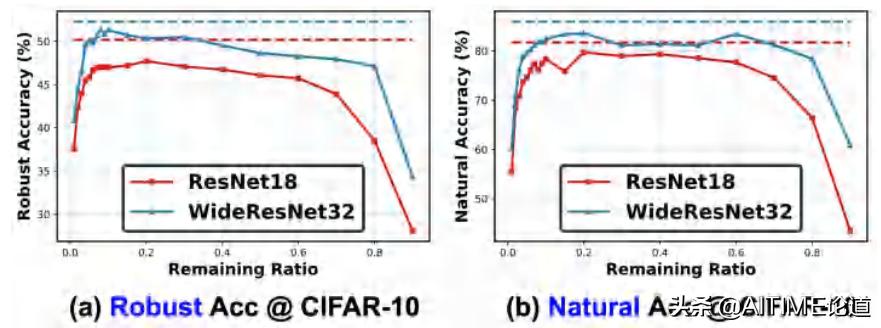
从参数化程度较高(更大)的network中识别出的RSTs比从参数化程度较轻的network中识别出的RSTs具有更好的robust/natural accuracy。
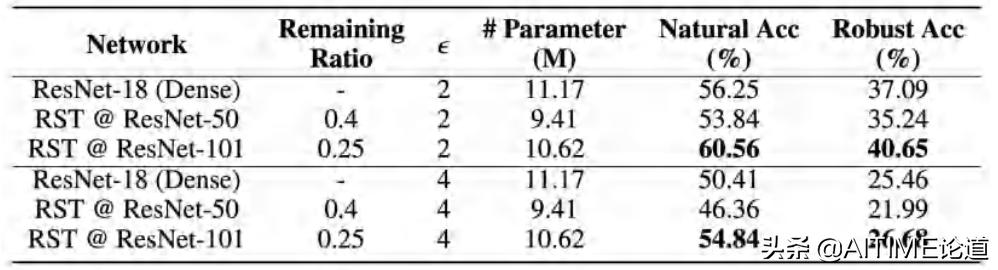
我们在不同的setting上也进行了很多实验。

05
Robust Scratch Ticket: The Properties
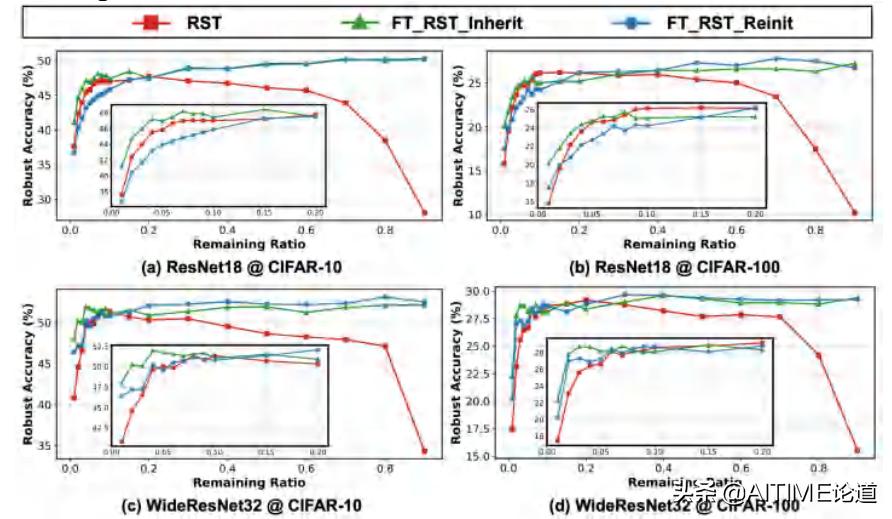
问题一:找到的RSTs没有经过训练,但如果进行一个weight的fine-tuned后是否会取得更好的结果?
实验
设置两种Fine-tuned RSTs
- Fine-tuned RSTs starting with model weights inherited from the vanilla RST
- Fine-tuned RSTs with reinitialized weights
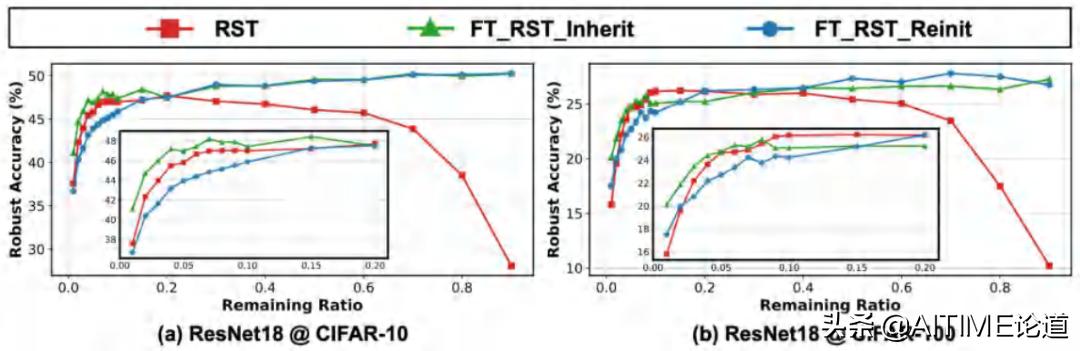
我们比较了这两种经过fine-tuned的RSTs和原本的结果有什么不同。
- Vanilla RSTs vs. fine-tuned在较广泛范围的remaining ratio下,实现了相当稳健的精度
- Fine-tuned RSTs with inherited weights:在较低remaining ratio情况下,大部分RSTs保持了较好的鲁棒性。
- Fine-tuned RSTs with re-initialization: 在较低remaining ratio情况下,相比原来的RSTs具有相似甚至更差的稳健性
上述情况反映出了lottery ticket phenom,即我们找到的RSTs本来就是很好的initialization,如果再用他作为initialization来进行fine-tuned找到的子网络,那么也会取得更好的结果。
- RSTs win a better initialization as fine-tuned RSTs with inherited weights are more robust than the re-initialized one
在不同的model和datasets上我们的结论都是近乎一致的。
问题二:RSTs的search process不止可以用到随机的网络上,当用到训练好的网络上是否会取得更好的效果呢?
实验
设置两种Robust Trained Tickets (RTTs)
- Natural RTTs: RTTs searched from naturally trained networks
- Adversarial RTTs: RTTs searched from adversarially trained network
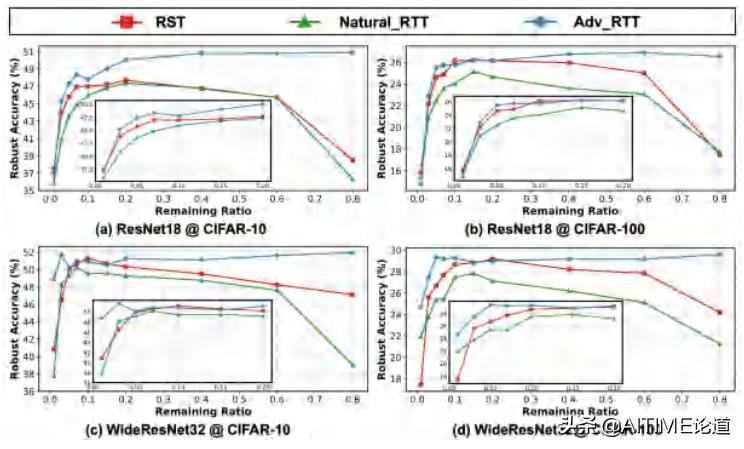
- Adversarial RTTs:具有最好的robustness
- Natural RTTs:robust/natural accuracy的表现甚至不如 vanilla RSTs
这就是说,在naturally trained的model中找子网络还不如去随机初始化的网络中去找子网络。下面,我们就通过实验探究一下原因。
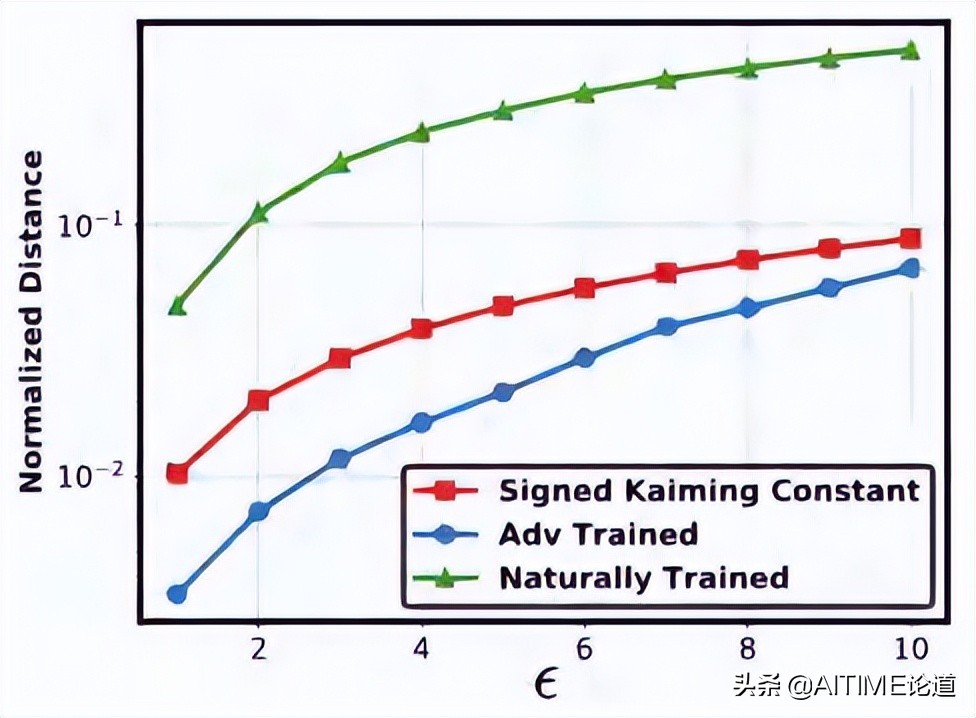
结果我们发现naturally trained的model会对input上的perturbation更加sensitive,所以我们对model的input上加了扰动。之后记录下加noise前后最后一层feature map的变化,就有了上图所示。我们可以看出,在naturally trained的model上,最后一层feature map的变化最为明显。这也就解释了naturally trained的model中找子网络表现不佳的原因。
06
Robust Scratch Ticket: The Applications
我们发现在不同的weight remaining ratios下,RSTs的adversarial transferability的表现较差。
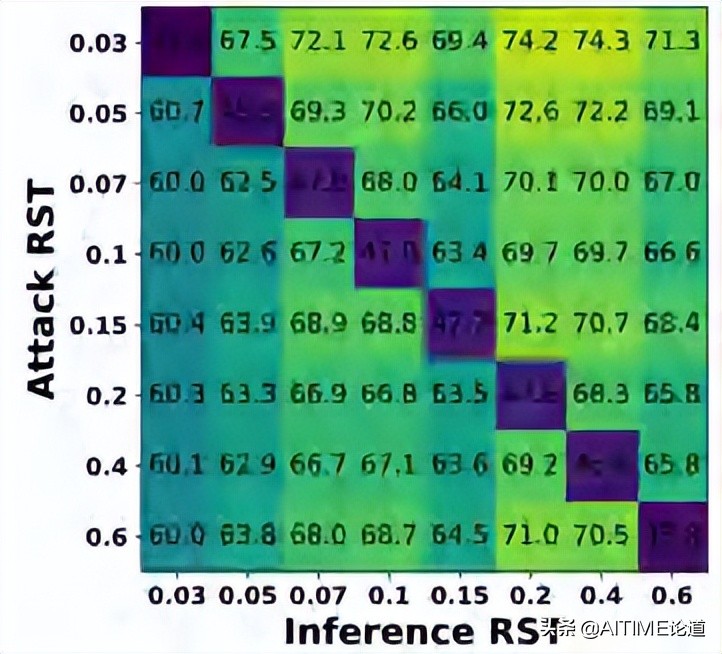
y轴:我们用哪个RST来生成attack
x轴:用哪个ratio的RST来做influence
对角线:这两个RST如果为同一个,adversarial transferability的表现就会较差。
我们在不同的网络和数据集上均有类似发现。
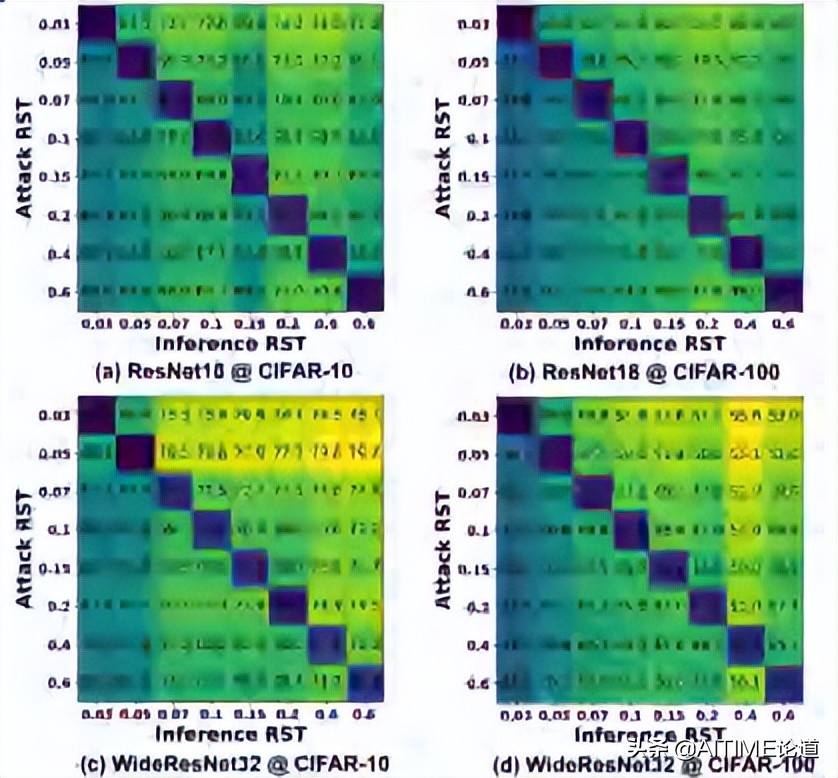
我们选择在不同的RSTs之间Randomly switch,这其实是博弈的过程。Attacker金额defender都可以构造最合适的attack和defend策略,最终会达到nash均衡。我们发现Randomly switch这些RSTs的结果和nash均衡下的鲁棒性表现一致。
优点:
- Parameter-efficiency due to the weight-sharing scheme
- The same randomly initialized networks can be shared among different tas
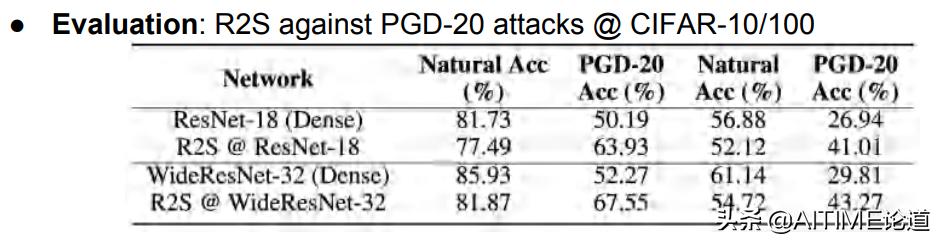
我们发现把R2S应用到ResNet-18之后,比adversarial trained的ResNet-18还能取得更好的鲁棒性表现。
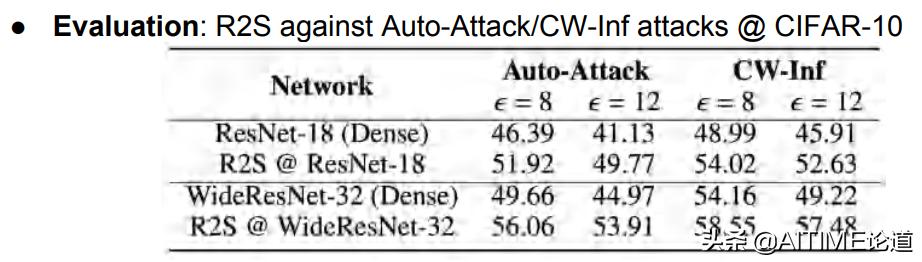
上述结果在其他datasets上的表现是普遍一致的。
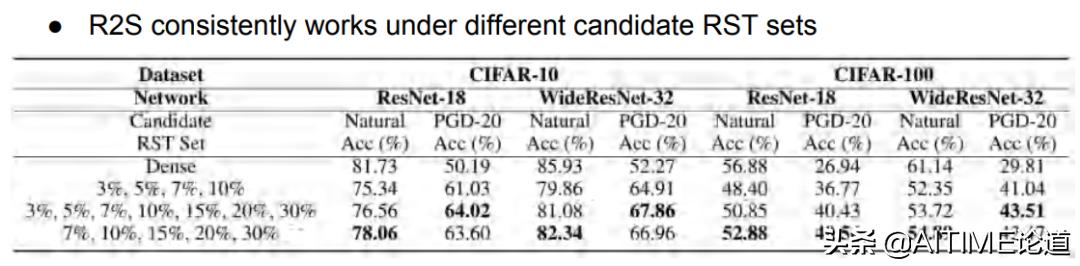
我们还发现如何选取RST并不会对最终的performance造成影响。
提
醒
论文链接:
https://proceedings.neurips.cc/paper/2021/file/6ce8d8f3b038f737cefcdafcf3752452-Paper.pdf
论文题目:
Drawing Robust Scratch Tickets: Subnetworks with Inborn Robustness Are Found within Randomly Initialized Networks