什么是支持向量机(SVM)
SVM或支持向量机算法试图在两个类之间画一个超平面来分离它们。超平面可以有很多,但是支持向量机的目的是找出每个类之间的数据点之间的最大距离。这些数据点是从每个类到超平面最近的数据点。让我们看看下面的图片
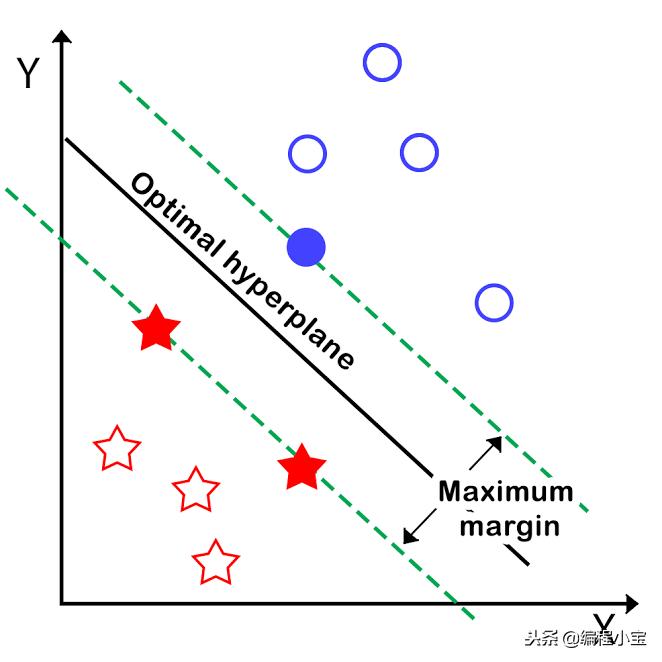
此外,SVM使用称为核技巧的技术来转换数据。如果数据点具有较小的维度空间并且无法绘制超平面,则会尝试向数据添加新维度。
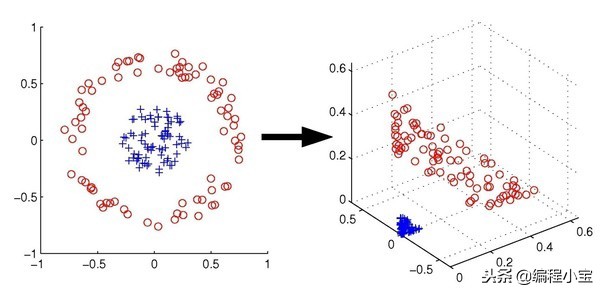
现在我将解释SVM中的一些参数,我们将尝试使用SVM根据特征对语音进行分类。
SVM - 参数
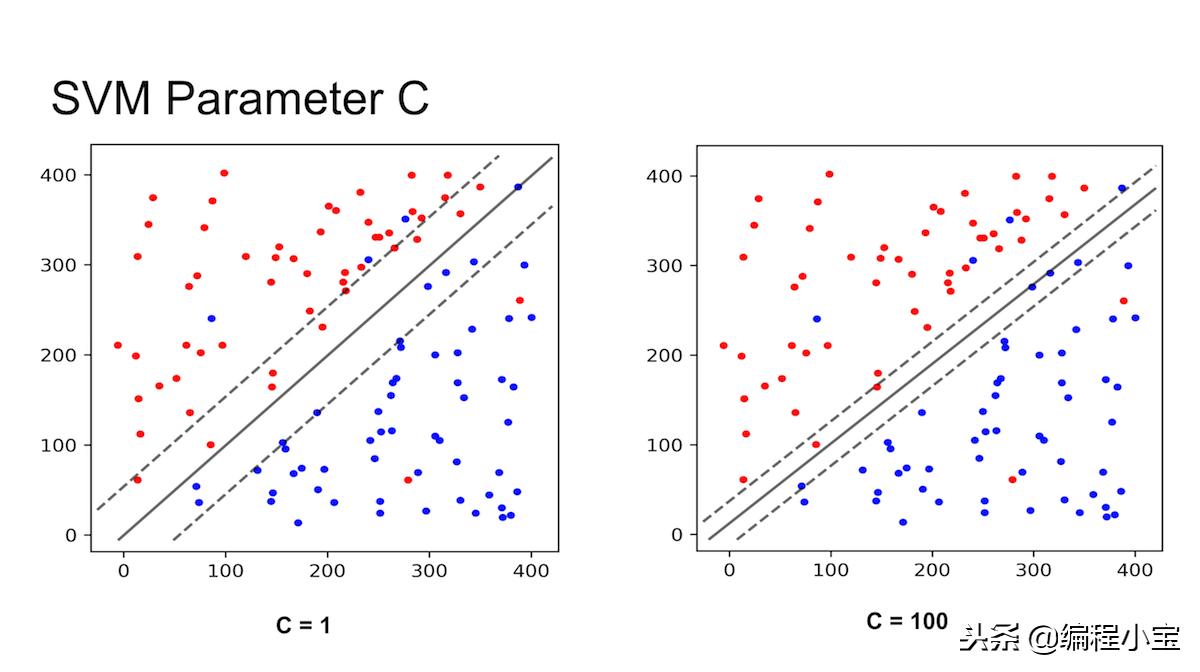
C参数
C参数控制训练点之间的权衡。
- Small C:Large margin
- Large C:Small margin,它有可能过度拟合。
如果您问哪个更好用,请回答“这取决于您的数据”。如果你尝试不同的C值来找到最佳分数会更好。
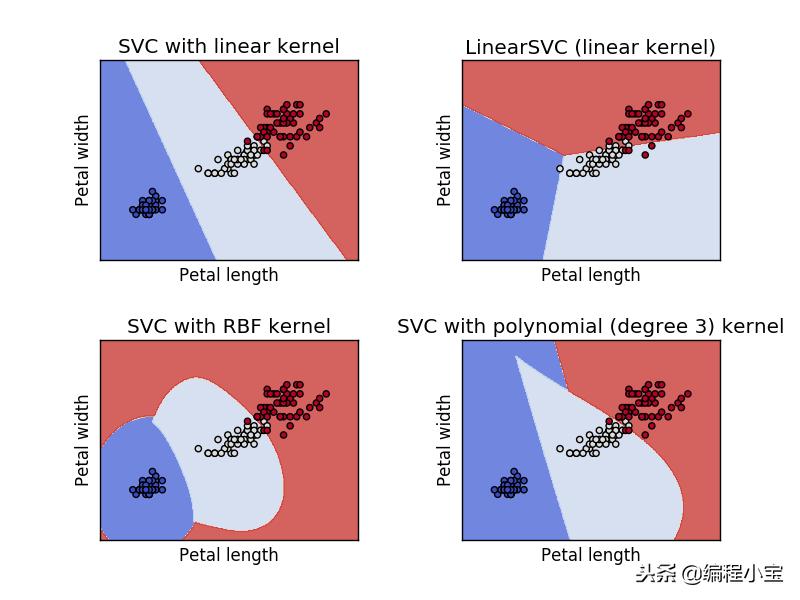
核
您可以选择SVM使用的核类型。它可以是'linear','rbf','poly','sigmoid','precomputed'。这仍然取决于您的数据。
Gamma参数
它是核系数。如果选择'rbf','poly'或'sigmoid'作为核,则使用它。
还有'degree'参数。它用于'poly'核来定义多项式核的次数。默认为3。
导入库和读取数据
采用的原始机器学习数据集:https://www.kaggle.com/primaryobjects/voicegender,可以自行*载下**编辑
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
# Read Data
df = pd.read_csv("../input/voice.csv")
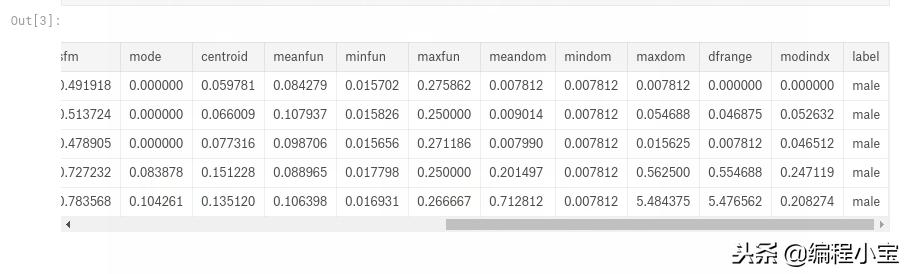
# First 5 Rows of Data
df.head()
df.columns

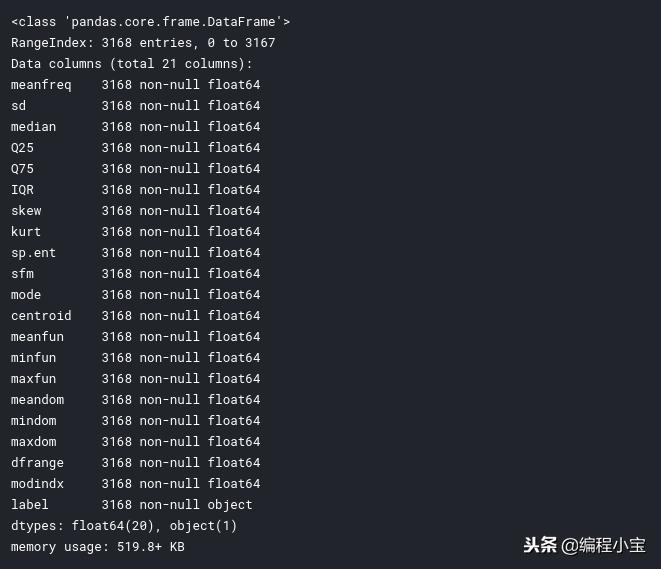
df.info()
可视化数据
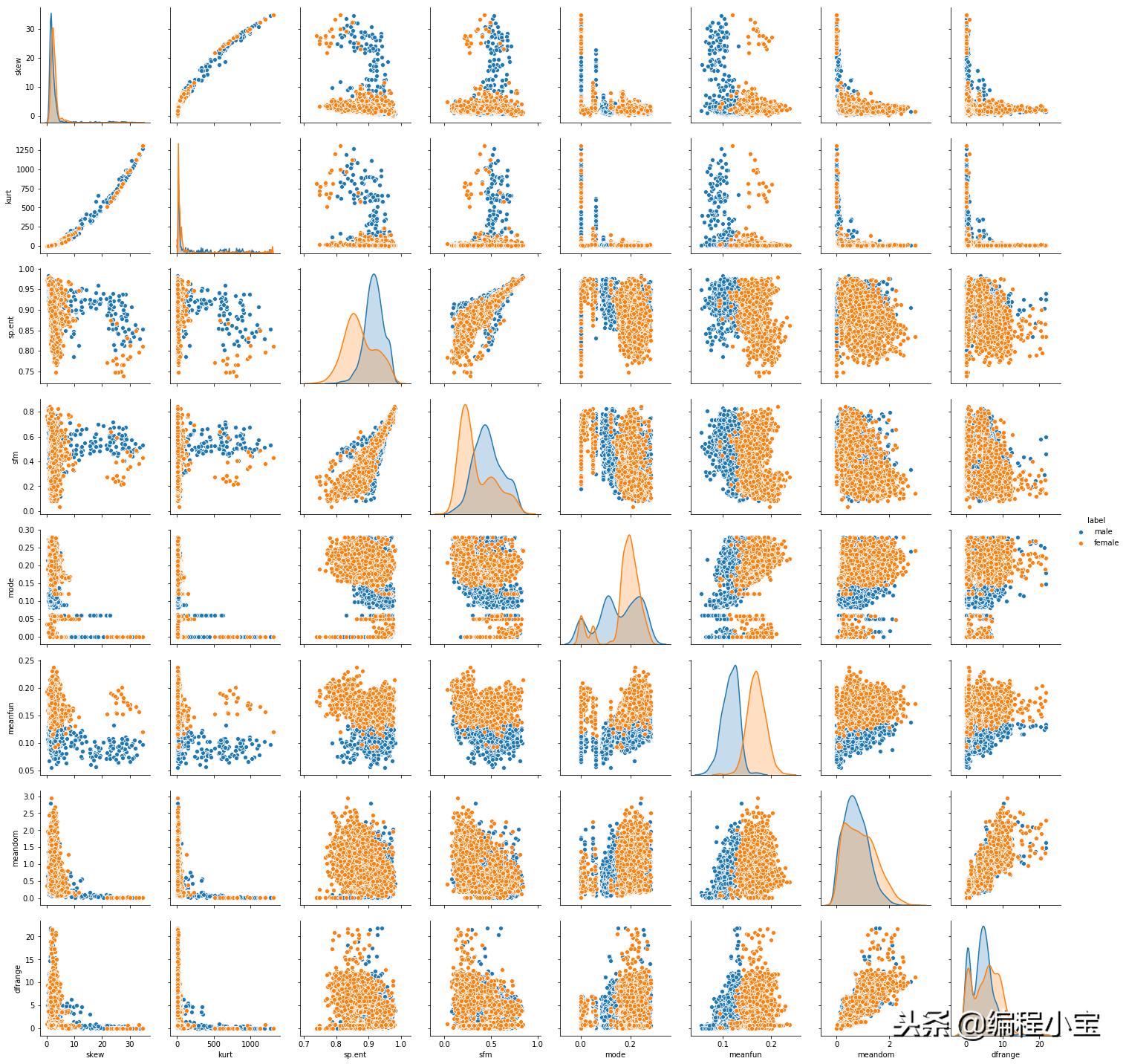
sns.pairplot(df, hue='label', vars=['skew', 'kurt', 'sp.ent', 'sfm', 'mode','meanfun', 'meandom','dfrange']) plt.show()
sns.countplot(df.label) plt.show()
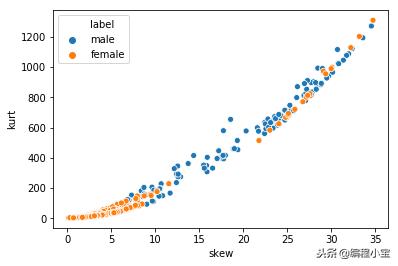
sns.scatterplot(x = 'skew', y = 'kurt', hue = 'label', data = df) plt.show()

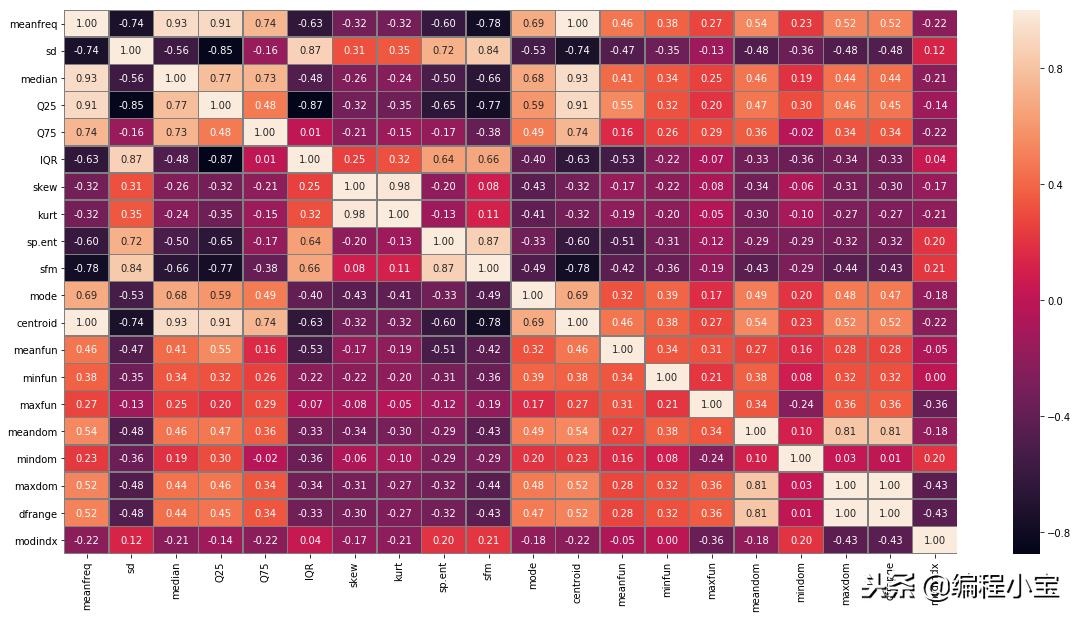
plt.figure(figsize=(20,10)) sns.heatmap(df.corr(), annot=True, linewidth=.5, fmt='.2f', linecolor = 'grey') plt.show()

创建和评估机器模型
X = df.drop(['label'],axis=1) y = df.label
我们将使用70%的数据来训练我们的机器学习模型,我们将使用30%的数据进行测试。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state=42)
# Import SVM
from sklearn.svm import SVC
svm = SVC()
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)
from sklearn.metrics import confusion_matrix, classification_report
cm = confusion_matrix(y_test, y_pred)
sns.heatmap(cm, annot=True, cmap="Paired_r", linewidth=2, linecolor='w', fmt='.0f')
plt.xlabel('Predicted Value')
plt.ylabel('True Value')
plt.show()
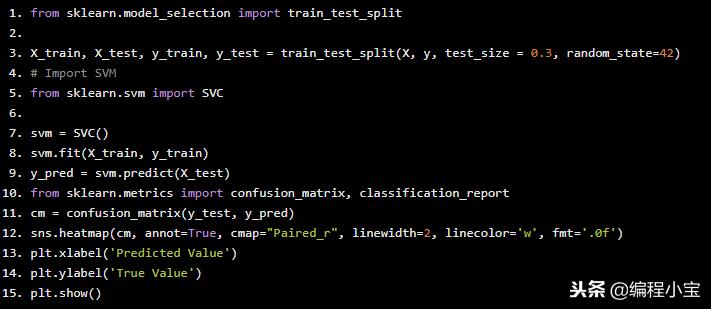
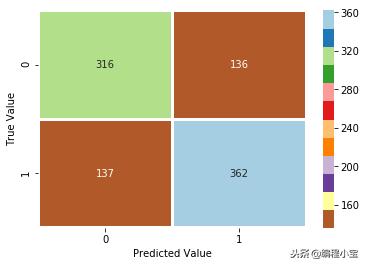
测试准确度:71.29%
我们的准确性并不好,因为你可以看到混淆矩阵高于我们的预测并不好。所以让我们试着改进我们的机器学习模型。首先,我们将对数据进行归一化,之后我们将应用一些参数优化。
# Normalization X = (X - np.min(X)) / (np.max(X) - np.min(X)).values X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3, random_state = 42)

让我们拟合我们的机器学习模型。
svm.fit(X_train, y_train)
y_pred = svm.predict(X_test)
cm = confusion_matrix(y_test,y_pred)
sns.heatmap(cm, annot=True, fmt='.0f', cmap='brg_r')
plt.xlabel('Predicted Value')
plt.ylabel('True Value')
plt.show()
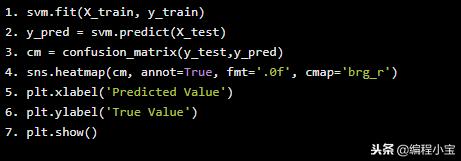
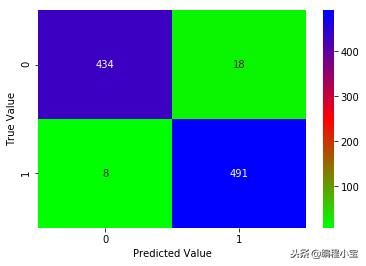
测试准确度:97.27%
我们的分数增加到97.27%,我们所做的就是将数据归一化!我们可以在这里看到normalizaton的重要性。让我们尝试为我们的模型找到最佳参数。
from sklearn.model_selection import GridSearchCV
param_grid = {'C':[0.1, 1, 10, 100], 'gamma':[1, 0.1, 0.01, 0.001], 'kernel' : ['rbf', 'poly', 'sigmoid', 'linear']}
grid = GridSearchCV(SVC(), param_grid, refit=True, verbose=4)
grid.fit(X_train, y_train)
print("Best Parameters: ",grid.best_params_)

最佳参数:{‘C’: 10, ‘gamma’: 1, ‘kernel’: ‘rbf’}
grid_pred = grid.predict(X_test)
cmNew = confusion_matrix(y_test, grid_pred)
sns.heatmap(cmNew, annot=True, fmt='.0f', cmap='gray_r')
plt.xlabel('Predicted Value')
plt.ylabel('True Value')
plt.show()
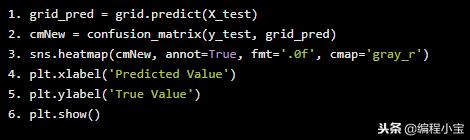
测试准确的度:97.79%
print(classification_report(y_test, grid_pred))
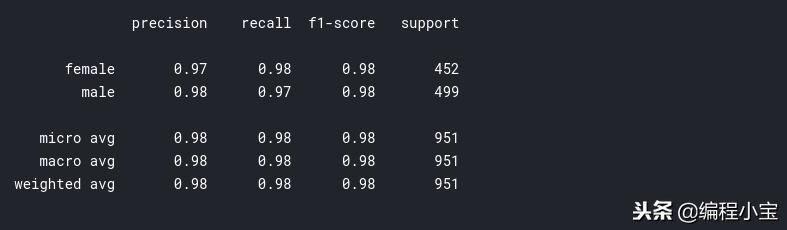
我们的测试分数再次增加了一点,我们达到了97.79%的准确率。