声明:此代码仅仅是为了学习Python,分析网页用,借助平台记录学习过程。
我在读研时,常常在文库里面搜索一些资料,但苦于不能*载下**,所以后来就文库用的比较少。最近看了网上说可以免费*载下**百度文库文档、PPT之类,并且还有一个*载下**神器叫冰点文库,看了视频操作,真是强大,这可真破解了当年写论文的一大难题啊---资料搜索。今天写这个文章呢,纯粹就是为了检验Python学习效果。
一、网站分析
随便打开了一个文库(PPT)网页,如下图。

- 需求分析。当我们打开网站后,类似上图,是一个4页的ppt,文字不能复制(不过网上传可以拖动复制值QQ对话框,有兴趣大家可以试试),*载下**还需要2个*载下**券。想*载下**,怎么破?今天我的目标就是要*载下**这个文档。
- 利用开发者工具分析。

在上图中找出下图所标记的网址,可以看出该网址是返回的是一个json数据,里面有个list列表,正好四个元素,经分析,正好是四张PPT图片*载下**链接。
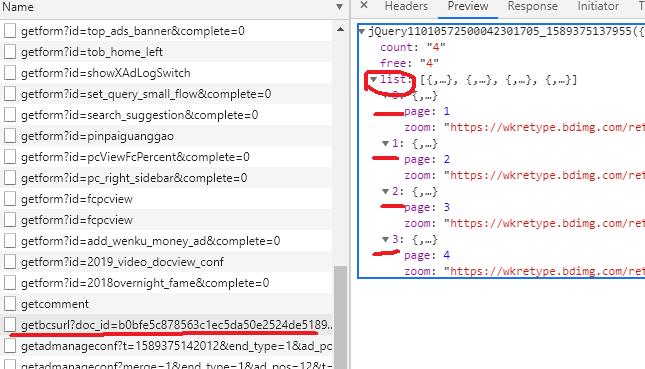
左侧网址打开后如下图,包含四个图片地址。

对Headers分析,get请求,带有6个参数,所以他的URL才那么长。
3,代码编写思路
一是使用requests发起请求。
二是获取doc_id,。如果*载下**单个的话可以不用那么麻烦,直接上网址就可以,如果想要通用的话,还是获取doc_id,构造请求参数。
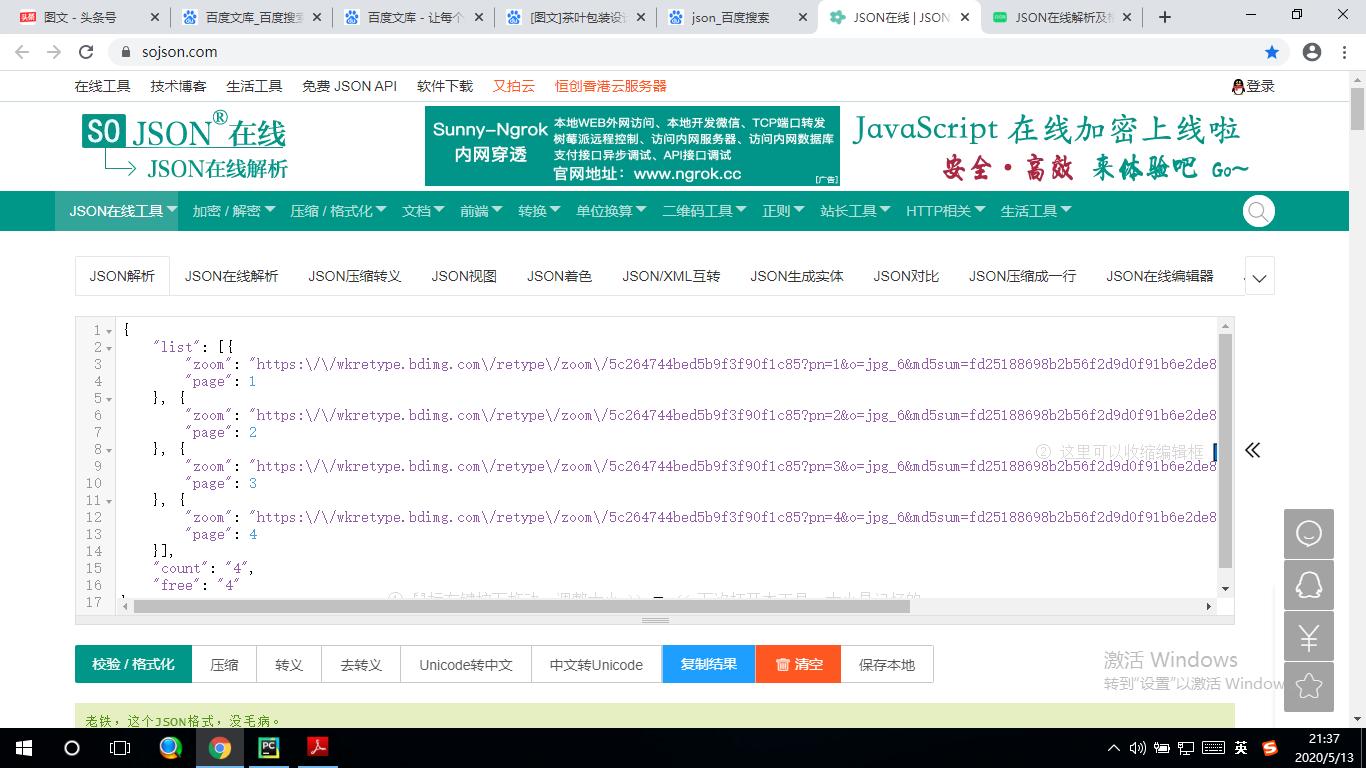
三是获取json数据,从数据中把图片地址获取下来。下图为json格式化后的效果
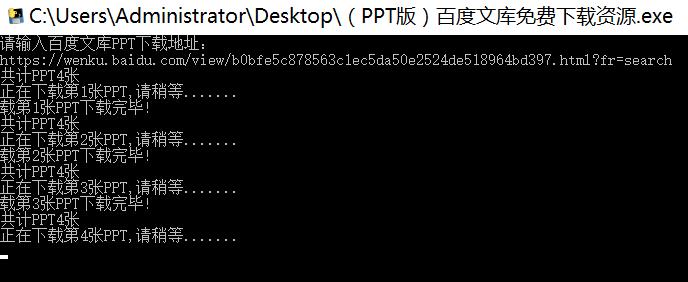
四是*载下**图片。这是后期做成的exe文件。方便,通用。
五是将所有图片制作成PDF。
六是将*载下**的图片删除。
二、代码展示
代码写的不够完美,有点粗糙。
import requests,json,os
import fitz,re
#头信息
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36'
}
print)
#用户输入地址,这块是可以看到PPT的地址
user_url = input(('请输入百度文库PPT*载下**地址:')
#使用字符串分割对输入的网址取出doc_id
doc_id = user_url .split('/')[-1].split('.')[0]
#构造参数,将doc_id 传入
params={
'doc_id':doc_id,
'pn': 1,
'rn': 99999,
'type': 'ppt',
}
#获取json文件
def get_json(url):
data=requests.get(url,headers = headers).text
img_json=json.loads(data)
return img_json
if __name__ == '__main__':
#请求访问,url拼接网址用,未带请求参数
url = 'https://wenku.baidu.com/browse/getbcsurl?'
response = requests.get(url, params=params, headers=headers)
#传入的是json数据的网址
img_json = get_json(response.url)
# #创建一个空白的PDF文档
doc = fitz.open()
#获取ppt文件名
data = requests.get(user_url , headers=headers)
data.encoding = 'gb2312'
pat = '<title>(.*?)</title>'
name = re.findall(pat, data.text, re.S)[0]
name = name.split('')[0]
#循环,*载下**图片
for i in range(len(img_json)):
print('共计PPT%d张'%len(img_json))
#获取图片URL
img_url = img_json[i]['zoom']
#这个用于计数
num = i + 1
print('正在*载下**第%d张PPT,请稍等.......' % num)
res = requests.get(img_url, headers=headers)
#保存图片
with open('%d'%i + '.jpg', 'wb') as f:
f.write(res.content)
print('载第%d张PPT*载下**完毕!' % num)
#将图片转换为PDF
img_doc =fitz.open('%d'%i + '.jpg')
pdf = img_doc.convertToPDF()
imgPdf = fitz.open('pdf',pdf)
doc.insertPDF(imgPdf)
doc.save('%s.pdf'%name )
doc.close()
print(name+'已成功创建!')
#循环,删除图片,需要图片的这步可以跳过
for i in range(len(img_json)):
os.remove('%d'%i + '.jpg')
print('图片已删除')