用深度学习理解 保险卡的意义
fastai深度学习社区马老师译
了解保险范围并使用它来寻找相关的医生对患者来说是一项重要而复杂的任务。在美国,我们有数百家保险公司,其中许多都有数百个可用的计划。病人有很多东西要分辨,以确定他们需要找到医生和预约的正确信息。为了帮助患者更轻松地了解保险,我们决定建立Zocdoc保险检查器,从病人的保险卡照片中提取关键信息。我们感兴趣的信息如下:
保险公司的名称和计划
用户的会员ID
根据这些信息,我们可以检查患者是否在网络中进行某种访问,而只将网络内的医生提供给用户。我们还可以根据资格检查向用户提供估计的金额数量。我们所建立的系统利用计算机视觉和深度学习方面的各种进步,是同时进行分类,图像裁剪和OCR的深层神经网络的混合。这个博客的其余部分详细介绍了这个系统的架构,并突出了我们必须采用的各种技巧和经验,以达到与我们的患者相当的准确性水平。
建设与购买
我们知道图像识别和OCR是研究得很好的问题,所以我们首先想到的是探索外部工具和服务。然而,我们发现的服务中没有一个是为了处理我们从用户那里获得的图像中的照明,模糊,方向,角度,大小和背景等方面的差异而设计的。这是一个典型的卡片图像变化的例子:

图1:一个程式化的动画,展示了产品设计的目的

图2:传递给我们的卡片图像示例,请注意,这些都是一个Zocdoc工程师过期卡的图像,仅用于说明目的
模型架构
在过去的几年中,使用深度学习的方法在计算机视觉领域取得了显着的进步,这促使我们使用深度学习神经网络流水线来构建我们的系统。我们的系统由三个独立的网络组成,包括一个基本分类网络,一个对齐网络和一个OCR网络。对齐和OCR网络使用可区分的关注层进行连接,以便它们可以共同优化。下面是整个系统的体系结构,本文的其余部分分别介绍每个组件的细节。
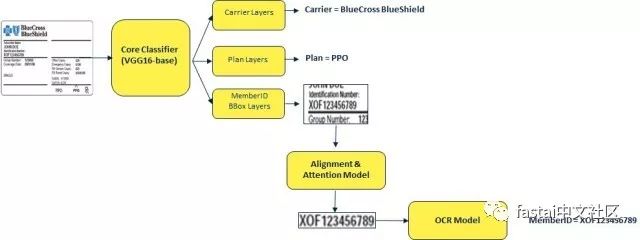
图3:我们的网络分类,字段提取和OCR
基本CNN模型
神经网络的基本模型采用缩放到200×300像素分辨率的图像并输出以下信息:
运营商和计划ID。
成员ID的边界框的坐标位置及其方向。
基本模型基于VGG16模型,其中我们从预先训练的卷积层开始,并添加了我们自己的一组密集层,将卷积特征转换为上述输出。利用卷积滤波器的图像网权重进行初始化(传输学习)使我们能够开始我们的训练过程,使用在大型图像网络上的图像进行训练的特征检测器,而不仅仅依赖于我们的训练数据,并且改进了我们的模型。
一起训练多个输出也通过在多个任务之间共享特征(多任务学习)来提高泛化。我们的损失函数是载体和计划ID的分类变量的标准交叉熵损失。然而,由于我们的训练数据有一些错误标记的例子,损失被限制在一个固定的水平,以使系统对其预测有信心,即使他们不同意几个用户的样本。
为了生成MemberID包围盒标签,我们使用tesseract检测卡片图像上的所有单词和相应的包围盒。如果任何检测到的单词(或任何两个靠近检测到的单词的组合)与用户输入完全匹配,我们使用相应的边界框(或两个合并的边界框)作为我们的训练数据。这个过程导致我们在我们的数据集中有大约10%的图像的MemberID边界框标签。该过程导致一些错误。用户在卡上标记了一些实际的文本,但该文本不对应于MemberID。为了避免在这些错误情况下对模型进行过度惩罚,我们使用了一个由小错误组成的二次罚分的损失,但是随后转换为更大错误的线性惩罚序列。
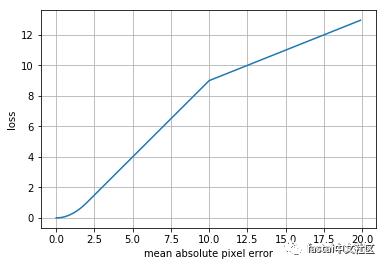
图4:MemberID包围盒丢失函数
多假设预测:另一种类型的标签错误是在相同卡上的多个位置出现相同的MemberID编号的卡片。在这种情况下,我们的训练数据可能会在这些位置中的任何一个上具有边界框。为了对这种类型的训练数据具有鲁棒性,该模型预测了成员ID位置的多重假设(在实践中仅有两个),并且损失被认为是不同预测的最小值。使用训练的单一假设模型初始化多重假设预测模型,并且通过从单一假设预测中随机扰动它们来初始化附加假设。在我们训练时,对于有多次MemberID的卡,不同的假设会附加到MemberID出现的不同位置。对于MemberID在卡上只出现一次的大多数卡而言,这两个假设都移到非常接近相同的位置。为了简化,在训练之后,我们只选择与训练集中边界框重叠最高的预测作为下一个阶段的单个预测。

图5:放大了由VGG CNN和关注层
组成的MemberID提取网络的视图
成员ID提取的流程的下一个阶段是从用基本CNN模型的松散边界框估计提取的高分辨率图像开始,并将边界框坐标与MemberID的确切位置对齐。对齐模型也使用与卷积层的VGG模型类似的体系结构。最后,我们使用一个基于DRAW:一个递归神经网络用于图像生成的可微分关注层来提取具有精确的边界框坐标的更严格的MemberID图像。此关注层将512×64输出中的每个像素映射到对齐边界框坐标的可微分函数以及近似边界框(输入到对齐模型)周围的高分辨率图像。该函数包含可训练的填充量以及可训练的高斯模糊,以衰减MemberID图像中的高频噪声,并使映射足够平滑,以便对齐进行有效的训练。在训练过程中,我们将模糊级别初始化为比所需更高的级别,并使其恢复到较低级别,同时改进边界框的对齐。
OCR模型
给定一个文本序列的非常局部的图像,OCR组件是相对简单的。我们考虑的选择是使用开源的OCR引擎tesseract,或者自己构建它。保险卡上的MemberID文本,字体和背景的分布比像tesseract这样的通用系统已经被调整处理的分布要受限制得多,因此定制的解决方案可以提供卓越的性能。一些研究也表明,许多其他公司正在为自己的问题建立自己的版本,深度学习社区提供了很好的基础范例。
类似于上面的参考文献,我们的解决方案包括一系列两个卷积和最大池化层,以及在图像的深度和高度上的密集层,紧接着沿着宽度的一系列双向GRU层,穿过深度的密集层GRU层和沿宽度的每个位置的softmax激活。OCR模型输出128×40维张量,其中40是词汇表(包括空白)的大小,并且表示每个符号出现在沿图像长度的128个位置中的每一处的概率。
OCR训练的一个核心挑战是将输出与图像对齐(即,图像可以是512个像素宽,但包含8个字符,并且问题是将每个字符分配给像素序列)。我们使用CTC(连接时间分类)丢失来解决这个问题,并且将OCR模型和附加的对齐模型一起训练。我们可以进行这种联合训练,因为我们在对准模型中使用了一个可区分的关注层——联合训练显著提高了这两项训练的表现。
数据采集
任何图像识别和OCR训练任务中的关键挑战是获取标记的图像。在我们的案例中,患者在预约(和/或上传他们的卡片)之前指定他们的保险公司和计划。在卡片上传流程中,我们也提示他们手动输入他们的MemberID。
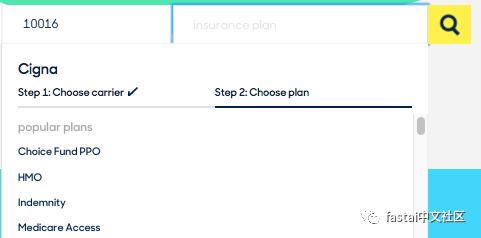
图6:Zocdoc Insurance Picker的快照
我们在仔细研究了大量数据后得出的一个有趣的观察结果,以及这个产品的强有力的理由是患者常常错在他们有什么计划或者他们的MemberID是什么(而不仅仅是考虑打字错误)。除了方便之外,我们发现我们的过程也可以比单纯依靠病人的努力更准确。展望未来,我们计划使用Mechanical Turk类工具来使用内部的Zocdoc操作团队以符合HIPAA标准的方式标记图像——提高训练数据质量—有望进一步提高系统精度。
模型训练
如上面简要提到的,用户照片包含四个方向中的任何一个方向的卡——相互成90度。我们还使用数据增强,通过将小旋转转化图像,180度翻转,以及对颜色通道的小改动转化图像来获得额外的训练数据并改进泛化。
在8台GPU服务器(AWS p2.8xlarge实例)上使用Python中的Keras库和Tensorflow后端对每个模型运行多个培训。
成员ID提取的端到端性能
下面我们将介绍MemberID提取管道的各种组件对端到端准确性的影响,并将系统的准确度与我们的用户进行比较。我们的目标是实现相对于我们的用户的相似或更高的准确度——在我们的测试数据集中约为82%(这意味着,患者只有82%的时间正确地进入了他们的MemberID)。我们首先使用预测单个MemberID边界框假设位置的Base CNN模型,并使用Tesseract作为OCR引擎来读取边界框内图像中的文本。这给了我们42%的端对端准确度——这是一个好的开始,但不令人满意(考虑到最先进的图像识别系统可以实现的)。我们注意到,人类看到的轻微对齐错误导致Tesseract失败,所以我们增加了第二阶段,使第一阶段的近似预测更准确地与MemberID文本对齐。这提高了69%的准确性。

最后,我们增加了关注层和内部OCR模型,并用对齐模型进行了联合训练。我们还在系统中增加了多重假设预测,以提高某些保险卡类型的准确性,并且发生了多次的MemberID,使我们的准确率达到了86%,这与我们测试集的用户准确度相当。在这个阶段,我们决定开始测试生产中的模型,同时我们继续提高性能。
结论
多年来,我们可以针对新问题开发深度学习解决方案的速度大大加快。通过提供基于云的GPU服务器,预先训练的模型以及开放源代码体系结构和代码,我们能够非常迅速地开发出一个概念验证(并证明这一点)。我们很快得知,获得适合生产级别个人健康应用程序的质量需要更多的聪明才智和反复试验,而不仅仅是将开源组件串起来。这对我们来说并不令人意外,因为保险卡和图像的复杂性已知,而且不会强加格式限制。我们对现在的处境感到非常满意,并且对于更多的数据感到非常兴奋,这个系统将会具有超人般的准确性。
我们的模型现在正在Zocdoc应用程序和移动网络上进行生产,并帮助我们的患者寻找护理,同时提高所得到的建议的准确性。这是Zocdoc的第一个深度学习型产品,代表了我们带给患者创新的医疗体验的理念。
关于作者
Akash Kushal是位于PiñaCaliente团队的Zocdoc工程师,他喜欢建立机器学习系统和固定飞行翼的飞机。
