在数据库设计的时候 我们需要考虑数据量的大小,当数据量比较大的时候我们会考虑分表或者分表,那么一般我们分库分表怎么去分呢?
首先我们常用的分库分表是按用户、订单、时间、地区等这些维度去分,尽量保证每个库每个表数据是均衡的,如果数据不均就失去分库分表的意义,严重时,甚至可能影响系统性能和稳定性。 分布不均我们又叫 数据倾斜,特别严重时,就要考虑二次分表了,也就是添加一定数量的表,然后按照相应规则将对应的数据迁移到新表中。
这里我们就可以利用一致性哈希算法对倾斜的数据表进行二次分表。
首先,一致性哈希算法可以动态添加虚拟节点,在不增加表的情况下,减少数据倾斜。其次,一致性Hash算法在应对增加一张表这种场景时,只会引发部分数据迁移,不会像普通的Hash算法一样导致需要迁移几乎所有数据。如果没明白上面两句话的意思,不要紧,继续往下看。
一致性hash采用环形设计思路,根据 节点(库,表)的Hash值将所有节点映射到Hash环上,在我们查询和写入数据时,会根据该数据的Hash值计算出该数据在Hash环上的位置,然后从 该位置开始按顺时针方向找到Hash环上最近一个节点,这个节点就是该数据对应的节点(库,表)

实际使用中,由于服务器节点数量有限, 很有可能出现数据分布不均匀的情况。这个时候会出现大量数据都被映射到某一个节点的情况,如下图左侧所示。为了解决这个问题,一致性Hash算法巧妙利用 了虚拟节点。虚拟节点是实际节点在Hash环上的复制品,一个实际节点可以对应很多的虚拟节点。虚拟节点越多,Hash环上的节点也就越多,数据分布也会 越均匀。
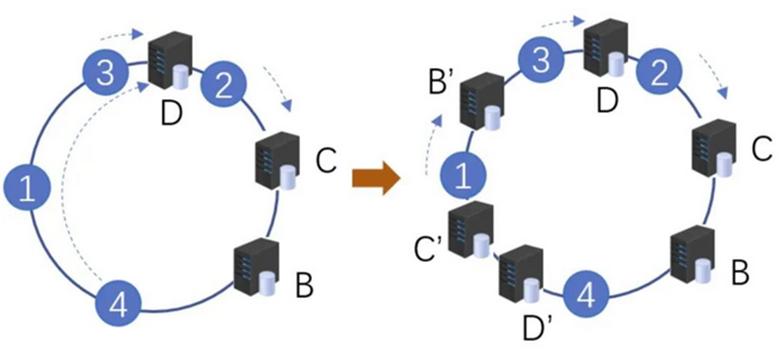
如上图右侧所示,B'、C'、D' 是原始节点复制出来的虚拟节点,原本映射到节点D上的数据1和4,分别被映射到了B'和D',最终会落到对应的真实节点B和D上。我们可以看到,虚拟节点让数据分布更均匀了。