本节讲解什么是回归算法,如何求解回归问题,因为它涉及股票、期货等资产的更高级模型的建立,这是一个数学问题,但很多交易者因为无法理解而被拦在学习和进步的道路上。
1.问题引入
我们用回归算法中一个经典的问题,房价的预测,举例。
|
房屋面积(m^2) |
租赁价格(1000¥) |
|
10 |
0.8 |
|
15 |
1 |
|
20 |
1.8 |
|
30 |
2 |
|
50 |
3.2 |
|
60 |
3 |
|
60 |
3.1 |
|
70 |
3.5 |
请问,如果现在有一个房屋面积为55平,请问最终的租赁价格是多少比较合适?
建模
自变量目前只有一个房屋面积(X),因变量是租赁价格(Y),我们需要找到自变量X和因变量Y之间的关系,然后用一个公式近似表达这种关系。线性公式为y=ax+b,构建出来应该是这样的,最终也解出了a和b的值,如图所示:
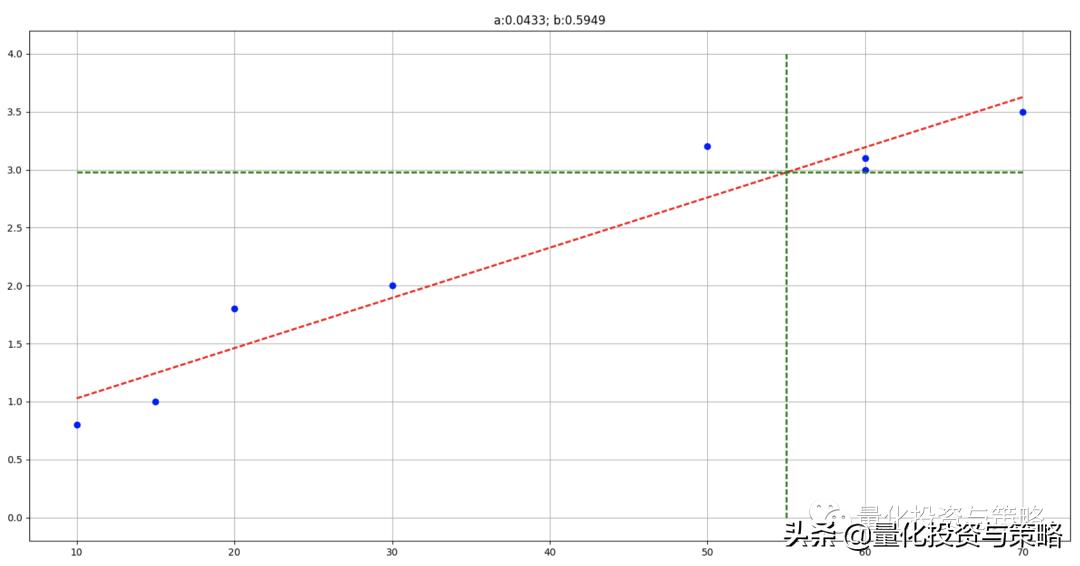
好了,关于一个自变量的问题大家应该都理解了。现在问题得到了延伸了,即出现两个自变量X1和X2的情况:
|
房屋面积 |
房间数量 |
租赁价格 |
|
10 |
1 |
0.8 |
|
20 |
1 |
1.8 |
|
30 |
1 |
2.2 |
|
30 |
2 |
2.5 |
|
70 |
3 |
5.5 |
|
70 |
2 |
5.2 |
|
..... |
...... |
........ |
线性公式将是这样的:
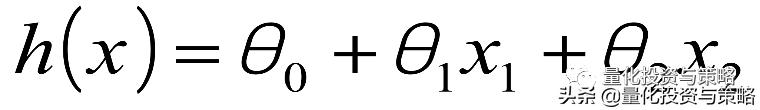
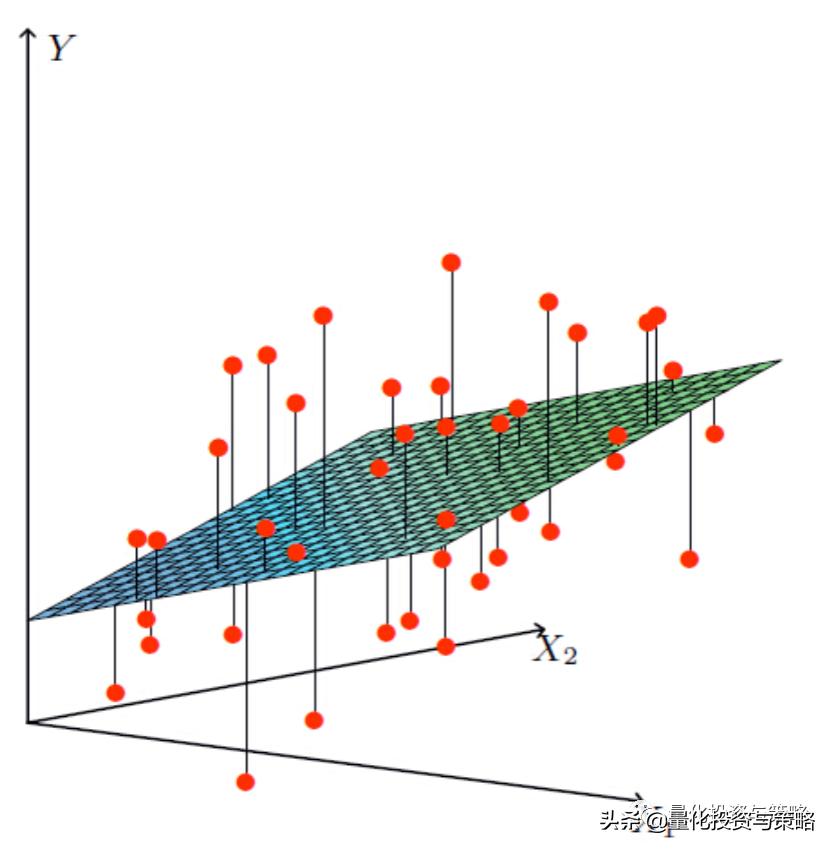
最后得到的解空间,如图所示:
2.回归算法
回归算法是一种有监督算法。回归算法是一种比较常用的机器学习算法,用来建立“解释”变量(自变量X)和观测值(因变量Y)之间的关系;从机器学习的角度来讲,用于构建一个算法模型(函数)来做属性(X)与标签(Y)之间的映射关系,在算法的学习过程中,试图寻找一个函数,
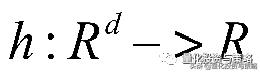
, 使得参数之间的关系拟合性最好。
回归算法中算法(函数)的最终结果是一个连续的数据值,输入值(属性值)是一个d维度的属性/数值向量。
3.线性回归算法
认为数据中存在线性关系,也就是特征属性X和目标属性Y之间的关系是满足线性关系。
在线性回归算法中,找出的模型对象是期望所有训练数据比较均匀的分布在直线或者平面的两侧。
在线性回归中,最优模型也就是所有样本(训练数据)离模型的直线或者平面距离最小。
线性回归模型公式,可以表达为:
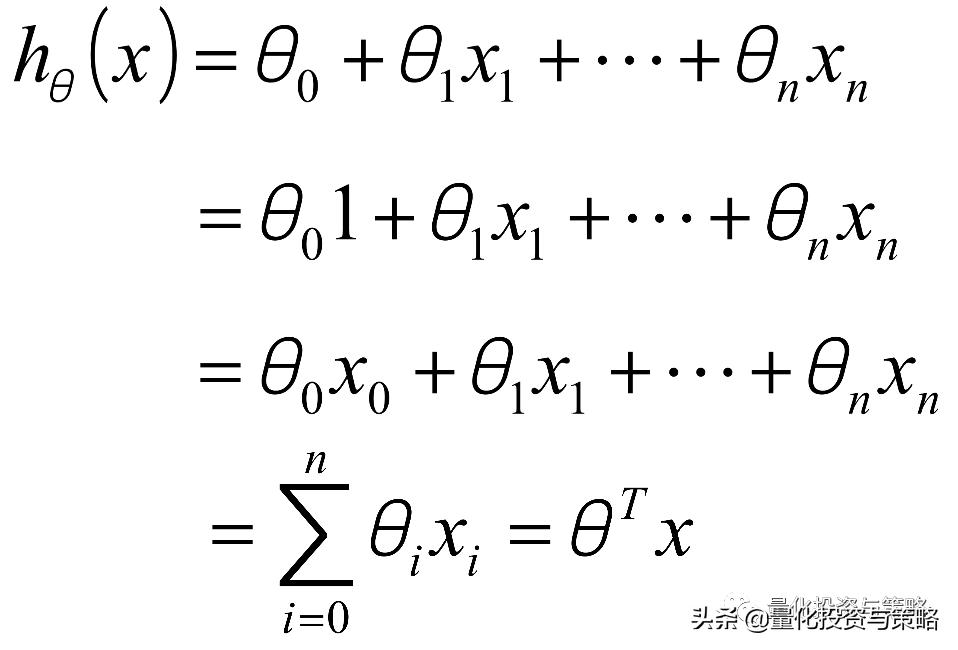
最终要求是计算出
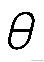
的值,并选择最优的
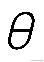
值构成算法公式。
4.最大似然估计和最小二乘法
解空间可以表达为:
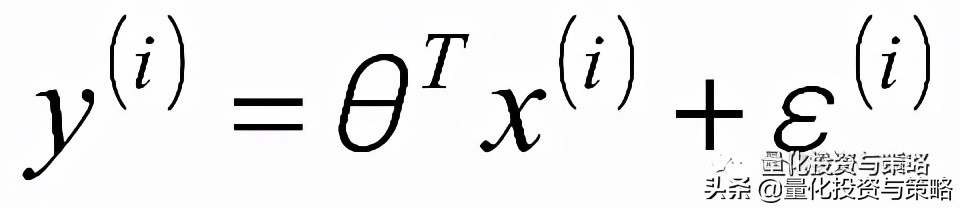
误差
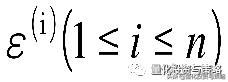
是独立同分布的,服从均值为0,方差为某定值
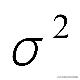
的高斯分布。原因:中心极限定理。
实际问题中,很多随机现象可以看做众多因素的独立影响的综合反应,往往服从正态分布。
最小二乘法是说我们线性回归模型最优的时候是所有样本的预测值和实际值之间的差值最小化,由于预测值和实际值之间的差值存在正负性,所以要求平方后的值最小化。也就是可以得到如下的一个目标函数:
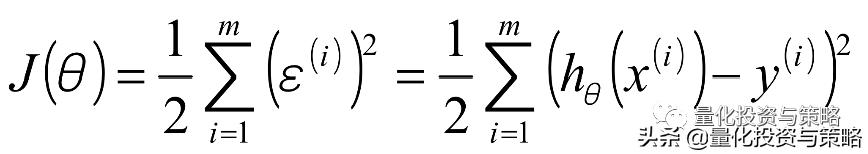
似然函数的表达:
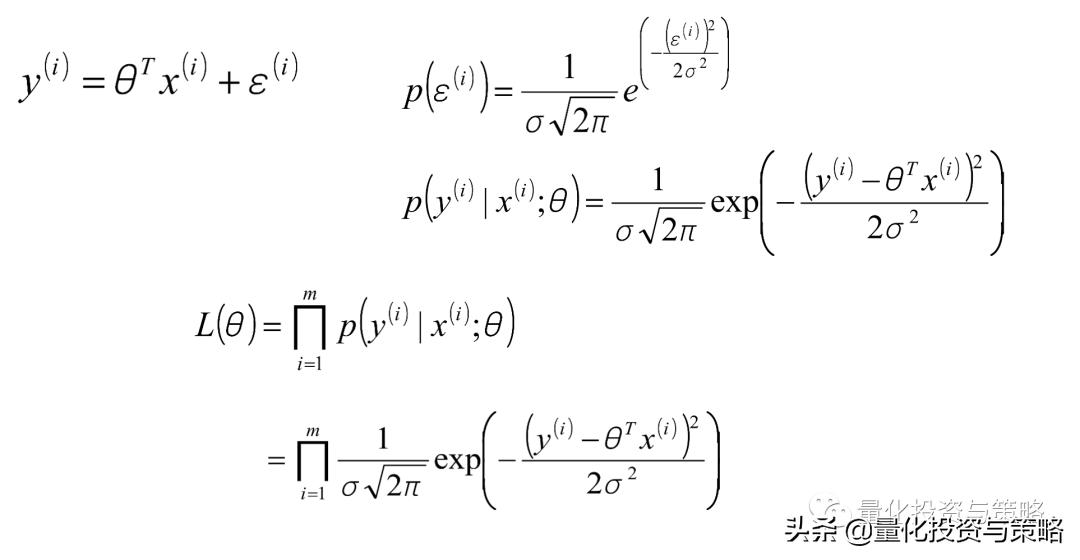
取对数后,推导出:
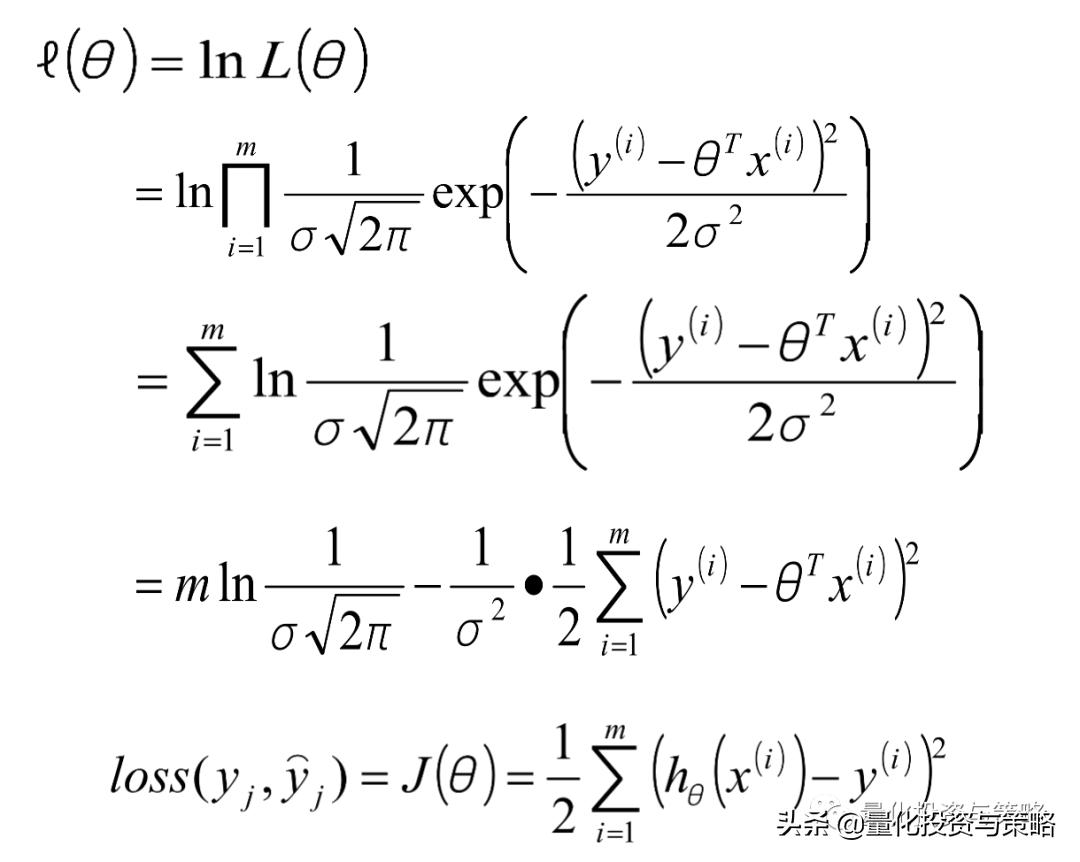
θ的求解过程:
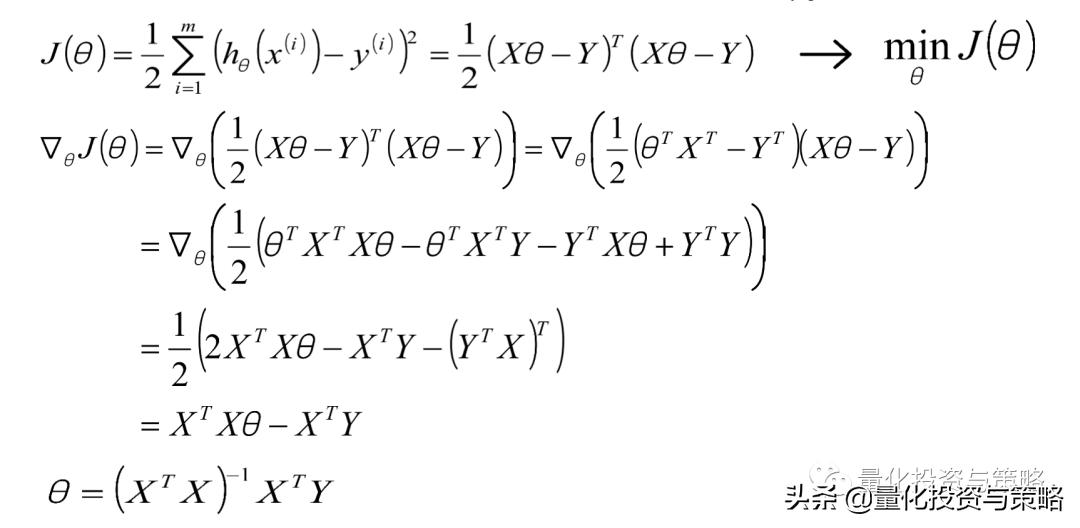
最小二乘法的参数最优解
参数解析式:
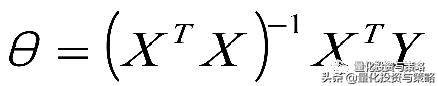
最小二乘法的使用要求矩阵
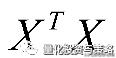
是可逆的;为了防止不可逆或者过拟合的问题存在,可以增加额外数据影响,导致最终的矩阵是可逆的:
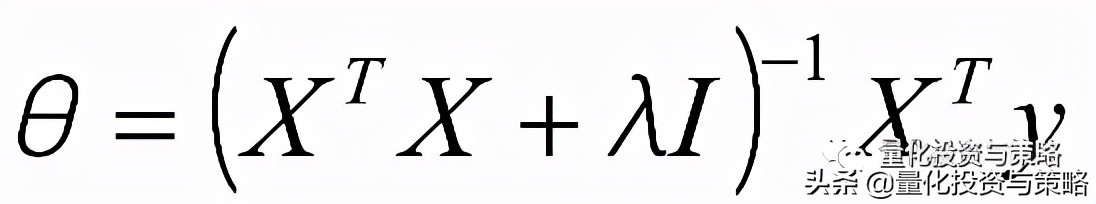
最小二乘法直接求解的难点:矩阵逆的求解是一个难处。
5.过拟合和正则项
目标函数:
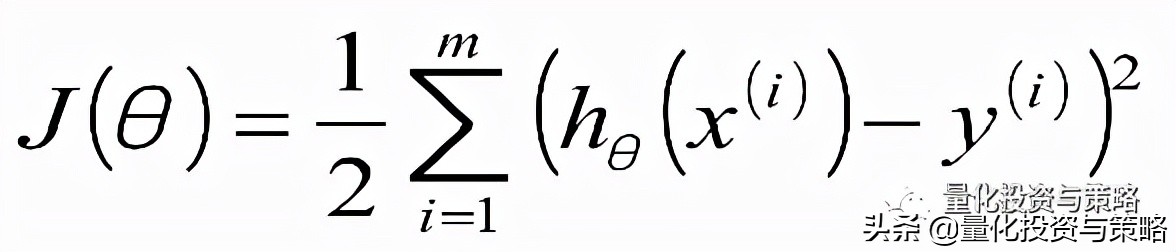
为了防止数据过拟合,也就是的θ值在样本空间中不能过大,可以在目标函数之上增加一个平方和损失:
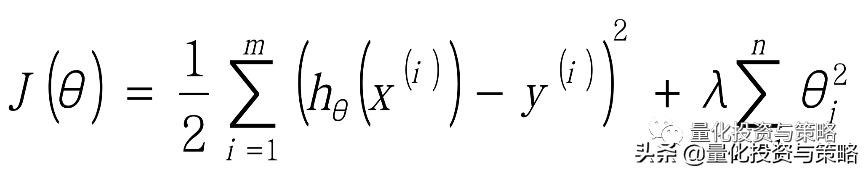
正则项(norm)/惩罚项:
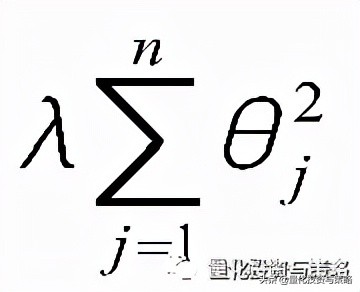
;这里这个正则项叫做L2-norm
L2-norm:
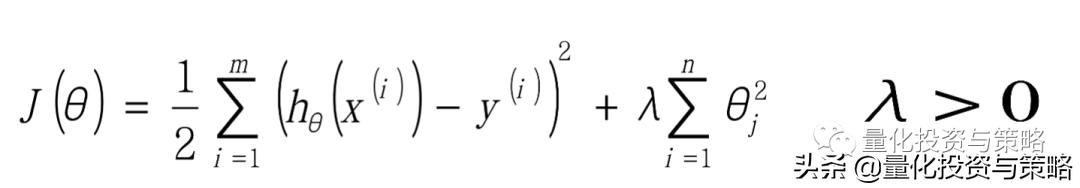
L1-norm:
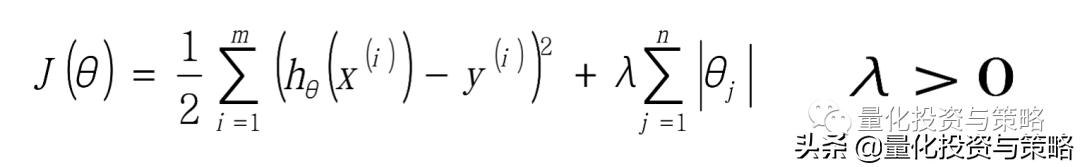
6.模型评价与效果
MSE:误差平方和,越趋近于0表示模型越拟合训练数据。
RMSE:MSE的平方根,作用同MSE。
R2:取值范围(负无穷,1],值越大表示模型越拟合训练数据;最优解释1;当模型预测为随机值的时候,有可能为负;若预测值恒为样本期望,R2为0。
TSS:总平方和TSS(Total Sum of Squares),表示样本之间的差异情况,是伪方差的m倍。
RSS:残差平方和RSS(Residual Sum of Squares),表示预测值和样本值之间的差异情况,是MSE的m倍。
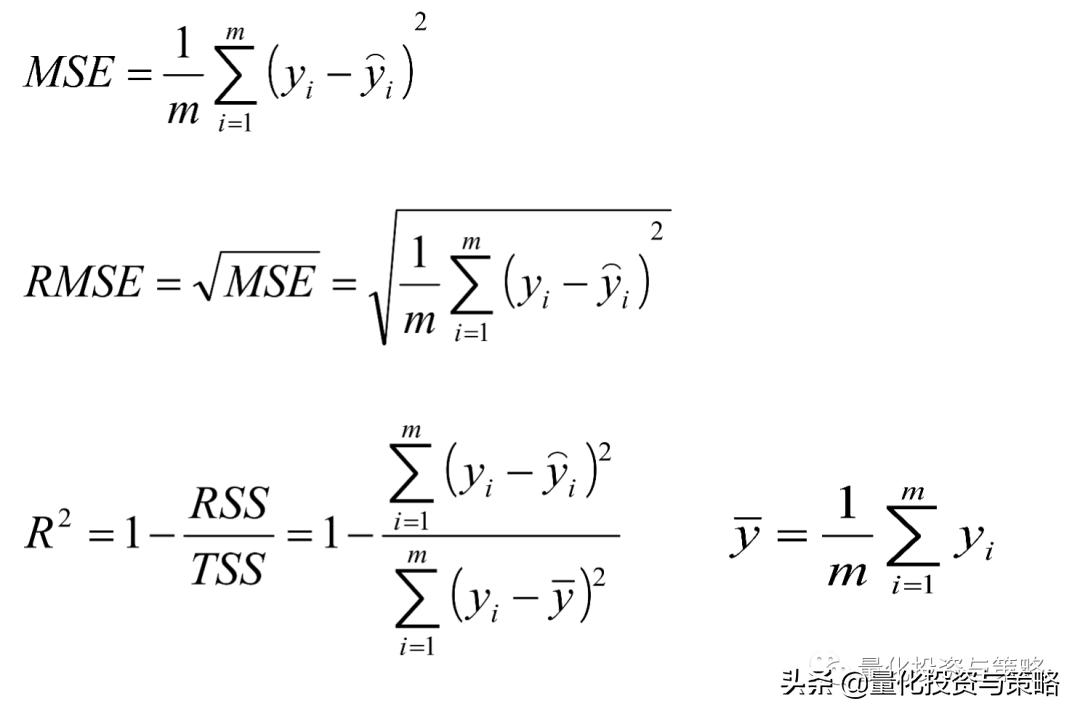
机器学习调参
在实际工作中,对于各种算法模型(线性回归)来讲,我们需要获取θ、λ、p的值;θ的求解其实就是算法模型的求解,一般不需要开发人员参与(算法已经实现),主要需要求解的是λ和p的值,这个过程就叫做调参(超参)。
交叉验证:将训练数据分为多份,其中一份进行数据验证并获取最优的超参:λ和p;比如:十折交叉验证、五折交叉验证(scikit-learn中默认)等。

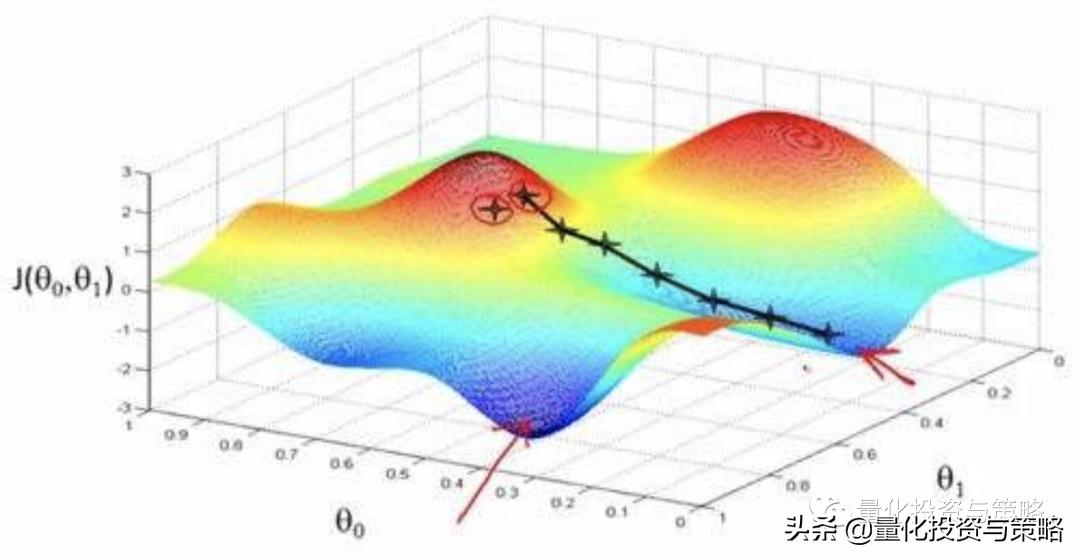
7.求解器:梯度下降法
梯度下降法(Gradient Descent, GD)常用于求解无约束情况下凸函数(Convex Function)的极小值,是一种迭代类型的算法,因为凸函数只有一个极值点,故求解出来的极小值点就是函数的最小值点。

举几个例子,一元和多元的情况,设置不同学习率去比较:
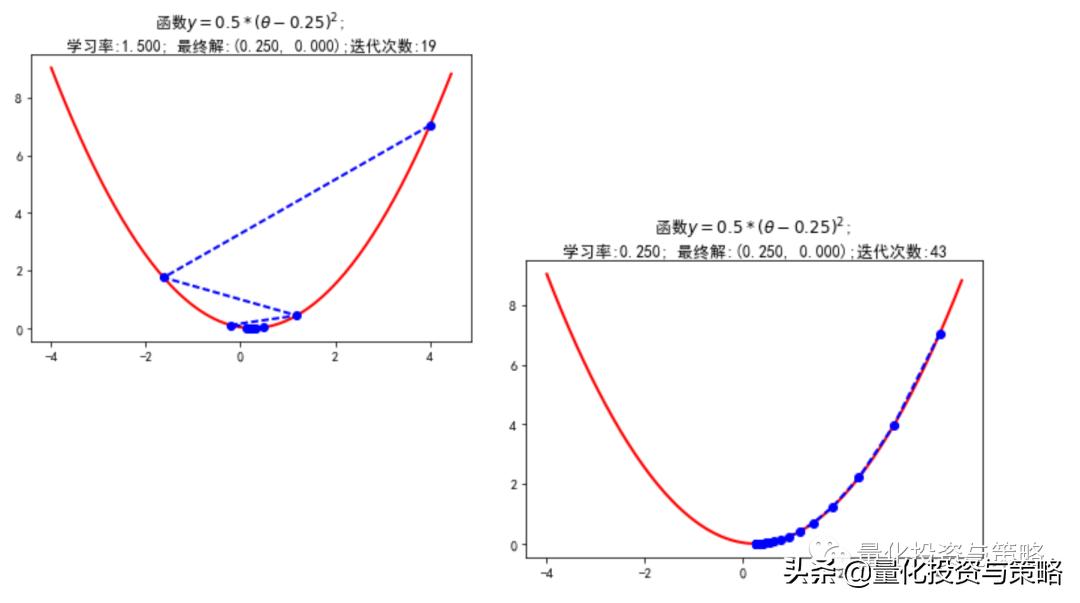
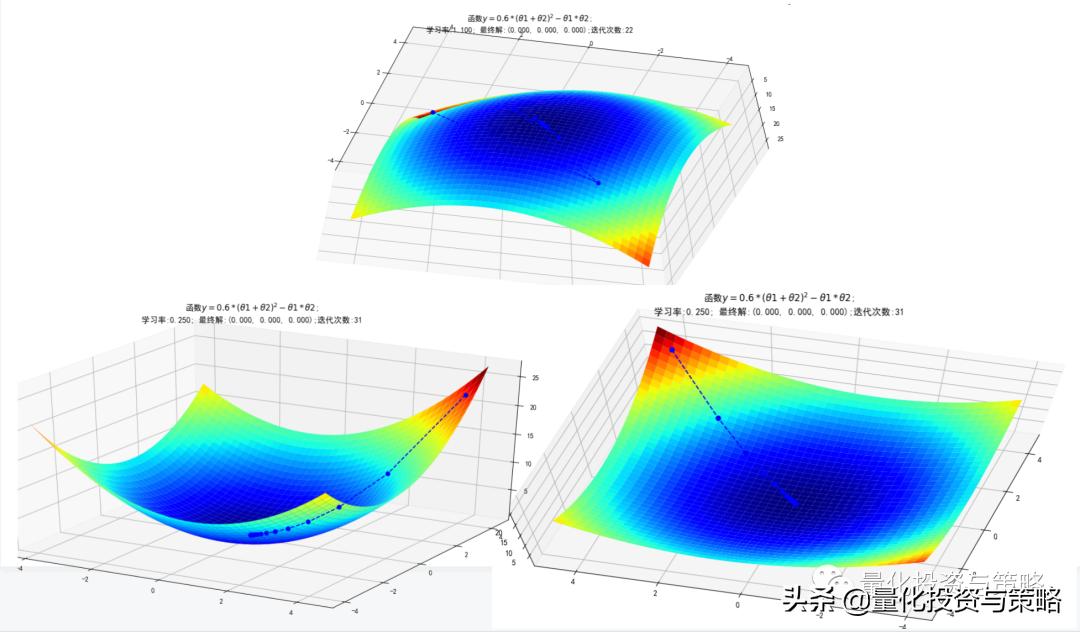
梯度下降算法,目标函数θ求解
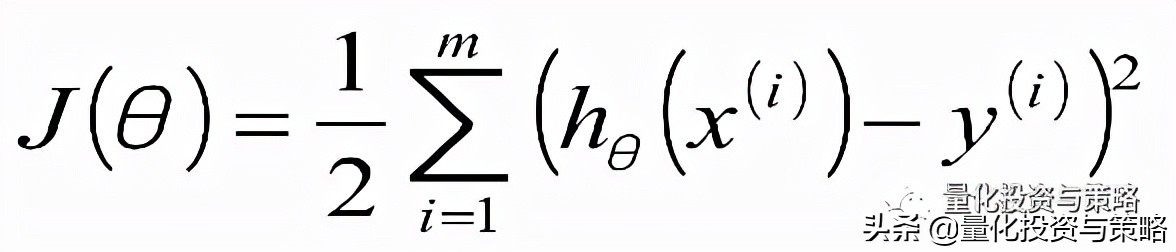
初始化θ(随机初始化,可以初始为0)
沿着负梯度方向迭代,更新后的θ使J(θ)更小:
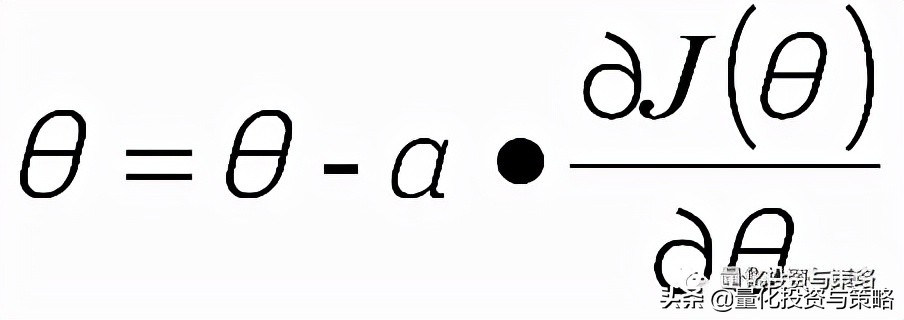
其中,α:学习率、步长
仅考虑单个样本的单个θ参数的梯度值:
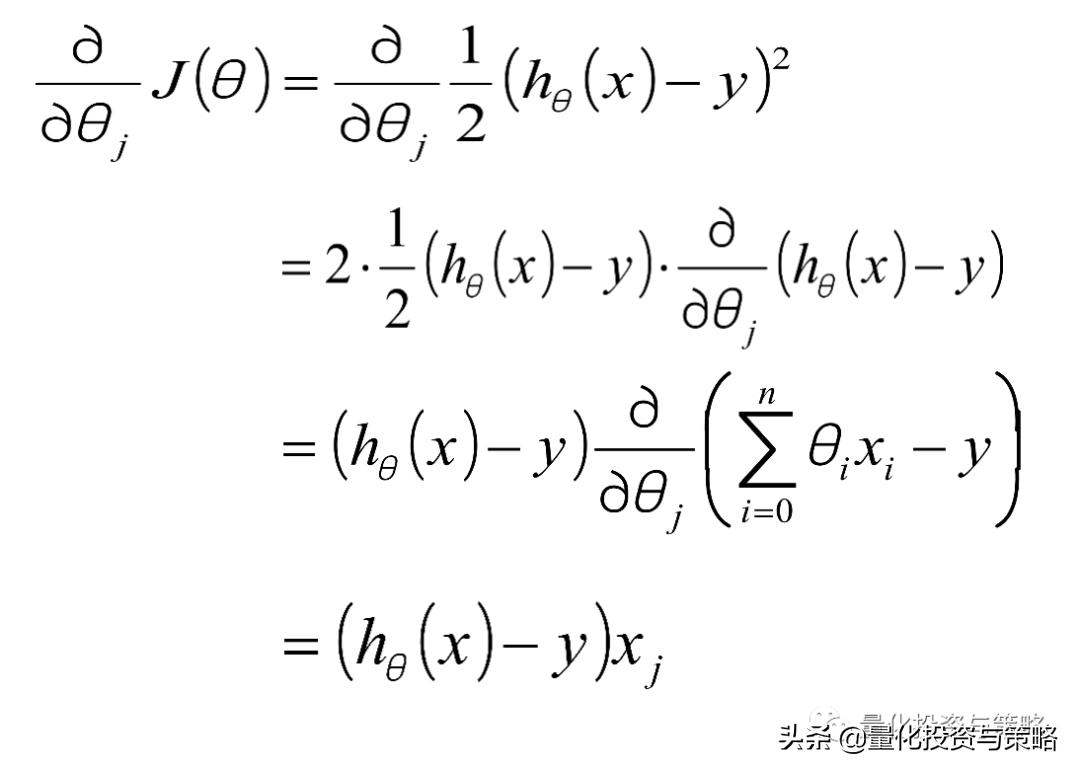
批量梯度下降算法(BGD):
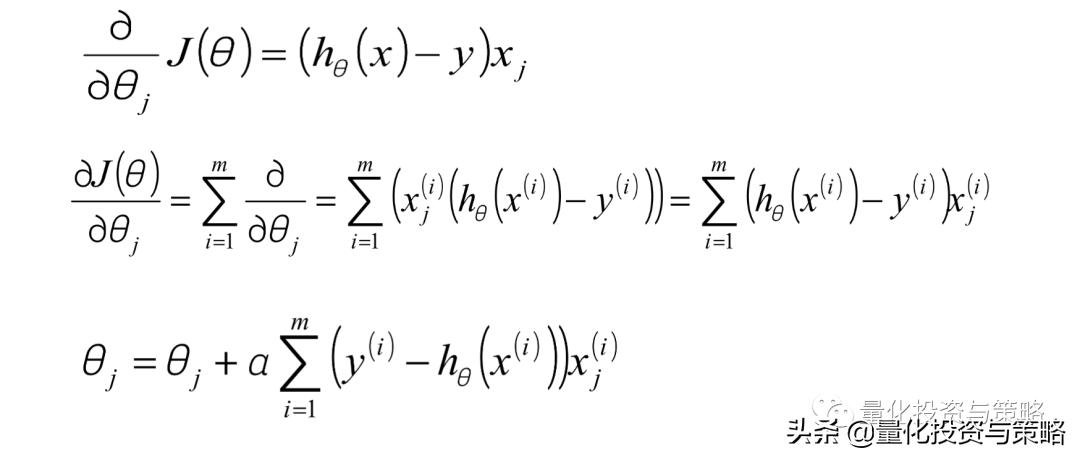
随机梯度下降算法(SGD):
使用单个样本的梯度值作为当前模型参数θ的更新
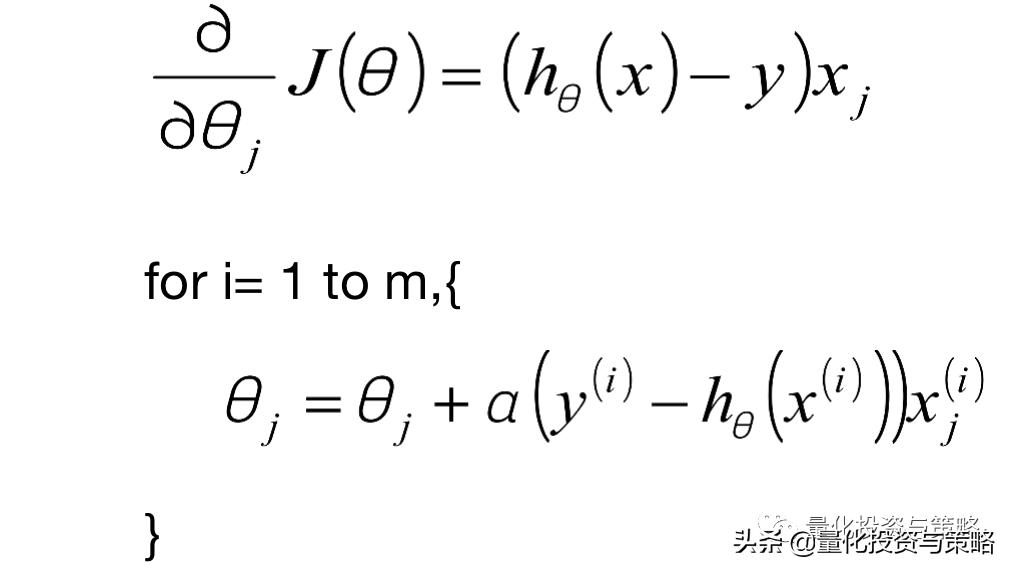
小批量梯度下降法(MBGD):如果即需要保证算法的训练过程比较快,又需要保证最终参数训练的准确率,而这正是小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)的初衷。MBGD中不是每拿一个样本就更新一次梯度,而且拿b个样本(b一般为10)的平均梯度作为更新方向。
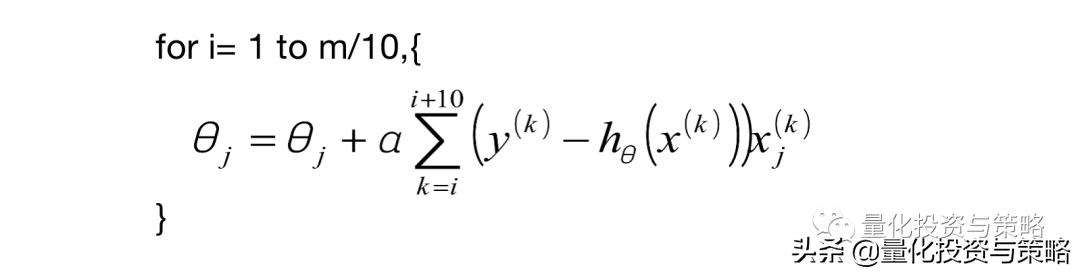
由于梯度下降法中负梯度方向作为变量的变化方向,所以有可能导致最终求解的值是局部最优解,所以在使用梯度下降的时候,一般需要进行一些调优策略:
学习率的选择:学习率过大,表示每次迭代更新的时候变化比较大,有可能会跳过最优解;学习率过小,表示每次迭代更新的时候变化比较小,就会导致迭代速度过慢,很长时间都不能结束;
算法初始参数值的选择:初始值不同,最终获得的最小值也有可能不同,因为梯度下降法求解的是局部最优解,所以一般情况下,选择多次不同初始值运行算法,并最终返回损失函数最小情况下的结果值;
标准化:由于样本不同特征的取值范围不同,可能会导致在各个不同参数上迭代速度不同,为了减少特征取值的影响,可以将特征进行标准化操作。
BGD、SGD、MBGD的区别 :
当样本量为m的时候,每次迭代BGD算法中对于参数值更新一次,SGD算法中对于参数值更新m次,MBGD算法中对于参数值更新m/n次,相对来讲SGD算法的更新速度最快;
SGD算法中对于每个样本都需要更新参数值,当样本值不太正常的时候,就有可能会导致本次的参数更新会产生相反的影响,也就是说SGD算法的结果并不是完全收敛的,而是在收敛结果处波动的;
SGD算法是每个样本都更新一次参数值,所以SGD算法特别适合样本数据量大的情况以及在线机器学习(Online ML)。
8.实现
回归问题确定几个变量之间的关系,我们能否思考:能够分析因子A、因子B作为自变量X1、X2,他们和价格Y的关系(是否能用因子A和因子B共同解释价格Y),接下来我们做一个例子,通过回归市值和波动幅度的关系,寻找我们常说的“大盘股炒不动,小盘股很活跃”这一概念。
在下面的实验中,我们会涉及回归问题,通过它求出因子和价格的关系,训练出一个稳定的可以用数学公式表达的方程,当有新的数据进入模型时,即可求出新的价格(拟合价格)。
import pandas as pd
# 查询个股(总市值)数据,要求市值在1千亿元以下,具体逻辑省略自我实现
def queryLargeCapStocks():
return []
# 获取股票某个区间内的所有收盘价(按天数),具体逻辑省略自我实现
def getStockClosePrice(stock, interval):
return None
# 根据股票池名单,求出5周期价格涨幅绝对值,按照排名返回,具体逻辑省略自我实现
def getStocksByRate():
retuen []
# 将数据合成Dataframe
df = pd.DataFrame()
df['market_cap'] = market_cap_list
df['momentum'] = momentum_list
df = df.fillna(0)
# 回归计算和绘图
from sklearn import linear_model
import matplotlib.pyplot as plt
# 建立线性回归模型
regr = linear_model.LinearRegression()
regr.fit(df['market_cap'].reshape(-1,1), df['momentum'])
# 得到斜率、截距项
a, b = regr.coef_, regr.intercept_
# 作图
# 1.数据
plt.scatter(df['market_cap'], df['momentum'], color='red')
# 2.拟合直线
plt.plot(df['market_cap'], regr.predict(df['market_cap'].reshape(-1,1)), color='blue', linewidth=2)
图略。