在网络活动中,网络的低延迟性一直是开发者与用户所关注的问题。缓存区过载会增加网络延迟,降低速度传输效率。SQM算法与数据流整形的方法都能减轻缓存区过载,从而优化用户体验。
缓存区过载的含义与影响
ISP指的是互联网提供商,在网络活动中,家庭网络中的设备连接到路由器,路由器再与ISP 相连接,从而访问Internet。在连接到光纤“骨干”,也就是为整个国家或地区服务的总光纤之前,ISP需要先连接到更大的ISP。
而要访问Web服务器时,数据博旭从家庭网络上的设备跨越许多其他设备,到达才能到达目的地,以在BBC网站上阅读新闻报道为例,数据的最终目的地是BBC 网端服务器。
当家庭或者用户的设备访问BBC网络服务器时,家庭网络上的多个设备都可能需要发送和接收数据。这些独立的数据流量流在家庭宽带路由器上相交。
因此一般来说,路由器需要配有数个输入端口,允许多个设备将数据从家庭网络发送到互联网,或者允许数据包从路由器的输出端口进行传输。
通常,家庭宽带路由器只有一个输出端口,连接到ISP的线路。作为互联网协议(IP)套件的一部分,传输控制协议(TCP)和用户数据报协议(UDP)负责在互联网上发送数据。TCP保证了数据包的传输,但它的传输速度比“尽力而为”的UDP慢。
当接收方收到TCP数据包时,会向将确认信息反馈给发送方。如果发送方没有收到对数据包的确认,则发送方就会重传该数据包。
还是以BBC阅读新闻为例,当人们访问BBC网络服务器时,路由器上的设备会通过网线相连接,传输方面,BBC网络服务器则使用了TCP slow,会缓慢增加发送的数据包数量,直到检测到缓存已到最大容量为止,这样能避免造成网络拥塞。
TCP使用流量控制来确保网络服务器的接收方效率,避免其被发送方设备的数据包淹没。这是接收器提供者声称的接收窗口效率。即使发送方发送数据包的速度够快,能与宣传中的接收窗口效果达成一致,但拥塞仍然可能发生在传输路径的任何设备上。
图1显示,在家庭网络设备发送方和BBC web服务器接收方之间,数据的传输路径上有许多设备。因此,传输速度可能受到发送方性能、接收方性能以及它们之间路径上的设备的影响。
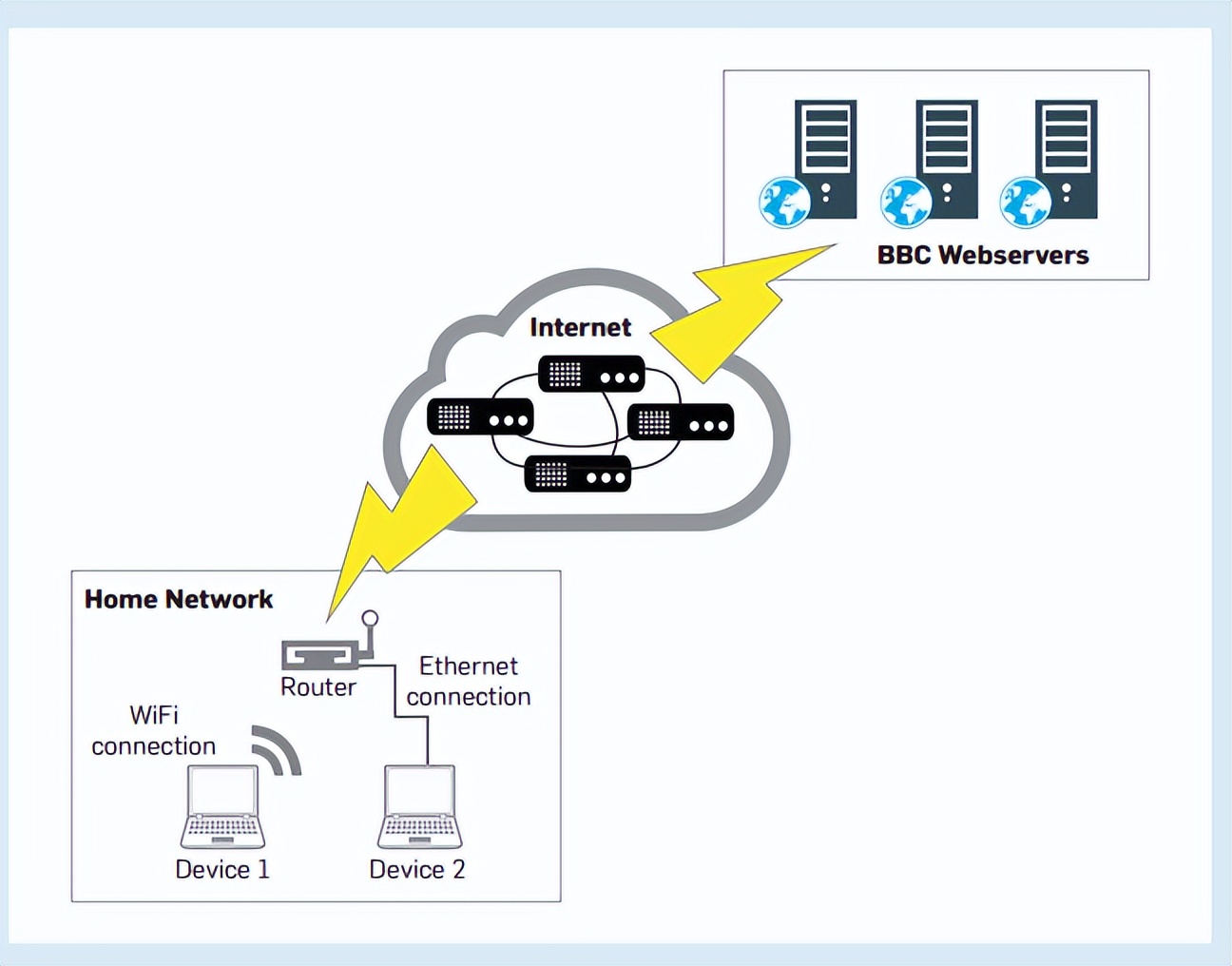
图1
当数据包的数量,也就是线路负载大于线路的容量时,传输路径上就会出现拥塞,数据包只能排队等待通过或直接被丢弃。
为了避免这种情况出现,TCP开发了拥塞控制机制,旨在利用发送的数据包流发送情况和确认情况,确定数据发送速率来避免拥塞。
如果TCP发送方检测到,它和接收方之间的路径数据很少或没有拥塞情况,它就会提高传输速率。如果发送方发送的数据*过包**多,则会导致接收方丢弃数据包,丢弃的数据包将不会被接收方确认。
如果一个数据包没有在第一时间收到确认反馈,则TCP会假定它已被丢弃。而丢弃的数据包向发送端发出传输速率较大,当其大于容量的信号时,数据传输速率还是会降低。因此,TCP拥塞控制是“反馈控制”。
但是延迟是传输延迟、处理延迟和排队延迟的组合。队列延迟取决于队列大小。因此,缓冲区过大也可能导致缓冲区膨胀。
如图2所示,路由器中缓冲区是一项必备要素,在拥塞发生时它会发挥作用,可以临时存储那些等待传输的数据包。有了缓冲区的存在,TCP和UDP数据包在排队时不会丢失,并且可以在带宽可用时发送。
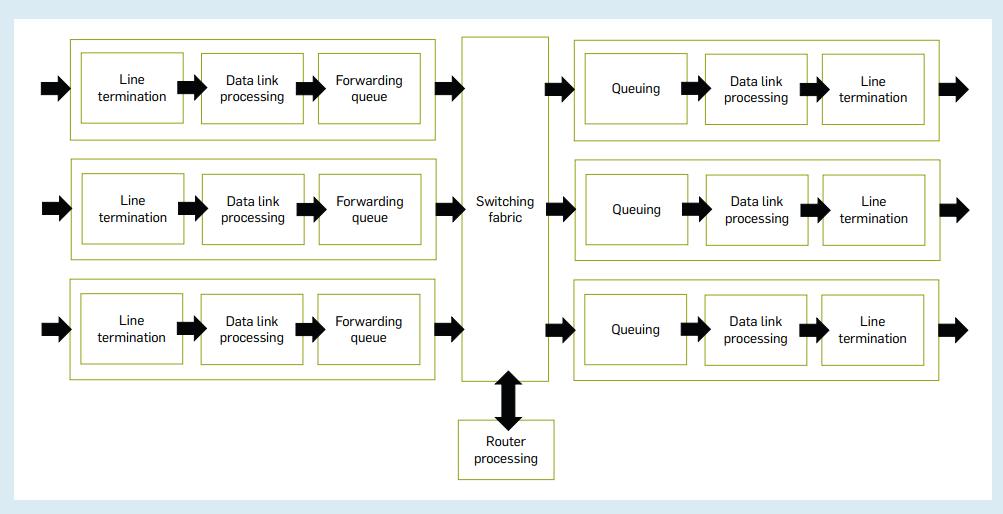
图2
路由器需要这些缓冲区以最大传输速率保持数据包流。但如果路径上的设备有很大的缓冲区,相关的问题出现,即数据包可能要等待很长时间才能发送。
由于数据包没有被丢弃,所以发送方不会收到线路容量已超出的信息,只有信息传送超时的时候,发送方才能知道传输路径上存在拥塞。
这种反馈延迟会影响路由器与接收器性能,如果延迟非常大,则用户端得到的网络状态反馈就会不准确。这就导致当拥塞发生时,数据传输防堵塞机制不会做出应有的响应,即降低数据包发送速率。
缓存区过载不仅会影响TCP,还会影响数据传输其他协议,部分原因是它们使用了相同的缓冲区。在数据包开始丢失之前,路由器的缓冲区可能就会填满数据。
虽然TCP数据包可以在交互式应用程序之前排队,但是当缓冲区及队列中有太多数据包时,就会出现缓冲区膨胀,数据包排队的时间就会增长,这会增加延迟,并导致应用程序性能下降。
图3演示了一个具体实例,对于正在进行视频通话的用户来说,延迟可能意味着他们正在观看五秒前,甚至更早之前的影音图像。不夸张的说,缓存区过载导致互联网的延迟,有时甚至会超过地球到月球的光传播延迟。
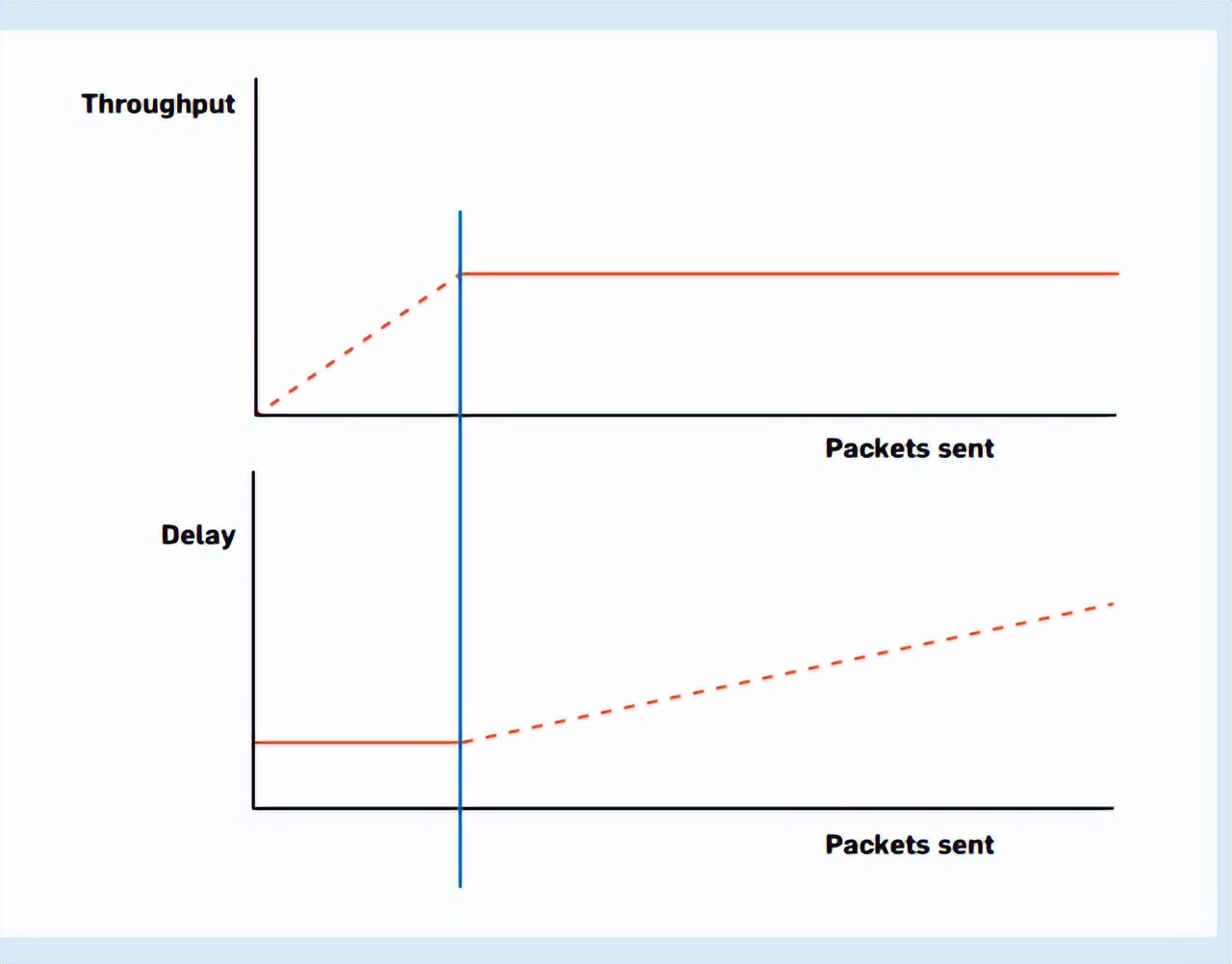
图3
与当今的路由器相比,较老的路由器具有较小的缓冲区,所以缓冲区满载的速度更快,线路饱和的信息反馈更及时,过载数据包也能迅速丢弃。
较新的路由器具有更大的缓冲区,通常可以保存相当于大约10秒的数据。因此,10秒的数据会在没有丢包反馈的情况下发送,这就产生了如图4所示的TCP锯齿状结构。
当线路上的容量可用时,TCP缓慢地提高数据速率,从图中可以看到线路缓慢上升,当拥塞发生时,它会迅速降低速率,比如图中的直线急剧下降。
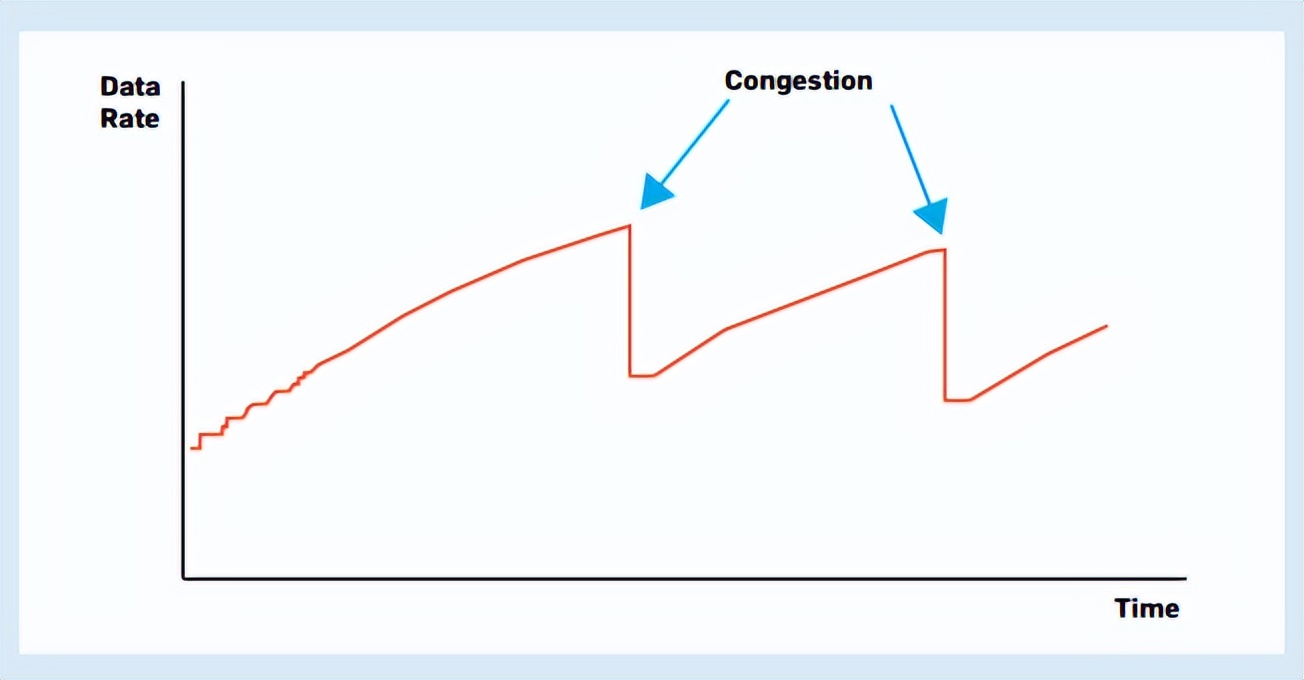
图4
随着内存成本的下降,路由器缓冲区变得更大了。但是缓冲区应该有多大,以及缓冲区大小如何影响网络带宽,目前还没有得到很好的理解。
路由器缓冲区的大小通常基于ANSNET中的高性能TCP中的规则。缓冲区大小的增加可以看作是防止网络拥塞,从而保证算法正常工作。
然而在大多数家庭宽带路由器上,用户不能更改缓冲区大小。路由器上的QoS (Quality of Service)设置也不能有效减少缓存区过载。当一些数据流量被优先化时,其余数据就会被排在后面。这意味着缓冲区中的所有数据流量仍然需要发送,但是速度更慢。
而高速连接不能防止缓冲区膨胀。延迟的时间可能仍然很长。而许多应用程序对延迟比对低带宽更敏感。通常受缓存区过载影响的延迟敏感应用包括但不限于,VoIP电话、视频会议、在线游戏、视频流与音乐流等等。
缓存区过载可以通过智能队列管理(SQM)算法得到缓解。SQM执行按包或者按流的网络调度、活动队列长度管理(AQM)、流量整形和速率限制以及QoS。
SQM会将来自单个IP地址或端口的流量放入自己的队列中。这意味着,与使用QoS时不同,拥塞时的队列不会变得太长,因为那些小队列中的数据包,以及没有队列的流数据包会被优先考虑。如果队列变得太大,算法则会丢弃一定比例的数据包,以使拥塞避免生效。
但是SQM成本较为高昂,许多消费级路由器制造商在成本考虑下,不会安装可以防止缓存区过载的固件。
进一步来说,路由器的设计已经好几年没有改变了,而且这个趋势似乎还会继续持续下去,所以用另一种方法减少缓存区过载是很有必要的。
缓存区过载缓解方法的验证实验
目前,数据流整形和SQM算法都能用于缓解缓存区过载,改善用户体验。为了更好地了解上述方法的适用性,缓存区过载的优化验证实验需要使用不同的路由器配置,结合优化算法进行大量测试,同时测量不同负载下的延迟效果。
为了排除其他因素的干扰,实验需要控制卸载和加载测试之间的延迟度,
过载优化验证实验测试了视频流与文件*载下**两种行为。关于视频流上传于*载下**行为,优化实验使用了两个设备来创建不同的负载,同时以不同的分辨率流式传输视频。当视频分辨率改变时,带宽需求也会所有改变。
视频的传输格式则包括720p、高清1080p和4K的2160p 。为了模拟用户在实际使用时的复杂行为模式,验证实验还尝试了用一台设备,将*载下**文件与*放播**视频视频同时进行。
在SQM算法测试方面,验证实验首先要使设备具有算法运行条件。要在路由器上启用SQM,用户需要安装OpenWRT固件的SQM包,luci-app-sqm。SQM使用的队列规则是cake,脚本是pieces_of_cake.qos,SQM链路层自适应设置是ATM和44字节的开销。
在数据流整形测试方面,用户可以利用日志含义修改路由器配置,在实验中,当使用数据流整形时,上游和下游都被整形为95%的线路容量。
对于每个测试,实验者都使用ping测试来记录最小、最大和平均延迟以及数据包丢失情况。
如果延迟随着负载的增加而显著增加,这表明路径中存在缓存区过载现象。此外,如果视频在测试过程中被缓冲、冻结或像素化,那么它们都会被记录下来。对于执行文件*载下**的测试,实验组则记录了*载下**文件所需的时间。
但是有些因素是研究人员无法控制的,比如YouTube服务器用于视频流的速度,微软服务器用于文件*载下**的模式,谷歌域名系统(DNS)服务器用于测量延迟的方法,以及用于使带宽饱和Me服务器执行情况。因此,每次测试都需要重复三次以检测异常。
在设置好后,实验验证了SQM和数据流整形的积极作用,它们都能减轻缓冲区过载和改善用户体验。同时不管是启用SQM还是数据流整形,其相对应的数据传输延迟都在一个很低的水平,在负载下也没有显着变化。
流媒体视频在观看时也没有出现缓冲、冻结或像素化现象。通过ping测试产生的平均往返时间(RTT)可以看出,当同时启用数据流和SQM时,数据传输的延迟最低。
从优化实验中可以看出,当使用这些机制时,流媒体视频不会缓冲、冻结或像素化。也就是说,当延迟一直维持在低水平时,对延迟敏感的应用程序不会受到影响。人们就算同时流视频、玩在线游戏、视频会议和进行VoIP呼叫,也不会出现延迟或应用程序不稳定的问题。
然而当启用SQM和数据流整形时,文件*载下**时间却增加,因为视频流量是优先级的。数据流整形确实会导致带宽的小损失,但相比之下,SQM能在缓解过载压力方面发挥更大作用。
过载优化方案的适用性讨论
自2011缓冲区过载问题第一次被提出以来,大量的互联网流量转向依赖于rtt的小突发,或者使用限速流,来限制控制缓冲区膨胀速率,以及控制进出网络的流量。然而,缓冲区过载的问题仍然存在。
根据1965年的摩尔定律,路由器容量每24个月翻一番。对于处理速度、内存容量、传感器等,摩尔定律解释了它们是如何随着价格的下降而呈指数级增长的。
如今,路由器有了更多的内存,但路由器的速度还是在受内存访问速度的限制,内存访问速度自2011年以来一直没有提高。
路由器通常具有动态随机存取存储器(DRAM)。DRAM的存取速度不如静态随机存取存储器(SRAM)快,但它具有更低的成本。因此,路由器内存通常是为大容量存储设计,而不是为了提高速度。
虽然SQM能够减轻缓冲区过载,降低网络延迟,但由于互联网服务提供商通常免费提供路由器,所以人们不太可能为带有SQM的路由器支付更多费用。而且SQM算法的OpenWRT固件网络界面也较为复杂,可能超出了大多数家庭宽带用户的理解范围。
此外,用户需要自己执行固件升级,不会提供对路由器的支持。
对于消费者级和ISP供应商提供的路由器来说,它们的重要目标是易于设置和操作。有报道称,一些ISP提供商正在他们提供的路由器中添加SQM。然而,当SQM与数据流整形相结合时,二者才能发挥出最佳性能。
由于互联网服务提供商寻求降低客户服务成本,而数据流成形过程需要较高水平的技术技能,这超出了大多数家庭用户的能力,因此在经济层面上,互联网服务提供商推广数据流成形的使用不太可行。