你好,世界! 我的数据科学社区博客。 上一篇文章我们讨论了线性回归中的端到端管道,这里我们将讨论数据科学家和从业者面临的最常见问题。 如果您的模型过拟合并且您想解决它,那么本文适合您。
什么是过拟合?
过度拟合是一种建模错误,当函数或模型过于紧密地拟合训练集并在测试集中拟合出现巨大差异时,就会发生这种过度拟合。 过度拟合模型通常采取制作过于复杂的模型的形式来解释所研究数据中的模型行为。
> Overfitted Data ['Image Created By Dheeraj Kumar K']
过度拟合的例子
让我们来看一些例子,
假设我们需要根据学生的简历来预测学生是否会进行工作面试。 现在假设我们从20,000个简历及其结果的数据集中训练模型。
然后,我们在原始数据集上尝试建立模型,并以98%的准确度预测结果……哇! 太神奇了,但事实并非如此。
但是现在来了一个坏消息。 当我们在新的简历数据集上运行模型时,我们只能获得50%的准确性。
我们的模型无法从我们的训练数据中得到很好的概括,无法看到看不见的数据。 这被称为过度拟合,这是数据科学中的常见问题。
实际上,过度拟合一直发生在现实世界中。 我们需要处理它以推广模型。
如何找到过拟合?
机器学习和数据科学中的主要挑战是,我们无法对模型性能进行评估,除非对其进行测试。 因此,找到过度拟合的第一步是将数据拆分为训练和测试集。
如果我们的模型在训练集上比在测试集上做得好得多,那么我们可能会过度拟合。
可以使用在两个数据集中观察到的准确度百分比来得出性能,以得出是否存在过度拟合的结论。 如果模型在训练集上的表现优于测试集,则意味着该模型可能过度拟合。 例如,如果我们的模型在训练集上看到99%的准确度,但在测试集上只有50%的准确度,那将是一个很大的警报。
如何防止过拟合?
· 训练更多数据
· 数据扩充
· 交叉验证
· 功能选择
· 正则化
让我们深入一点,
1.训练更多数据
防止过度拟合的方法之一是借助更多数据进行训练。 这些事情使算法更容易更好地检测信号,以最大程度地减少错误。 用户应不断收集更多数据,以提高模型的准确性。 但是,这种方法被认为很昂贵,因此,用户应确保所使用的数据相关且干净。
2.数据扩充
使用更多数据进行训练的另一种方法是数据增强,与前者相比,该方法便宜。 如果您无法连续收集更多数据,则可以使可用数据集看起来多样化。 数据扩充使样本数据每次在模型处理后看起来都略有不同。 该过程使每个数据集看起来对于模型都是唯一的,并阻止模型学习数据集的特征。
3.交叉验证
交叉验证是防止过度拟合的有力预防措施。
这个想法很聪明:使用您的初始训练数据来生成多个微型火车测试拆分。 使用这些拆分来调整模型。
在标准的k倍交叉验证中,我们将数据划分为k个子集,称为折叠。 然后,我们迭代训练k-1次折叠的算法,同时使用剩余的折叠作为测试集。
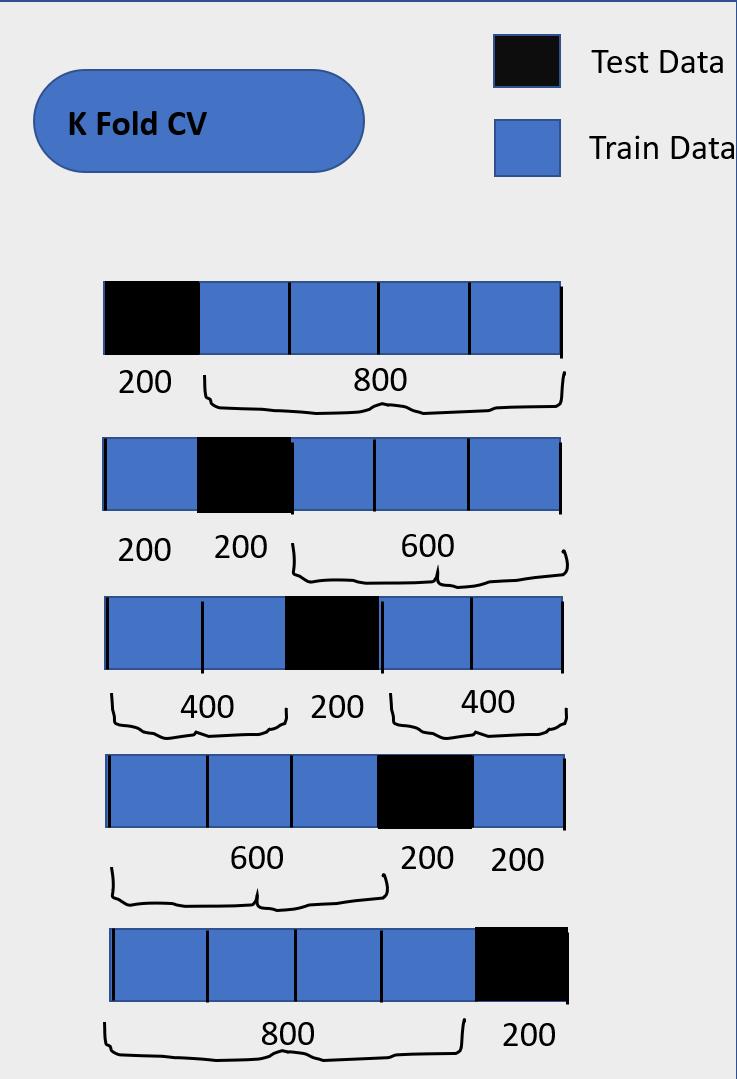
> Cross-Validation ['Image Created By Dheeraj Kumar K']
交叉验证使您可以仅使用原始训练集来调整超参数。 这使您可以将测试集作为选择最终模型时真正看不见的数据集。
from sklearn.model_selection import cross_val_score
from sklearn import model_selection
def kfold(models, train_X, train_y, seed=7, scoring='accuracy', n_splits=10):
results = []
names = []
for name, model in models:
kfold = model_selection.KFold(n_splits=n_splits, random_state=seed)
cv_results = model_selection.cross_val_score(model, train_X, train_y, cv=kfold, scoring=scoring)
results.append(cv_results)
names.append(name)
msg = "%s: %f (%f)" % (name, cv_results.mean(), cv_results.std())
print(msg)
4.特征选择
一些算法具有内置功能选择。
对于那些没有的,您可以通过删除不相关的输入功能来手动提高其通用性。
一种有趣的方法是讲一个有关每个功能如何适合模型的故事。 如果没有任何意义,或者很难证明某些功能的合理性,这是识别它们的好方法。
from sklearn.feature_selection import VarianceThreshold
varModel=VarianceThreshold(threshold=0)
varModel.fit(x_train)
constArr=varModel.get_support()
constArr
import collections
collections.Counter(constArr)
5.正则化
什么是正则化?
正则化是一种阻止模型复杂性的技术。 它通过惩罚损失函数来做到这一点。 这有助于解决过度拟合的问题。
为什么我们需要正则化?
我们来看一些例子
我们要预测学生的学生分数。 对于预测,我们使用学生的GPA分数。 该模型过于简单,因此具有较高的偏差,因此无法预测一系列学生的学生得分。
现在,我们开始添加更多可能会影响学生的学生成绩的功能。 我们会在模型中添加更多输入功能,出勤率,初中学生的平均成绩以及初中,学生的BMI,平均睡眠时间。 我们看到,随着输入功能的增多,模型变得太复杂了。
我们的模型还学习了数据模式以及训练数据中的噪声。 当模型试图拟合数据模式以及噪声时,则模型具有高方差广告,将被过度拟合。
过度拟合的模型在训练数据上表现良好,但不能一概而论。
正则化是三种类型
· L 1或套索
· L 2或山脊
· L 3或弹性网
L 1正则化或套索
Lasso回归与Ridge回归非常相似,并且有很大差异。 与Ridge相似,我们从一堆小鼠的体重和体重测量开始。 我们将数据分为两组,红色点是训练数据,绿色点是测试数据。
我们使用最小二乘法拟合一条直线到训练数据,这意味着最小化残差平方和。
当我们这样做时,即使该行确实非常适合训练数据,它的偏差也很低,如果不能很好地拟合测试数据,它的偏差也就很大。 在套索回归中,这里的残差平方和+λ*(|斜率|)的总和不是平方斜率,而是取绝对值。
像岭回归一样,λ值可以是从0到正无穷大的任何值,并且可以使用交叉验证来确定。 Ridge和Lasso回归之间的最大区别是ridge只能将变量渐近缩小到0,而Lasso可以将变量一直缩小到0
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.cross_validation import train_test_split
boston=load_boston()
boston_df=pd.DataFrame(boston.data,columns=boston.feature_names)
newX=boston_df.drop('Price',axis=1)
print newX[0:3] # check
newY=boston_df['Price']
X_train,X_test,y_train,y_test=train_test_split(newX,newY,test_size=0.3,random_state=3)
lasso = Lasso()
lasso.fit(X_train,y_train)
lasso100 = lasso(alpha=100)
lasso100.fit(X_train, y_train)
train_score=lasso.score(X_train,y_train)
test_score=lasso.score(X_test,y_test)
lasso00001 = Lasso(alpha=0.0001, max_iter=10e5)
lasso00001.fit(X_train,y_train)
train_score00001=lasso00001.score(X_train,y_train)
test_score00001=lasso00001.score(X_test,y_test)
coeff_used00001 = np.sum(lasso00001.coef_!=0)
L2正则化或岭回归
岭回归。 Ridge回归是线性回归的扩展。 它基本上是一个正规化的线性回归模型。
让我们开始收集一堆老鼠的重量和大小。 由于数据看起来相对线性,因此我们使用线性回归(最小二乘)来建模重量和尺寸之间的关系。 我们应该找到残差平方和最小的线结果。
该线的方程式
尺寸= 0.9 + 0.75 *重量
尺寸= 0.9 + 0.75 * 2.5
大小= 0.9 +1.88
大小= 2.8
当我们进行大量测量时,我们可以完全确信最小二乘法线可以准确反映尺寸和重量之间的关系。
如果我们只有两个测量值,则"新线"将以最小二乘法拟合。 由于新线与数据点重叠,因此残差平方的最小总和=0。第二张图显示了原始数据和原始线用于比较。
两个红点是训练数据,其余的绿点是测试数据。 训练数据的两个红点的残差平方和很小(这种情况下为0),而绿点的残差平方和则测试数据很大。
首先,插入与最小二乘拟合相对应的数字。
尺寸= 0.4 + 0.3 *重量
残差平方和+λ*(斜率)^ 2
(因为线与点重叠)0 + 1 *(1.3)^ 2 = 1.69
现在,将数字插入Ridge回归行
尺寸= 0.9 + 0.8 *重量
残差平方和+λ*(斜率)^ 2
(0.3)^ 2 +(0.1)^ 2 +1 *(0.8)^ 2 = 0.74
因此,Lambda值增加,然后对大小的预测变得不那么敏感,因此我们必须进行交叉验证才能确定λ值。
from sklearn.datasets import load_boston
from sklearn.linear_model import LinearRegression
from sklearn.linear_model import Ridge
from sklearn.cross_validation import train_test_split
boston=load_boston()
boston_df=pd.DataFrame(boston.data,columns=boston.feature_names)
newX=boston_df.drop('Price',axis=1)
print newX[0:3] # check
newY=boston_df['Price']
X_train,X_test,y_train,y_test=train_test_split(newX,newY,test_size=0.3,random_state=3)
rr = Ridge(alpha=0.01)
rr.fit(X_train, y_train)
rr100 = Ridge(alpha=100)
rr100.fit(X_train, y_train)
train_score=lr.score(X_train, y_train)
test_score=lr.score(X_test, y_test)Ridge_train_score = rr.score(X_train,y_train)
Ridge_test_score = rr.score(X_test, y_test)Ridge_train_score100 = rr100.score(X_train,y_train)
Ridge_test_score100 = rr100.score(X_test, y_test)
L3正则化或弹性网
如果我们对模型中的所有参数都了解很多,则可以轻松选择是否要使用套索回归或山脊回归。
如果我们的模型有变量罐头怎么办?
要知道太多的变量太困难了,那么我们当然需要使用一些正则化方法来估计它们。
但是,我们中的变量可能有用或无效,我们事先不知道。
现在我们应该选择套索回归还是岭回归?
我们不必选择任何东西,而是可以转到Elastic Net Regression。
就像Lasso和Ridge弹性回归从最小二乘开始一样,它结合了Lasso回归罚分和Ridge回归罚分
λ1* |变量1 | +…+ | 变量x | +λ2* [|变量1 |]²+…+ [| 变量x |]²
套索回归+我们不必选择任何东西,相反,我们可以转到Elastic Net Regression。
就像Lasso和Ridge弹性回归从最小二乘开始一样,它结合了Lasso回归罚分和Ridge回归罚分
λ1* |变量1 | +…+ | 变量x | +λ2* [|变量1 |]²+…+ [| 变量x |]²
套索回归+岭回归
我们对λ1和λ2的不同组合使用交叉验证,以找到最佳值
我们对λ1和λ2的不同组合使用交叉验证,以找到最佳值
结论
在此博客中,我们讨论了过度拟合,其预防以及正则化技术的类型,正如我们所看到的,Lasso帮助我们进行偏差方差折衷,并帮助我们进行重要的特征选择。 而Ridge只能将系数缩小到接近零。
我希望这可以作为探索其他测试和方法的入门。
另外,让我知道我是否错过了"过拟合概念"中的任何内容。
(本文翻译自Dheeraj Kumar K的文章《The problem of Overfitting in Regression and how to avoid it?》,参考:https://medium.com/datadriveninvestor/the-problem-of-overfitting-in-regression-and-how-to-avoid-it-dac4d49d836f)