最近在听阿陈播的二号*长首**,非常过瘾,1~3部全听完了,发现后续还有高手过招。不过是在爱书音网页上。

不过一共122集,于是想实现把这些的音频mp3都*载下**到手机上听。
分析了下 :
比如第18集,url是“https://www.ishuyin.com/player.php?mov_id=19248&look_id=18&player=down”
打开每集的页面,中间有个*载下**,href里面真好是mp3的*载下**地址:
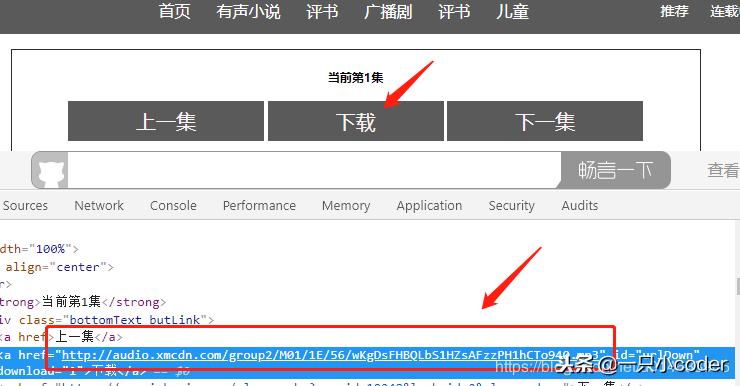

但是事情没那么简单,通过查看网页源码发现:


这个href是加密的,是通过js动态算出来的。在页面中找找js,发现了加密算法:


也就是先通过*切割字符串,再将每个数字转换成字母。
通过以上分析,就有了思路:
全部代码:
import requests
import json
from bs4 import BeautifulSoup
s = requests.Session()
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Host": "www.ishuyin.com",
"Referer": "https://www.ishuyin.com/show-19248.html",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36"
}
def parse(url):
ret = s.get(url=url, headers=headers)
soup = BeautifulSoup(ret.content, "html.parser")
d = soup.select("#urlDown")[0]
h = d.attrs["href"].split("*")
r = "".join([chr(int(x)) for x in h if x != ""])
return r
def download(link, index):
ss = requests.Session()
ret = ss.get(link)
with open("mp3/{}.mp3".format(index), 'wb') as file:
file.write(ret.content)
if __name__ == '__main__':
for i in range(34, 123):
url = "https://www.ishuyin.com/player.php?mov_id=19248&look_id={}&player=down".format(i)
link = parse(url)
download(link, i)
print(u"第{}集*载下**完成".format(i))
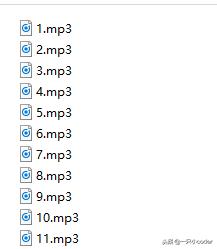
效果:



源码:https://github.com/onelittlecoder/python/blob/master/cmd/multi-download-ishuyin-mp3.py