要点
- TCP协议的基本概念。
- 定位TCP问题的常用工具。
- 一些常见的网络问题。
基本概念
TCP状态转换
TCP的状态变迁图如下:
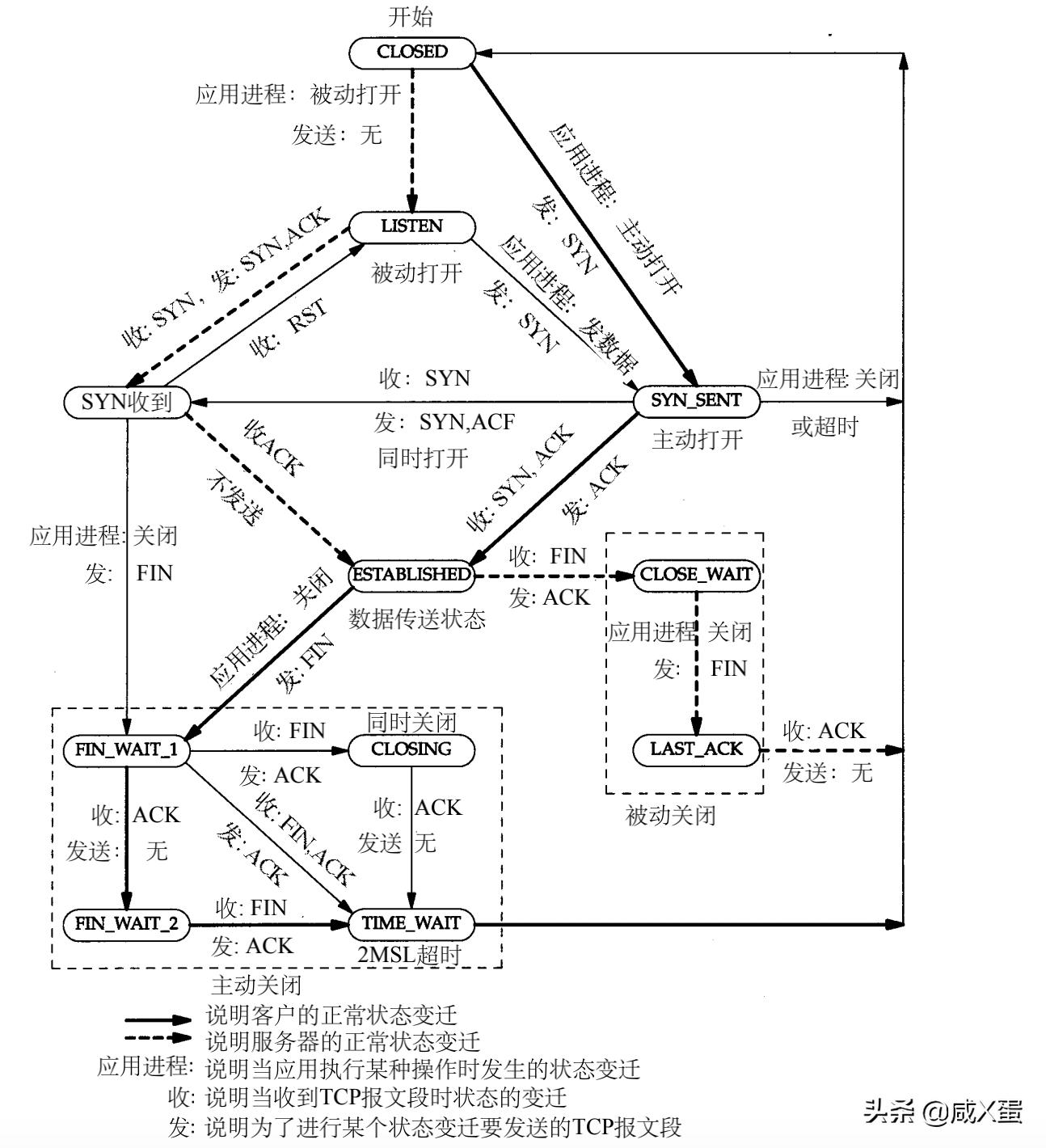
掌握TCP的状态变迁,对分析网络问题,有着非常重要的意义。结合tcpdump工具,能发现很多网络相关的问题。
连接建立与关闭

通过上图,可以清晰地知道,每个系统函数调用之后,TCP的状态转换过程,对于定位应用程序的网络相关问题,有重要帮助。
复位报文
TCP首部中的RST比特是用于“复位”的,一般情况是: 到不存在的端口的连接请求 和 异常终止一个连接 。
backlog
它表示 未完成连接队列 和 已经完成连接队列 之各。如果连接队列中已没有空间,对于新的连接请求,TCP将不会理会收到的SYN,也不发回RST。
SO_KEEPALIVE
TCP套接字设置该选项后,如果2小时内(tcp_keepalive_time)内,在该套接字的任一方向上都没有数据交换,TCP就自动给对端发送一个保活探测报文。这是一个对端必须响应的TCP分节,它会导致以下三种情况之一:
- 对端以期望的ACK响应:一切正常。
- 对端以RST响应:对端已崩溃且重新启动,套接字关闭,错误为ECONNRESET。
- 对端没有任何响应:套接字关闭,分以下两种情况:1) 服务器没有任何响应,并在75秒(tcp_keepalive_intvl)后超时,服务器总发送10个(tcp_keepalive_probes)这样的探查,每个间隔75秒,错误为ETIMEOUT。2) 收到一个ICMP错误的响应,服务不可达,错误为EHOSTUNREACH。
UDP
UDP是一种面向报文的、无连接、不可靠的通信协议,它支持一对一,一对多,多对一和多对多的通信方式。在能容忍数据包丢失,实时性要求较高的场景中,可以考虑使用,如视频、直播等。
分析工具
netstat
查看网络连接状态。
# netstat -nap
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN 1321/sshd
tcp 0 0 10.17.0.11:43026 10.10.10.1:8086 ESTABLISHED 31714/agent
tcp 0 0 10.17.0.11:58238 10.10.10.2:5574 ESTABLISHED 21114/Service
- Recv-Q:当连接为 ESTABLISHED 状态时,表示没有被应用程序取走的字节数。当连接为 LISTEN 状态时,表示syn backlog的当前值。
- Send-Q:当连接为 LISTEN 状态时,表示没有被远端确认的字节数。当连接为 LISTEN 状态时,表示最大的syn backlog值。
- Local Address:本地端口地址。
- Foreign Address:远端端口地址。
- State:套接字状态。
tcpdump
抓取数据包工具。
- 抓取eth0网卡所有数据包。
# tcpdump -i eth0
- 抓取eth0网卡中,主机10.1.1.2所有的收发数据包。
# tcpdump -i eth0 host 10.1.1.2
- 抓取eth0网卡中,主机:10.1.1.2,端口:3344所有的收发数据包。
tcpdump -i eth0 host 10.1.1.2 and port 3344
- 抓取eth0网卡中,主机:10.1.1.2发送的数据包。
tcpdump -i eth0 src host 10.1.1.2
- 抓取eth0网卡中,发往主机:10.1.1.2的数据包。
tcpdump -i eth0 dst host 10.1.1.2
sar
查看网络相关的历史统计数据。
# sar -n DEV 1
Linux 3.10.0-1127.19.1.el7.x86_64 (VM-0-11-centos) 2021年11月05日 _x86_64_ (1 CPU)
18时14分14秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
18时14分15秒 eth0 17.00 17.00 2.88 4.27 0.00 0.00 0.00
18时14分15秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
^C
18时14分15秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
18时14分16秒 eth0 18.52 14.81 1.48 2.56 0.00 0.00 0.00
18时14分16秒 lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
平均时间: IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
平均时间: eth0 17.53 16.23 2.39 3.67 0.00 0.00 0.00
平均时间: lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00
- rxpck/s、txpck/s:每秒接收(发送)的数据包。
- rxkB/s、txkB/s:每秒接收(发送)的千字节。
- rxcmp/s、txcmp/s:每秒接收(发送)的压缩包数。
- rxmcst/s:每秒接收的多播数据包数。
iftop
可以用来查看网卡的实时流量信息,中间的箭头表示流量方向。
- RX、TX:接收(发送)流量。
- TOTAL:总流量。
- Cumm:运行iftop到目前时间的总流量。
- peak:过去40s的流量峰值。
- rates:分别表示过去2s 10s 40s 的平均流量。
traceroute
显示数据包到指定主机之间的路由信息,可以检查网络延时。
# traceroute github.com
traceroute to github.com (20.205.243.166), 30 hops max, 60 byte packets
1 9.30.191.130 (9.30.191.130) 2.445 ms 2.714 ms 2.959 ms
2 9.30.251.110 (9.30.251.110) 2.172 ms 2.391 ms 2.523 ms
3 10.196.36.126 (10.196.36.126) 2.234 ms 2.417 ms 10.196.36.62 (10.196.36.62) 2.215 ms
4 10.200.65.101 (10.200.65.101) 2.986 ms 10.200.65.121 (10.200.65.121) 3.352 ms 10.200.65.101 (10.200.65.101) 2.838 ms
5 10.162.5.110 (10.162.5.110) 3.908 ms 101.227.217.26 (101.227.217.26) 2.977 ms 7.735 ms^C
每一跳会显示连续的三个RTT值。
分析策略
1、检查网络统计信息,网络包速率和网络接口吞吐量:ss、netstat、sar。
2、跟踪新TCP连接的建立和时长来分析负载:tcplife。
3、跟踪TCP重传和其他的不常见TCP事件:tcpretrans、tcpdrop、skb:kfree_skb跟踪点。
4、测量DNS延迟,这可能是一个性能问题,如:gethostlatency。
5、测量各维度的网络延迟,如连接延迟、首字节延迟、软件栈各层之间的延迟等。注意,如有可能,网络延迟测试应该在负载和空闲网络中分别测试,进行比较。
6、检查主机之间的网络吞吐量上限,同时检查在已知负载情况下发生的网络事件。
7、使用高频CPU性能分析抓取内核调用栈信息,以量化CPU资源在网络协议和驱动程序之间的使用情况。
8、使用跟踪点和kprobes来探索网络软件栈的内部情况。
常见问题
TIME_WAIT存在的2MSL的意义
在TCP实现中,每个报文的最大生存时间为MSL,2MSL则表示,一个报文在一个连接中,一来一回的时长。它存在的意义主要是,1、保证最后一个ACK,已经到达到远端。2、保证连接(客户端IP和端口,服务端IP和端口)只能在2MSL后才能使用。
TIME_WAIT过多
从TCP状态转换图可知,TIME_WAIT状态的出现,是由于 主动断开 连接导致的。也就是说,应用程序中存在大量的短连接,因此,解决TIME_WAIT过多的方法是,找出短连接的业务逻辑,将其修改为长连接。当然,如果应用程序作为服务端,主动断开了大量连接,可能需要结合业务作进一步分析断开原因。
可能还有的解决方案是,修改系统参数: tcp_tw_reuse 、 tcp_tw_recycle 和 tcp_max_tw_buckets ,这三个参数的含义是:
- tcp_tw_reuse: 该参数需要在两端打开 tcp_timestamps ,否则无效。它表示复用TIME_WAIT状态下的连接,在主动连接时生效。
- tcp_tw_recycle: 该参数需要在两端打开 tcp_timestamps ,否则无效。它表示将TIME_WAIT状态下的连接快速回收,在4.12内核版本中已废弃。
- tcp_max_tw_buckets: 控制TIME_WAIT的并发数量,达到一定数量后,系统会清理所有的TIME_WAIT连接,并打印日志。
使用修改 tcp_tw_reuse 和 tcp_tw_recycle 参数的方式,本身是有 风险 的,并不符合TCP协议规范。它可能导致延时的报文与新连接混在一起。尤其是 tcp_tw_recycle 参数,在NAT网络中,可能会导致SYN报文丢弃。可参考RFC 1122中关于TIME_WAIT重用的处理。
CLOSE_WAIT过多
当应用程序收到对端发过来的FIN报文,而未调用close()函数时,会在被动关闭一方,出现CLOSE_WAIT状态。因此,当出现大量CLOSE_WAIT状态时,通常是应用程序,未及时调用close()关闭连接。更进一步分析,可以看看,应用程序在处理对端连接关闭请求时是否有问题,还是Recv-Q有堆积。
Recv-Q和Send-Q堆积
判断当前连接状态是,Established还是Listening,然后,分析应用程序,是堵塞在收发数据包阶段,还是取连接的阶段。
TCP中KeepAlive与HTTP中keep-alive区别
- KeepAlive是传输层的保活机制。keep-alive是应用层的保活机制。
- KeepAlive是当两个socket之间无数据交换时,进行保活检测的机制。keep-alive是指一次HTTP请求之后,不会将该连接断开,即与web服务之间,维护一个长连接,后续请求可以复用该连接。
参考
《Systems Performance:Enterprise and Cloud》
《BPF Performance Tools》
《Computer Systems》
《Modern Operating Systems》
《TCP/IP详解 卷1:协议》
http://www.brendangregg.com/linuxperf.html
https://datatracker.ietf.org/doc/html/rfc1122
https://vincent.bernat.ch/en/blog/2014-tcp-time-wait-state-linux