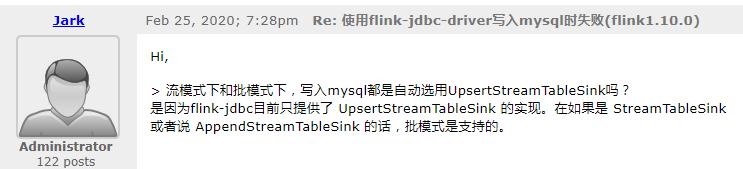
导读:在Flink1.10版本中,在Batch环和使用Blink Planner 创建TableSink出现了Batch环境不支持RetractStreamTableSink 和 UpsertStreamTableSink。下面将详细讨论导致该问题的原因及对应的解决方式。
场景
//创建流运行时环境
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bsTableEnv = TableEnvironment.create(bbSettings);
/*StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);*/
//输出目标(MySQL) 此处记得需要引入flink-jdbc 及对应的 数据库驱动包
bsTableEnv.sqlUpdate("CREATE TABLE sourceTable (" +
"USER_NAME VARCHAR," +
"USER_SEX VARCHAR" +
")" +
"WITH (" +
"'connector.type' = 'jdbc'," +
"'connector.url' = '"+JDBC_URL+"'," +
"'connector.table' = 'flink_test_user'," +
"'connector.driver' = 'com.mysql.jdbc.Driver'," +
"'connector.username' = 'root'," +
"'connector.password' = 'Marry583@&%!'," +
"'connector.write.flush.max-rows' = '1')");
//输出目标(MySQL) 此处记得需要引入flink-jdbc 及对应的 数据库驱动包
bsTableEnv.sqlUpdate("CREATE TABLE sinkTable (" +
"USER_NAME VARCHAR," +
"USER_SEX VARCHAR" +
")" +
"WITH (" +
/*"'update-mode' = 'append'," +*/
"'connector.type' = 'jdbc'," +
"'connector.url' = '"+JDBC_URL+"'," +
"'connector.table' = 'flink_test_user2'," +
"'connector.driver' = 'com.mysql.jdbc.Driver'," +
"'connector.username' = 'root'," +
"'connector.password' = 'Marry583@&%!'," +
"'connector.write.flush.max-rows' = '1')");
//编写SQL语句
bsTableEnv.sqlUpdate("INSERT INTO sinkTable SELECT USER_NAME,USER_SEX FROM sourceTable");
//执行
bsTableEnv*ex.e**cute("MySQLDDLTest");
运行结果如下,Batch环境不支持RetractStreamTableSink 和 UpsertStreamTableSink

对于RetractStreamTableSink、UpsertStreamTableSink和AppendStreamTableSink的大概区别如下,这里就不做详细讨论。

分析问题
1、首先,查看源码发现BatchTableSink中并不存在UpsertStreamTableSink或AppendStreamTableSink而只有JDBCAppendTableSink,那么为什么会出现上面的错误?

2、查阅资料时一位朋友提到了一些相关信息,大概了解到了默认选择使用UpsertStreamTableSink。那么Flink代码具体是怎么做的?
3、我们来跟踪一下源码
在org.apache.flink.table.client.gateway.local.ExecutionContext 的createTableSink方法进行Sink的创建,在这里注意到这两个判断是StreamPlaner或BatchPlaner。

通过查看这两个判断发现,如果我们采用Blink Planner的话,那么都认为是StreamPlaner。我们在最先创建环境的时候使用了Blink Planer(相比于Old Planner对SQL有更好的支持)。
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
通过查看判断发现,Blink Planner一律都默认为是StreamPlanner。那么导致接下来在创建Sink时使用的是StreamTableSourceFactory。

从StreamTableSourceFactory追踪到JDBCTableSourceSinkFactory工厂的createStreamTableSink方法。发现在创建Sink时创建的是JDBCUpsertTableSink。而JDBCUpsertTableSink实现了UpsertStreamTableSink。
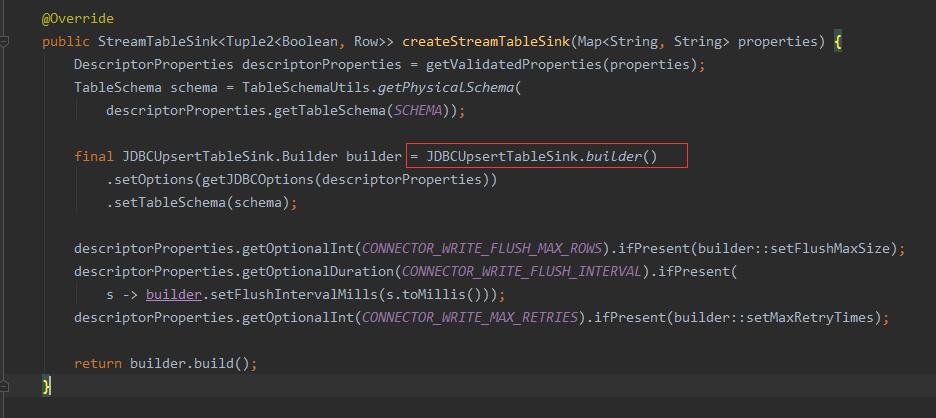
通过上面的跟踪我们发现了Blink Planner在创建TableSink时,无论环境是Stream还是Batch创建的都是UpsertStreamTableSink。但是Batch环境下并不支持UpsertStreamTableSink,所以最终导致了上述的异常。
RetractStreamTableSink and UpsertStreamTableSink is not supported in Batch environment
关于解决方案
- 使用流环境
- 关注Flink github对应的RP
1、使用流环境
//流环境
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
通过将环境改为流环境虽然可以正确运行,但是使用流环境及批环境还是存在一定差异的。如:批模式会等所有数据都处理完以后,一次性输出最终结果。流模式会持续不断输出结果,以及更新结果,是一种增量模式。对于相同的数据集以及相同的 query,从最终结果上来说,流与批运行的结果是一致的。但是批模式必然要比流模式性能更优(因为计算量更少),流模式的优势是"提前(实时)看到结果"。
2、RP
目前已有人对此问题进行了处理,感兴趣的朋友可以关注一下,尝试拉取并构建。
https://github.com/apache/flink/pull/11045
最后
感谢您的阅读,如果喜欢本文欢迎关注和转发,本头条号将坚持持续分享IT技术知识。对于文章内容有其他想法或意见建议等,欢迎提出共同讨论共同进步