我们知道,char类型的长度是一个字节,ASCII码使用7位能够编码了128个字符。
扩展的ASCII使用全部的8个位(1字节)可以编码256个字符。
自然,对于中文,常用汉字就有6000左右,一个字节无法全部完成编码,如果使用两个字节,便可编码2^16=65536个字符了。
而C编译器便是使用两个字节来解析一个中文字符(unicode编码方案的utf-16存储方案)。
对于多字节编码,不同的编码方案可以使用不同的存储方案,如unicode编码方案,可以使用变长存储方案uft-8,固定两字节的uf-16或固定四字节的utf-32。
如果操作系统的系统区域 locale 设置为简体中文,那么两个连续的扩展 ASCII 码就会根据 GB2312 编码解析。
中文的 GB2312 编码,将汉字分成 94 个区和 94 个位,区和位分别使用了扩展 ASCII 码的 161~254 这个范围。
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
int main()
{
// “中国”两字的区位码分别是 5448 2590"
char s[] = {160 + 54, 160 + 48, 160 + 25, 160 + 90, 0}; // 中国
printf("%s\n",s); // 中国
char str[] = "中国,你好!";
printf("%s\n",str); // 中国,你好!
printf("%s\n",str+6); // 你好!
printf("%c%c\n",str[0],str[1]); // 中
printf("%c%c\n",str[6],str[7]); // 你
//setlocale(LC_ALL, "zh_CN.UTF-8");
setlocale( LC_ALL, "chs" );
wchar_t wstr[] = L"中国,你好!";
wprintf(L"%s\n",wstr); // 中国,你好!
wprintf(L"%c\n",wstr[3]); // 你
while(1);
return 0;
}
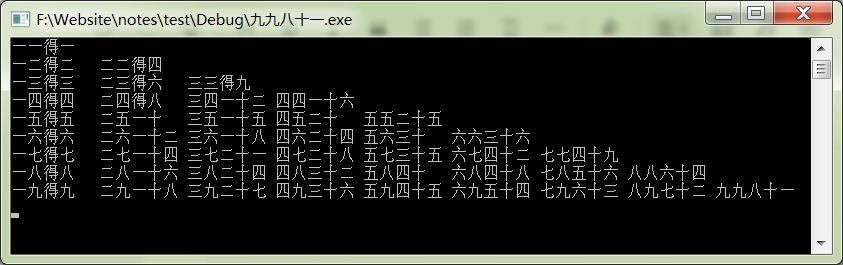
1 使用char数组输出九九乘法表
#include <stdio.h>
char str[] = " 一二三四五六七八九";
void outchar(int n);
int main()
{
for(int i=1;i<=9;i++)
{
for(int j=1;j<=i;j++)
{
//printf("%d%d得%d\t",j,i,j*i);
if(i*j<10)
printf("%c%c%c%c得",str[j*2],str[j*2+1],str[i*2],str[i*2+1]);
else
printf("%c%c%c%c",str[j*2],str[j*2+1],str[i*2],str[i*2+1]);
outchar(i*j);
printf(" ");
}
printf("\n");
}
//printf("%s",&str[5]);
while(1);
return 0;
}
void outchar(int n)
{
if(n<10)
printf("%c%c ",str[n*2],str[n*2+1]);
else
{
printf("%c%c十",str[(n/10)*2],str[(n/10)*2+1]);
printf("%c%c",str[(n%10)*2],str[(n%10)*2+1]);
}
}
输出效果:
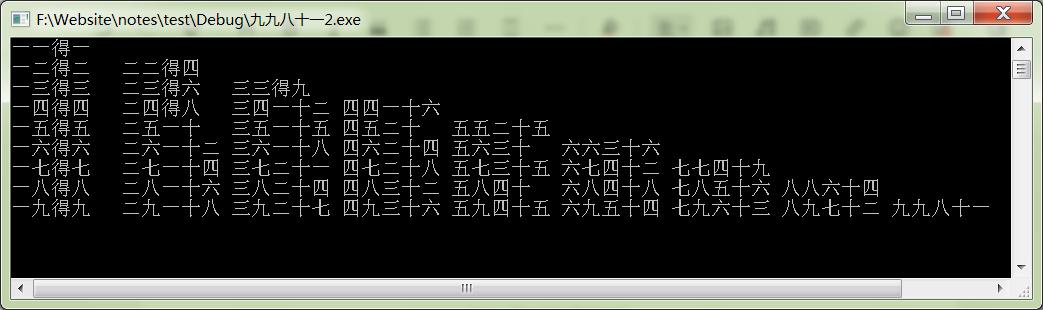
2 使用wchar_t数组输出九九乘法表
#include <stdio.h>
#include <wchar.h>
#include <locale.h>
wchar_t str[] = L" 一二三四五六七八九";
void outchar(int n);
int main()
{
setlocale(LC_ALL,"chs");
for(int i=1;i<=9;i++)
{
for(int j=1;j<=i;j++)
{
//printf("%d%d得%d\t",j,i,j*i);
if(i*j<10)
wprintf(L"%c%c得",str[j],str[i]);
else
wprintf(L"%c%c",str[j],str[i]);
outchar(i*j);
wprintf(L" ");
}
printf("\n");
}
//printf("%s",&str[5]);
while(1);
return 0;
}
void outchar(int n)
{
if(n<10)
wprintf(L"%c ",str[n]);
else
{
wprintf(L"%c十",str[(n/10)]);
wprintf(L"%c",str[(n%10)]);
if(n%10==0)
wprintf(L" ");
}
}
输出效果:
3 将有汉字的字符串存储到一个二维字符数组中
#include <stdio.h>
#include <string.h>
int main()
{
char a[] = "male男female女sex";
char b[80][3],t[3];
int i,j,n=0;
// 将字符串所有字符拆开,存储到二维数组b中,每行存一个字符(汉字)
for(i=0; a[i]!='\0'; i++)
{
if(a[i]>=0) // 非汉字的普通ASCII字符
{
b[n][0]=a[i];
b[n][1]='\0';
}
else // 汉字字符,需要保存2个连续的字符
{
b[n][0]=a[i];
b[n][1]=a[i+1];
b[n][2]='\0';
i++;
}
n++;
}
for(i = 0 ; i <n-1 ; i++)
{
for( j = i+1 ; j <=n-1 ; j++)
if(strcmp(b[i],b[j])<0) //字符串大小比较交换
{
strcpy(t,b[i]);
strcpy(b[i],b[j]);
strcpy(b[j],t);
}
}
for(i=0; i<n; i++)
printf("%s",b[i]); // 女男xsmmllfeeeeaa
while(1);
return 0;
}
-End-