今天故事的主题是
「 人类真的太多余了么?」
狗又来虐我们了。
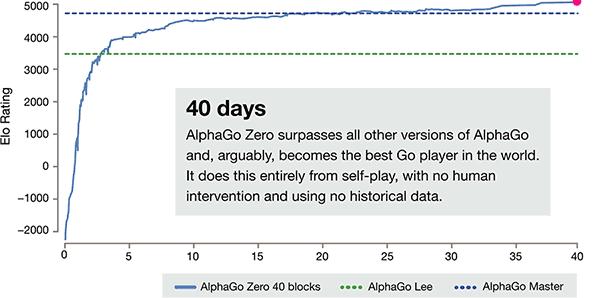
打败柯洁的AlphaGo Master退役之后,狗爸关于狗的研究并没有停止。今天凌晨,他们在《自然》杂志发表论文,说迄今最强最新的AlphaGo Zero,仅仅经过3天训练,就100比0击败了战胜李世石的AlphaGo,21天达到Master,40天碾压Master。
而且,完全自学,不借助任何人类的经验。

柯洁惊呆了,“一个纯净、纯粹自我学习的alphago是最强的...对于alphago的自我进步来讲...人类太多余了。”
整个人类都惊呆了。
1
3天完爆旧狗,21天从无知到无敌。
AlphaGo Zero的纪录是惊人的。
1天,超越人类棋手水平;
3天,在100局比赛中100:0击败了上一版本的 AlphaGo,就是打败李世石的那个;
21天,达到Master水平,就是今年5月底在乌镇打败了世界上最优秀的棋士、世界第一的柯洁的那个Master;
40天,碾压Master。
这样的速度此前从来没有过。
AlphaGo 2014年出世,到成为第一个无需让子即可在19路棋盘上击败围棋职业棋手的电脑围棋程序,用了至少1年零10个月。打败李世石,已经是2016年3月的事了。
AlphaGo Master比它厉害一点,2016年年底网络出道,一路厮杀,60战全胜。5个月后,正式在乌镇赢了柯洁。然后退役。
但AlphaGo Zero只用了21天。
2
AlphaGo Zero完全抛弃人类经验。自己跟自己下棋,每下一次都比之前更厉害。
狗爸团队DeepMind发表的论文,标题说明了一切,“不使用人类知识掌握围棋”。

之前各个版本的AlphaGo,要先跟着上千个业余及专业棋手训练,学习围棋的规则与技巧。AlphaGo Zero 完全抛弃人类经验,从随机的对弈开始,自行学习规则。而且,每下一次,都比之前的自己更厉害一点。
根据DeepMind的论文,这是因为,AlphaGo Zero利用了一种新的强化学习方式。在这个过程中,AlphaGo Zero 成为自己的老师。
这个系统从零开始,最初只是一个完全不懂围棋的神经网络。然后,将这个神经网络跟一种强大的搜索算法结合,AlphaGo Zero就能自己和自己下棋了。它自我对弈的时候,神经网络就被调整、更新,以预测下一个落子位置以及对局的最终赢家。
更新后的神经网络又与搜索算法重新组合,进而创建一个新的、更强大的 AlphaGo Zero 版本。然后,再次重复对弈的过程。
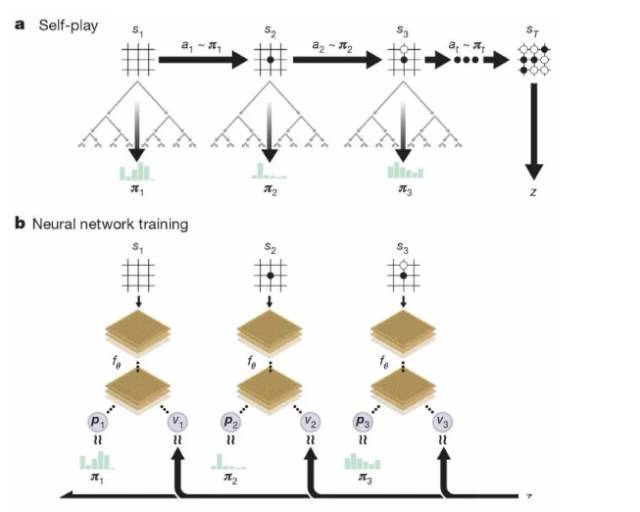
AlphaGo Zero 自我对弈训练的流程:a. 程序自己和自己下棋。b. AlphaGo Zero 中神经网络的训练。
所以,AlphaGo Zero的每一次自我对弈,就是一次迭代。每一次迭代,系统的性能都得到一次提高,自我对弈的质量也在提高。对弈,迭代,对弈,迭代……最终,神经网络的预测越来越准确,AlphaGo Zero也越来越强大。
不跟人类学习,不用站在巨人的肩膀就自己成了巨人,AlphaGo Zero也不再受限于人类知识的局限了。
甚至,从目前的结果来看,或许一直以来,是人类的智慧耽误了狗。
3
除了不向人类学习,AlphaGo Zero甚至,完全没有人类血统,没有一丁点来自人类的“基因”。也就是说,起初,它就是个完全不懂围棋的门外汉,是张婴儿般的白纸。
其实“婴儿般的白纸”这个说法并不准确,不准确在婴儿并不是白纸一张,婴儿有些与生俱来的本领。比如,偏爱高热量的食物,饿了就会哭以期得到注意。这是生物体在亿万年的演化中学来的。
但AlphaGo Zero是完完全全的白板。
它没有亿万年的演化,也没有先天的知识。此前的AlphaGo,它们的输入中,其实包含了少量人工设计的特征。但AlphaGo Zero不用,它只使用围棋棋盘上的黑子和白子作为输入。也就是说,只要告诉它棋盘,棋子和规则,它就可以自我进化。
哲学上有个著名观点,叫“白板理论”,是说婴儿生下来白板一块,通过不断训练、成长获得知识和智力。当现代科学证明婴儿并不是白板,这个理论将要被搁置的时候,AlphaGo Zero的成功,给了这个理论以实验上的可能性。

AlphaGo Zero学到的知识
4
更可怕的是,AlphaGo Zero完成这些逆天成就,只需要比前几代AlphaGo更少的运算,和更少的训练。
3天,AlphaGo Zero 就100:0赢下了李世石版的狗AlphaGo Lee,这时,它的训练数据是490万次自我对弈。而AlphaGo Lee打败李世石的时候,它已经训练了好几个月,它的训练数据已经达到3000万盘比赛。
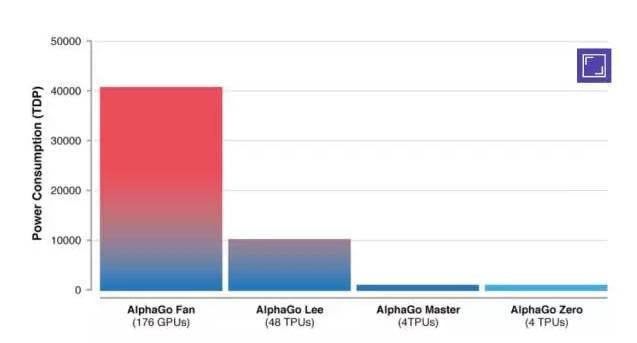
然后是装备上的碾压。
AlphaGo Zero维持运转,只用了1台机器和4个TPU,TPU是谷歌专为加速深层神经网络运算能力而研发的芯片。而李世石版AlphaGo则用了48个TPU。
5
最大的功劳属于一个高级算法。
前面说过,AlphaGo Zero利用了一种新的强化学习方式。只要将它的神经网络跟一种强大的搜索算法结合,AlphaGo Zero就能自己和自己下棋。而且,DeepMind团队还发现,这么走着走着,AlphaGo Zero居然独立发现了游戏规则,并走出了新策略。
那么,这种神经网络与高级算法,究竟是如何结合工作的呢?
首先,跟以前版本相比,AlphaGo Zero只使用一个神经网络,而不是两个。
以前版本的 AlphaGo ,使用一个“策略网络”(policy network)选择下一个落子位置,一个“价值网络”(value network)来预测游戏的赢家。而在AlphaGo Zero 中,这两个网络是联合进行的。也因此,它能够更有效地进行训练和评估。

AlphaGo Zero 和 AlphaGo Lee 的神经网络架构比较。“dual-res”和“sep-conv”分别表示在 AlphaGo Zero 和 AlphaGo Lee 中使用的神经网络架构。
算法上,AlphaGo Zero 不使用“走子演算”(rollout),也就是其他围棋程序惯常使用的快速、随机游戏,用来预测哪一方将从当前的棋局中获胜。相反,它依赖于高质量的神经网络来评估落子位置。
所有这些差异,提高了AlphaGo Zero系统的表现。但归根结底,是算法上的变化使得系统更为强大和高效。
6
AlphaGo Zero在算法上的成就意义重大。
AlphaGo项目负责人David Silver说,“人们一般认为机器学习就是大数据和海量计算,但是我们从AlphaGo Zero中发现,算法比所谓计算或数据可用性更重要。”
但这不是最重要的。
“我们希望利用这样的算法突破来帮助解决现实世界的各种紧迫问题,例如蛋白质折叠、减少能耗或新材料设计。”现在,AlphaGo Zero已经在做这方面的工作。

半年前狗赢了柯洁,DeepMind就说,他们发明AlphaGo,并不是为了赢取围棋比赛,只是想为人工智能算法搭建一个有效的平台,最终目的是把这些算法应用到真实世界中,为社会服务。
那时候,他们就已经和英国国家医疗服务体系NHS合作,利用人工智能筛查癌症,进行医学诊断。
7
David Silver说,AlphaGo Zero实际上已经消除了人类知识的限制。但人类也不是完全无用。
美国的两位棋手,在《自然》杂志上对AlphaGo Zero的棋局做了点评,“它的开局和收官和专业棋手的下法并无区别,人类几千年的智慧结晶,看起来并非全错。但是中盘看起来则非常诡异。”
在这种对比之下,人类的智慧就像一个美丽的错误,是一个偶然。机器智慧看上去真的无敌了。
人类真的没有可能了么?
中国科学院自动化研究所的王飞跃给了点不同的看法。他说,那种“看了AlphaGo Zero,就认为人类经验没用了,人工智能已经超过人类智力”的观点是不正确的。
因为,在所有“规则界定得非常清楚,而且规则中包含了所有信息”的任务中,机器或程序都应超过人类。而人工智能在应用中面临更多挑战的是那些规则不清,或者规则清楚但不包含所有信息的事情。
王飞跃说,真正智能的是AlphaGo Nothing,即人类,为定规则而生。而机器是为执行而造的。
但不可否认,机器的智慧已经可以自我进化了,人类的智慧还停留在经验积累。有人说,我们创造了神,自己却成为了狗。真的是这样么?人类的智慧可以进化么?
【END】

欢迎关注有马体育微信公众号 ID:youmatiyu