一、统计与概率论的一些概念
定义
PDF- 概率密度函数
CDF - 累积分布函数
Quantile - 分位数
Mean - 均值
Median - 中位数
Mode - 众数
Variance - 方差
Skewness - 偏度
Kurtosis - 峰度
Entropy - 信息熵
CF - Characteristic Function, 特征函数
MGF - Moment Generating Function, 矩量母函数, 也被称为动差生成函数
Erf - Error function, 误差函数
1、累积分布函数CDF(Cumulative Distribution Function)
If X is any random variable, then its CDF is defined for any real number x by
F(x)=P(X ≤ x)
2、概率密度函数PDF(Probability Density Function)
The probability density function (PDF) f(x) of a continuous distribution is defined as the derivative of the (cumulative) distribution function F(x),
ƒ(x) =dF(x)/dx
so we have

3、众数 (Mode)
它是样本观测值在频数分布表中频数最多的那一组的组中值,主要应用于大面积普查研究之中。例如:1,2,3,3,4的众数是3;例如:1,2,2,3,3,4的众数是2和3;例如:1,2,3,4,5没有众数;在高斯分布中,众数位于峰值。
4、分位数(Quantile )
分位数就是用概率作为依据将一批数据分开的那个点,是为了便于研究区间估计而挑选的对应一定概率的随机变量取值。
一天,班主任气冲冲地走进教室对我们说:“太不像话了,这次考试竟然有60%的同学不及格!” 班主任这句话里就有一个分位数的应用。
5、中位数 (Median)
中位数,又称中点数,中值。中位数是按顺序排列的一组数据中居于中间位置的数,即在这组数据中,有一半的数据比他大,有一半的数据比他小。
有一组数据:
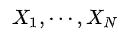
将它按从小到大的顺序排序为:

则当N为奇数时,

当N为偶数时,

6、偏度(Skewness)
对于离散随机变量:

一般化公式:

其中µ为均值或期望,σ为标准差。
可以用来度量随机变量概率分布的不对称性。是统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。偏度亦称偏态、偏态系数。它表征概率分布密度曲线相对于平均值不对称程度的特征数。直观看来就是密度函数曲线尾部的相对长度。
例如:一组数据为1、2、2、4、1,均值为2,标准差约为1.22,所以偏度为

几何意义:
偏度的取值范围为(-∞,+∞)
- 当偏度<0时,概率分布图左偏。
- 当偏度=0时,表示数据相对均匀的分布在平均值两侧,不一定是绝对的对称分布。
- 当偏度>0时,概率分布图右偏。

7、峰度
峰度被定义为四阶累积量除以二阶累积量的平方,它等于四阶中心矩除以概率分布方差的平方再减去3:

“减3”是为了让正态分布的峰度为0。
对于具有n个值的样本,样本峰度为:

在统计学中,峰度衡量实数随机变量概率分布的峰态。峰度高就意味着方差增大是由低频度的大于或小于平均值的极端差值引起的。
根据变量值的集中与分散程度,峰度一般可表现为三种形态:尖顶峰度、平顶峰度和标准峰度。当变量值的次数在众数周围分布比较集中,使次数分布曲线比正态分布曲线顶峰更为隆起尖峭,称为尖顶峰度;当变量值的次数在众数周围分布较为分散,使次数分布曲线较正态分布曲线更为平缓,称为平顶峰度。可见,尖顶峰度或平顶峰度都是相对正态分布曲线的标准峰度而言的。
8、信息熵(Entropy)
熵在信息论中代表随机变量不确定度的度量。一个离散型随机变量X的熵H(X)定义为:

其中p(xi)代表随机事件X为xi的概率。
令f(x) = log(1/p(x)), E[f(x)] = ∑p(x)f(x). H(x)可以看作f(x)的数学期望。
信息论之父克劳德·香农,总结出了信息熵的三条性质:
- 单调性,即发生概率越高的事件,其所携带的信息熵越低。极端案例就是“太阳从东方升起”,因为为确定事件,所以不携带任何信息量。从信息论的角度,认为这句话没有消除任何不确定性。f(x) = 1/p(x)是不是很容易想得到?
- 非负性,即信息熵不能为负。这个很好理解,因为负的信息,即你得知了某个信息后,却增加了不确定性是不合逻辑的。
- 累加性,即多随机事件同时发生存在的总不确定性的量度是可以表示为各事件不确定性的量度的和。
我们希望信息熵满足:
所有可能发生事件所带来的信息量的期望:E[f(x)];
概率越高,信息熵越低:f(x) = log(1/p(x));
非负性:f(x) = log(1/p(x));
如果两个事件A,B同时发生,且相互独立,有H(A,B) = H(A)+H(B)。
因此,构造了我们现在的信息熵公式。
香农从数学上,严格证明了满足上述几个个条件的随机变量不确定性度量函数具有唯一形式:

其中的C为常数,我们将其归一化为C=1, 即得到了信息熵公式。
如果两个事件不相互独立,那么满足:
H(A,B) = H(A) + H(B) - I(A, B),
其中I(A, B)是互信息,代表一个随机变量包含另一个随机变量信息量的度量,这个概念在通信中用处很大。比如一个点到点通信系统中,发送端信号为X,通过信道后,接收端接收到的信号为Y,那么信息通过信道传递的信息量就是互信息I(X,Y)。根据这个概念,香农推出了一个十分伟大的公式,香农公式,给出了临界通信传输速率的值,即信道容量:

9、特征函数 (Characteristic Function, CF)
如果F(x)是累积分布函数,那么特征函数由黎曼-斯蒂尔切斯积分给出:

如果f(x)是概率密度函数,则特征函数:

它被用于中心极限定理的最常见的证明中,还可以用来求出某个随机变量的矩。
10、动差生成函数(Moment Generating Function, MGF)
在统计学中,矩又被称为动差(Moment)。矩量母函数(Moment Generating Function,简称mgf)又被称为动差生成函数。定义为:

前提是这个期望值存在。
如果X具有连续概率密度函数f(x),则它的动差生成函数由下式给出:

其中,mi是第i个矩。

如果两个随机变量具有相同的mgf,那么它们具有相同的概率分布。
动差生成函数可用来求n阶原点矩。
只要动差生成函数在t = 0周围的开区间存在,第n阶原点矩为:

11、误差函数 (Error function, Erf)

误差函数的级数展开式为:


误差函数是特殊的不完全伽玛函数之一。
误差函数在概率论、统计学以及偏微分方程和半导体物理中都有广泛的应用。
二、正态分布(Normal Distribution)
(1)概率密度函数(PDF)

以上结果可表示为 X~N(µ, σ2), µ为均值或期望,σ为标准差。
标准正态分布(standard normal distribution)表示为N(0,1)


(2)累积分布函数 (CDF)


(3)正态分布的性质

(4)小结
卡方分布、t-分布、F分布统计学三大分布皆来自正态分布。
正态分布还有诸多迷人的数学特性,我们可以欣赏一下:

三、泊松分布(Poisson Distribution)
泊松分布,是一种统计与概率学里常见到的离散概率分布,由法国数学家西莫恩·德尼·泊松(Siméon-Denis Poisson)在1838年时发表。
泊松分布是用来描述某段时间内事件的发生概率。
(1)概率密度函数


(2)累积分布函数

(3)泊松分布的性质

(4)小结
泊松分布通常用于两个主要目的:
- 预测事件在选定时间段内将发生多少次。 该技术可用于不同的风险分析应用,例如房屋保险价格估计。
- 考虑到事件过去发生的频率,估计事件发生的可能性(例如,未来两个月停电的可能性有多大)。
许多随机变量服从泊松分布,如某医院一天内的就诊人数,一段时间内一个网站的登陆人数,某路口一段时间内通过的车辆数。
四、伯努利分布(Bernoulli Distribution)
伯努利分布是一个离散型机率分布,是N=1时二项分布的特殊情况,为纪念瑞士科学家詹姆斯·伯努利(Jacob Bernoulli 或James Bernoulli)而命名。
(1)概率密度函数


(2)累积分布函数
(3)伯努利分布的性质

五、二项分布(Binomial Distribution)
(1)概率密度函数


(2)累积分布函数

或

其中,I是正则不完全的beta函数。

(3)二项分布的性质

六、几何分布(Geometric Distribution)
(1)概率密度函数


(2)累积分布函数

(3)几何分布的性质

(4)小结
考虑一系列试验,其中每个试验只有两个可能的结果(指定的失败和成功)。假定每个试验的成功概率是相同的。在这样的试验序列中,几何分布可用于对首次成功之前的失败数量进行建模。分布给出了以下可能性:首次成功之前有0个失败,第一次成功之前有1个失败,第一次成功之前有2个失败,依此类推。
什么时候几何分布是合适的模型?如果以下假设成立,则几何分布是合适的模型。
一系列独立试验:
每次试验只有两种可能的结果,通常指定为成功或失败。
每个试验的成功概率p是相同的。
如果满足这些条件,则几何随机变量Y是首次成功之前失败次数的计数。
七、超几何分布(Hypergeometric Distribution)
(1)概率密度函数


(2)累积分布函数

(3)超几何分布性质

八、卡方分布(Chi-squared ( χ2))
卡方分布是由阿贝(Abbe)于1863年首先提出的,后来由海尔墨特(Hermert)和现代统计学的奠基人之一的卡·皮尔逊(C K.Pearson)分别于1875年和1900年推导出来,是统计学中的一个非常有用的分布。
如果 Z1, Z2 ..., Zn 是相互独立的随机变量,且都服从于 N(0,1)分布,那么随机变量X

服从自由度(degree of freedom, df)为 k 的χ2分布,记为

(1)概率密度函数PDF of χ2

这里Γ(x)代表Gamma函数。

(2)累积分布函数CDF of χ2

这里γ(v,z)为不完全Gamma函数。

(3)卡方分布的性质

(4)小结
卡方分布特点:
- 是伽玛分布的一个特例;
- 是统计学三大分布之一,是数理统计必须的知识点;
- 于检验样本是否偏离了期望;
- 可以用来测试随机变量之间是否相互独立,也可用来检测统计模型是否符合要求;
- 在分布曲线和数据拟合优度检验中是一个利器,皮尔逊的这个工作被认为是假设检验的开山之作;
九、t-分布(Student's t-distribution)
戈赛特(W.S.Gosset)发现了t-分布。他依靠自己的化学知识进酿酒厂工作,工作期间考虑酿酒配方实验中的统计学问题,酒厂虽然禁止员工发表一切与酿酒研究有关的成果,但允许他在不提到酿酒的前提下,以笔名发表t分布的发现,所以论文使用了“学生”(Student)这一笔名。之后的相关理论经由罗纳德·费雪(Sir Ronald Aylmer Fisher)发扬光大,为了感谢戈塞特的功劳,费雪将此分布命名为学生t分布(Student's t)。
戈赛特追随皮尔逊学习了一年的统计学,最终依靠自己的数学知识发现t-分布而名垂青史。1908年,戈塞特提出了正态样本中样本均值和标准差比值的分布,并给出了应用上极其重要的第一个分布表。戈塞特在t-分布的工作开创了小样本统计学的先河。
设X ~ N(0,1)和Y ~ χ2(n) ,且 X 和 Y 相互独立,则称随机变量

服从 自由度df 为 n 的 t-分布,记为 T ~ t(n)。
(1)PDF of t-distribution

其中, υ为自由度数,Γ为伽玛函数。
或

其中 υ为自由度数,B为Beta函数。
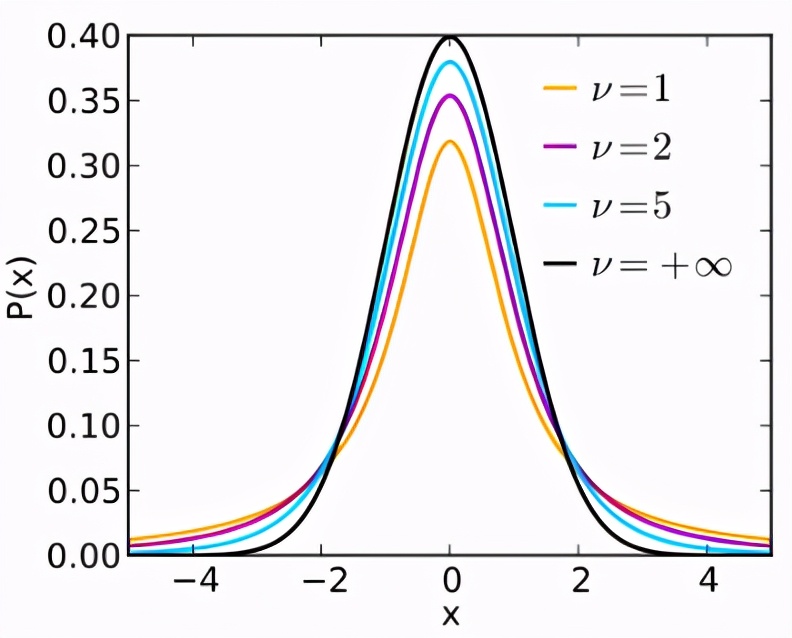
(2)CDF of t-distribution


(3)t-分布的性质

(4)小结
t-分布特点:
- 以0为中心,左右对称的单峰分布;
- 是一簇曲线,其形态变化与n(确切地说与自由度ν)大小有关。自由度ν越小,t分布曲线越低平;自由度ν越大,t分布曲线越接近标准正态分布曲线;
- 是统计学三大分布之一,是数理统计必须的知识点;
- 用于检验均值是否不同;
- 在概率统计中,在置信区间估计、显著性检验等问题的计算中发挥重要作用。
十、F-分布(F-distribution)
费希尔(R.A.Fisher), F分布就是为了纪念费希尔而用他的名字首字母命名的。费希尔统计造诣极高,受高斯的启发,系统地创立了极大似然估计法,这套理论现在在统计学参数估计中用处最广。
X 和 Y 是相互独立的χ2分布随机变量,df 分别为 d1 和 d2,则称随机变量
F =(X/d1 /(Y/d2)
服从df 为 (d1, d2)的 F-分布,且通常写为 F~F(d1,d2)。
(1)PDF of F distribution

实数x>0, B是Beta函数,d1和d2是正整数。

(2)CDF of F distribution


(3)F-分布的性质

(4)小结
F分布的特点:
- 是统计学三大分布之一,是数理统计必须的知识点。
- 用于检验方差是否不同。
卡方分布、t-分布、F分布三大分布皆来自正态分布。
假设独立随机变量

则满足三大分布的随机变量可以构造如下:

有了统计学三大分布的加持,正态分布在数理统计学独领风骚。
十一、指数分布(Exponential Distribution)
推导公式见附录1
(1)概率密度函数

其中λ>0为常数。

(2)累积分布函数


(3)指数分布的性质

(4)小结
指数分布是伽玛分布和威布尔分布的特殊情况,可以看作是威布尔分布中的形状系数等于1的特殊分布。
指数函数的一个重要特征是无记忆性(Memoryless Property,又称遗失记忆性)。这表示如果一个随机变量呈指数分布,当s,t≥0时有P(T>s+t|T>t)=P(T>s)。所谓缺乏“记忆”,是指某种产品或零件经过一段时间t0的工作后,仍然如同新的产品一样,不影响以后的工作寿命值,或者说,经过一段时间t0的工作之后,该产品的寿命分布与原来还未工作时的寿命分布相同,显然,指数分布的这种特性,与机械零件的疲劳、磨损、腐蚀、蠕变等损伤过程的实际情况是完全矛盾的,它违背了产品损伤累积和老化这一过程。所以,指数分布不能作为机械零件功能参数的分布形式,因而限制了它在机械可靠性研究中的应用。
指数分布在电子元器件的可靠性研究中,通常用于描述对发生的缺陷数或系统故障数的测量结果。这种分布表现为均值越小,分布偏斜得越厉害。在日本的工业标准和美国*用军**标准中,半导体器件的抽验方案都是采用指数分布。
十二、瑞利分布(Rayleigh Distribution)
瑞利分布(Rayleigh Distribution):当一个随机二维向量的两个分量呈独立的、均值为0,有着相同的方差的正态分布时,这个向量的模呈瑞利分布。例如,当随机复数的实部和虚部独立同分布于0均值,同方差的正态分布时,该复数的绝对值服从瑞利分布。
瑞利分布是最常见的用于描述平坦衰落信号接收包络或独立多径分量接受包络统计时变特性的一种分布类型。两个正交高斯噪声信号之和的包络服从瑞利分布。
瑞利分布是威布尔分布的一种特殊情况,也就是说,当威布尔分布的形状参数为2时,威布尔分布就是瑞利分布。
推导公式见附录2
(1)概率密度函数
如果连续型随机变量X的概率密度函数为

其中σ为尺度参数,且σ>0, 则称随机变量X服从瑞利分布。

(2)累积分布函数


(3)瑞利分布的性质

(4)小结
瑞利分布在风资源评估中的应用
风资源评估,风场选择,单位选择和容量规划应基于风资源评估的结果。瑞利分布和威布尔分布是风资源评估中使用最广泛的两个分布函数。
瑞利分布在无线通信方面的应用
在无线移动通信系统中,瑞利衰落分布常用于平坦衰落信号或独立多径分量接收中包络具备时变统计特性的衰落模型。瑞利衰落属于小尺度的衰落效应,小尺度衰落信道包络一般服从瑞利分布或莱斯分布。
瑞利衰落信道(Rayleigh fading channel)是一种无线电信号传播环境的统计模型。这种模型假设信号通过无线信道之后,其信号幅度是随机的,即“衰落”,并且其包络服从瑞利分布。这一信道模型能够描述由电离层和对流层反射的短波信道,以及建筑物密集的城市环境。瑞利衰落只适用于从发射机到接收机不存在直射信号的情况,否则应使用莱斯衰落信道作为信道模型。
基于瑞利分布的粒子滤波跟踪算法
瑞利分布(RD)在许多现实生活中都有广泛的应用,特别是寿命测试,机械构件的载荷能力方面,可靠性分析,药品等。
十三、韦伯分布(Weibull Distribution)
韦伯分布,又称威布尔分布,是可靠性分析和寿命检验的理论基础。历史来源:
- 1927年,Fréchet首先给出这一分布的定义;
- 1933年,Rosin和Rammler在研究碎末的分布时,第一次应用了该分布(Rosin, P.; Rammler, E. (1933), "The Laws Governing the Fineness of Powdered Coal", Journal of the Institute of Fuel 7: 29 - 36.);
- 1951年,瑞典工程师、数学家Waloddi Weibull详细解释了这一分布,于是,该分布便以他的名字命名为Weibull Distribution。
(1)韦伯分布是连续性的概率分布,其概率密度函数为:

其中,x是随机变量,λ>0是比例参数(scale parameter),k>0是形状参数(shape parameter)。

(2)累积分布函数


(3)韦伯分布的性质

(4)小结
威布尔分析最主要的优点:
- 提供比较准确的失效分析和小数据样本的失效预测,对出现的问题尽早地制订解决方案。
- 为单个失效模式提供简单而有用的图表,使数据在不充足时,仍易于理解。
- 描述分布状态的形状可很好地选择相应的分布。
- 提供基于威布尔概率图的斜率的物理失效的线索。
在所有可用的可靠性计算的分布当中,威布尔分布是唯一可用于工程领域的。威布尔分析广泛用于研究机械、化工、电气、电子、材料的失效,甚至人体疫病。具体应用如下:
- 工业制造
- 研究生产过程和运输时间关系。
- 极值理论
- 预测天气
- 可靠性和失效分析
- 雷达系统
- 对接受到的杂波信号的依分布建模。
- 拟合度
- 无线通信技术中,相对指数衰减频道模型,韦伯衰减模型对衰减频道建模有较好的拟合度。
- 量化寿险模型的重复索赔
- 预测技术变革
- 风速
- 由于曲线形状与现实状况很匹配,被用来描述风速的分布。
十四、帕雷托分布(Pareto Distribution)
帕雷托分布, 也称帕累托分布。以意大利经济学家 Vilfredo Pareto命名,他在1882年研究英国的财富分配情况时,发现前20%的人群拥有着社会80%的财富,这一现象可以用一个简单的概率分布函数来描述,即帕雷托分布。帕累托分布是从大量真实世界的现象中发现的幂次定律分布,这个分布在经济学以外, 也被称为布拉德福分布。
(1)概率密度函数


(2)累积概率分布


(3)帕雷托分布的性质

(4)小结
帕累托分布被广泛应用于经济学研究中。被认为大致是帕累托分布的例子有:
- 财富在个人之间的分布;
- 沙粒的大小;
- 人类住区的规模(更少的城市和更多的村庄);
- 接近绝对零度时,玻色-爱因斯坦凝聚的团簇;
- 在互联网流量中文件尺寸的分布;
- 油田储量价值(大油田少,小油田多);
- 龙卷风带来的灾难数量;
- 对维基百科条目的访问。
十五、拉普拉斯分布(Laplace Distribution)
拉普拉斯分布是由两个指数函数组成的,所以又叫做双指数函数分布(double exponential distribution)
(1)概率密度函数
设随机变量X具有密度函数

其中尺度参数b,位置参数μ为常数,且b>0,则称X服从参数为b,μ的拉普拉斯分布。

服从拉普拉斯分布的随机变量,出现极端大的值的概率,要远远大于正态分布。
(2)累积分布函数


(3)拉普拉斯分布

(4)小结
拉普拉斯分布是比较常见的概率统计模型,它在生活中很多专业领域都有广泛的应用。如拉普拉斯分布在证券金融经济领域有着重要的作用。在工程中,对于测绘数据的处理以及在语音和图像数据等领域上也有着广泛的应用。
过去人们研究证券市场收益率的分布时大都假设其服从正态分布,后来发现此假设的缺点越来越明显——无法满足尖峰厚尾非正态的分布特性,而且根本就不能通过统计检验.出于上述考虑,引入拉普拉斯分布,比较成功地解决了这些问题,并且发现该类分布在证券市场上具有很大的应用前景。
拟合优度检验是统计学应用中的一个常见的问题,即检验来自总体中数据其分布是否与某种理论分布相一致的统计方法。一般情况下,先根据问题的实际情况、观测的样本数据以及抽样方法,猜测数据可能的理论分布,然后利用样本数据进一步检验这个猜测的模型。
十六、逻辑斯蒂分布(Logistic Distribution)
(1)概率密度函数

其中μ为均值参数,s>0为尺度参数。

(2)累积分布函数

其中μ为均值参数,s>0为尺度参数。

(3)逻辑斯蒂分布

十七、柯西分布(Cauchy Distribution)
柯西分布也叫作柯西一洛伦兹分布,它是以奥古斯丁-路易-柯西与亨德里克-洛伦兹名字命名的连续概率分布。
柯西分布是一个数学期望不存在的连续型概率分布。
(1)概率密度函数

其中,x0定义分布峰值位置的位置参数;γ为最大值一半处的一半宽度的尺度参数。
如果x0=0, γ=1, 则为标准柯西分布:


(2)累积分布函数


(3)柯西分布性质

十八、贝塔分布(Beta Distribution)
贝塔分布(Beta Distribution) 是一个作为伯努利分布和二项式分布的共轭先验分布的概率函数,在机器学习和数理统计学中有重要应用。在概率论中,贝塔分布,也称Βeta分布,是指一组定义在(0,1) 区间的连续概率分布。
推导公式见附录3
(1)概率密度函数

其中Γ(x)代表Gamma函数,参数α>0, β>0, B(α,β)是Beta函数。

(2)累积分布函数


其中B(x;a,b)是不完全Beta函数。Ix(α,β)是正则不完全贝塔函数。
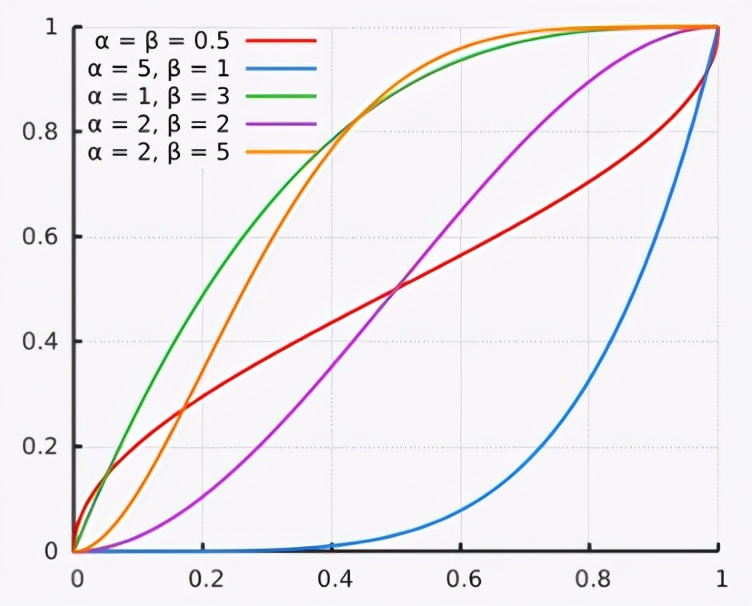
(3)Beta分布的性质

十九、附录
附录1 指数分布的推导
设某电子元件使用时间超过x的概率为P(X>x)。元件在x和x+h时间段内失效的概率为 P(x≤X≤x+h)。假设元件已经使用了 x时长了, 那么,元件在x和x+h时间段内失效应等于条件概率:

用上面的条件概率除以h, 也就得到了h时段的平均失效率:

当h--->0时,上式当元件已经使用了X时长,元件在下一时刻的失效概率恒为λ

设B事件为 X>x, A事件为x≤X≤x+h,有条件概率公式:

则有

设F(x) = P(X≤x), 有

得到微分方程:

可以转化为:

是一个具有常数系数和常数项的一阶微分方程。
有通解公式:

这就是指数分布的分布函数,求导即得到概率密度函数:

推导完毕。
附录2 瑞利分布的推导
定理1 若 随机变 量 X与Y相互 独立 , 又 f( x) 、 g (x ) 是两个连 续函 数 , 则随机 变量 f (X)如与 g (Y)相互独立 。
定理2 随机变量X的概率密度函数为Ψ(x), 则随机变量Y=X2的概率密度函数为

定理3 若 随机变 量 X与Y相互独立 , 且其概率密度函数分别为Φ(x)、θ(y)。
则随机变量Z=X+Y的概率密度函数为

定理4 设X是一个连续型随机变量 , 其概率密度函数为Ψ(x), 由函数y=f(x)严格单调,其反函数h(y)有连续导数,随机变量Y=f(X)也是一个连续型随机变量,其概率密度函数为

其中α = min{f(-∞), f(+∞)}, β = max{f(-∞), f(+∞)}
设两个随机变量ζ与η相互独立且它们均服从正态分布N(0,σ2) , 则随机变量

服从瑞利分布

其中σ为常数,且σ>0。
推导如下:
由定理1、2, 可得X=ζ2 和 Y=η2 相互独立,其概率密度函数分别为


由定理3随机变量Z=X+Y的概率密度函数为

故Z=X+Y的概率密度函数为

由定理4可得随机变量

的概率分布服从瑞利分布:

推导完毕。
附录3 Beta分布的推导
在贝叶斯公式中,离散随机变量的后验概率可以由先验概率和条件概率得到

在已经知道参数先验分布信息与样本信息的情况下,我们可以应用贝叶斯公式得到参数的连续随机变量的后验分布信息。

这里,θ表示需要估计的未知参数,x表示样本信息,π ( θ )表示θ 的先验密度函数,L ( x | θ ) 表示x 关于θ 的条件密度函数,Θ 表示参数θ 的取值空间。
已知样本信息x,需要选择合适的参数θ使发生样本所代表事件的概率最大,所以L ( x | θ ) 在这里是一个似然函数。
假设随机变量X服从二项分布B ( n , θ ) ,那么似然函数:

如果我们对参数θ一无所知,那么对θ的先验分布π ( θ ) ,可以做θ~U ( 0 , 1 )均匀分布的假设,我们称之为贝叶斯假设:

由以上似然函数和参数的先验分布可以得出参数的后验分布:

令x=θ,α = x + 1,β = n − x + 1,可以得到Beta分布的概率密度函数:

推导完成。
二十、参考文献
[1] Hurst, Simon. The Characteristic Function of the Student tDistribution, Financial Mathematics Research Report No. FMRR006-95, Statistics Research Report No. SRR044-95 Archived February 18, 2010, at the Wayback Machine.
[2] Johnson, Norman Lloyd; Samuel Kotz; N. Balakrishnan (1995). Continuous Univariate Distributions, Volume 2 (Second Edition, Section 27). Wiley. [1] ISBN 0-471-58494-0.
[3] Abramowitz, Milton; Stegun, Irene Ann, eds. (1983) [June 1964]. "Chapter 26". Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables. Applied Mathematics Series. 55 (Ninth reprint with additional corrections of tenth original printing with corrections (December 1972); first ed.). Washington D.C.; New York: United States Department of Commerce, National Bureau of Standards; Dover Publications. p. 946. ISBN 978-0-486-61272-0. LCCN 64-60036. MR 0167642. LCCN 65-12253.
[4] Lazo, A.V.; Rathie, P. (1978). "On the entropy of continuous probability distributions". IEEE Transactions on Information Theory. IEEE. 24 (1): 120–122.[1] doi:10.1109/tit.1978.1055832.
[5] en.wikipedia.org/wiki/Beta_distribution