你是否有过,流批技术栈不统一的抓狂?
你是否有过,流批数据对不上的烦恼?
你是否有过,海量数据update时效性跟不上的无奈? ...
有最新的数据湖Iceberg技术,一切都迎刃而解!
接下来,以新闻业务为例,分享下如何基于Iceberg进行流批一体业务落地
作者:Jason峰爵
发表时间:2021-03-17 12:07
一、背景
众所周知,在数据领域,根据业务场景对数据时效性的要求不同,数据可以划分为:离线数据和实时数据两大类型。针对不同的数据类型,数据接入、数据处理、数据存储以及数据输出等各个环节的技术栈各不相同。从而导致目前基于不同技术栈构建的数仓架构也大相径庭。目前市面上最流行的两大数仓架构:Lambda与Kappa架构
Lambda架构:流批分离模式
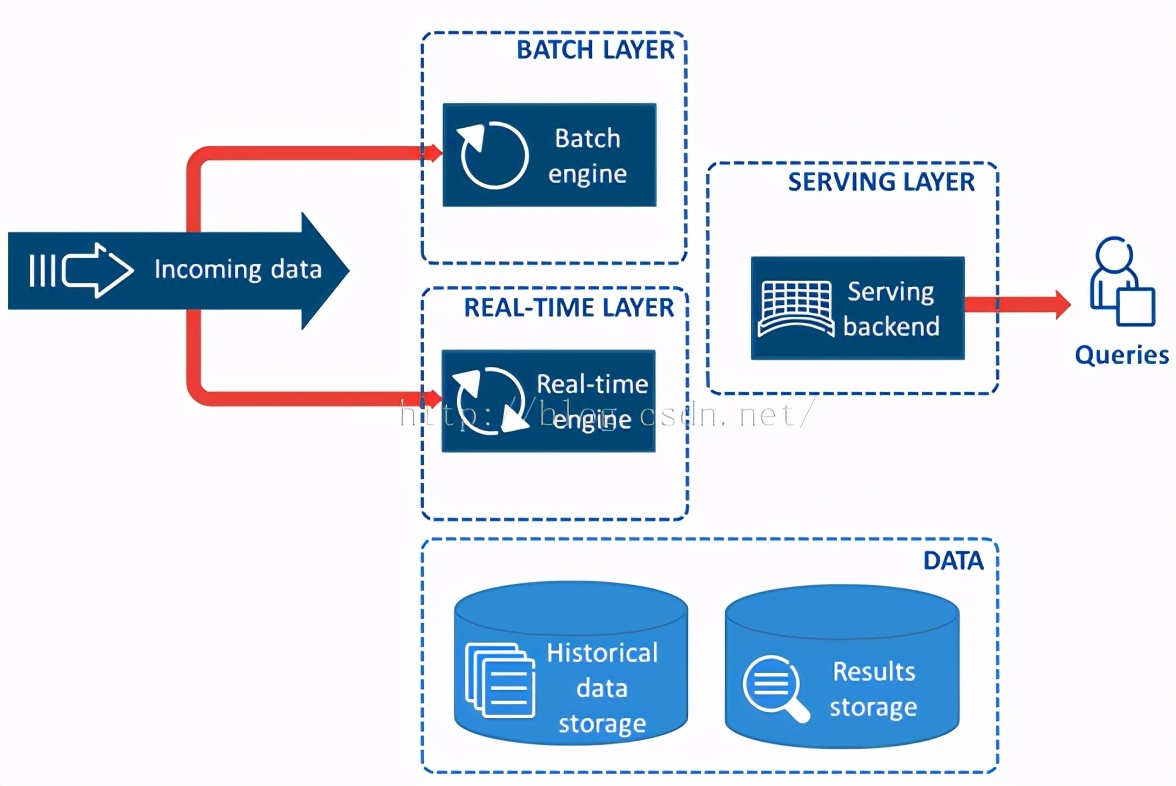
Kappa架构:批转流模式

两种架构比较
|
对比项 |
Lambda |
Kappa |
结论 |
|
数据源类型 |
支持流批数据 |
支持流数据 |
kappa对数据源的限制较大 |
|
存储成本 |
流批 独立存储 |
流存储 |
存储分离,无法统一 |
|
计算成本 |
同时运行两套作业 |
同时运行一套作业,回放时多套 |
lambda较大,kappa较小 |
|
数据一致性 |
流批分离,易偏差 |
流批一体,天然吻合 |
kappa架构后期对账成本较小 |
|
数据时效性 |
数据upsert时效性较低,不支持实时、准实时 |
同lambda |
|
|
数据输出方式 |
条件检索、批load、流消费 |
条件检索、流消费 |
|
|
开发成本 |
两套技术栈和代码 |
一套代码和技术栈 |
|
|
运维成本 |
运维两套系统 |
一套,回放时多套 |
|
|
历史回溯成本 |
支持大规模历史回溯 |
仅支持小规模数据回溯 |
总结:
对比发现,现行的lambda和kappa两种数仓架构在多个维度各有利弊。
但是,都有一个致命的缺点就是 由于流批数据的存储的不统一,导致后续的数据链路割裂,进而导致无论是数据接入、数据处理以及数据输出等各个环节的成本骤然升高。
同时,对于海量数据的upsert时效性都难以保证。
二、新闻实战业务
当前业务场景
在新闻业务中,文章是最核心的资源,包括图文、视频等。那么,精准的管理新闻中每一篇文章的完整生命周期中的每一个环节,无论是对文章作者通知反馈、还是对于平台运营团队的全局分析、乃至后台算法的持续优化迭代等等都是至关重要。
那么,在新闻的文章管理中,我们遇到了哪些问题呢?
遇到的问题
数据量级
数据量级庞大,字段丰富
- 新闻的文章数据基数庞大,千亿级
- 新闻的 文章 各环节维度众多,多达几百个以上
- 多维度导致的各个生命周期环节的 数据量 线性膨胀,单环多达 日均30-50亿
数据源类型
包括 复杂多变的多种数据输入类型
- 全量数据(静态分区表、离线文件)
- 准实时增量
- 消息流
数据使用方式
下游使用场景多样化,对数据处理和输出方式以及时效性也要求多样化
- 流式消费
- 批加载
- on-hoc条件检索
- 准实时update
- md多维分析
|
序号 |
dataflow |
数据类型 |
数据时效性 |
技术栈 |
业务场景 |
|
1 |
数据采集 |
文件、流、批 |
准实时、离线 |
flink、spark |
数据上报包括:实时流式、准实时批、离线文件 |
|
2 |
清洗、融合 |
流 |
准实时 |
flink、spark |
准实时数据清洗与融合 |
|
3 |
存储&更新 |
流、批 |
准实时、离线 |
flink、spark |
准实时 saveOrupdate、离线save |
|
4 |
数据消费 |
批、流 |
准实时 |
presto、spark、flink |
流式消费、准实时数据检索、条件batch load |
|
5 |
多维分析与报表 |
批 |
准实时、离线 |
presto、spark、hive、impala |
准实时多维分析、离线报表 |
总结:海量数据,数据源多元化、数据使用多元化、时效性要求较高、流批兼顾
三、最终解决方案
技术选型分析
针对当前业务场景的 特性要求1、海量数据,持续增加2、数据类型:流、批兼顾3、操作类型:append、upsert、del、load、on-hoc query、md analysis等4、数据时效性(实时、准实时、离线)
可以看出,基于传统存储方案的lamda和kappa架构 都无法独立优雅、低成本的满足此类【流批兼具】的场景需求。
那么我们该怎么办呢?真实的业务场景需求永远是推动技术革新的原动力。
为了解决传统数据存储中存在的这些问题,大数据开源领域在存储层表格式方面萌发了三种流批一体解决方案, Apache Iceberg, Delta Lake, Apache Hudi。这三个项目有着较多的共同点,首先, 它们都提供了ACID事务语义,其次,它们都支持版本控制和时间旅行,再者,这三个项目都支持Schema Evolution,最后, 通过这些表格式,计算引擎可以方便的实现表的更新,删除等操作。
我们为什么选择了Iceberg
- Apache Iceberg是由NetFlix最先主导开发的一个表格式,和Data Bricks的Delta Lake相比,Iceberg有更好的开放性。
- Iceberg 支持更多的底层文件格式,包括了Parquet, Orc, Avro, 而Data Bricks 的Delta Lake支持的文件格式只有Parquet 一种
- Iceberg支持更多的计算引擎,目前Iceberg文件格式支持的计算引擎有Spark, Presto, Pig, 目前社区正在做Flink的集成,而Delta Lake由于DB公司的强控制,目前只支持Spark 一种引擎,未来支持更多计算引擎的可能性也比较小。而对比Apache Hudi, Iceberg是基于底层对象存储的假设做的设计,Hudi是基于底层HDFS存储做的设计,这两者各有优劣
- Iceberg不仅支持Java API 还支持Python API。
|
特性 |
iceberg |
hudi |
Delta |
|
文件格式 |
多元化,Parquet, Orc, Avro |
/ |
Parquet |
|
设计思想 |
元数据驱动,动态更新 |
基于hdfs |
/ |
|
计算引擎 |
多元化兼容,Spark、flink、Presto、Pig |
/ |
Spark |
|
上层api |
多元化,多语言 |
/ |
/ |
详细对比:见参考文献
So,考虑到后续业务变动带来的表更新频率,业务存储媒介的多元化,项目本身的开放程度以及架构特点,2020年10月份,我们最终决定采用基于数据湖Iceberg技术的流批一体 数仓建设方案来承载新闻文章业务分析
业务目标
旨在 完成 新闻文章 全生命周期的管理,包括:图文和视频文章核心生命周期包含以下环节:1、文章素材收集2、文章编辑与创建3、文章审核与标签化4、文章索引化(索引创建、索引上报、索引load)5、文章分发与推荐6、...
下面 以 文章索引化 环节为例,来重点介绍iceberg落地方案
整体设计
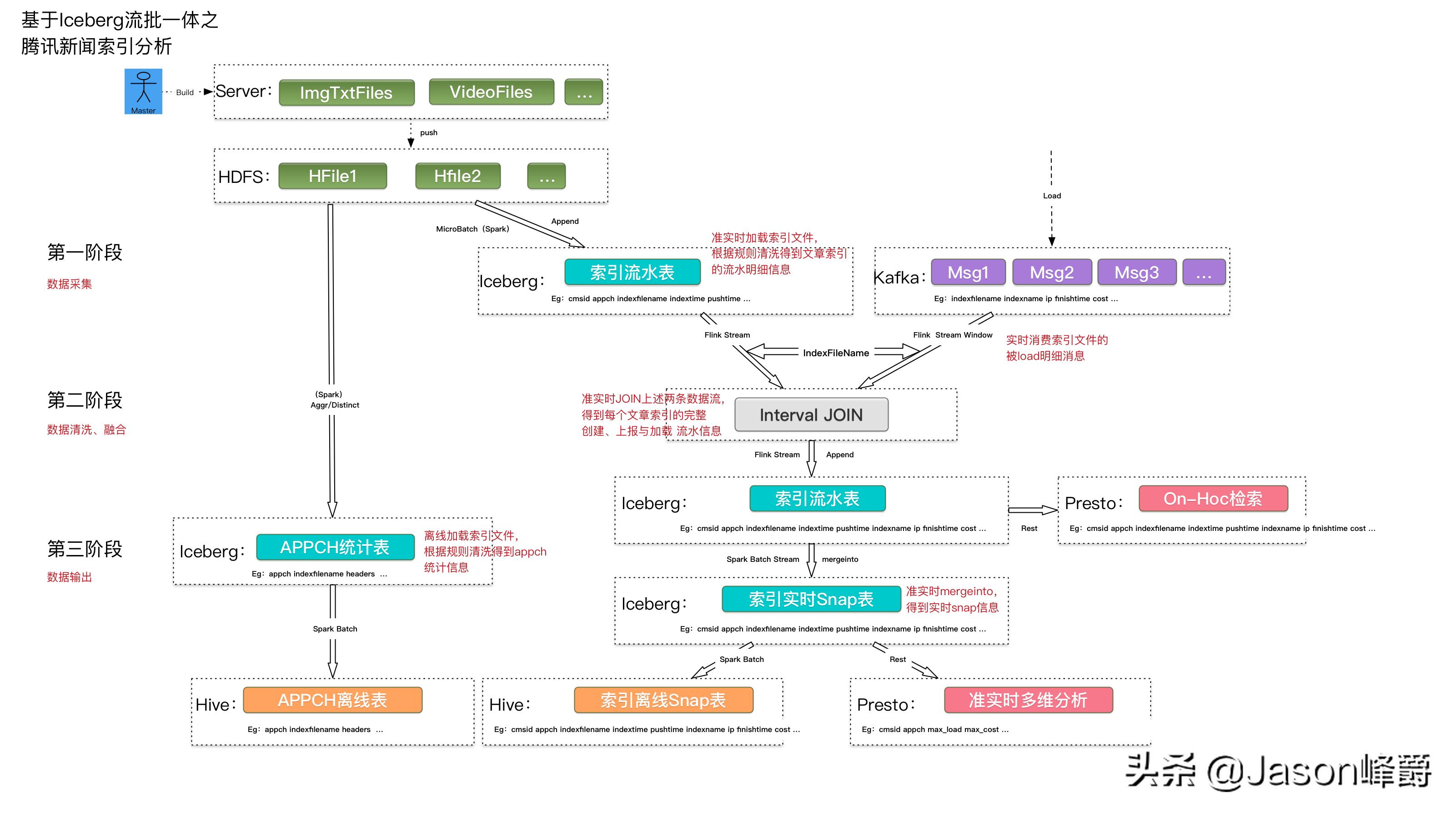
详细设计
- 准实时流水明细当前上游文章索引明细数据是基于H离线文件和准实时增量两种输出方式,后期迭代可能会演进成直接以streaming方式。So,为了兼容后期的技术演进,减少改造成本,我们采用spark filestream方式,【准实时】监控hdfs 索引文件,按照既定append方式,【mico批】 落地iceberg 流水分区表
- 实时流式消费在索引创建和加载完成后,为了能尽可能的提高 流水数据对下游的可见性,采用flink stream方式,【实时流式消费】iceberg流水表,进行多流JOIN后,按照既定append方式,【批】 落地iceberg 流水分区表
- 实时流式mergeinto基于部分下游对数据的时效性要求较高,例如,索引监控等,我们采用了流式消费+mergeinto方式 来加快数据在iceberg流水表和实时snap表中的流转。采用spark stream方式,【实时流式消费】iceberg流水表,与iceberg实时snap表 JOIN后,按照不同operation(append,update、delete)方式,【批】 落地iceberg 实时snap分区表
- on-hoc数据检索与多维分析无论是千亿iceberg流水表还是亿级snap表,都可以结合presto进行on-hoc查询和md数据分析当前采用presto 分布式引擎,【on-hoc】查询iceberg流水和snap表
- 离线统计为了兼容已有的传统hive离线数仓,满足部分数据使用需求,采用spark sql方式,【离线批】load Iceberg 实时snap表,进行相关aggr后,写入hive 分区表
四、落地成果
根据线上的实际运行结果来看,基于iceberg的数仓建设已经取得了里程碑的成功。
数据输出结果
目前已经接入全量文章的【索引】数据,并稳定输出1、完整历史流水数据,包含:过百基础属性、指标字段2、最新索引snap数据,即:准实时upsert得到的snap全量数据3、各细分粒度的上卷统计分析数据...
数据量级
目前线上 全量文章的【索引】数据,大致如下1、图文索引日均:5-15E/35G最*b大**atch:2000万当前单表:500亿(持续增长)
2、视频索引日均:10-30E/50G最*b大**atch:900万当前单表:千亿(持续增长)...
性能与时延
对于iceberg来说,无论数据流/批写入,还是数据的流批消费,最底层都是依赖于datafile。So,datafile的【合理性】、以及【hdfs读写性能】与【并发度】就是影响其性能的关键指标。最终决定Iceberg性能的就是当前操作的表中 【目标datafile数量是否过多】、【filesize是否合理】、【计算资源是否充足】、【并发度是否合理】、【hdfs是否稳定】等指标。
|
操作类型 |
数据量级 |
耗时 |
时延 |
计算资源配额 |
|
数据写入 |
千万级 |
< 亚秒级 |
2核~2G~10 executor |
|
|
数据更新 |
百万级- >千万级 |
< 亚秒级 |
2核~2G~10 executor |
|
|
数据消费 |
百万级 |
< 亚秒级 |
2核~2G~10 executor |
|
|
数据检索 |
百亿级 |
亚秒级(目前瓶颈hdfs) |
五、问题治理与源码优化
虽然结果是令人值得高兴的,但是在实际的iceberg数仓构建过程中,我们仍旧需要注意一些核心的问题!
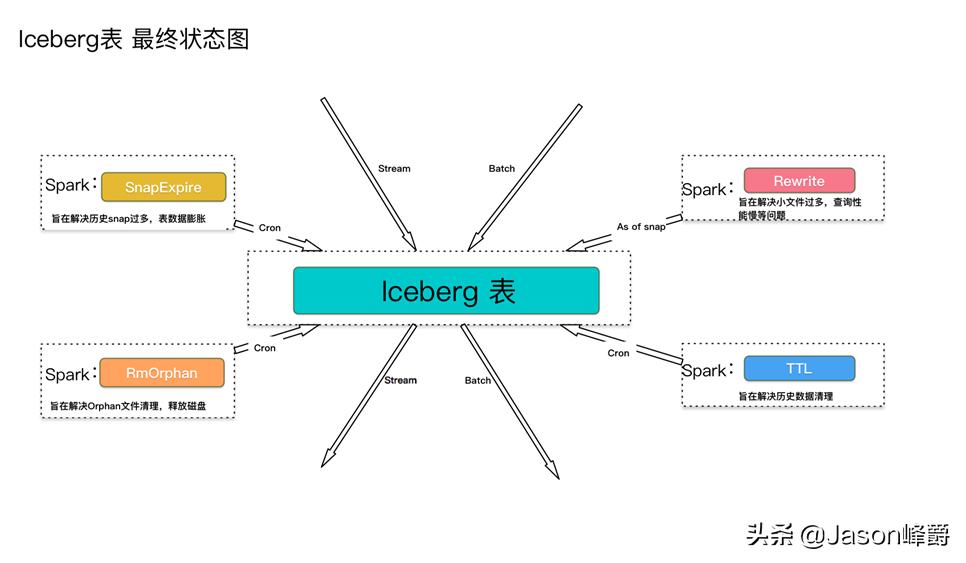
(一)小文件过度膨胀 Icberg表,每次commit提交时,最终数据以datafile文件形式落地成snapshot,单个snapshot的文件数由 作业output并发度与表分区决定。在流式或者微批场景下,commit较频繁,会导致当前表的总datafile数量急速膨胀,从而产生雪崩效应,间接影响后续数据链路的稳定性与查询性能,最终导致可用性大大降低。

So,我们需要进行同步小文件的优化,主要分为以下方法:1、降低commit频次,满足业务时效性要求即可2、降低output并发度与表分区,保持单个分区数据量级在 XXX 范围3、开启rewrite操作
- . 根据当前表数据分布,配置合理的filter
- . 根据当前hdfs blockSize & iceberg表splitsize 合理配置targetSizeInBytes
- . 根据适当控制rewrite频次,防止过多消耗资源
代码样例:
System.out.println("START TO REWRITE FROM {" + start.getTime() + "} TO {" + end.getTime() + "}");
Actions.forTable(table)
.rewriteDataFiles()
.filter(Expressions.greaterThan("ftime", start.getTimeInMillis() * 1000))
.filter(Expressions.lessThan("ftime", end.getTimeInMillis() * 1000))
.targetSizeInBytes(targetSizeInBytes)
*ex.e**cute();
table.refresh();
(二)历史snap过多,导致数据膨胀 频繁的rewrite产生的snap、会导致iceberg表实际磁盘存储占用急速膨胀,需要根据实际业务场景进行历史snap的expire工作。当前社区spark api的retainlat和oldThan两种策略结果与预期在一定的差异,且是单并发,性能不是很好,多并发版本,见:news-spark-sdk-1.0-SNAPSHOT.jar
代码样例:
int maxSize = getMaxParallelSize();
ActionsWithParallel.forTable(table)
.expireSnapshotsWithParallel()
.retainLast(config.getIntKValue(RETAIN_SNAP_NUMS))
.expireOlderThan(end)
*ex.e**cute(maxSize, 10000);
(三)orphan files过多 在日常iceberg表的使用过程中,会由于各种原因,导致很多orphan 垃圾文件,导致无效的磁盘占用,如:snap expire未完成、多端写入时由于锁竞争导致、rewrite commit失败导致等等,所以我们需要定时进行表清理。当前社区的文件收集和删除都是单并发,多并发版本见:news-spark-sdk-1.0-SNAPSHOT.jar
代码样例:
int maxSize = getMaxParallelSize();
System.out.println("start to removeOrphanFile before " + today + ", " + end);
ActionsWithParallel.forTable(table)
.removeOrphanFilesWithParallel()
.olderThan(end) // 谨慎操作,避免误删当前写入还未成功commit的datafile
*ex.e**cute(maxSize, 10000);

(四)历史数据过多,如何TTL?
- 行级 删除
第一步
delete from * where filter...
第二步
snap expire,参看上文
- 文件级 删除 to be checked...
总结:
Iceberg表的核心就是datafile,datafile的合理性决定了所有基于iceberg表的数据环节的稳定性与性能。
So,我们需要重点针对iceberg表的datafile等文件,启动对应的"补丁"作业,来保证datafile在可预期范围。
**补丁分为:同步方式、异步方式**
- 同步方式:即在iceberg的数据写入的同时运行,优点是可以保证即时的补丁效果,缺点是对于正常的读写主线逻辑有一定的干扰,资源不可控,当前不是很稳定。
- 异步方式:即单独启动异步的spark作业对iceberg表进行操作,与主线读写完全分离,资源可控,频率可控,稳定性较好。
六、日常维护
分区优化
iceberg作为大数据的存储媒介,在生产环节中,分区设计必不可少。根据iceberg的核心原理,分区是影响小文件数量的关键因素,参看【问题1】。继而间接的影响整个iceberg表的稳定性以及读写性能。甚至于对我们的日常数据维护也起到息息相关的作用。假如线上业务或者数据变化,需要进行表分区调整的,可以通过spark api进行针对性的优化
代码样例:
Configuration configuration = new Configuration();
configuration.set("hive.metastore.uris", "XXXX");
HiveCatalog catalog = new HiveCatalog(configuration);
TableIdentifier identifier = TableIdentifier.of(srcDB, srcTable);
Table table = catalog.loadTable(identifier);
BaseTable baseTable = (BaseTable) table;
TableMetadata current = baseTable.operations().current();
PartitionSpec newSpec = PartitionSpec.builderFor(table.schema())
.bucket(config.getKValue(BUCKETS), Integer.parseInt(config.getKValue(BUCKETS_NUM)))
.day(config.getKValue(DAYS))
.withSpecId(current.spec().specId() + 1)
.build();
baseTable.operations().commit(current, current.updatePartitionSpec(newSpec));
table.refresh();
基础操作
见官网文档
七、大规模数仓建设反思
基于近三个月余的实际落地情况,不由得引人深思,假如我们要基于iceberg来替换传统的离线和实时数仓技术栈,我们还欠缺哪些事情,又会有哪些风险呢?主要从以下几个维度来与传统的数仓技术进行简单比对
- (一)、可用性 通过当前千亿级数据落地实践,不管是数据的准实时写入更新,还是亚秒级查询以及批量load这些基础功能,还是其事务、隐藏分区、时光机等高级特性,都完全可以满足需求 流批场景的大部分需求。不过,由于其基于文件的核心设计理念,导致其在时效性上暂时还无法做到完全实时。实际应用过程中,时效性要求越高,成本就会相应的越高。
- (二)、易用性 在实际的落地过程中,无论表维护(DDL\DML等)、读写api,都比较通俗易上手,就是数据治理过程可能有点复杂,在后续迭代过程中,可以进一步的封装,实现自动化的例行数据治理。
- (三)、稳定性 由于iceberg只是一种基于已有metastore服务的数据结构,所以其核心的稳定性都依赖于metastore以及底层存储媒介的稳定,所以目前上线3月余未出现其本身的大数据故障事故
- (四)、落地成本 由于处于摸索阶段,暂时性学习成本会稍高一点相对比,目前市场比较成熟的消息队列和离线数仓技术,如果对时效性要求比较高的场景下,iceberg单表的各项成本还是略高,需要借助外部的计算平台资源进行各种补丁辅助工作
八、FAQ
(一)iceberg区
- 写入时,明明存在 A 字段,为啥报 A 字段不存在呢?iceberg表 默认schema大小写敏感,操作时注意配置 spark.sql.caseSensitive=false
- iceberg表dml语句,支持新增字段指定位置或者移动嘛?默认不支持after等插入列,也不支持change移动列
- mergeinto 性能较差,莫名其妙多了一个aggr操作,是什么原因?默认开启write.merge.cardinality.check.enabled,严重消耗性能非必要情况下,可以关闭设置表属性alter table newsapp_data_lake.t_newsapp_dmd_img_txt_parsed_streaming_snapshot set tblproperties ("write.merge.cardinality-check.enabled"="false");
- 监控告警 iceberg单表存储超标,几十P数据?别慌,看看是不是忘记开启 snap expire和remove orphan "补丁",各个目录实际文件数,orphan文件数一目了然,世界都清净了~

(二)spark区
- spark df中的schema 范围不能比iceberg表的列范围大
- spark 批写入时(非fanout),报closed partition错误?需要根据当前表分区,自定义分区udf,开启 sort
- spark iceberg save时,单次commit datafile数量过多?默认按照df的partion粒度进行commit,需要先进行repartion保证跟iceberg的分区一致
- 通过spark sql建的表,然后写入一个timestamp,为啥读取出来后少了8小时?timestamp日期类型字段默认带时区,timestamptziceberg默认是 utc时区,可以用spark api进行ddl
- 通过spark sql删除表数据时,为什么报错?必须带着where条件delete from 111.111 where true;
(三)presto区
- 明明才几Billion数据,为啥查询十几分钟甚至超时失败呢?莫慌,先查看iceberg表的files metadata表,确认当前表是不是小文件超标,
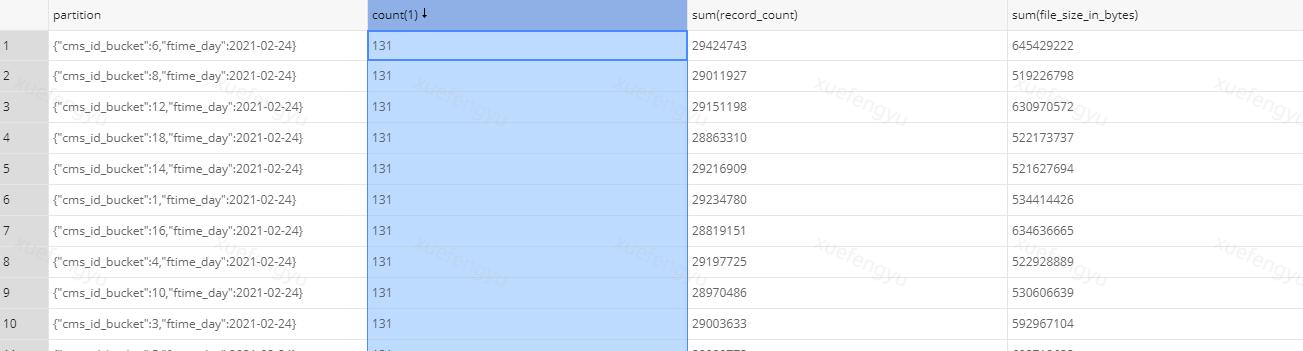
如果不是,再去查看presto的执行计划,看看是否是部分dn倾斜,压力不稳定
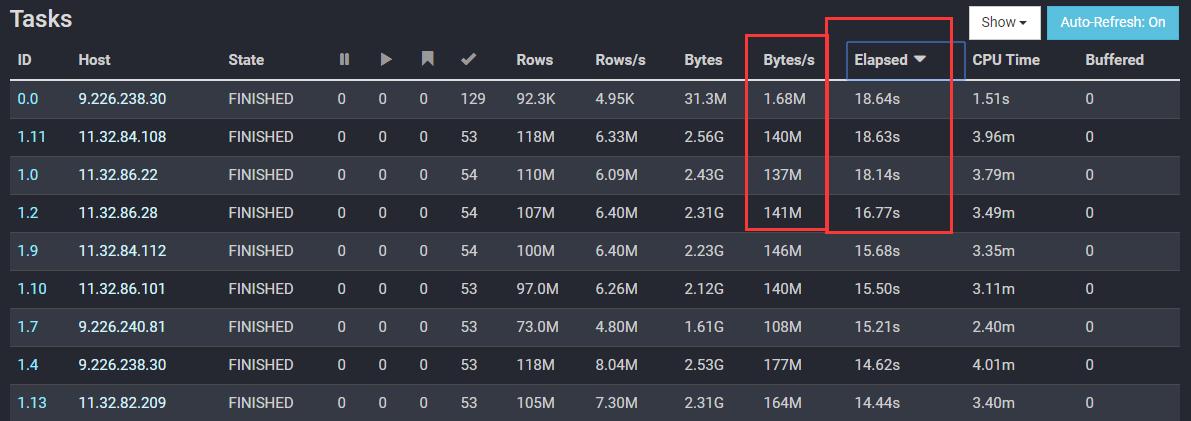
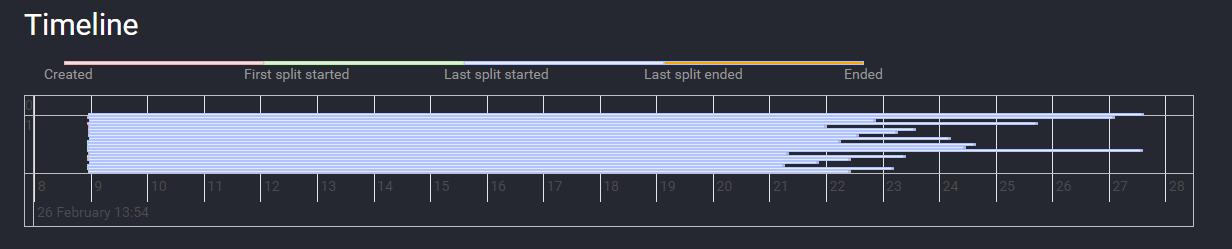
总结
1、目前此文档旨在 探索iceberg的实际应用场景,并不代表iceberg的全部特性
2、目前千亿级别数据量级,iceberg在离线和准实时领域皆可满足需求。准实时场景中,端端数据可见性最高可达 亚秒至分钟 级别
3、目前iceberg的小文件问题始终是重中之重,也是痛中之痛,要特别注意!建议分配常驻计算资源来运行,以免由于资源竞争导致线上雪崩事故
4、目前在iceberg流式消费特性上,只是简单当做消息中间件来使用,对于upsert操作的数据尚未涉及
5、在实战业务中,使用的说presto作为iceberg的查询引擎,由于各层组件的不稳定性,导致最终的效果不是很稳定,如果想以iceberg+presto做olap分析,还是建议多注意底层组件的稳定性,例如:hdfs集群的压力,presto的集群规模等
6、目前已iceberg来替换hive或者消息队列组件,进行大规模的数仓建设,成本和稳定性还有待进一步验证
参考:
http://iceberg.apache.org
https://prestodb.io/
https://blog.csdn.net/post_yuan/article/details/52241252
https://blog.csdn.net/wypblog/article/details/104744513
To be continued
后续,给大家带来一些iceberg的高级特性与底层原理
Iceberg 小文件是如何膨胀的?
Iceberg 底层数据存取与传统数仓工具 有何差异?
Iceberg 不同版本特性的对外组件兼容性等
...