【中国科大新创校友基金会(ID:USTCIF),全球最活跃的科大校友组织,实时发布科大要闻与校友资讯】
以下文章来源:小王随笔
按:这是微信公号《小王随笔》关于AlphaFold的批评观点的汇编之作,颇见功力。作者王宗安,中国科学技术大学0808/0803校友,芝加哥大学博士。
前言:
没有批评,则赞扬没有意义。
Critical acclaim is to not adulate but appreciate.
一月中旬(2022.1.11),Nature Methods 发布了年度方法专刊,将蛋白质结构预测(protein structure prediction)评为2021年的年度科技方法——这是15年来计算方法第一次被评为年度 Nature Method。
Nature Methods 编辑部给出了2条“蛋白质结构预测”当选年度方法的理由 [1]:
以 AlphaFold2 和 RoseTTAFold 作为代表,基于深度学习算法的高精度蛋白质结构预测令计算结果接近甚至达到实验解析的结构精度;
DeepMind 公司与欧洲分子生物学实验室(EMBL)下属的欧洲生物信息学研究所(EBI)合作,利用 AlphaFold2,预测并公布了人类全蛋白质组和另外20种模式生物的全蛋白质组的结构,总数多达35万个,并且其预计在2022年将完成1.3亿条蛋白质序列的结构预测。
专刊共发表了5篇评论,分别是 AlphaFold 和 RoseTTAFold 的作者对各自工作的简述和评价,计算化学家的审视和批评,生物信息学家的展望,以及结构生物学家的期待。
小王读完这5篇评论后认为最有意思的是第3篇:<The impart of AlphaFold2 one year on> [1]。这一篇包含了对 AlphaFold2 的诸多批评(不是贬义的批驳,而是批判性的评论),或许可以为时下高涨的蛋白计算产业热情提供一些冷静,稍稍按下狂欢的鼓点。
这里,小王汇编这篇文章以及相关文献和社交网络素材,将一些值得思考的观点分享给大家。
这篇评论的作者是:
伦敦大学学院计算生物学教授 David T. Jones
EMBL-EBI 荣休主任 Janet M. Thornton

两位教授:Jones(左),Thornton(右)
批评一:工程化的极限 VS 革命性的创新
作者凝练地概括了 AlphaFold2 算法的核心:基于“注意力”(attention)概念的一系列相关联的变换神经网络(transformer neural network)。
自注意力机制(self-attention)的变换神经网络非常强大,因为它不仅考虑输入队列中相邻近的元素,而将任何一对元素的关系都考虑在内。这种全局观对 AlphaFold2 而言就是通判地考虑序列与三维结构的关系。
主流观点认为,AlphaFold2 在算法架构上有两条“轨道”(track),一是包含残基保守和共变化程度的 MSA(多序列比对),二是由三维结构刻画的氨基酸残基之间的空间距离。Transformer 神经网络将二者联通,使得序列信息能传递到结构,结构信息也能传递给序列,从而二者中任何一者的改进都将促使另一者改进。
接下来,经过两条轨道交互处理过的信息,被传送给“结构模块”(structure module);后者直接生成预测蛋白的三维结构,也就是所谓“端到端”预测。
2021年初,根据 DeepMind 披露的 AlphaFold2 框架,学界和业界推测 AlphaFold2 使用了SE(3) equivariant attention来保持三维坐标的刚体旋转不变性,从而实现“端到端训练”。Baker 团队在几个月内就完成了“逆向工程”,名曰RoseTTAFold。但是,在 AlphaFold2 论文于 2021.6 发布后,大家才发现 AlphaFold2 其实仅仅用了一个堪称古老的蛋白质结构基本常识,即肽键的几何构型约束。
在此,两位作者也难掩失望,直言不讳地说:AlphaFold2 的成功并不是因为什么深刻异常的生物学洞见,而是因为,AlphaFold2 是一个非常好的工程化系统,它利用注意力算法将许多新近尝试过的想法无缝地衔接在一起。
In many respects, AlphaFold2 is ‘just’ a very well-engineered system….
AlphaFold2 的成功是否只是将工程化推到了极限?
为了回答这个问题,不妨考虑它的等价问题:为什么 AlphaFold2 的预测如此准确?
对机器学习算法做“外科切除手术”(ablation)—— 将算法的一些关键部分整体移除,能给出部分解答。既然,普遍认为 AlphaFold2 的训练依靠两条腿走路(MSA + structure),切掉一条腿就是了!
下图是 AlphaFold2 的论文正文 Fig. 4a,是 ablation 的结果。两个红色的框框是小王加的,分别是切掉结构模板和不使用 raw MSA(依然用了MSA)的结果。可以看到,相对基线(baseline),特别是对 CASP14 的比赛测试集,影响非常小。—— 前者是在几乎移除了整个 AlphaFold2 一半的深度学习结构的情况下得到的!
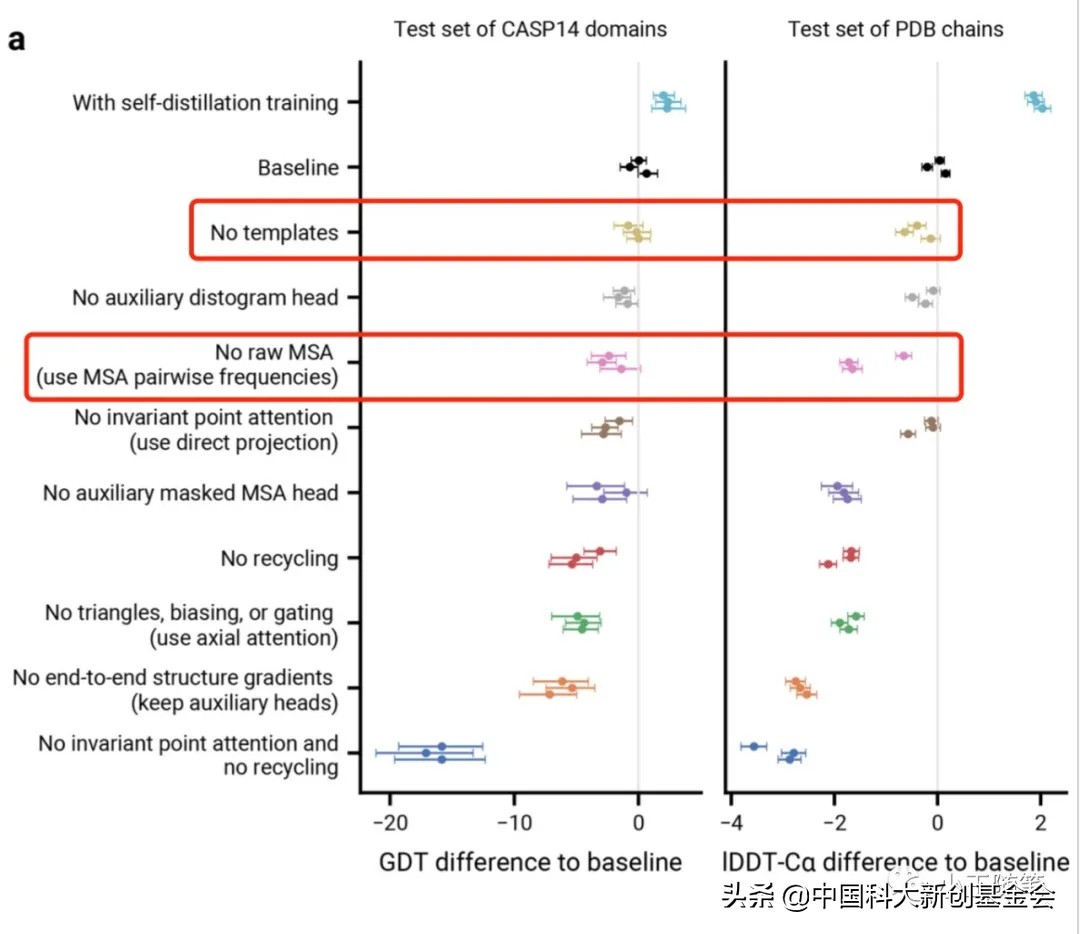
Jumper et al., Nature 2021 [2]
这说明,看似最重要的“transformer使序列与结构信息交互”似乎,似乎啊,没那么重要?惊不惊喜,意不意外?
作者认为这件事有两种可能性:
(1)AlphaFold2 过度工程化了(over-engineered)。这种情况下,AlphaFold2 可以被简化,甚至简化后,将复杂而不必要的部分替换,还能进一步提高预测精度。
(2)AlphaFold2 只是许多独立的小的点子的集合,每一个独立的小点子都仅仅贡献了一小点提高。这种情况下,只要继续堆砌小点子就行了。
作者在这打了一个比方:F1 方程式赛车 —— 赛车的任何一点改进,如气动外形、发动机等等,都不足以单独将车速大幅提高,但是加和在一起,却能使其登峰造极。
小王按:在过去一年,小王听到的各种谈及 AlphaFold2 的讲座报告中,最常提及的就是“端到端训练”和“transformer 使序列与结构信息交互”。如果”信息交互“确实如 Jones 和 Thornton 二位作者所言,仅是堆砌在过度工程化的系统内的小改进。这意味着,如果继续在 AlphaFold2 的算法框架下推进蛋白预测工作(如同几年前各支团队在 RaptorX-contact 的框架下推进),加入一项堪称重要的新点子也不过就提高一到两个百分点,反之提高一到两个百分点也就能够被称为重大创新。若不满足于此,则须另辟蹊径。
批评二:Benchmarking needs attention
AlphaFold2 令做蛋白计算而不做深度学习的人也熟悉了著名论文 <Attention is all you need>。这里,作者不得不特意强调 AlphaFold2 的基准测试(benchmarking)所需要的 attention 就指关注,不是玩梗(no pun)。
AlphaFold2 甫一发布,各种关于其性能和应用场景的测试相关工作纷纷发表,层出不穷 —— 从 AlphaFold2 的论文引用数就能看出,不到7个月,总引用已经超过1200次。甚至,将论文预印本发布在 bioRxiv 都已经显得不够快,新想法、新工作要在社交平台(推特)上时时交流。
至今发表在 bioRxiv 上的各类基准测试多达30余篇。兹列举若干如下:
内禀无序 [3]
错义点突变 [4-6]
蛋白-蛋白相互作用 / 蛋白复合体 [5,7-9]
配体结合 [5, 10]
蛋白质设计 [11, 12]
构象动态、折叠路径 [13-15]
作者认为,这些对 AlphaFold2 进行基准测试,多少有些,心急了。—— 因为它们大多没有仔细选取测试集。
我们已经清楚地知道,AlphaFold2 的置信度打分(例如 pLDDT)与是否在 PDB 中存在目标结构的同源体(homologs)显著相关。—— 既然如此,同源结构模板是评估 AlphaFold2 预测能力的干扰。

Jones & Thornton (2022) Fig. 1。这幅图是 AlphaFold2 预测结果的置信度的分布。横轴是置信度打分(0 - 100),纵轴是预测的结构的数量。橘黄色分布是在存在结构模板的;蓝色分布是不存在结构模板的。可以看到,不存在结构模板时,预测结构可信度普遍低了很多。
在作预测时,这有两种可能:(1)显式地使用了结构模板;(2)AlphaFold2 的训练集内含有预测序列的同源序列或者结构。
为排除干扰,对于(1),只须在预测时不使用结构模板 —— AlphaFold2 的推理模型允许这么做。对于(2),不太容易。显然,首先应该检查基准测试集内的序列与 AlphaFold2 的训练集内(2018.5之前发布)的序列的相似度(例如,≤ 30%)。其次,更好的做法是参考折叠分类数据库,如 CATH、SCOP、ECOD。
作者强调:任何对 AlphaFold2 所做的基准测试都不应该在没有检查过上述任何一种折叠分类数据库的情况下进行。
批评三:西西弗斯之困
西西弗斯(Sisyphus)是希腊神话中的悲剧人物。他足智多谋,是连接希腊本土与伯罗奔尼撒半岛的战略要冲科林斯的国君。当宙斯掠走河神女儿而河神遍寻不着时,西西弗斯告知了河神,坏了宙斯淫事。为报复,宙斯派出死神要将西西弗斯押入地狱。没想到西西弗斯却设计绑架了死神,勾销生死簿,让人间人人与神同寿永生。
触犯了众神的西西弗斯最终被打败,为了惩罚他,诸神让他每天把一块巨石推上山顶,但是每每未及退上,又滚落山谷,前功尽弃;日复一日,循环往复,西西弗斯永无止尽地推巨石上山,却永远也完成不了这项任务。

Veronese Design 8.125 Inch Sisyphus and The Eternal Boulder Cold Cast Resin Bronze Finish Statue Home Decor
Jones 和 Thornton 用西西弗斯比喻 EBI-AlphaFold 蛋白质结构库。
DeepMind 与 EMBL-EBI 联合开发的“AlphaFold 蛋白结构库”是蛋白质结构高精度预测算法被评为本年度 Nature Method 的两大原因之一。它在去年6月公布之时就囊括了人类蛋白质组 98.5% 的结构,以及另外20种模式生物的蛋白质组结构,总数多达35万。1月28日,DeepMind 再次宣布,27种生物的全蛋白质组结构的预测完毕,其中包括17种被忽视的疾病的病原体,数据库新增逾19万个结构。

https://www.alphafold.ebi.ac.uk/
这是好事不是吗?两位作者是什么意思!?
首先,AlphaFold2 没有那么好。参考上面的置信度分布图,联想 CASP14 的比赛结果,AlphaFold2 在对待特别是困难的目标序列时,可能会预测出非常糟糕的结果,这部分结果所占比例并不低。那么,AlphaFold蛋白结构库必然含有大量低质量的预测结构,并且,这些结构很可能会随着新解析的实验结构、新测序的宏基因组而改进。
其次,AlphaFold2 存在竞争对手。更新、更准确的结构预测算法,或者,至少能媲美 AlphaFold2 的算法,势必出现。那么,对一条没有实验结构的序列,如何判断哪一个算法的预测最准确?
这两点顾虑给 AlphaFold 蛋白结构库带来了一个巨大的两难困境(dilemma):AlphaFold 蛋白结构库要更新吗?
不更新肯定不行,因为 AlphaFold 算法也在更新。更新的话,更新频率是多少?一年一次?两年一次?三年一次?
现在 DeepMind + EMBL-EBI 预计预测 UniProt 内 1.3 亿条序列,这么多序列所对应的结构,预测一次,耗费的机时和能源、资金成本是多少?能经得起预测第二次吗,或者,每年一次?
简单地算算呗:
5 GPU*minute per model * 130 M model ≈ 1200 GPU*year
英国也要碳达峰啊!
还没完呢。UniProt 序列库自身也在迅速增大,大约2年倍增一次。后续测序的序列需要预测结构并添加进 AlphaFold 蛋白结构库吗?
此外,如果其它算法,假设 mouFold 吧,将来领先于 AlphaFold,那么这种算法预测的结构可否替换 AlphaFold 蛋白结构库内 AlphaFold 所预测的结构?如果可以,这个结构库还能被称为 AlphaFold 蛋白结构库吗?如果不行,那么这个库的可信度岂非要打折扣?
这是否恰恰西西弗斯的困境?
批评四:Open Source VS Open Science
AlphaFold2 的算法、推理模型源代码、训练好的用于推理的参数都已经开源,这是 open source 的伟大实践。然而,AlphaFold2 的参数,尽管公布了,它的许可授权(license)却仅限于学术用户。换句话说,任何工业界的研究员都不能未经授权而使用它。并且,AlphaFold 蛋白结构库内的预测结构也不允许工业界研究员使用。这不是 open science。
很有意思。
这篇评论刊发于 2022.1.11。8天后,1.19(美国时间),DeepMind 在开源的代码中修改了许可授权 —— 推理模型 + 参数均可免费商用。
当然,很可能 DeepMind 的团队恰巧有了重大突破,可以放心地将训练参数的商用限制也去掉,依然领先全业界 0.5 ~ 2 年。也有可能是受到这篇文章的感召呢?毕竟合作方、 EMBL 的前主任也站出来呼吁 open science 了。
无论如何,这种自拆技术壁垒,自填技术护城河的做法,格局打开了。

最后
Nature Methods 专刊关于 AlphaFold 与 RoseTTAFold 的最后一篇文章 <Structural biology is solved — now what?> 的末尾引用了维特根斯坦的《逻辑哲学论》:
… the problems… have in essentials been finally solved. And if I am not mistaken in this, then the value of this work… consists in the fact that it shows how little has been achieved when these problems have been solved.
Tractatus Logico-Philosophicus
Well said. 诸君熟思之。
本文完。
2022.2.3 于深圳
鸣谢:
Rosetta中文社区阿坤、力文所浩博、上交超算小明。他们在中文互联网开源社区的讨论与信息分享,为本文提供了丰富的素材。
壬寅虎年,祝愿大家虎年吉祥,虎虎有生气!
参考资料:
[1] Jones & Thornton, The impart of AlphaFold2 one year on, Nat. Methods (2021)
[2] Jumper et al., Nature 2021
[3] AlphaFold2: a role for disordered protein prediction?
[4] Using AlphaFold to predict the impact of single mutations on protein stability and function
[5] A structural biology community assessment of AlphaFold2 applications
[6] Predicting single-point mutational effect on protein stability
[7] Improved predictions of protein-protein interactions using AlphaFold2
[8] Protein complex prediction with AlphaFold-multimer
[9] Benchmarking AlphaFold for protein complex modeling reveals accuracy determination
[10] Benchmarking peptide-protein docking and interaction prediction with AlphaFold-multimer
[11] Using AlphaFold for rapid and accurate fixed backbone protein design
[12] AlphaDesign: a de novo protein design framework based on AlphaFold
[13] Current protein structure predictors do not produce meaningful folding pathways
[14] Sampling the conformational landscapes of transporters and receptors with AlphaFold2
[15] AlphaFold and the amyloid landscape
新闻来源: 小王随笔
【转载请注明中国科大新创校友基金会。了解更多,请移步官方微信(ID:USTCIF)与网站(www.ustcif.org.cn)】