概述
最近生产系统某个功能管理模块出现卡顿,输入查询条件查询到进入查询结果页面耗时20分钟,该问题对现场作业效率造成较大影响。但之前并无异常,最近也没有做什么太大操作,下面介绍一下问题的排查过程~
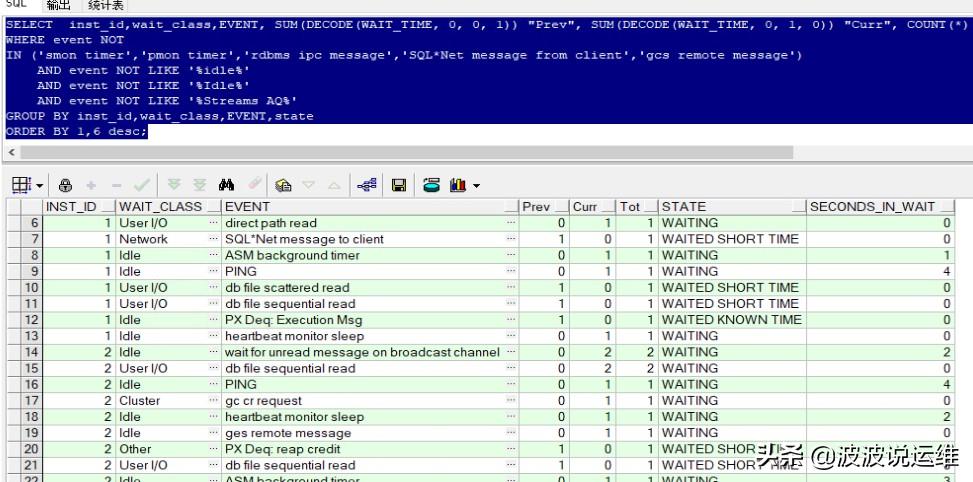
一、查看当前等待事件
排查结果:等待事件无明显异常,等待时间均不长
SELECT inst_id,wait_class,EVENT, SUM(DECODE(WAIT_TIME, 0, 0, 1)) "Prev", SUM(DECODE(WAIT_TIME, 0, 1, 0)) "Curr", COUNT(*) "Tot" , state, sum(SECONDS_IN_WAIT) SECONDS_IN_WAIT FROM GV$SESSION_WAIT
WHERE event NOT
IN ('smon timer','pmon timer','rdbms ipc message','SQL*Net message from client','gcs remote message')
AND event NOT LIKE '%idle%'
AND event NOT LIKE '%Idle%'
AND event NOT LIKE '%Streams AQ%'
GROUP BY inst_id,wait_class,EVENT,state
ORDER BY 1,6 desc;
说明:
1)当state值为Waiting,Second_in_wait值才是实际的等待时间(单位:秒),当state值为Waiting known time,那么wait_time值就是实际等待时间。
Prev代表上一次等待次数,Curr代表当前等待次数
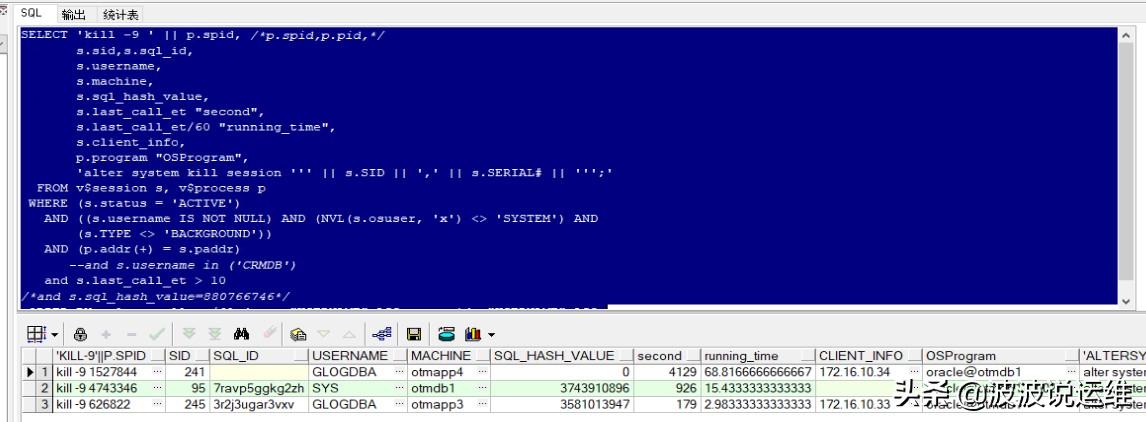
二、查看长时间运行sql
排查结果:均是一些正常跑的sql和任务
--实时监控执行时间超过10s的sql语句
SELECT 'kill -9 ' || p.spid, /*p.spid,p.pid,*/
s.sid,s.sql_id,
s.username,
s.machine,
s.sql_hash_value,
s.last_call_et "second",
s.last_call_et/60 "running_time",
s.client_info,
p.program "OSProgram",
'alter system kill session ''' || s.SID || ',' || s.SERIAL# || ''';'
FROM v$session s, v$process p
WHERE (s.status = 'ACTIVE')
AND ((s.username IS NOT NULL) AND (NVL(s.osuser, 'x') <> 'SYSTEM') AND
(s.TYPE <> 'BACKGROUND'))
AND (p.addr(+) = s.paddr)
--and s.username in ('CRMDB')
and s.last_call_et > 10
/*and s.sql_hash_value=880766746*/
ORDER BY s.last_call_et/60 desc, "USERNAME" ASC, ownerid, "USERNAME" ASC;
--根据sid查看具体的sql语句
select username, sql_text, machine, osuser
from gv$session a, gv$sqltext_with_newlines b
where DECODE(a.sql_hash_value, 0, prev_hash_value, sql_hash_value) =
b.hash_value
and a.sid = &sid
order by piece;
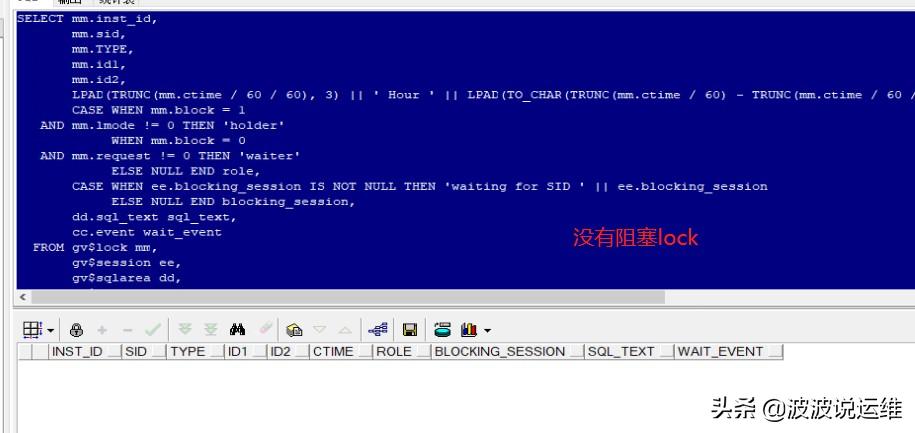
三、查看阻塞lock
排查结果:无
SELECT mm.inst_id,
mm.sid,
mm.TYPE,
mm.id1,
mm.id2,
LPAD(TRUNC(mm.ctime / 60 / 60), 3) || ' Hour ' || LPAD(TO_CHAR(TRUNC(mm.ctime / 60) - TRUNC(mm.ctime / 60 / 60) * 60, 'fm09'), 2) || ' Min ' || LPAD(TO_CHAR(mm.ctime - TRUNC(mm.ctime / 60) * 60, 'fm09'), 2) || ' Sec' ctime,
CASE WHEN mm.block = 1
AND mm.lmode != 0 THEN 'holder'
WHEN mm.block = 0
AND mm.request != 0 THEN 'waiter'
ELSE NULL END role,
CASE WHEN ee.blocking_session IS NOT NULL THEN 'waiting for SID ' || ee.blocking_session
ELSE NULL END blocking_session,
dd.sql_text sql_text,
cc.event wait_event
FROM gv$lock mm,
gv$session ee,
gv$sqlarea dd,
gv$session_wait cc
WHERE mm.sid IN (SELECT nn.sid
FROM (SELECT tt.*,
COUNT(1) OVER (PARTITION BY tt.TYPE,
tt.id1,
tt.id2) cnt, MAX(tt.lmode) OVER (PARTITION BY tt.TYPE,
tt.id1,
tt.id2) lmod_flag, MAX(tt.request) OVER (PARTITION BY tt.TYPE,
tt.id1,
tt.id2) request_flag
FROM gv$lock tt) nn
WHERE nn.cnt > 1
AND nn.lmod_flag != 0
AND nn.request_flag != 0)
AND mm.sid = ee.sid (+)
AND ee.sql_id = dd.sql_id (+)
AND mm.sid = cc.sid (+)
AND ((mm.block = 1
AND mm.lmode != 0)
OR (mm.block = 0
AND mm.request != 0))
ORDER BY mm.TYPE, mm.id1, mm.id2, mm.lmode DESC,
mm.ctime DESC
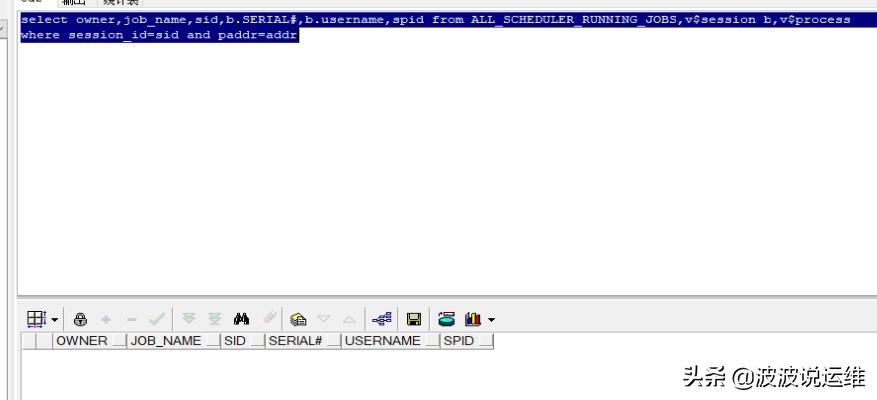
四、查看是否有正在运行的定时任务
排查结果:无
--查询正在执行的scheduler_job
select owner,job_name,sid,b.SERIAL#,b.username,spid from ALL_SCHEDULER_RUNNING_JOBS,v$session b,v$process
where session_id=sid and paddr=addr
五、从AWR报告做分析
前面四条SQL只是凭经验去快速定位,看来快速定位找不到问题,只能拿故障时间段的awr进行整体分析了,如果时间点能更细那就再拿ASH看。
1、awr概览
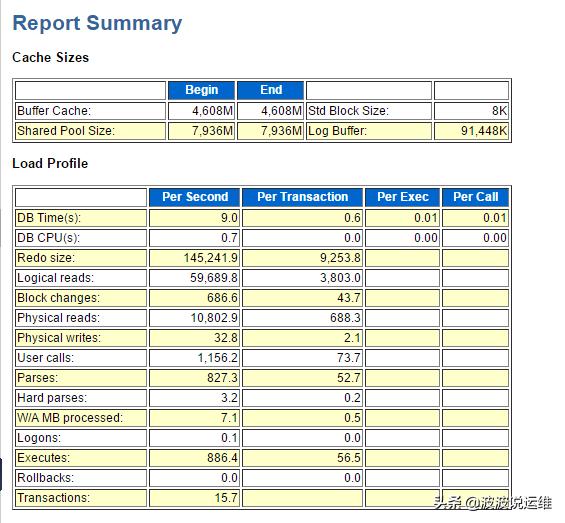
Instance Efficiency Percentages (Target 100%)所有指标 的目标均为100%,即越大越好,在少数bug情况下可能超过100%或者为负值。
标准是:
- 80%以上 %Non-Parse CPU
- 90%以上 Buffer Hit%, In-memory Sort%, Soft Parse%
- 95%以上 Library Hit%, Redo Nowait%, Buffer Nowait%
- 98%以上 Latch Hit%
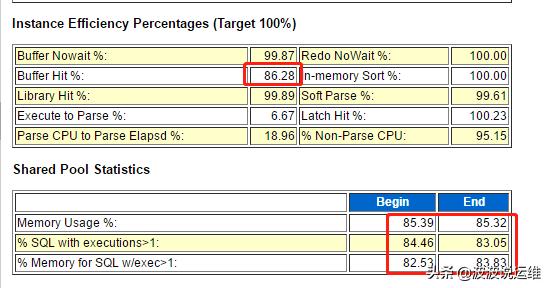
可以看到Buffer Hit %: 是不达标的
Memory Usage %:对于一个已经运行一段时间的数据库来说,共享池内存使用率,应该稳定在75%-90%间,
SQL with executions>1:执行次数大于1的sql比率,如果此值太小,说明需要在应用中更多使用绑定变量,避免过多SQL解析。
Memory for SQL w/exec>1:执行次数大于1的SQL消耗内存的占比。这是与不频繁使用的SQL语句相比,频繁使用的SQL语句消耗内存多少的一个度量。
2、时间模型分析
在awr中,Time Model Statistics用于回答“到底前台进程消耗了多少时间?”,“语句解析消耗了多少时间?”等诸如此类的问题。
这里可以看到排在最前的是SQL execute elapsed time ,该值代表SQL statements 运行所花费的总的时间 , 注意对于 select 语句来说 . 这相同包含获取 (fetch) 查询结果的时间。
可以看到用于sql执行的时间(sql execute elapsed time)占到了95.02%,作来一个相对正常的系统,这一比率不应低于90%甚至更高。
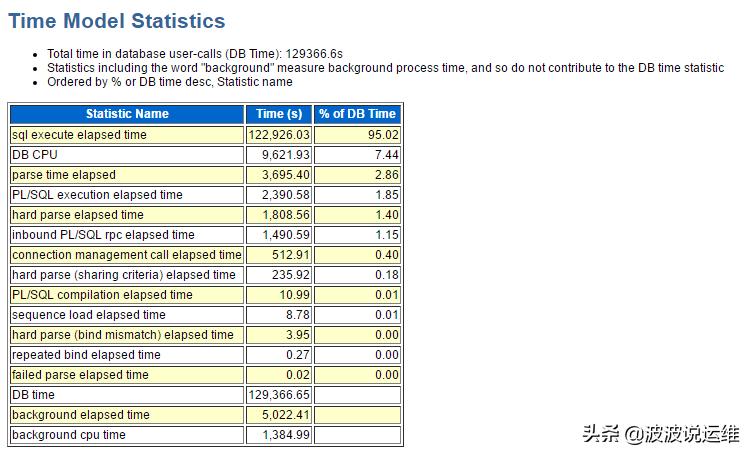
ps:
parse time elapsed、hard parse elapsed time 结合起来看解析是否是主要矛盾,若是则重点是软解析还是硬解析
sequence load elapsed time sequence序列争用是否是问题焦点
PL/SQL compilation elapsed time PL/SQL对象编译的耗时
注意PL/SQL execution elapsed time 纯耗费在PL/SQL解释器上的时间。不包括花在执行和解析其包含SQL上的时间
connection management call elapsed time 建立数据库session连接和断开的耗时
failed parse elapsed time 解析失败,例如由于ORA-4031
hard parse (sharing criteria) elapsed time 由于无法共享游标造成的硬解析
hard parse (bind mismatch) elapsed time 由于bind type or bind size 不一致造成的硬解析
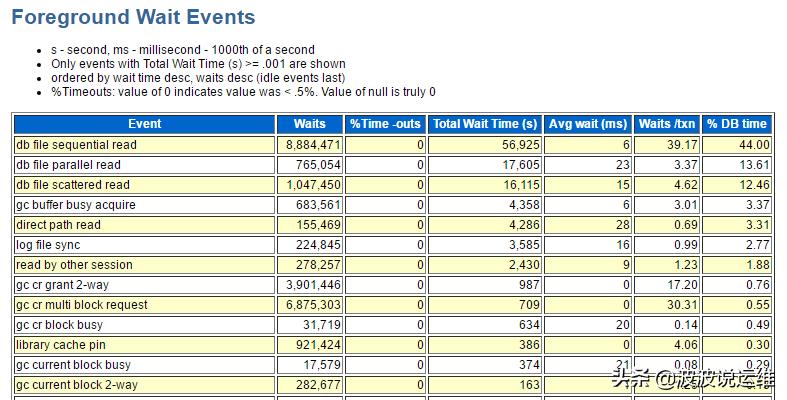
3、等待事件分析
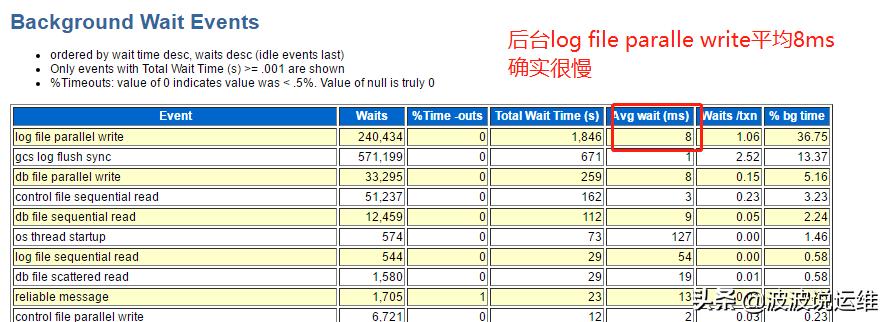
从等待事件可以看出主要是I/0上的瓶颈,其中commit平均等待16ms,后台log file paralle write平均8ms确实太慢了,初步判断系统明显卡顿。
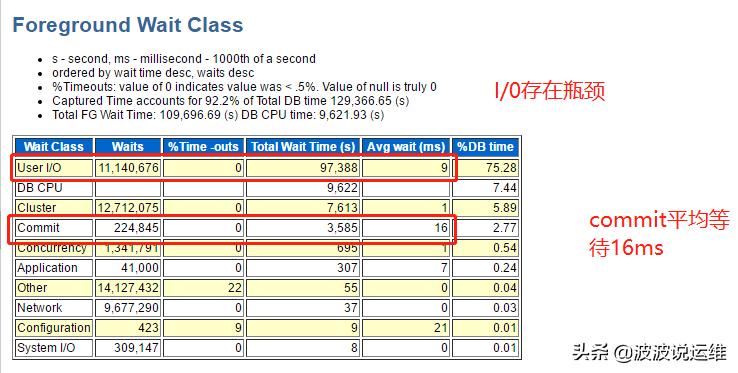
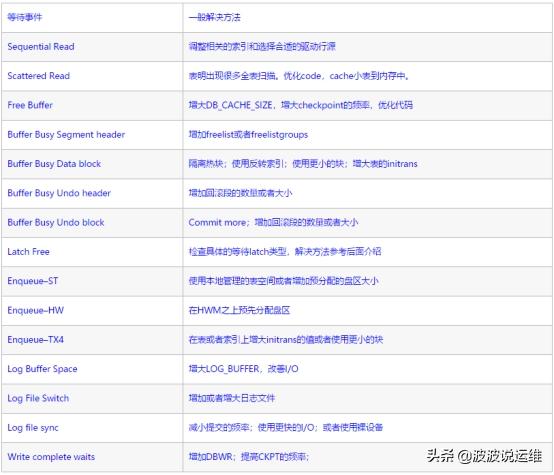
ps:常见的等待事件和解决方法
4、TOP SQL分析
从以上结果分析,主要问题是在I/0上,如果是从整体优化还是需要从SQL ordered by User I/O Wait Time(I/0等待时间)、SQL ordered by Gets(逻辑读)、SQL ordered by Reads(物理读)四个方面去找sql做优化。
但以下涉及的sql均属于日常用到的,没明显异常,但系统却突然卡顿?
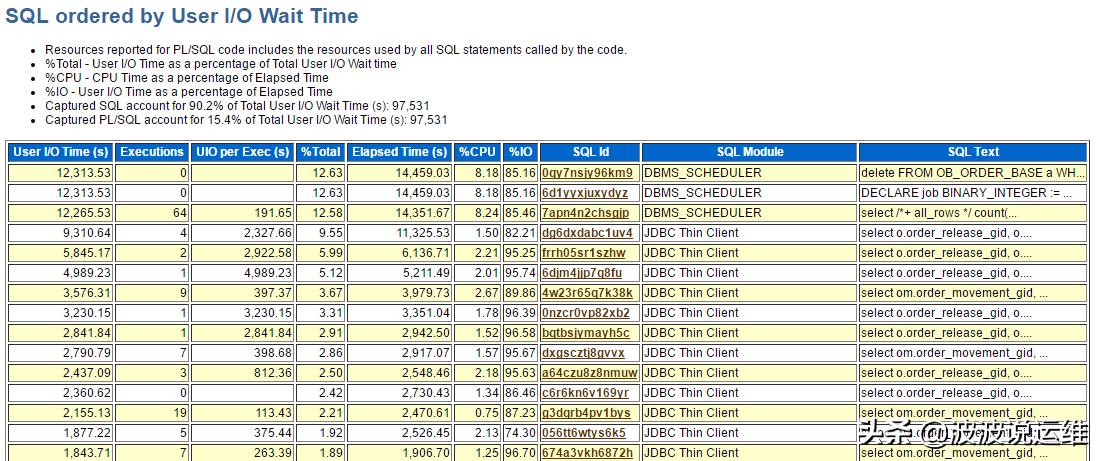
说明:
- CPU TIME : 该SQL 在快照时间内累计执行所消耗的CPU 时间片,单位为s
- Executions : 该SQL在快照时间内累计执行的次数
- CPU per Exec (s) :该SQL 平均单次执行所消耗的CPU时间 , 即 ( SQL CPU TIME / SQL Executions )
- %Total : 该SQL 累计消耗的CPU时间 占 该时段总的 DB CPU的比例, 即 ( SQL CPU TIME / Total DB CPU)
- % CPU 该SQL 所消耗的CPU 时间 占 该SQL消耗的时间里的比例, 即 (SQL CPU Time / SQL Elapsed Time) ,该指标说明了该语句是否是CPU敏感的
- %IO 该SQL 所消耗的I/O 时间 占 该SQL消耗的时间里的比例, 即(SQL I/O Time/SQL Elapsed Time) ,该指标说明了该语句是否是I/O敏感的。
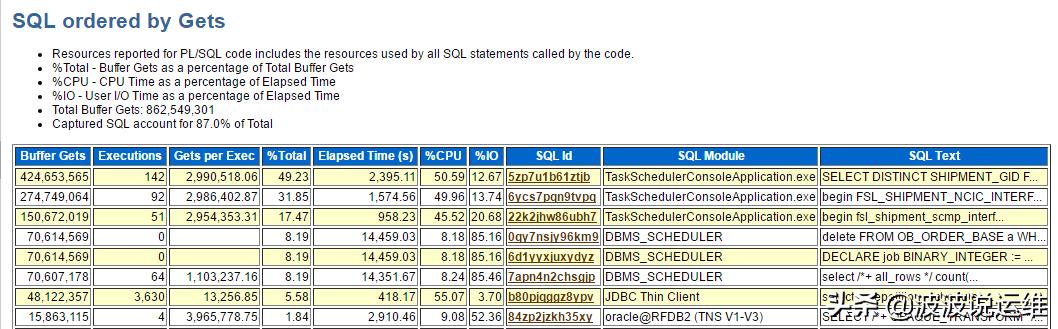
说明:
- Buffer Gets : 该SQL在快照时间内累计运行所消耗的buffer gets,包括了consistent read 和 current read
- Executions : 该SQL在快照时间内累计执行的次数
- Gets per Exec : 该SQL平均单次的buffer gets , 对于事务型transaction操作而言 一般该单次buffer gets小于2000
- % Total 该SQL 累计运行所消耗的buffer gets占 总的db buffer gets的比率, (SQL buffer gets / DB total buffer gets)
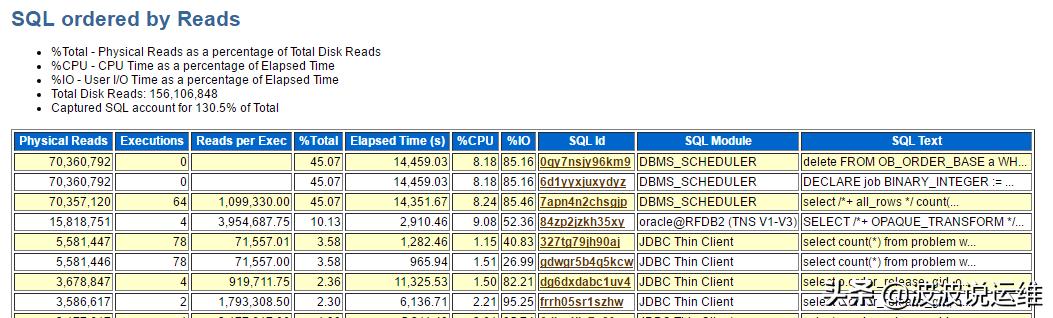
说明:
- Physical reads : 该SQL累计运行所消耗的物理读
- Executions : 该SQL在快照时间内累计执行的次数
- Reads per Exec : 该SQL 单次运行所消耗的物理读, (SQL Physical reads/Executions) , 对于OLTP transaction 类型的操作而言单次一般不超过100
- %Total : 该SQL 累计消耗的物理读 占 该时段总的 物理读的比例, 即 ( SQL physical read / Total DB physical read )
5、表段分析
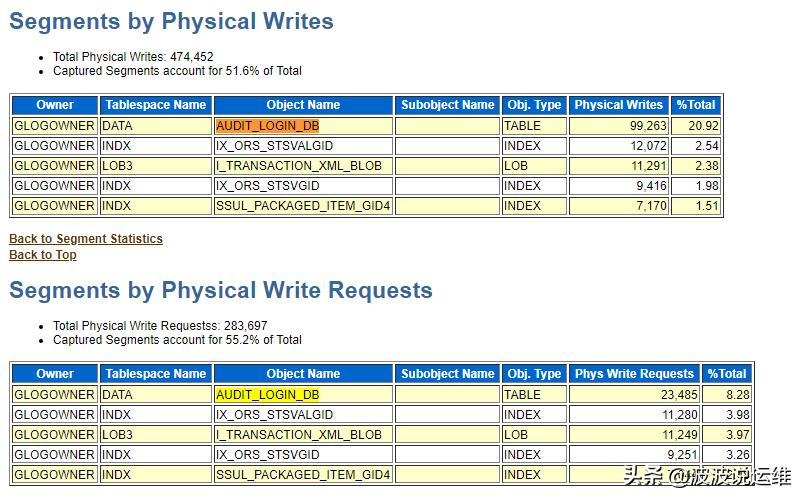
从前面整体提示IO问题,接下来我们看一下Segments by Physical Writes和Segments by Physical Write Requests,看一下哪些表段在IO方面占用比较高,发现AUDIT_LOGIN_DB这张表物理写占了20%,物理请求也占了8.2%,估计是数据量过大了
该表不属于业务表,这里判断异常在这张表上。
六、故障表分析
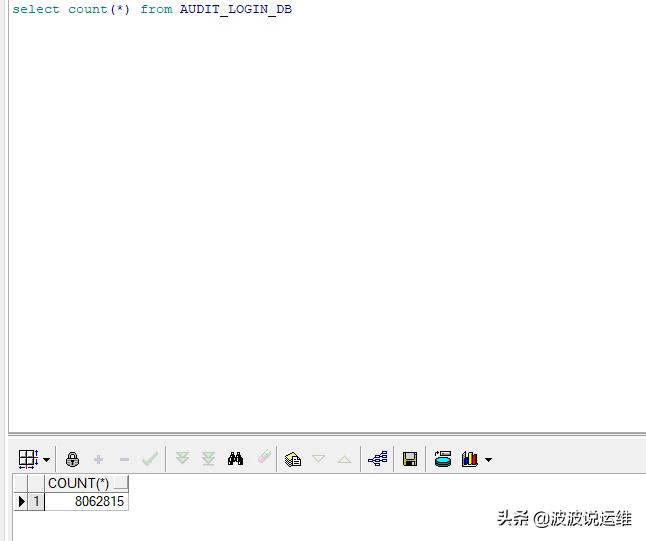
1、查看该表数据量及明细
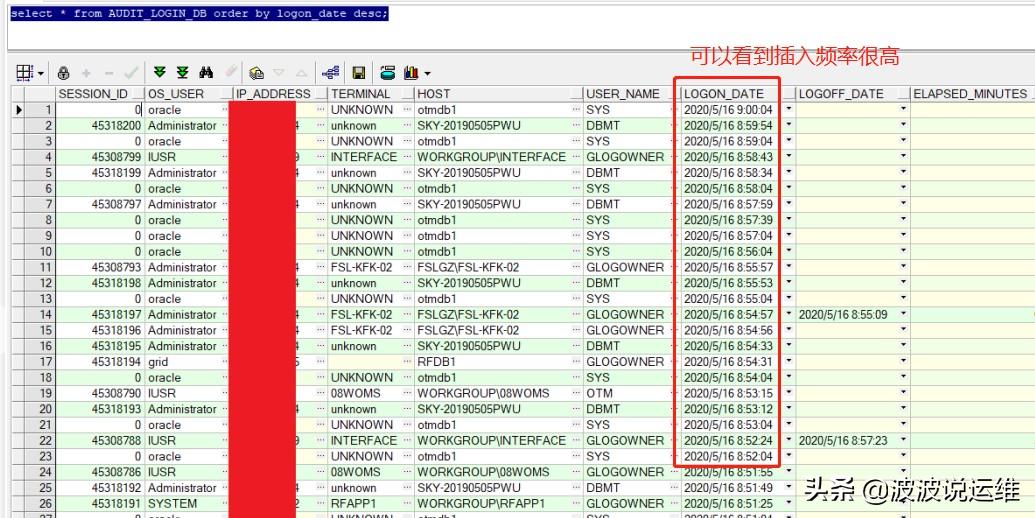
这张表是属于用户登录时记录IP等信息,每次登陆触发器都会去写这张表,目前该表数据量已经到8百万级别,且从登录时间可以看到插入频率一直很高
2、减少数据量
该表无太大作用,这里选择保留一段时间后做表的切换,然后truncate,至于怎么做,前面提了N次,篇幅有限,这里就不做介绍了...
七、测试
经过一段时间测试后,业务反馈正常,问题解决,又可以打酱油了~
觉得有用的朋友多帮忙转发哦!后面会分享更多devops和DBA方面的内容,感兴趣的朋友可以关注下~
