·第一步,先把数据上传好,然后进行一个拆分。拆不拆分是根据自己的样模量来进行决定的,大家也可以尝试一下拆还不拆,最后统计分析结果怎么样,所以能拆尽量拆。如果样模量够大,能拆尽量拆,加号之后要进行备份分析。往统计分析表格里面的tableone,对吧?
然后,把数据载入之后就选择这个应变量。比如说这个是死亡dead,然后里面自变量把相应的这些给选进去,对吧?比如说要研究哪些自变量,把它选进去,选好了之后点机械一,点生成表格。点三种表格,就会把这么多变量了全部来进行分析。
·这是机械一是指什么?这个所有数据就是没有进行拆分分组的时候所有数据。机械二是什么?就是是否发生阳*交性**集的就是是否发生死亡的。点生成表格,因为这地方一、二、三、四、五、六、七、八、九、十有十个变量,点生成表格,不然就把剩十个变量了全部就生成好了。
在这个设计的时候,这个软件可以识别几种事情。
·第一个,你是分类变量还是素质变量,会自动识别。如果发现里面只有零、一、零、一的,基本上都是分类变量。如果分类变量了就会用这个 躲开和这个percentage来进行描述,如果你是素质变量了还会自动检测到底是不是符合正在分布。如果符合正在分布就用迅速和标准差来进行展示,不符合就是用中位数和四分位数间距来进行标。这是第二种,根据是否发生假性结局的。
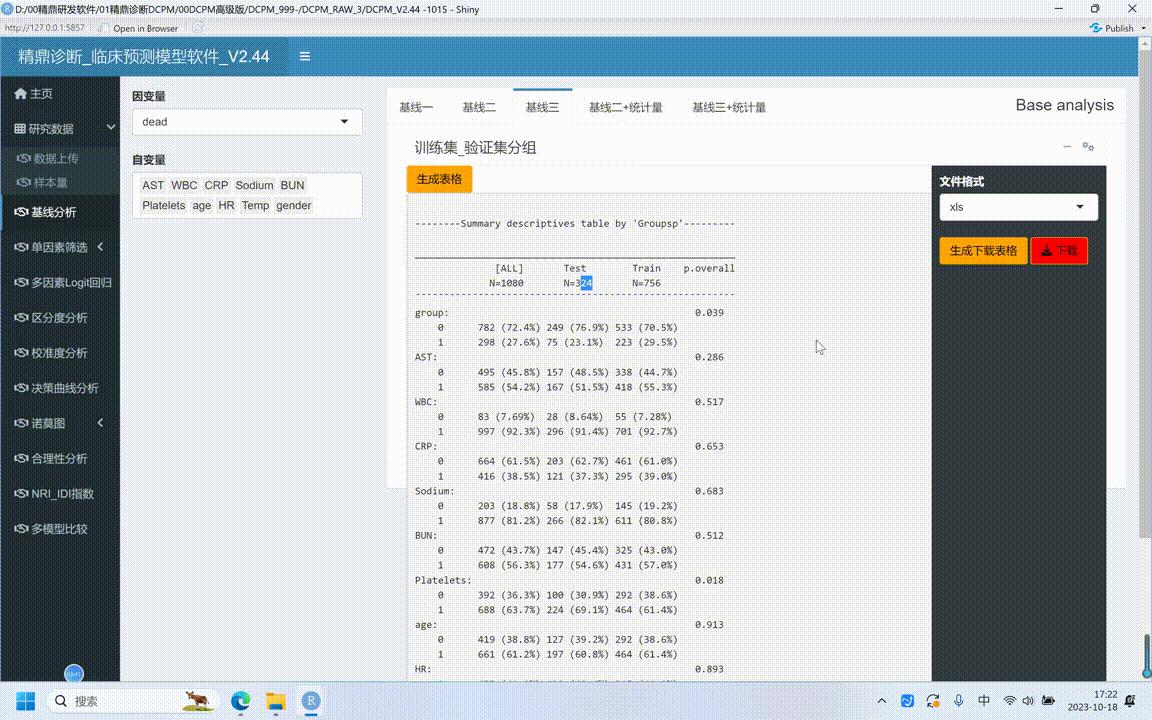
·第三种,根据分组是不是训练级验证级。我们看这个数据数据上传这方训练级多少?七、百五十六,七百五十六验证理论三百二十四。再看一下当点接线三点生成表格的时候,这里面就是训练级就是七、百五十六验证级就三百二十四。然后左边就是all,其实这个all就相当于是这个极限。
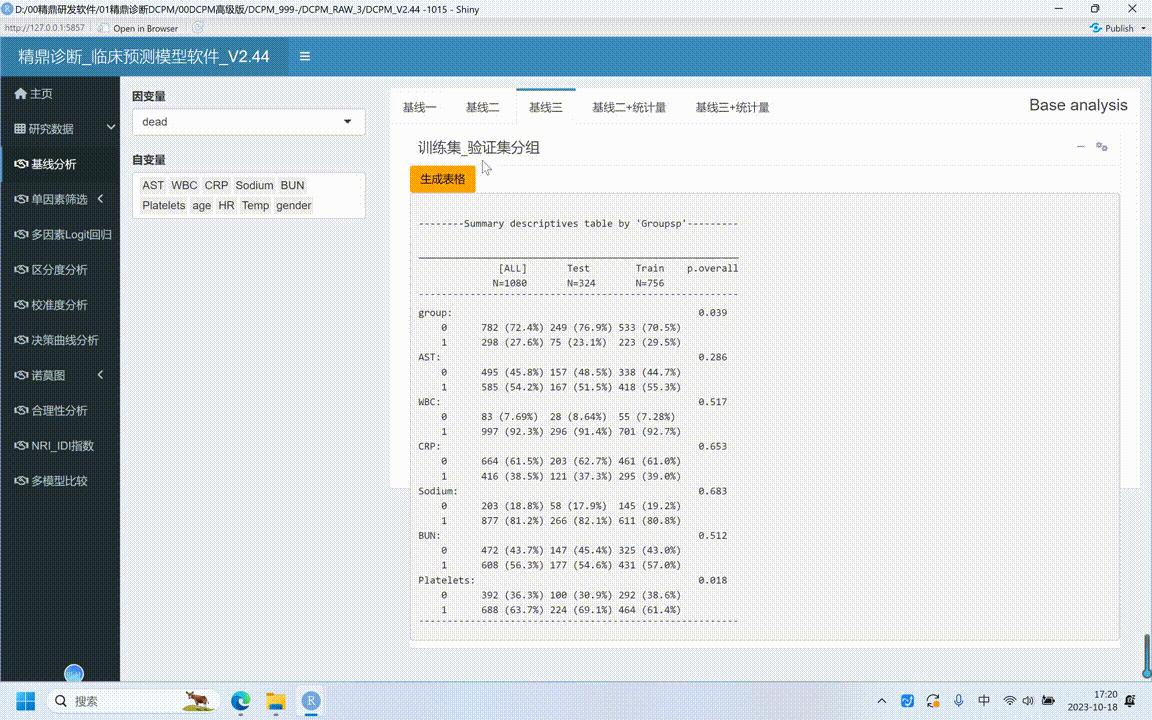
·在这个机械三,希望是什么?希望分组在所有的这些检测的这些x或者风险因素里面,p值都要大于零点零五的,这才反映随机分组的分成了训练级和验证级,一线才比较是不是?看到的确是可比的。这地方所有的变量都是什么,都是数大于零点零五的。
那这地方group是什么?group不是的。注意了,那这个group是什么?上传数据里面有一个人为指定的变量,这是分组信息的变量,在前面上传的已经说过了。所以这个变量在最终生成表格里面要把它删掉是不要的。ok。这是第二个。
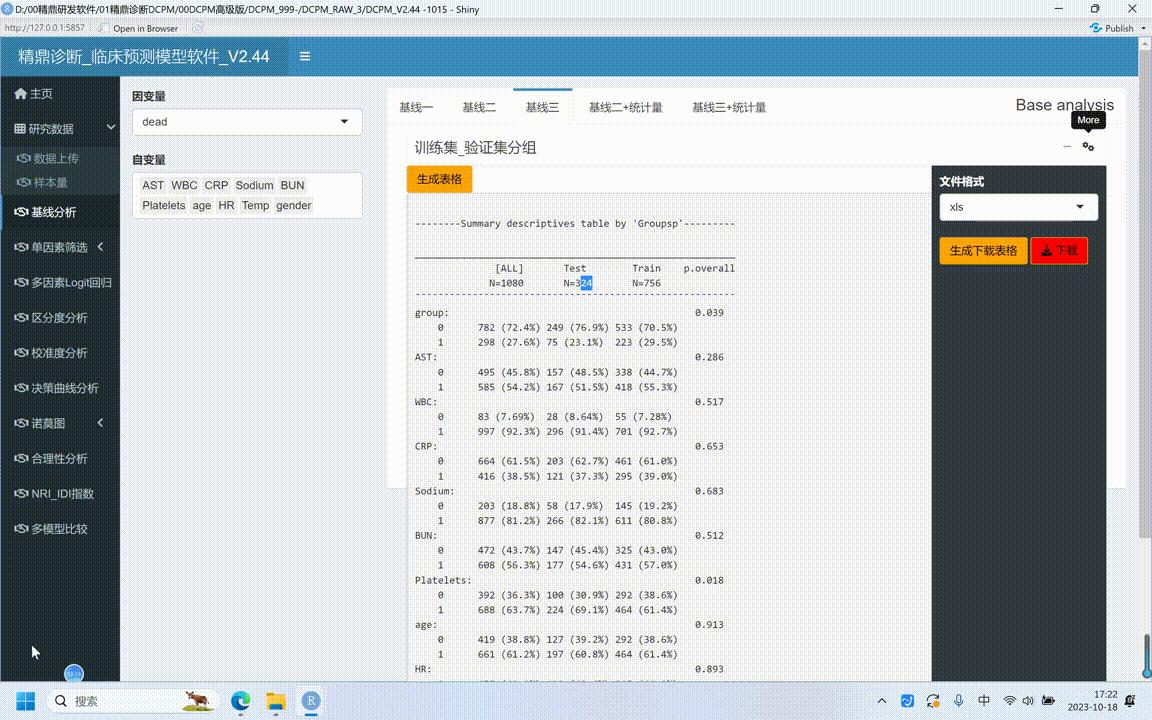
·什么?这发表英文文章,这样的表格*载下**下来基本上就可以了。怎么*载下**?就像生成这样的表格之后怎么*载下**?就点这个more,然后点生成下,然后点*载下**就可以了。
点完生成*载下**表格稍微等一下,因为要把 t x、t这种格式的要转化成,那么只要表格才能*载下**下来。一般来说会在左下下角的时候感觉到有一串数字出现了,出现完了之后就意味着它生成了,这时候点*载下**就可以了。
可以演示一个给大家看一下,这个是基线,点生成*载下**表格,点完之后点*载下**就可以了,这时候就可以了,然后找一个位置*载下***载下**就可以了。ok,发表英文文章就可以了。
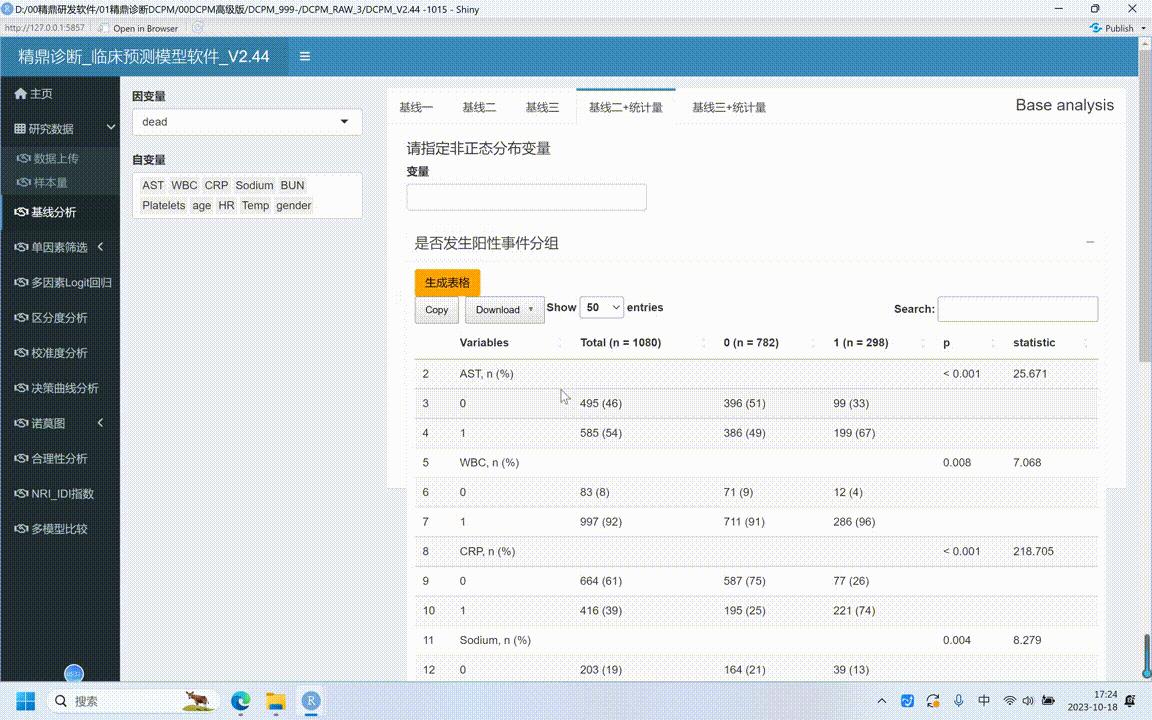
但是有一些用户说很多一些中文文章的时候,光有p值还不行的,还需要有统计量,这时候统计量到底怎么算?就可以又增加了这两个功能,点统计量,点生成表格,就会把这么多变量变量直到十、一行,但是总共有三十行,也可以显示多一点显示到五十号,表格就算完了。
这个表格前面都是一样的,后面不一样之处在什么地方?就在于除了p值之外,有个统计量。这个统计量就是如果对于前面是分类变量的就是卡方减,选中哪些变量?这时候还有两种。一种就是体检,因为是两种,如果是分类变量,如果是非正态分布采用的是中位数四分位数间距,那就是是非参数值和检验,这是第二种。
第三种,在这地方还有个问题,就是将分析完了之后,素质如果遇到素质变量的话,全部都会按照均速和标准查来进行显示的。
统计分析就是t值,如果有一些是不符合正态分布的,这时候可以在这边来进行指定。比如选择某一个变动,是不符合正态分布的,把它选进去。选过去之后再点生成表格,下面的数字变量就会分成两种。
就是凡是在这地方选入的那些素质变量,就会按照非正态分布的中位数四分位数间距来进行展示。同时恐惧分析采用的是什么?非像素检验,如果没有选进来的数字变量了,那就会按照均速标准差,就会用tg统计三也是一样的。
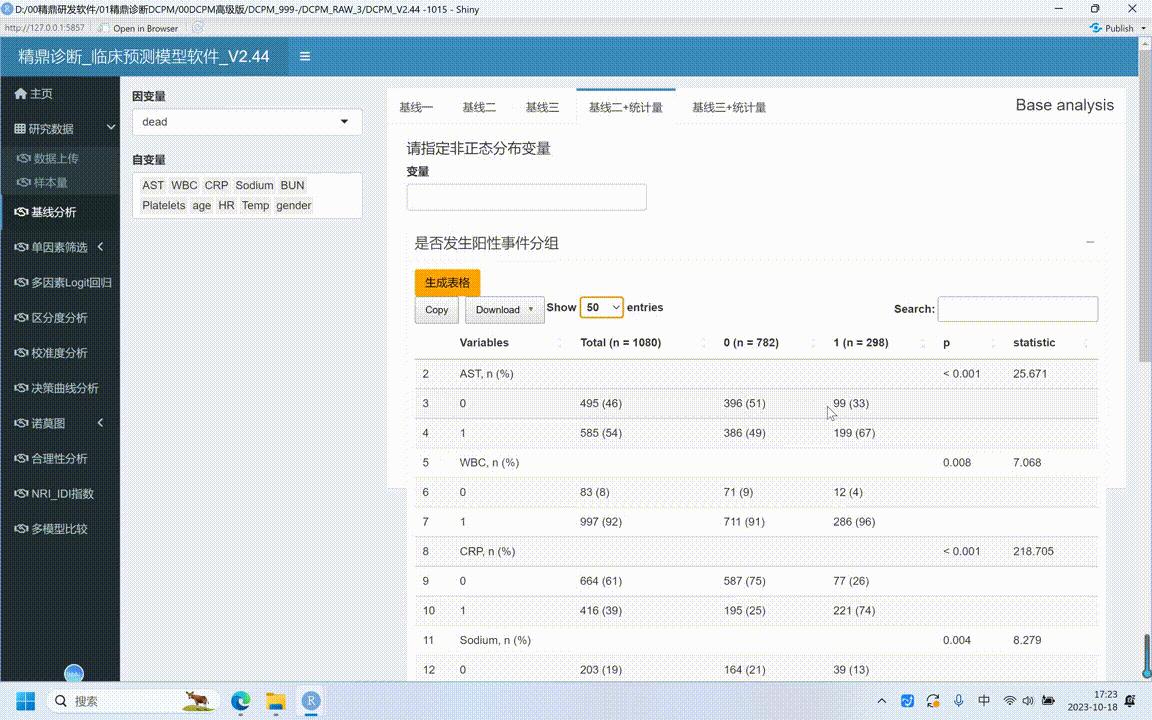
点三层表格,首先一定要点生成表格,先会把表格生成好,生成好了之后再针对到底是不是符合正态分布,在这段选择把非正态分布的选进来,选好了之后再点生成表格就会有一个问题,那怎么知道到底是不是符合正在分布?没有关系,因为是经验,比如说是机械二的,机械二会自动识别的,自动识别它到底是不是符合正在分布?把这地方不符合正在分布的,然后看好选中哪些变量,然后在这地方把它选中就可以了,这就会带统计量了。
发表 icr论文的机械一、机械二机械三就可以了。发表中文文章,如如果要这个统计量也可以用皖二和皖四带有统计量,这就是基线分析。
·接线分析一共可以做三种。
→第一种,数据量不大,所有都放在一起的是一组的。
→第二个,按照是不是发生结局的叫一万次,没有发生的叫一万次,就像这个讲的发生死亡和没有发生死亡的。
→第三种,极限三就是按照数据集分组的。这边是training set,这边是vanitation that set。这两个一般来讲是训练集和验证集,然后对他们来进行比较的时候,其实要求大于零点零五的,但是发生疾病和没有发生疾病就相当于是单因素分析了。
这时候不要去图大于零点零五,必须出现图小于零点零五了,不然就意味着没有意义了。这个就是基线分析指甲功能,相对来讲比较简单一点点。