数据分析师的典型工作内容与工作流程
数据分析师的主要内容就是利用一定的工具,结合具体的业务对数据进行处理分析,帮助业务部门监控,定位,寻因,解决问题,从而帮助企业高效决策,提高经营效率。可以看出作为一个数据分析师不仅仅要掌握数据分析的工具,还要对所要分析的问题具有一定的认知,并且还要具有一定的分析思路。
下图是一个数据分析师的典型工作流程,共分为三个环节:第一环节,数据需求的沟通;第二环节,数据分析建模;第三环节,结论落地应用。前两个环节是每一个数据分析师都必不可少的,而第三个环节是根据每个公司对数据分析师的定位不同而决定的。而我们今天要介绍的pandas主要是在数据预处理与数据分析建模的环节中应用。
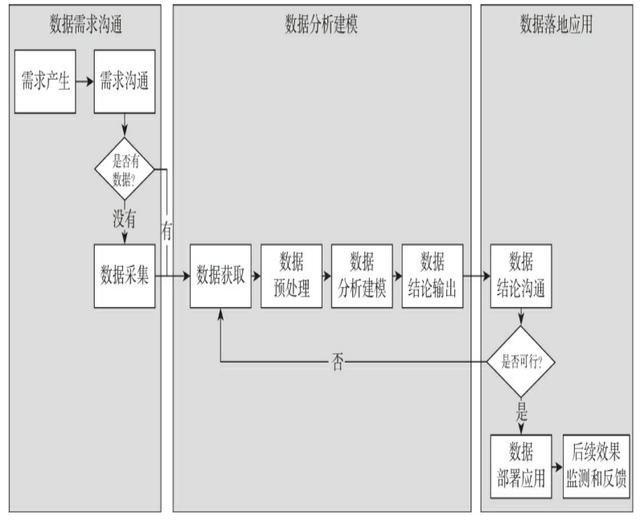
数据分析师的典型工作流程
你眼中的数据分析师的桌面
你眼中的分析师桌面
现实中的数据分析师的桌面
现实中分析师的桌面
数据为什么要学python,python的优势在哪?
随着python的热度的增加,现在越来越多的数据分析师开始学习与使用python,我么也不能只凭热度而选择一个工具,而是要分析一下对分析师来讲,python有哪些优势:
1、python的应用面更广,使用更加灵活,它能够关联数据分析中数据流转的上中下游,上游:数据获取,python可以很好的兼容爬虫,已经连接底层数据库的接口;中游:数据的分析,在这个过程中,python已经具有非常全面覆盖数据清洗,分析,建模等方面的库,下游:数据的展示与输出,在python中有许多库,能够实现各种个性化需求的展示图表。
2、在处理大量的数据时,python比excel更加高效与可靠,可以轻松实现大量数据的复杂计算。
3、python相比于excel,可以轻松实现自动化,对于许多个性化的需求,python比excel更容易实现自动化,并且自动化的程度更高。
数据分析师掌握python到什么程度,以及python向后的拓展可能有哪些?
1、对于一个初级分析师,对于python的掌握程度可以要求到,能够像excel处理数据似的使用python,需要熟练的掌握pandas,numpy库,基本掌握matplotplt库即可
2由于python的高拓展性,对于未来的发展方向,可以向算法,爬虫,可视化等方向发展,并且这些方向都是当前非常火的方向。
作为一个数据分析师如何零基础入门Python呢?
在此给大家一个两步走的过程:
第一步:基础打牢,python的基本知识肯定是必不可少的,这个基础知识可以通过廖雪峰教程,以及python菜鸟教程等学习,并且python的基础教程并不很难,对于编程的要求并不是很高。
第二步:定向训练,对于分析师最熟悉的工具当然是excel了,这一阶段的定向训练就可以对标excel,使用python的pandas库来实现excel常用的全部功能。下边的内容也是针对pandas如何实现excel的各种基本功能来展开的。
今天主要的内容是:像使用excel一样去使用Python
1、文件打开与保存
- 打开excel文件
data=pd.read_excel(r'E:\huawei\我的作品\头条号文章\pandas操作\案例数据.xlsx',sheetname='sheet1') #sheetname可省略,默认读取第一个 data_=data
原始数据见下图
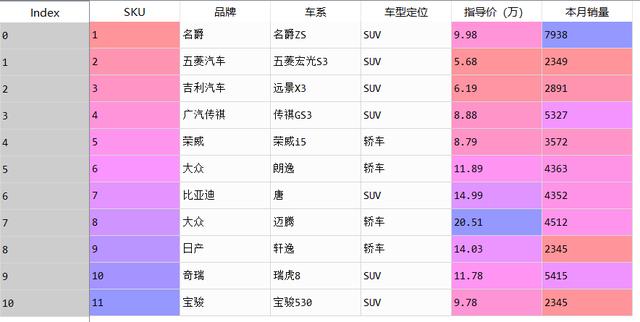
原始数据
- 保存文件
data_to_excel(r'E:\huawei\我的作品\头条号文章\pandas操作\案例数据1.xlsx')
- 多sheet保存
writer=pd.ExcelWriter(r'E:\huawei\我的作品\头条号文章\pandas操作\案例数据2.xlsx') data.to_excel(writer,'sheet_1',index=False) data.to_excel(writer,'sheet_2',index=False) writer.save() #一定不要忘记save(),否则无法保存。。
2、筛选是excel中常用的最基本的功能,我们来看一下pandas是如何实现的
- 对行进行筛选,例:筛选8-10万的SUV
data_1=data[(data['车型定位']=='SUV')&(data['指导价(万)']>8)&(data['指导价(万)']<=10)]
上面的查询逻辑其实非常的简单,需要注意的是,如果是多个条件的查询,必须在&(且)或者|(或)的两端条件用括号括起来。
- 对列进行筛选,例:只要sku与销量两列:
data_2=data[['SKU','本月销量']]
3、vlookup是大家在excel中用的最多的公式之一,当在两个表都非常大的情况下vlookup的速度是非常慢的,经常会出现死机的现象,反而用pandas中的‘vlookup’十分的快速与可靠,本人亲测,两个百万行的的表格查询,简直就是‘瞬秒’
data_4=pd.merge(data,data_2,how='left',left_on='SKU',right_on='SKU')
如下图,merge之后的效果,把data_3中‘本月销量’V进来了
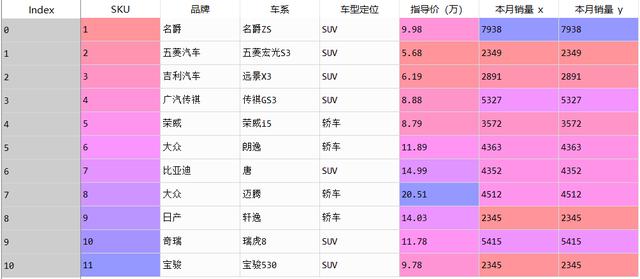
pandas-merge实现excel中的vlookup
4、透视也是大家最常用的excel技能了,下面就介绍利用pandas里的pivot_table函数如何透视,例:以车型定位对本月销量求和透视
data_5=pd.pivot_table(data,index='车型定位',values='本月销量',aggfunc='sum')
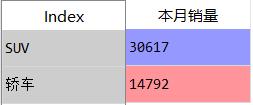
pivot_table透视效果
5、统计分析
- pandas中提供了describe()函数,能够一次性返回多个统计值,如下图:
data_6=data.describe()
- 如果想计算单独的统计值,可通过相对应的函数进行计算
ddta.count() #非空元素计算 data.min() #最小值 data.max() #最大值 data.idxmin() #最小值的位置 data.idxmax() #最大值的位置
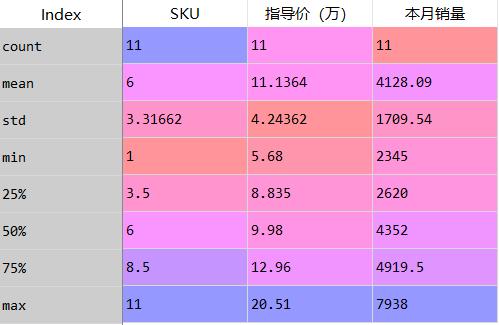
describe结果
6、排序与排名,例:对本月销量进行降序操作,对本月销量输出降序排名,排序排名效果见下图:
data_.sort_values(by='本月销量',ascending=False,inplace=True) data_['本月销量排名']=data['本月销量'].rank(ascending=False,method='min')
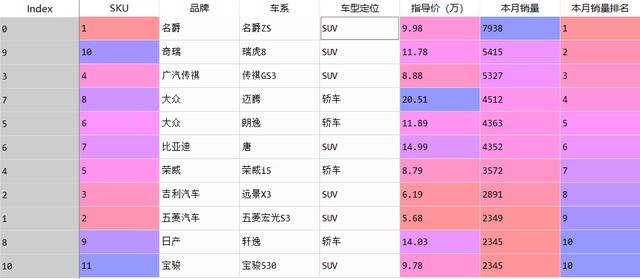
排序与排名结果
7、合并多个文件,将两个相同结构的表格进行连接将data与data_1进行合并,合并后结果见下图:
data_7=pd.concat([data,data_1]) #一定注意表格里的变量时list格式
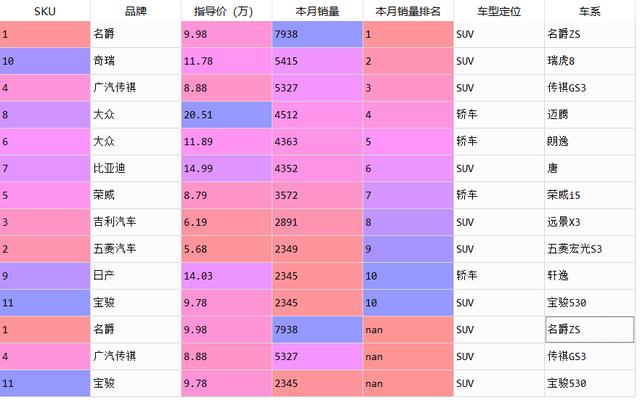
多文件合并
8、修改文件中满足特定条件的值,例:data数据中的名爵ZS的车型定位错了,需要由SUV修改成轿车,修改如下:
data.ix[data['车系']=='名爵ZS','车型定位']='轿车'

修改特定值
9、map方法在pandas里的应用,新增一列数据,将本月销量高于5000的打上‘高销量’标签,少于5000的为‘低销量’
data['高/低销量']=data['本月销量'].map(lambda x: '高销量' if x>=5000 else '低销量')
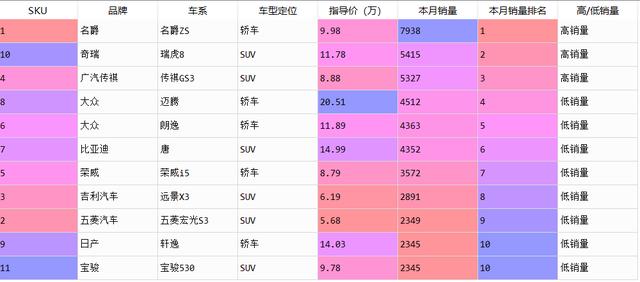
map方法应用
以上只是一些pandas的入门应用,大家在平时应用时,遇到不懂的点多百度,也可以关注我,有问题可以随时私信,只要坚持下来,总会有惊人的收获的
-------------------------------------------------------------
不忘初心,方得始终
最后,以下是全部源码汇总
import pandas as pd data=pd.read_excel(r'E:\huawei\我的作品\头条号文章\pandas操作\案例数据.xlsx') data_=data data_1=data[(data['车型定位']=='SUV')&(data['指导价(万)']>8)&(data['指导价(万)']<=10)] data_2=data[['SKU','本月销量']] data_4=pd.merge(data,data_2,how='left',left_on='SKU',right_on='SKU') data_5=pd.pivot_table(data,index='车型定位',values='本月销量',aggfunc='sum') data_6=data.describe() data_.sort_values(by='本月销量',ascending=False,inplace=True) data_['本月销量排名']=data['本月销量'].rank(ascending=False,method='min') data_7=pd.concat([data,data_1]) data.ix[data['车系']=='名爵ZS','车型定位']='轿车' data['高/低销量']=data['本月销量'].map(lambda x: '高销量' if x>=5000 else '低销量')