在矿山开采过程中,井巷或工作面周围岩体,由于弹性变形能的瞬时释放而产生突然剧烈破坏的动力现象,叫做冲击地压,它具有很大的破坏性,是煤矿重大灾害之一。
卸压钻孔,则是通过向煤壁钻孔,使钻孔周围煤体裂隙不断扩展,煤体压缩弾性能不断释放,形成大范围的卸压区,将压缩的弹性能逐步释放的冲击地压防治方法。但它的难点在于确定包括钻孔直径、钻孔深度、钻孔间距、装药量和钻孔的方向等复杂的*破爆**参数,一次施工流程往往需要3天。
而在7月18日,华为联合山东能源集团发布的盘古矿山大模型,利用AI大模型视觉识别能力,一举将这一过程缩短为10分钟,并能够实现防冲工程100%验收率。

作为AI大模型在能源领域的首次商用,就在具体行业中做出如此重要的表现。这让大模型未来在行业智能化当中的价值,特别让人期待。
但大模型的成功,有赖于算力规模的不断成长,也相应对数据中心网络提出了极高的要求。
01
大模型时代,背后的深层思考
无疑,ChatGPT是今年的世界顶流,OpenAI网站的流量在4月份就超过了18亿,进入了全球流量排名前20,同时也引发了AIGC的热潮。IDC也预计,2026年全球人工智能市场规模达到820亿美元,其中80%左右可能都是与AIGC相关的应用。
站在时代的风口,AI大模型如雨后春笋,层出不穷。文心一言、通义千问、紫东太初等中国一批通用化大模型正在快速发展,打造跨行业通用化人工智能能力平台,以华为盘古大模型为代表的专业领域大模型,以垂直解决方案的方式赋能行业数字化转型。
按照中国科技部新一代人工智能发展研究中心5月底发布的《中国人工智能大模型地图研究报告》显示,中国10亿参数规模以上的大模型已发布79个。
“百模大战”的格局已定,但也为大模型的发展提出了深层次的思考。尤其在网络层面:高速和稳定的网络是算力能够高效联接的关键,同时算力和数据也需要网络来进行调度。

从数据中心的角度,要支撑海量数据的大规模训练,大量服务器通过高速网络组成算力集群,GPU集群越大,产生的额外通信损耗越多。大带宽、高利用率、信息无损,这些能力就成为了AI大模型时代网络面临的核心挑战,
通常,数据中心多以以太网作为主要的联接方式,但以太网更擅长大容量的持续数据传输,而AI则是服务器之间的交互信息量巨大,海量大体积的信息包很容易导致网络拥塞,还会使计算效率下降。而超融合以太技术,可以满足超大规模算力集群对高性能计算的需求,可以看做是AI大模型时代的数据中心网络未来。
简单的说,超融合以太技术是通过实现数据中心网络融合,将通用计算、存储和高性能计算统一承载在0丢包以太网技术栈上,打破传统分散架构限制,实现从三张网到一张网的融合部署,并推动无损网络向超融合网络架构演进,从而实现算力网络融合,充分释放算力。
华为智能无损AI网络解决方案,正是基于超融合以太技术构建,在大模型时代,它能否成为数据中心网络AI演进的主流方向?
02
无法忽视的网络价值
我们知道,AI的三大元素包括:算法、算力和数据。其中,算法依赖大模型参数提升以及模型本身的优化,而算力和数据需要GPU服务器,存储和网络来实现交互。
大模型的训练,需要的参数规模是天量级的,对算力规模的需求同样也是天量级的。GIV的数据统计,到2030年,AI智算算力将增长500倍,达到105 ZFLOPS,训练模型将达到万亿参数千卡集群的规模,AI模型参数规模越大,对网络带宽和性能要求越高。
简单的理解,这就像是将网络运输理解成快递运输,我们需要降低路上耗时和提高运货效率,需保证不拥堵和不丢包裹。
但要如何做呢?是不是只要一味地加大带宽,让道路的承载力变大,就可以解决呢?
答案显然不是。
阿根廷首都布宜诺斯艾利斯的市中心,有一条著名的“七月九日大道”,这条大道共有18条并行车道,并有148米宽,是目前世界上最宽的道路。即便如此,这条大道依然长期处于拥堵不堪的状态。这个故事告诉我们,单纯只是拓宽道路,并不能解决交通网络的拥堵问题。
其实呢,路线的智能调度,是解决拥堵的关键。
比如,华为首创网络级负载均衡NSLB技术相当于智能导航系统,根据流量特性,将搜集到的整网信息作为创新算路算法的输入,从而得到最优的流量转发路径。一方面多条道路同时利用,不会拥塞。另一方面满足最大运货吞吐量。通过NSLB技术解决网络负载不均问题,实现98%高吞吐,AI训练效率提升20%。
另外,大模型训练往往有一个被人忽略的点,那就是网络丢包的影响。相比带宽和时延,丢包对GPU运算的影响更大,因为只要发生丢包,数据就需要重传,GPU训练就要经历一次重算,导致算力没有能够发挥最大的价值。
这也引出了网络的可用性和稳定性对于大模型训练的重要性。网络的可用性通常决定了整个集群的计算稳定性,而华为可以提供AI融合运维的能力,实现多算力网络1图呈现,秒级监控5维RoCE指标,网络负载均衡状态可视,对AI丢包、超时延主动识别,最大程度上保证算力价值得到合理释放。
例如,盘古大模型就在应用RoCE网络技术和CloudEngine系列数据中心交换机进行大模型训练。在网络架构上,华为基于CLOS组网模型构建基于CloudEngine系列交换机的Spine-Leaf两级智能架构:计算智能和网络智能结合、全局智能和本地智能协同,共同打造无损低时延的数据中心网络。利用架构创新和上述一系列的技术集合为RoCE(RDMA over Converged Ethernet)v2流量提供“无丢包、低时延、高吞吐”的网络环境,满足RoCEv2应用的高性能需求。
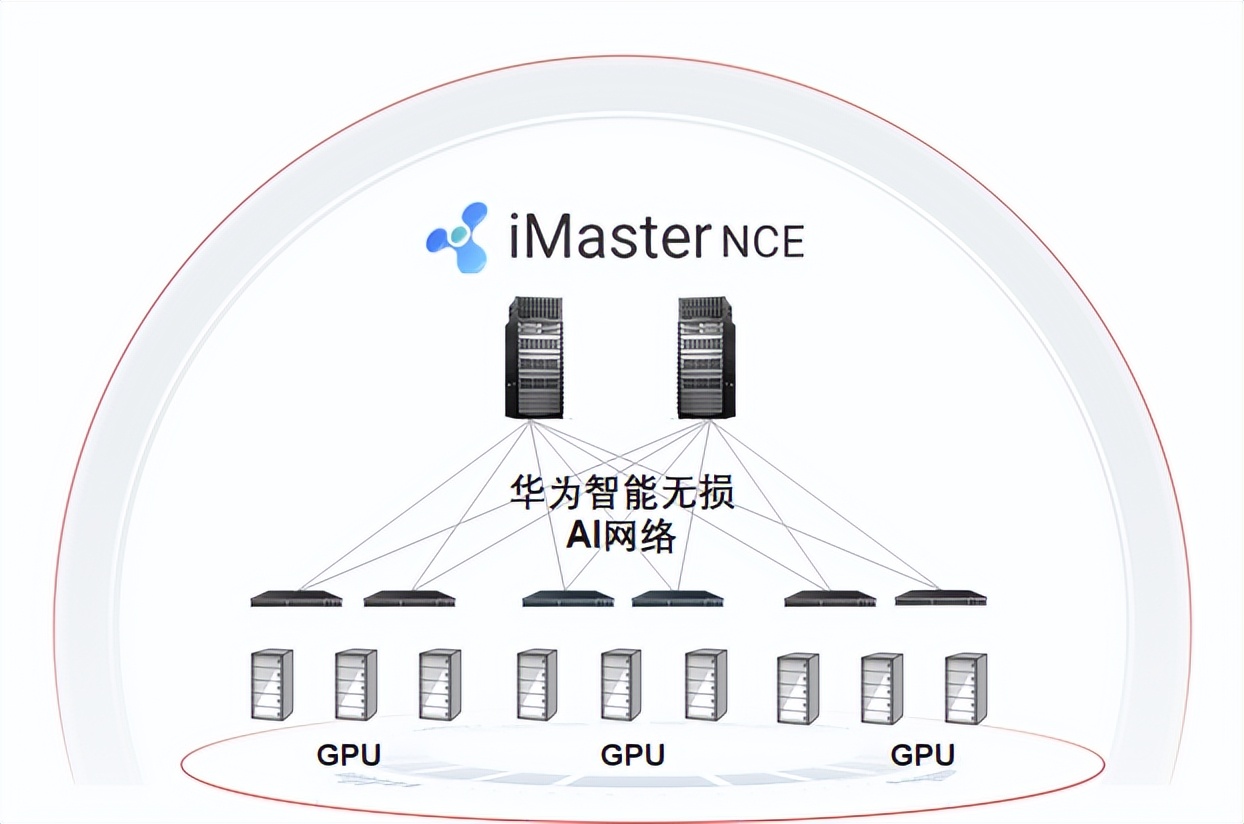
而在稳定性方面,无损的网络可以使GPU集群从存储集群中高效地获取数据,满足GPU间的参数、数据的双向传输的高可靠性。在此方面,华为还提供AI可靠易用,与计算协同工作,通过iMaster-NCE和eService管理平台进行联动,完成无损网络与NPU卡配置下发,实现端到端即插即用。
03
数据中心网络与AI时代齐头并进
大模型是当代人工智能发展的重要趋势之一,随着越来越多的大模型被应用到各个领域中,自动驾驶、医疗、金融、矿山、码头,应用场景会越来越广阔。
由于参数量庞大,需要大量的计算资源和存储空间,而且训练时间往往也很长。因此,如何提高训练效率、降低计算成本、提高模型的鲁棒性和可解释性均是目前的研究热点,而对于数据中心网络的瓶颈,认知明显不足。
劳伦斯·彼得告诉我们:一只木桶能盛多少水,并不取决于最长的那块木板,而是取决于最短的那块木板,这就是著名的短板原理。
因此,增强对数据中心网络的创新,与AI时代齐头并进,让网络不会成为大模型发展的短板,甚至成为一块“长板”,这对大模型的整体发展,尤为关键。
当然,反向的逻辑依然成立,正是AI 大模型时代的迅猛发展,也给网络带来了新的机遇与挑战:随着 GPU 算力的持续提升,GPU 集群网络架构也需要不断迭代升级。
客观地说,网络之所以关注度低的原因,也在于整个业界有能力在数据中心网络技术上做持续创新的企业并不多,而华为则是其中最重要的创新力量。如华为智能无损AI网络解决方案,凭借AI场景下的数据中心网络“0丢包、低时延、高吞吐”的特质,成为了很多数据中心用户的首选。目前,华为智能无损AI网络已经在国内数十个人工智能计算中心规模商用部署,让算力如同走上了“黄金水道”,顺流而下,价值实现最大化。