前言
阅读本文需要有一定正则表达式基础 正则表达式基础教程 ,和编译原理的基础。有使用过VUE的伙伴可能知道vue是自定了模版解析编译器的,vue用的是标准的AST语法树统计,如果对语法树不了了解的请查看 什么是AST抽像语法树
本示例介绍的是参考编译原理 词法分析->语法分析->构建AST语法树->解析成目标sql 的流程来实现
示例
sqlserver 的一条查询语句
select a.UniqueCode,a.BarCode,a.CategoryId from GD_UniqueCodeInfo as a
假如我们要将以上代码进行格式化成以下方式
select [a].[UniqueCode],[a].[BarCode],[a].[CategoryId] from [GD_UniqueCodeInfo] as [a]
分析
首先我们来分析一下这个语句有什么特点。
- 找关键词这个sql语法有三个关键词如 select , from , as
- 找结构有字段信息 a.UniqueCode,a.BarCode,a.CategoryId ,有表名信息 GD_UniqueCodeInfo 还有 重命名的表信息 a 这些信息可能符合命名规范可能有些不符合,那么在解析时都要进行检测出来
- 标识符在生成的目标sql语句中有[] 这个的作用主要是万一字段名称出现与关键词有相同的字段名称能进行正常识别
开始
首先我们先创建两个c#解析正则表达式的方法
这个方法就是可以将正则表达式中的匹配数据提出来返回一个字典数据
public static Dictionary<string, string> RegexGrp(string regex,string text)
{
Regex _regex = new Regex(regex, RegexOptions.IgnoreCase | RegexOptions.Multiline);
Dictionary<string, string> _dic = new Dictionary<string, string>();
Match _match = _regex.Match(text);
while (_match.Success)
{
foreach (string name in _regex.GetGroupNames())
{
if(!_dic.ContainsKey(name))
_dic.Add(name, _match.Groups[_regex.GroupNumberFromName(name)].Value);
}
_match = _match.NextMatch();
}
return _dic;
}
检测正则表达工是否正确匹配
public static bool RegexMatch(string regex, string text)
{
Regex _regex = new Regex(regex, RegexOptions.IgnoreCase | RegexOptions.Multiline);
Match _match = _regex.Match(text);
return _match.Success;
}
第一步 先检测这个sql语句是否是一个查询语句
正则代码: ^\s*(?<cmd>select)\s+(?<field>[\w\s\S]+(?=\bfrom\b))(?:\bfrom\b)(?<from>(?:[\s]+)(?<flag>[\#]{1,2}|[\@]{1})?(?<tab>[\w]+)\s*[\s\w\S]*)
那么我们来验证下通过把要解析的SQL语句放入测试工具中运行
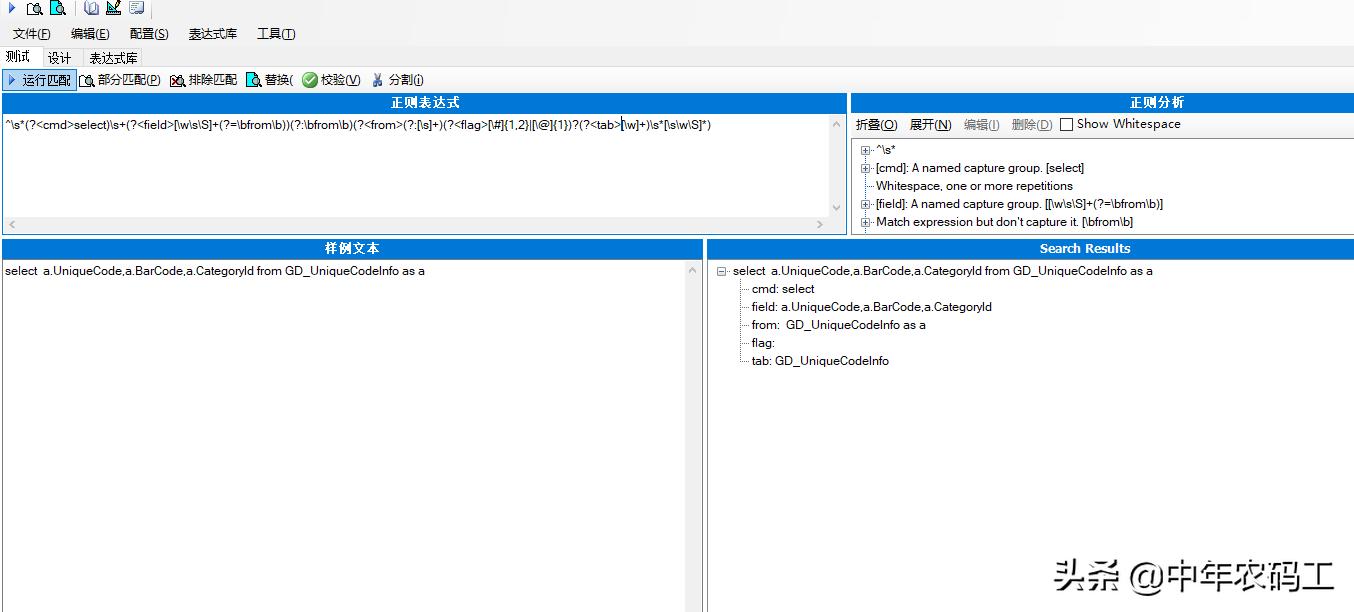
在右下方的区域通过正则匹配已经把该语句结构已经拆解出来了cmd: select field: a.UniqueCode,a.BarCode,a.CategoryId tab: GD_UniqueCodeInfo
一下就把SQL语句结构化出来了,有匹配结果说明是一个正常的sql语句
第二步 通过代码获取结构信息
string sql="select a.UniqueCode,a.BarCode,a.CategoryId from GD_UniqueCodeInfo as a";
Dictionary<string, string> dic =RegexGrp(@"^\s*(?<cmd>select)\s+(?<field>[\w\s\S]+(?=\bfrom\b))(?:\bfrom\b)(?<from>(?:[\s]+)(?<flag>[\#]{1,2}|[\@]{1})?(?<tab>[\w]+)\s*[\s\w\S]*)",sql);
if(dic.ConstainsKey("cmd"))
{
// 说明匹配成功
Console.Write(dic["cmd"]);
}
拆解select 后要把select 替换为空剩余的sql 为 a.UniqueCode,a.BarCode,a.CategoryId from GD_UniqueCodeInfo as a
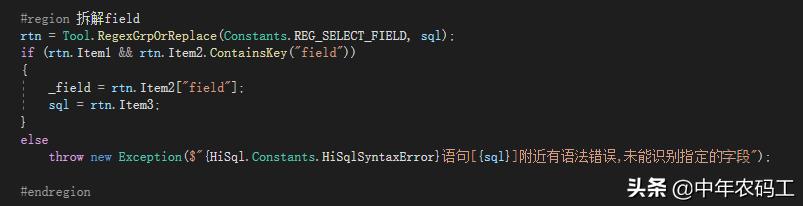
第三步 拆解字段
正则表达式: ^\s*(?<field>[\w\s\S]*?(?=\bfrom\b)) 两人通过测试工具测试一下
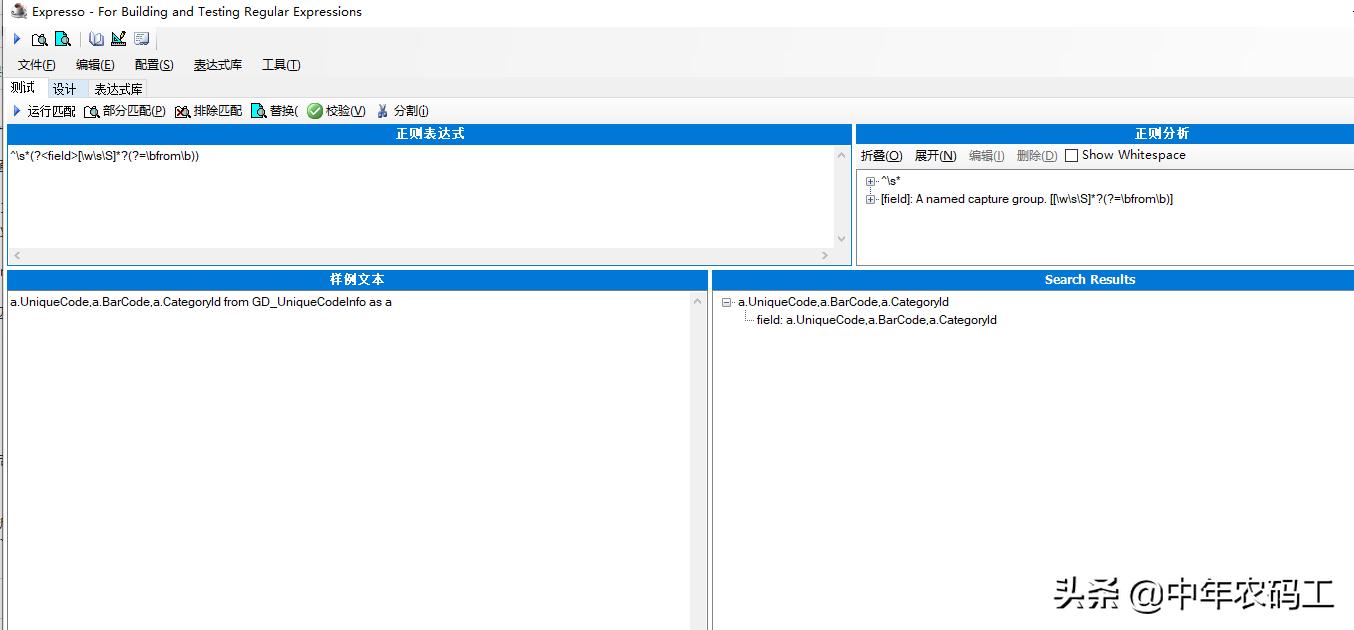
那么就可以通过代码获取出来
string sql="a.UniqueCode,a.BarCode,a.CategoryId from GD_UniqueCodeInfo as a";
Dictionary<string, string> dic =RegexGrp(@"^\s*(?<field>[\w\s\S]*?(?=\bfrom\b))",sql);
if (dic.ContainsKey("field"))
{
//说明匹配成功
}
字段是有多个的 还要单独拆解成一个一个的字段,拆解字段的这个就不详细描述了,可以继续用正则表达式也可以用Split(',') 进行分拆如
var _field=dic["field"];
var fields=_field.Split(',')
拆解完字段后 剩余的sql: from GD_UniqueCodeInfo as a
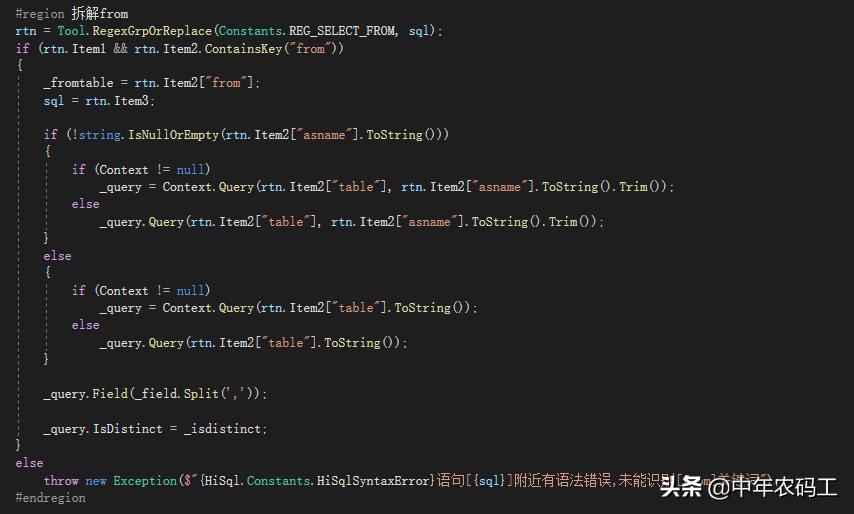
拆解from
正则表达式: ^\s*(?:\bfrom\b)(?<from>(?:[\s]+)(?<table>(?:[\s]*)(?<flag>[\#]{1,2}|[\@]{1})?(?<tab>[\w]+))\s*(?:\bas\b\s*(?<asname>[\w]+))?\s*) 通过该正则表达式可以拆解出 通过 as 重命名的表下面通过正则表达式工具测试一下
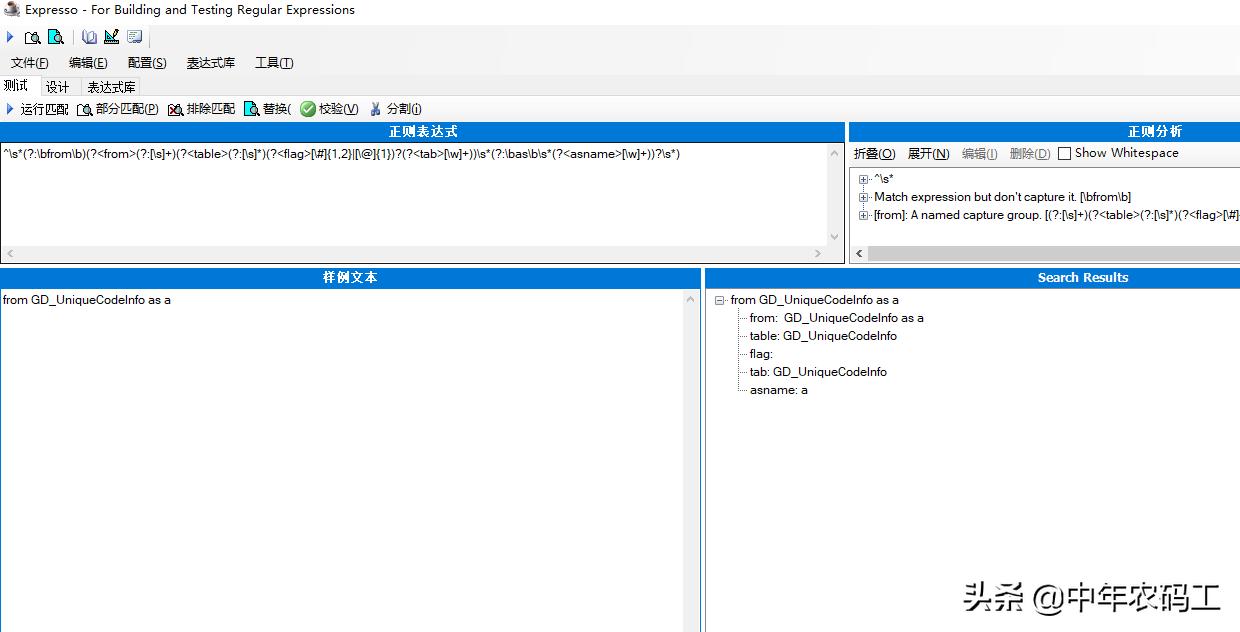
那么通过以下代码来获取
string sql="from GD_UniqueCodeInfo as a";
Dictionary<string, string> dic =RegexGrp(@"^\s*(?:\bfrom\b)(?<from>(?:[\s]+)(?<table>(?:[\s]*)(?<flag>[\#]{1,2}|[\@]{1})?(?<tab>[\w]+))\s*(?:\bas\b\s*(?<asname>[\w]+))?\s*)",sql);
if (dic.ContainsKey("tab"))
{
//说明匹配成功
}
此时 就算通过正则表达式拆解完成,但还需要对它进行结构化
以下是代码截图片段
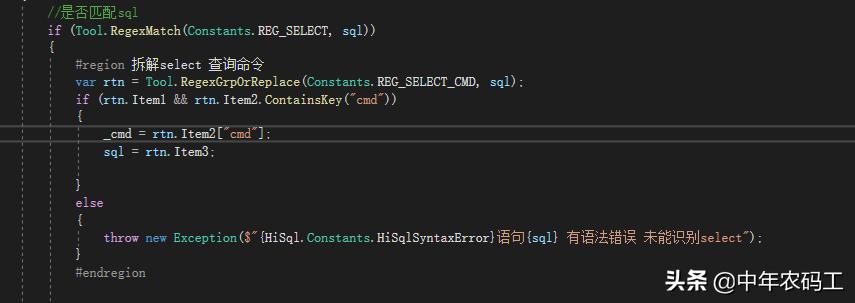
结果
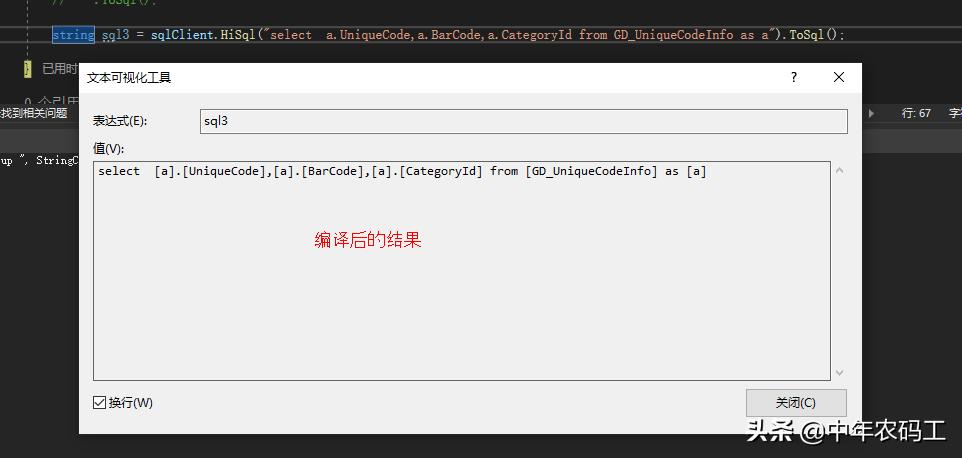
请查看demo代码:https://gitee.com/dotnetlowcode/hisql/blob/master/HiSql.SqlServerUnitTest/Demo_Query.cs