点击上方关注,All in AI中国
作者——Skander Hannachi, Ph.D
时间序列预测在数据科学领域是一匹黑马:它是商业中应用最广泛的数据科学技术之一,广泛用于金融、供应链管理以及生产和库存计划,它有一个良好的理论基础统计和动态系统理论。然而,与最近和流行的机器学习主题(如图像识别和自然语言处理)相比,它仍保持着某种局外人的地位,在数据科学和机器学习的入门课程中,它几乎没有或根本没有得到任何处理。

我最初的训练是在神经网络和其他机器学习方法中进行的,但在我的职业生涯引导我成为需求预测专家的角色之后,我更倾向于时间序列方法。
最近几周,我与经验丰富的ML工程师进行了几次讨论,他们非常擅长ML,但是对时间序列方法没有多少经验。
从这些讨论中我意识到,时间序列预测中有一些特定的事情,在预测领域被认为是理所当然的,但对其他ML实践者和数据科学家来说非常令人惊讶,特别是与标准ML问题的处理方式相比时。
这种脱节的症结是,时间序列预测可以作为监督学习问题,因此ML方法的整个库——回归、神经网络、支持向量机、随机森林、XGBoost等都可以利用它。但与此同时,时间序列预测问题有几个独特的怪癖和特质,使它们与监督学习问题的典型方法区别开来,这需要ML工程师重新思考他们建立和评估模型的方法。
根据我最近的讨论,以下是ML从业人员在应对预测挑战时遇到的3个最大惊喜:
每次要生成新预测时,你都需要重新训练模型:
对于大多数ML模型,需要训练、测试它,必要时重新训练,直到你获得满意的结果,然后在数据集上进行评估。在对模型的性能感到满意后,将其部署到生产中。一旦投入生产,你将获得新数据。在几个月后,如果有大量新训练数据进入,你可能需要更新的模型。模型训练是一次性活动,或者最多在不超过一定时间间隔的情况下进行,以保持模型的性能并获取int帐户的新信息。
对于时间序列模型来说,情况并非如此。相反,我们每次想要生成新的预测时都必须重新训练我们的模型。为了理解为什么会发生这种情况,请参考以下示例:
我们将使用ARIMA模型来预测澳大利亚季度啤酒销售(数据集来自Hyndman的R预测包)。 首先,我们将研究1956年至1970年的数据模型,然后根据1970年至1973年的数据对其进行测试。使用季节性ARIMA(1,1,1)(0,1,1)模型,我们可以获得相当好的预测( MAPE = 1.94%)(图1)。
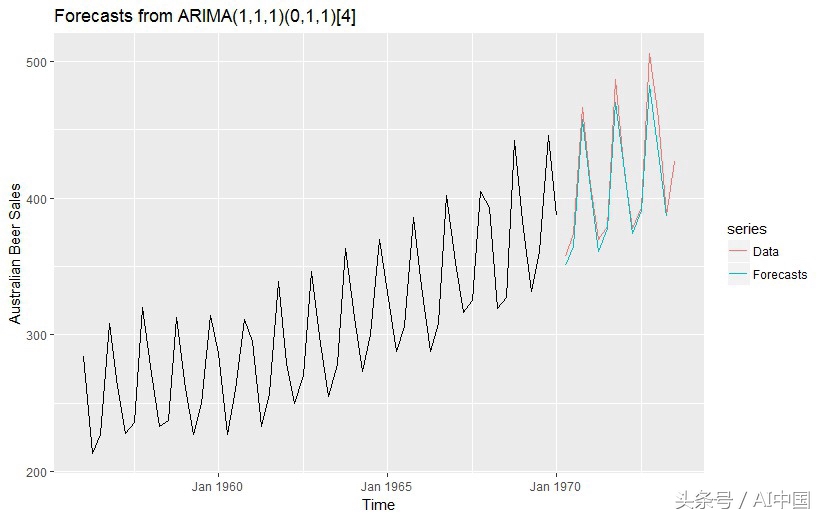
接下来,我们将使用相同的模型预测直到1993年的销售情况。你可以在图2中看到预测不再那么好:预测继续遵循1970〜1973年的相同模式,但是实际情况已经发生了变化 - 从1956年到1974年,我们可以看到恒定趋势在1974年开始逐渐减少,季节变化的幅度也开始变化。如果你使用相同的ARIMA(1,1,1)(0,1,1)来预测1990年至1993年的销售额,你将获得更差的准确度(MAPE = 44.92%)。
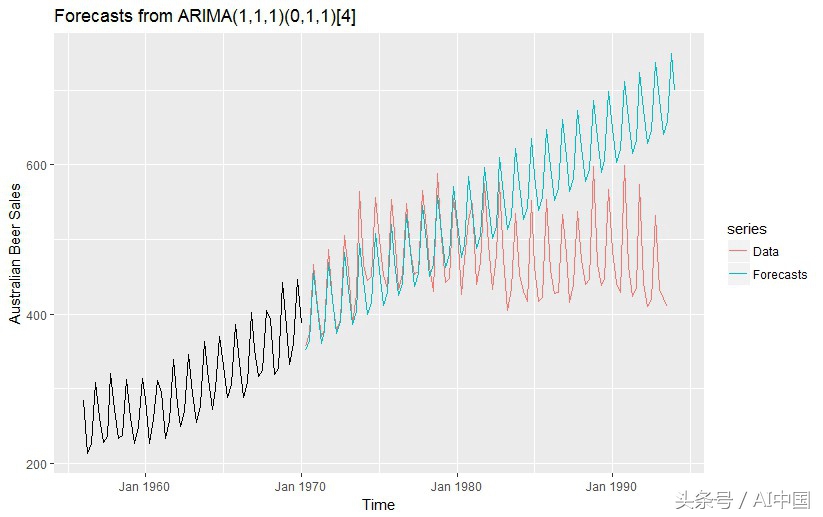
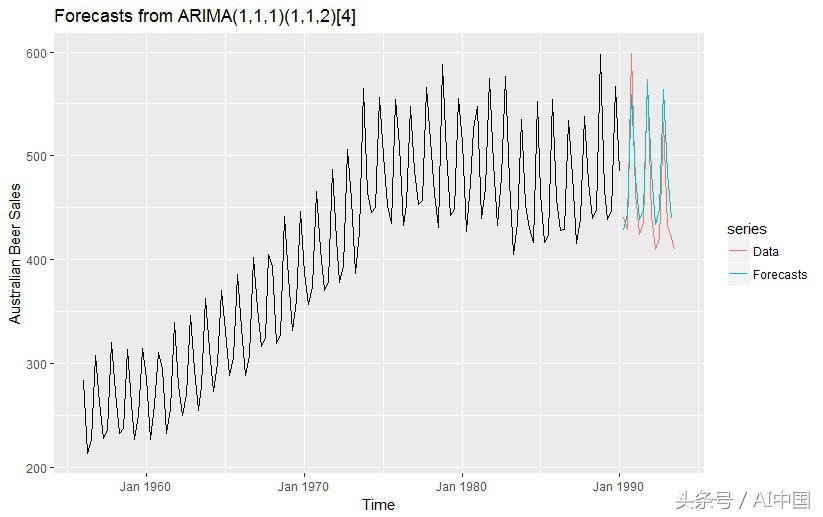
相反,我们必须重新安装第二个模型,该模型考虑了新数据和销售模式的变化。这一次,我们将对1956年至1990年的数据进行ARIMA(1,1,1)(1,1,2)模型的训练,并用它来预测1990〜1993年的数值。然后我们将得到一个更合理的MAPE值,它接近我们在第一个实验中获得的结果(MAPE = 5.22%)。
为了直观地了解这种情况发生的原因,首先考虑一个经典的ML任务:对猫图像进行分类。猫的视觉特性随着时间的推移是稳定的(除非我们开始研究进化的时间尺度),所以当我们训练神经网络识别猫的图片时,隐含的假设是:定义猫的特征将在可预见的未来保持不变。我们不希望猫在下周、明年、甚至十年后变得不同。有了足够的数据,我们训练的模型在可预见的未来也会足够好。
用统计学的说法,我们说猫图像特征的分布是一个平稳的分布,这意味着它的平均值和标准差等特性随着时间的推移保持不变。
现在回想一下,在ML项目中,当开发数据集的分布和生产数据集的分布不同时,会出现一个常见的陷阱,导致模型在生产中失败。对于时间序列来说,几乎总会有这样的情况,开发数据集和生产数据集不是来自同一分布,因为现实世界的业务时间序列(例如澳大利亚啤酒销售)数据不是固定的,当新的实际情况进入统计数据时,属性将不断变化。
解决这个问题的唯一方法是每次获得新数据时都重新训练模型。请注意,这与持续学习不同,在持续学习中,已经训练的模型随着新数据的进入而更新。实际上,每当你想要生成新预测时,你都是在从头开始重新训练新模型(尽管这将是一个有趣的研究课题,看看连续学习是否可以应用于时间序列预测)。
从实际的角度来看,这意味着将预测算法部署到生产中与部署其他ML模型非常不同。你不能仅仅部署静态模型并对其进行评分,模型服务的概念对时间序列预测没有意义。相反,你需要确保训练和模型选择可以在生产中及时完成,并且你必须确保你的整个训练集可以在生产中存储和处理。这让我想到了第二点:
有时候,你不得不放弃训练/测试划分:
让我们回到找到ML模型的基本方法:通常使用训练集构建模型,然后在测试集上进行评估。这要求你有足够的数据来预留一个测试集,并且仍然有数据来构建模型。但是与图像处理或NLP中使用的数据集相比,时间序列数据通常非常小。在给定位置的产品中其每周销售数据仅为104个数据点(几乎不足以捕获任何季节性)。花费10年采用的季度经济指标数据仅为40个数据点。由于数据集很小,我们没有能力为测试目的留出20%或30%的数据。交叉验证也没有多大帮助,因为根据你想要使用的算法,CV最适合设置时间序列模型,但在最糟糕的情况下它根本根本不适用。
因此,我们转而采用信息标准,如AIC、AICc或BIC。这些是模型选择指标,它本质上是试图通过分析来近似测试步骤。我们的思路是,我们没有经验的方法来确定模型的泛化误差,但我们可以通过使用信息理论考虑来估计这个误差。
在实践中,我们训练一组预先确定的模型,并选择具有最低AIC或BIC的模型。除了允许使用具有有限数据的训练模型之外,当我们想要自动化预测生成时,使用这样的模型选择标准是非常方便的。例如,在零售业中,我们必须为数百万个单独的时间序列生成预测,这并不罕见——一个大型的回收器将在几个地点运送20K~30K产品,从而产生数百万个单独时间序列(每个产品/位置组合一个)。
在这种情况下,每个单独的数据集都很小,但是你必须处理数百万个数据集,因此分析师或工程师无法对每个系列的测试集执行评估,自动化模型选择变得至关重要。
许多预测工具都使用这种方法:Rob Hyndman在R(1)中流行的预测包使用AIC在其auto.arima和ets函数中进行模型选择,许多商业需求预测应用程序(如Oracle的RDF)使用用于模型选择的BIC。
预测的不确定性与预测本身一样重要,甚至更重要:
将预测与其他监督学习任务区分开来的另一个原因是你的预测几乎总是错误的。处理图像分类问题或NLP问题的人可以合理地期望最终能准确地对所有新传入的示例进行分类——给定足够的训练数据的情况下。你所要做的就是确保你的训练数据和真实世界数据是从同一分布中采样的。正如我的第一点和第二点所述,业务预测应用程序通常不是这种情况,所以你的预测几乎总是错误的。你能准确预测下周将要销售多少款M红色阿迪达斯衬衫吗?因此,你所需要的不仅仅是一个点的预测,还需要衡量预测的不确定性。
在需求预测和库存应用中,预测的不确定性对于使用预测的应用程序至关重要。你预测的不确定性(由预测间隔或预测分位数表示)将用于计算你的安全库存,即你想要携带的额外库存量,以确保你不会丢失任何客户。
他们将这一想法在金融时间序列建模中更进了一步,他们实际上有一些模型专门用于建模时间序列的不确定性,而不是时间序列本身,如ARCH和GARCH模型。
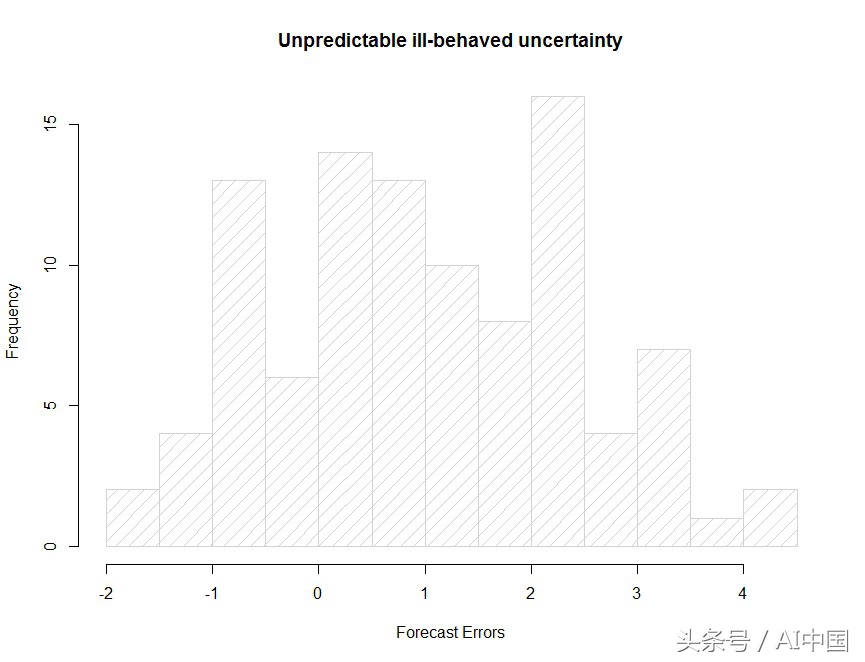
Maridakis等人(3)谈到地铁的不确定性和椰子的不确定性。椰子的不确定性,暗指椰子意外落在海滩上的某人的头上是"未知的未知数"的不确定性,无论我们多么努力,这些事件都是无法预测的。
更一般地说,一些时间序列表现出不可预测的、不正常的不确定性。预测误差的分布不遵循任何已知的分布。此类信息对于做出判断性决策很有用,但无法用于建模和预测。
另一方面,地铁的不确定性(暗示了地铁从A到B需要多长时间的不确定性)遵循已知的分布,例如正态分布或泊松分布,并且可以建模和用于将预测限制在一定范围内,即使无法预测确切的值。

那些习惯于在其他ML领域实现极高准确度的人,更重要的是,那些陷入当前的机器学习热潮中的决策者和商业领袖们,需要明白,通常我们用时间序列模型实现的最好的是地铁的不确定性。 如果我们能够找到正确的算法和正确的数据,找到足够深的神经网络或足够丰富的非结构化数据集,我们将能够实现更好的预测,这种信念是危险的误导。有时,我们能得到的最好结果是可控制的不确定性——我们应该相应地构建我们的数据管道和决策支持系统。
参考文献:
(1)https://cran.r-project.org/web/packages/forecast/forecast.pdf
(2)Hastie,Tibshirani,Friedman,统计学习要素,第7章(第228-229页)
(3)Makridakis,S.,Hogarth,R.M。 &Gaba,A。(2009)经济和商业世界的预测和不确定性。国际预测杂志
