背景
无论是互联网应用或者企业级应用,都充斥着大量的批处理任务。我们常常需要一些任务调度系统帮助我们解决问题。随着微服务化架构的逐步演进,单体架构逐渐演变为分布式、微服务架构。在此的背景下,很多原先的任务调度平台已经不能满足业务系统的需求。于是出现了一些基于分布式的任务调度平台。这些平台各有其特点,但各有不足之处,比如不支持任务编排、与业务高耦合、不支持跨平台等问题。不是非常符合公司的需求,因此我们开发了微服务任务调度平台(SIA-TASK)。
SIA是我们公司基础开发平台Simple is Awesome的简称,SIA-TASK(微服务任务调度平台)是其中的一项重要产品,SIA-TASK契合当前微服务架构模式,具有跨平台,可编排,高可用,无侵入,一致性,异步并行,动态扩展,实时监控等特点。
项目简介
SIA-TASK是任务调度的一体式解决方案。对任务进行元数据采集,然后进行任务可视化编排,最终进行任务调度,并且对任务采取全流程监控,简单易用。对业务完全无侵入,通过简单灵活的配置即可生成符合预期的任务调度模型。
SIA-TASK借鉴微服务的设计思想,获取分布在每个任务执行器上的任务元数据,上传到任务注册中心。利用在线方式进行任务编排,可动态修改任务时钟,采用HTTP作为任务调度协议,统一使用JSON数据格式,由调度中心进行时钟解析,执行任务流程,进行任务通知。
关键术语
- 任务(Task): 基本执行单元,执行器对外暴露的一个HTTP调用接口;
- 作业(Job): 由一个或者多个存在相互逻辑关系(串行/并行)的任务组成,任务调度中心调度的最小单位;
- 计划(Plan): 由若干个顺序执行的作业组成,每个作业都有自己的执行周期,计划没有执行周期;
- 任务调度中心(Scheduler): 根据每个的作业的执行周期进行调度,即按照计划、作业、任务的逻辑进行HTTP请求;
- 任务编排中心(Config): 编排中心使用任务来创建计划和作业;
- 任务执行器(Executer): 接收HTTP请求进行业务逻辑的执行;
- Hunter:Spring项目扩展包,负责执行器中的任务抓取,上传注册中心,业务可依赖该组件进行Task编写。

微服务任务调度平台的特性
- 基于注解自动抓取任务,在暴露成HTTP服务的方法上加入@OnlineTask注解,@OnlineTask会自动抓取方法所在的IP地址,端口,请求路径,请求方法,请求参数格式等信息上传到任务注册中心(zookeeper),并同步写入持久化存储中,此方法即任务;
- 基于注解无侵入多线程控制,单一任务实例必须保持单线程运行,任务调度框架自动拦截@OnlineTask注解进行单线程运行控制,保持在一个任务运行时不会被再次调度。而且整个控制过程对开发者完全无感知。
- 调度器自适应任务分配,任务执行过程中出现失败,异常时。可以根据任务定制的策略进行多点重新唤醒任务,保证任务的不间断执行。
- 高度灵活任务编排模式,SIA-TASK的设计思想是以任务为原子,把多个任务按照执行的关系组合起来形成一个作业。同时运行时分为任务调度中心和任务编排中心,使得作业的调度和作业的编排分隔开来,互不影响。在我们需要调整作业的流程时,只需要在编排中心进行处理即可。同时编排中心支持任务按照串行,并行,分支等方式组织关系。在相同任务不同任务实例时,也支持多种调度方式进行处理。
微服务任务调度平台设计
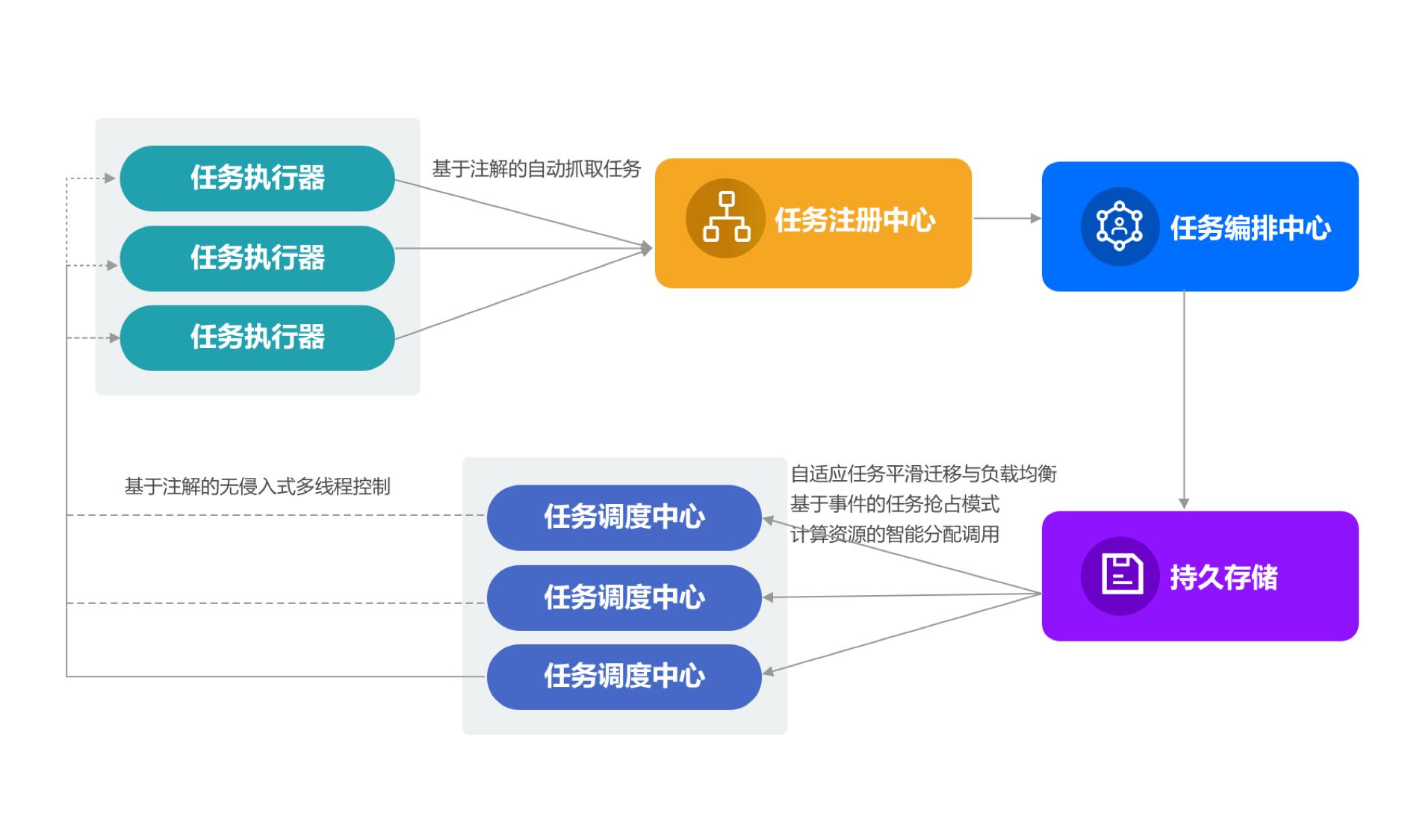
SIA-TASK主要分为五个部分:
- 任务执行器
- 任务调度中心
- 任务编排中心
- 任务注册中心(zookeeper)
- 持久存储(Mysql)
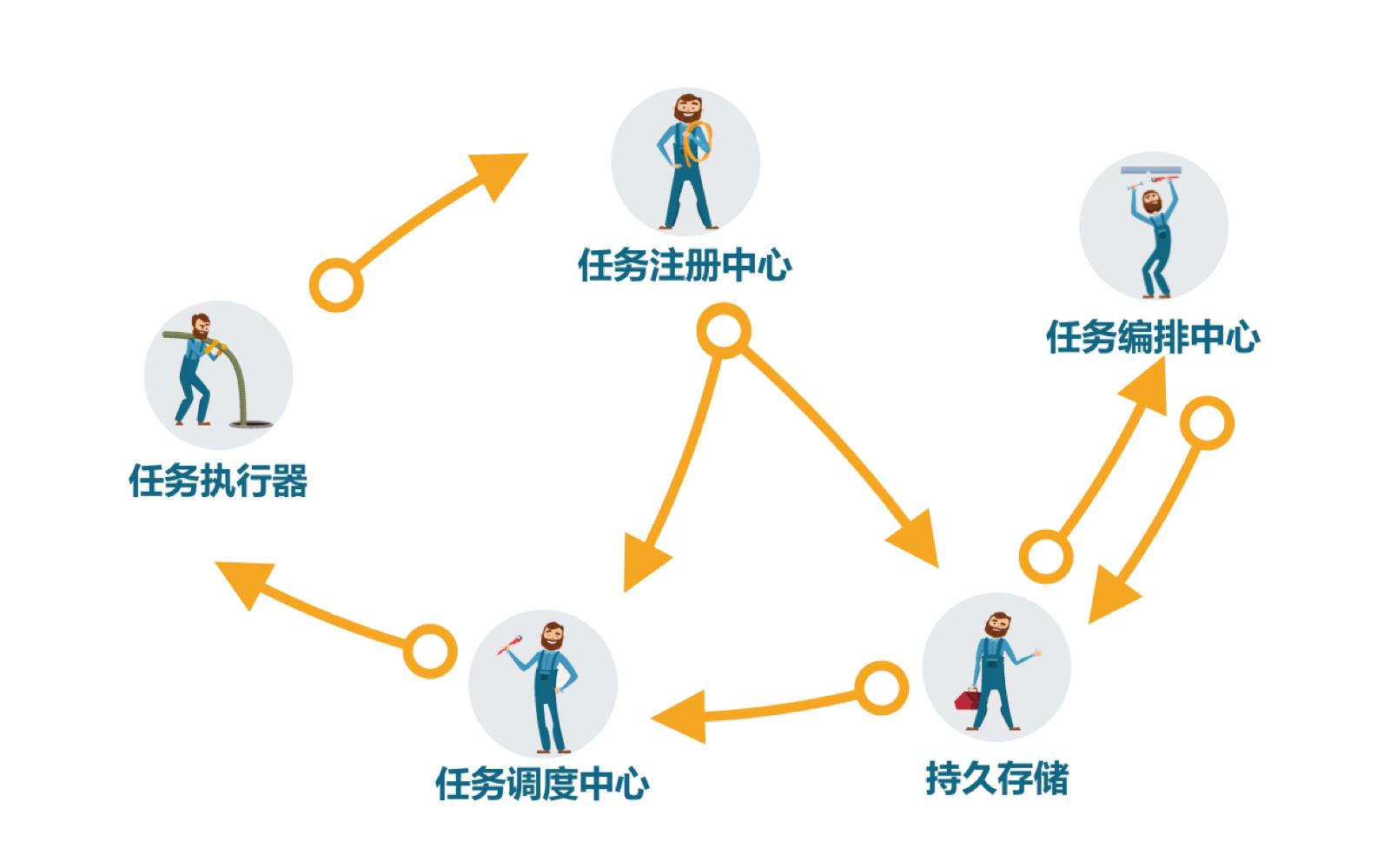
SIA-TASK的主要运行逻辑:
- 通过注解抓取任务执行器中的任务上报到任务注册中心
- 任务编排中心从任务注册中心获取数据进行编排保存入持久化存储
- 任务调度中心从持久化存储获取调度信息
- 任务调度中心按照调度逻辑访问任务执行器
UI预览
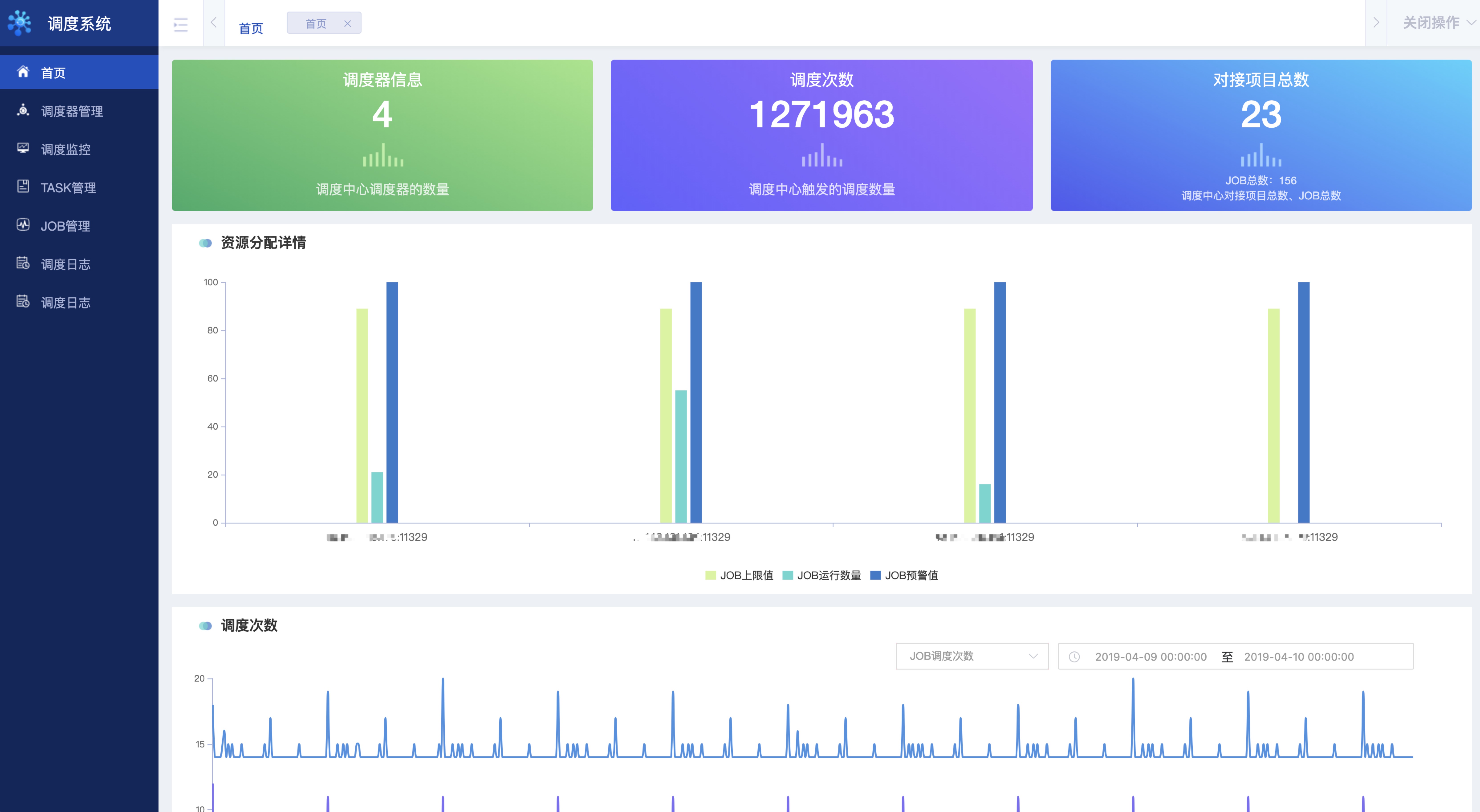
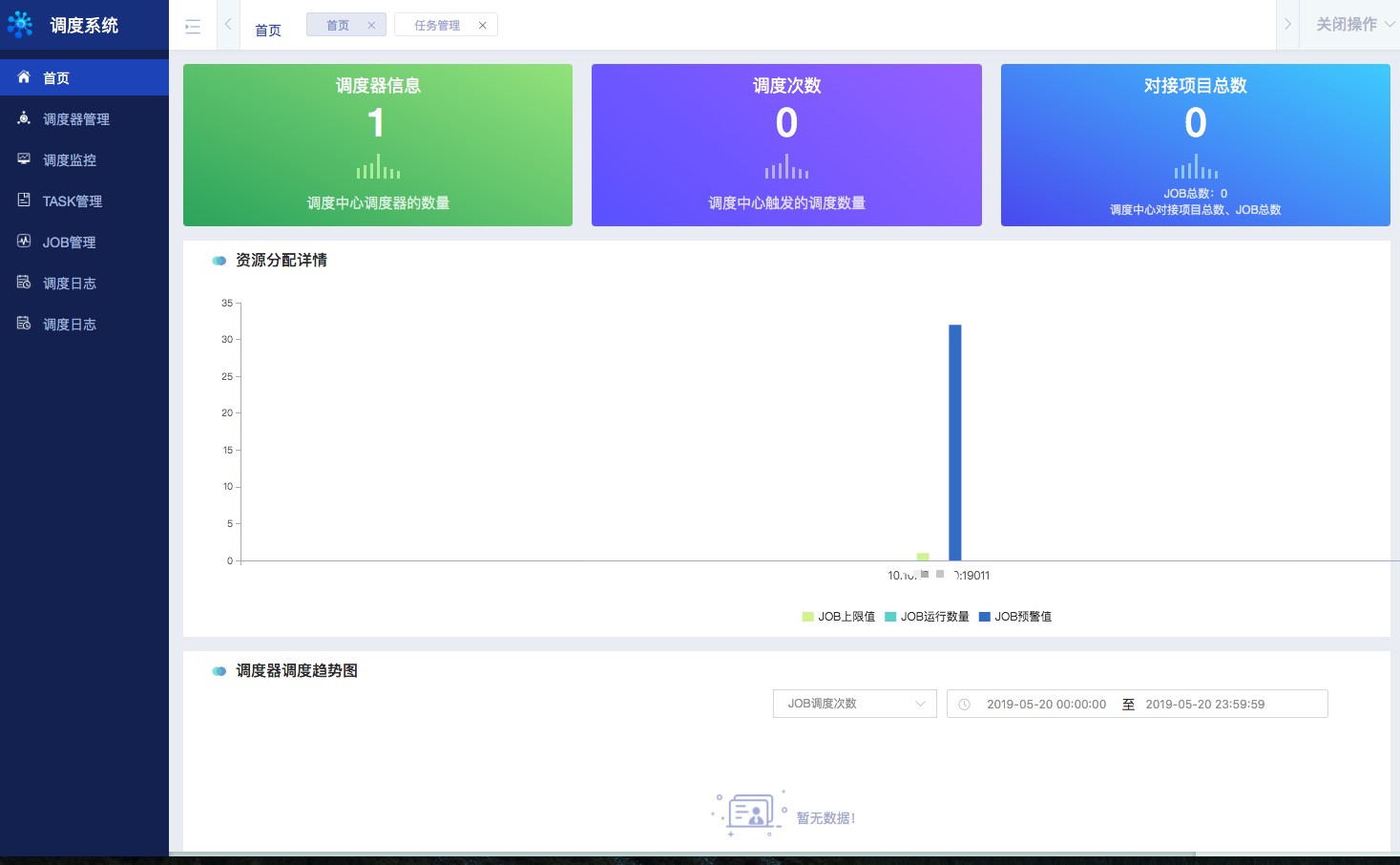
首页提供多维度监控
- 调度器信息:展示调度器信息(负载能力,预警值),以及作业分布情况。
- 调度信息:展示调度中心触发的调度次数,作业、任务多维度调度统计。
- 对接项目统计:对使用项目的系统进行统计,作业个数,任务个数等等。
调度监控提供对已提交的作业进行实时监控展示
- 作业状态实时监控:以项目组为单位面板,展示作业运行时状态。
- 实时日志关联:可以通过涂色状态图标进行日志实时关联展示。
任务管理:提供任务元数据的相关操作
- 任务元数据录入:手动模式的任务,可在此进行录入。
- 任务连通性测试:提供任务连通性功能测试。
- 任务元数据其他操作:修改,删除。
Job管理:提供作业相关操作
- 任务编排:进行作业的编排。
- 发布作业: 作业的创建,修改,以及发布。
- 级联设置:提供存在时间依赖的作业设置。
日志管理
Log Manager
微服务任务调度平台使用指南
一、任务调度首页
任务调度管理首页主要包括三部分:调度器信息、调度次数、对接项目详情
- 调度器信息:调度中心调度器的数量
- 调度次数:调度中心调度Job的历史累计总数
- 对接项目详情:调度中心对接的项目组总数,Job总数
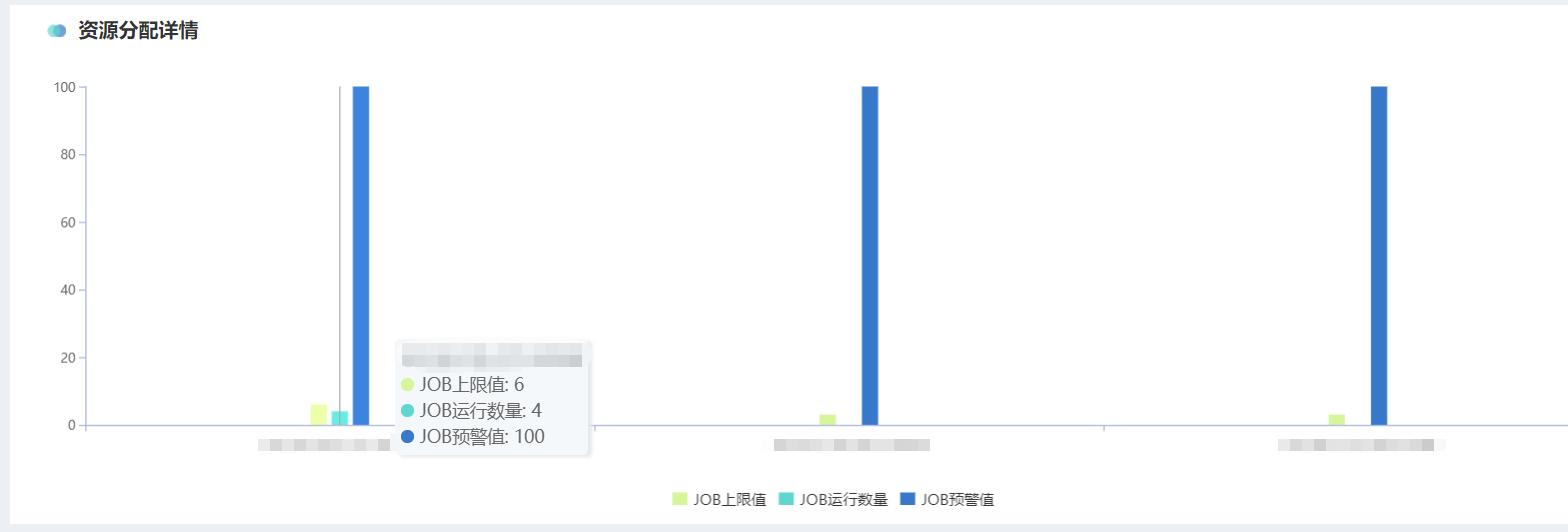
1.1 调度器信息
点击调度器信息,显示资源分配详情界面,如下图所示:
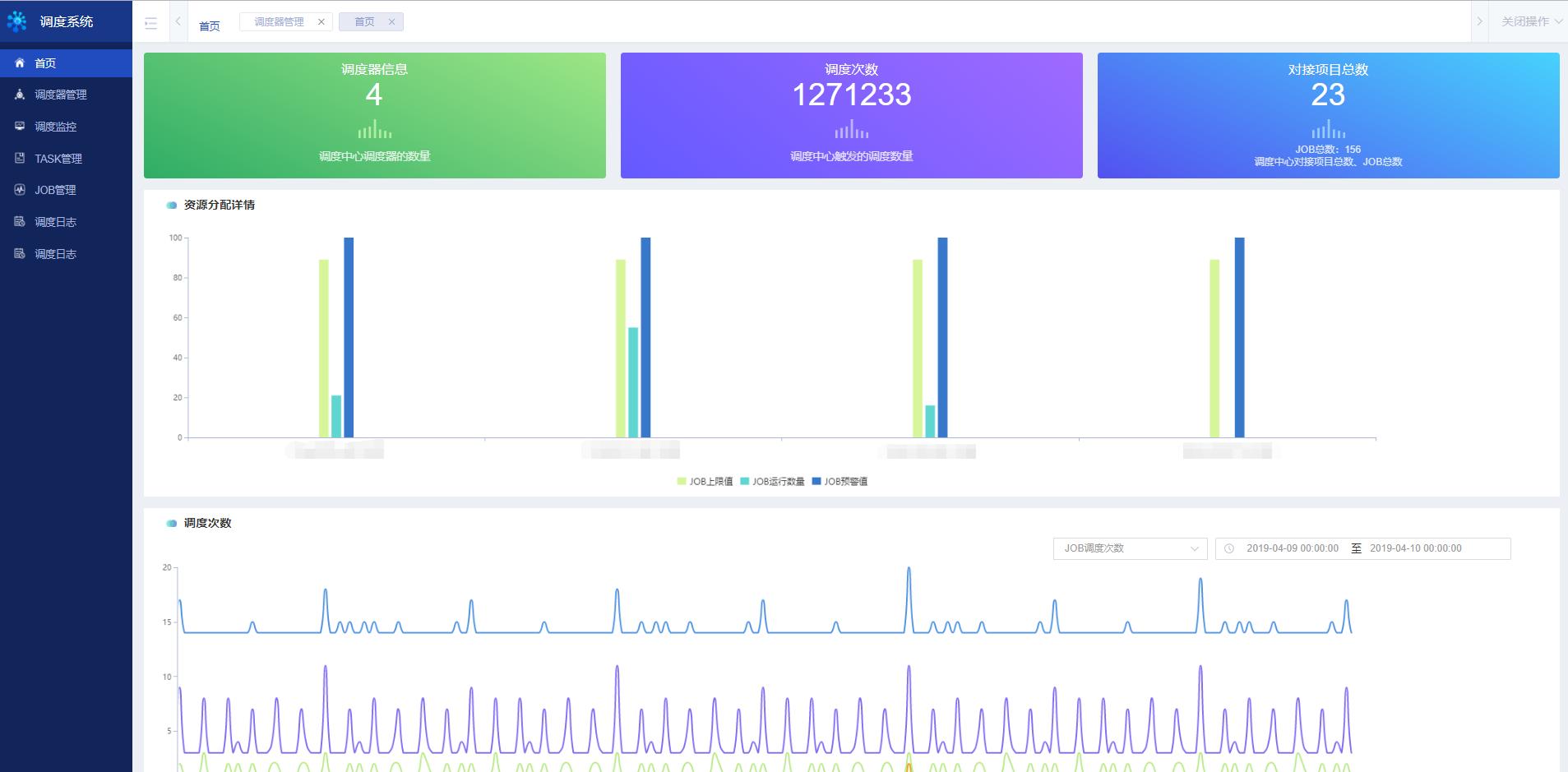
每台调度器有三个具体指标:
- Job上限值:所能负载的Job动态阈值;
- Job运行数量:该调度器当前运行的Job数量;
- Job预警值:当调度器运行的Job数超过预警值时,会发邮件通知管理员。
鼠标悬浮至某台调度器上方即可显示。
1.2 调度次数
点击调度次数,即可显示调度器的调度详情,共计两个图表:
- 调度器调度趋势图
- 任务调度状态统计
1.2.1 调度器调度趋势图
调度器调度趋势图表示各个调度器执行Job或Task调度次数的实时数据统计,便于观察某段时间内调度器的调度状况。
- 通过下拉框可选择Job调度次数或Task调度次数;
- 选上时间范围即可显示相应图表;
- 图表下方为各个调度器具体实例,点击可显示或隐藏
1.2.2 任务调度状态统计
任务调度状态统计表示所有调度器的历史调度信息
- 可按Job或Task分别显示出异常和已完成的历史累计数据;
- 选择时间区间后,可通过下拉框选择查看全部或某个调度器的任务调度详情;
- 可通过下拉框选择Job或是Task任务调度详情;
- 点击下方异常或已完成按钮,可显示或隐藏相应图线。
1.3 对接项目详情
点击对接项目详情,会显示微服务任务调度平台对接的项目组详情,如下图示:
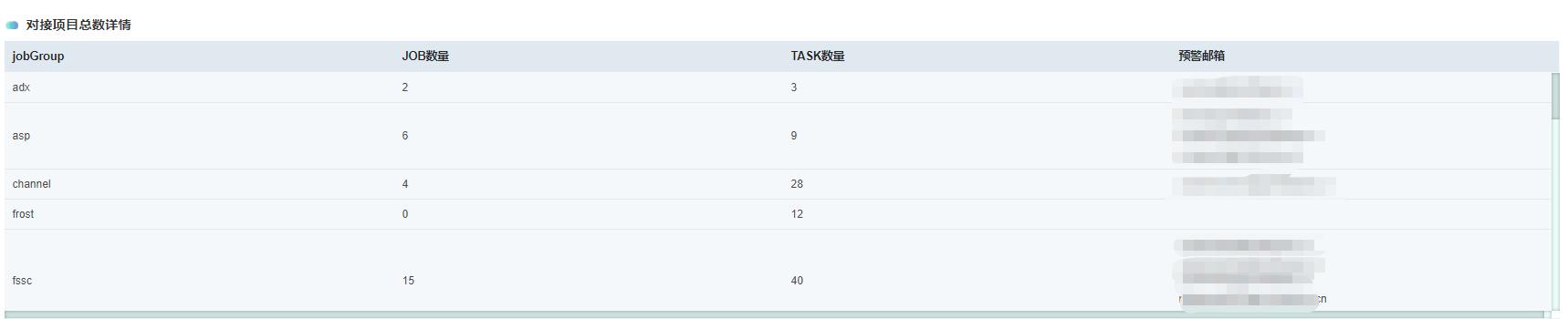
- jobGroup:对接的项目组名称
- Job数量:对接的项目组配置的Job数
- Task数量:对接的项目组自动或手动配置的Task数
- 预警邮箱:对接项目组的联系人列表
便于管理员能够迅速了解调度中心对接项目组的整体情况。
二、调度器管理
点击左边栏中调度器管理,会进入调度器管理界面,默认显示资源分配详情界面,如下图所示:
图中显示各个调度器简要信息,点击某个调度器(柱状图),会显示该调度器所抢占的Job详情列表:
- jobKey:所配置的Job名称
- 类型:配置Job的定时任务类型,分为Cron与fixRate两类
- job类型值:Cron表达式
- 预警邮箱:该Job配置的预警邮箱
- 描述信息:描述该Job的功能信息
便于管理员能够迅速发现某台调度器所抢占的Job详情。
在该界面上方点击调度器管理,会显示如下界面,分为以下几项:
- 工作调度器:
该类调度器具有抢占和调度Job的能力。对某调度器进行下线操作,它会立即失去抢占Job的能力,其已经抢占的Job执行完毕后会自动释放,进而被其他调度器抢占,该调度器下线后会进入下线调度器列表中;工作调度器列表提供下线以及批量下线的功能;
- 下线调度器:
该类调度器进程仍然存活,但失去了抢占Job与参与调度的能力。对该类调度器执行上线操作,其会进入工作调度器列表,且开始具有抢占和调度Job的能力;下线调度器列表提供上线及批量上线的功能;
- 离线调度器:
该类调度器进程不再存活,当下线调度器进程死亡后,会自动进入离线调度器列表,该类调度器进程重新启动后,会自动进入下线调度器列表;离线调度器列表也提供删除及批量删除的功能;
- 白名单:
将某个IP加入白名单之后,其具有调用所有执行器实例的权限;白名单列表提供批量删除的功能,删除该IP后自动失去该权限
三、调度监控
点击左边栏调度监控,会出现调度监控界面,如下图所示:
- 标号1:表示任务概览,分别为准备中、正在运行中、已停止、异常停止的Job数,以及项目汇总数量,Task汇总数量和Job汇总数量。
- 标号2:输入项目组名可实现按项目组过滤;
- 标号3:某个项目组的调度监控概览,包括该项目组的已激活Job数,异常停止Job数,Job总数以及Job列表详情;
- 标号4:可直接关联到对应Job的运行日志详情,如下图所示:
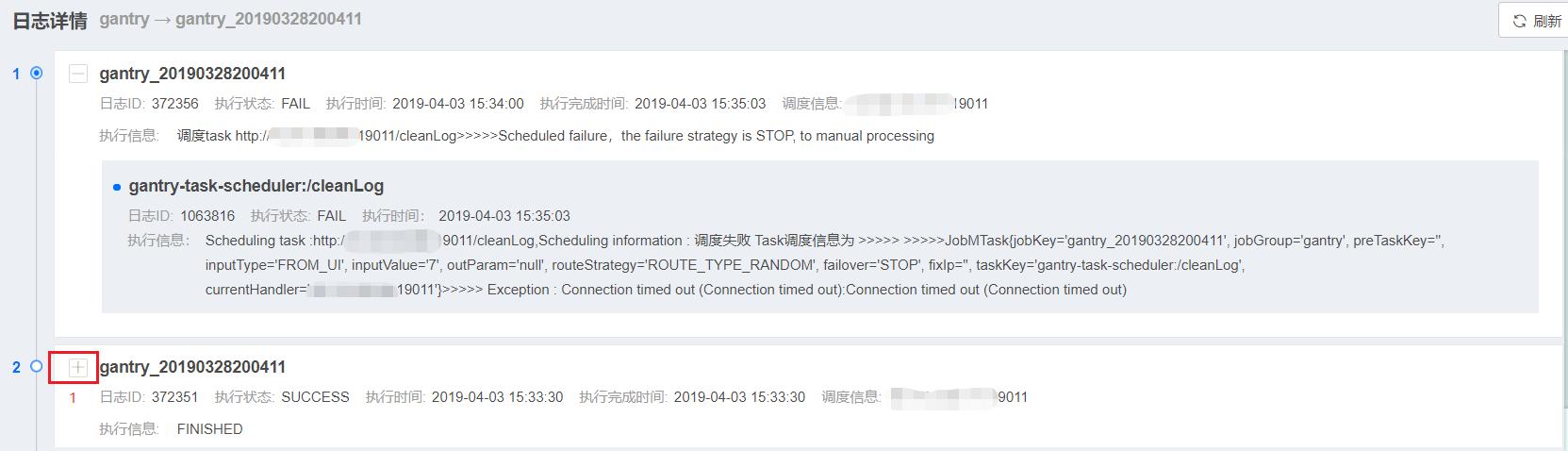
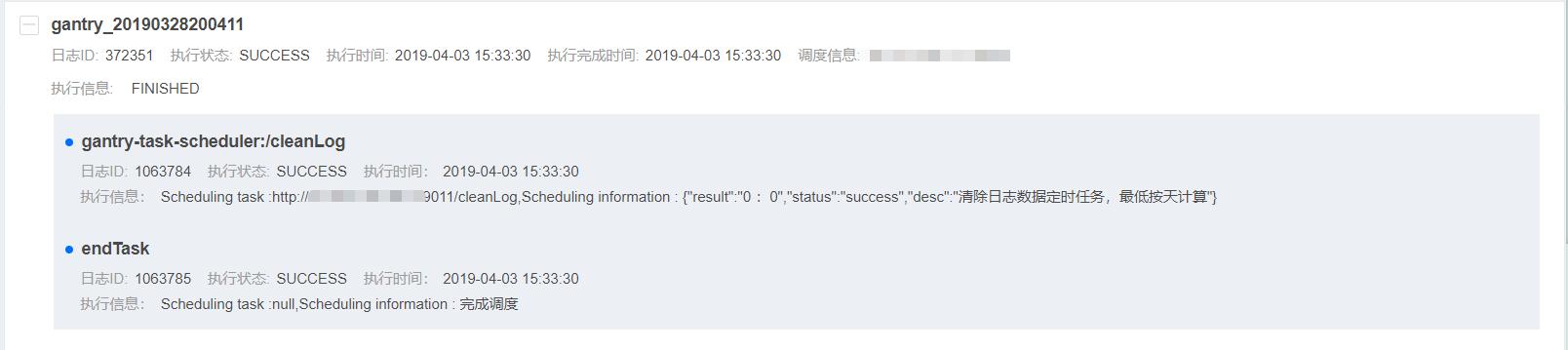
可通过日志详情查看该Job运行的详细信息,点击图中标识1中级联按钮,可关联中至所引用的Task日志信息,如下图所示:
四、TASK管理
点击左边栏中TASK管理项,显示Task管理界面,如下图所示:
Task管理界面中,Task按项目组分组显示,主要提供Task的配置、修改与删除等功能。本界面Task包含两部分,一部分Task使用了sia-task-hunter组件,通过标准注解实现Task的自动抓取,该类Task不允许修改;另外一部分Task并未使用sia-task-hunter组件,由用户手动添加,该部分Task可以修改和删除。
- 标识1:可以查看Task所属的项目组列表,点击某个项目组,可查看该项目组下的具体task列表;
- 标识2:可添加task;
- 标识3:查看、修改、连通性和删除动作;
- 标识4:某一Task的执行器实例列表;
- 标识5:按应用名称过滤(Job管理页过滤与此相同);
- 标识6:按Task名称过滤(Job管理页过滤与此相同);
4.1 添加Task
点击标识2添加task,弹出添加Task界面,如下图所示:
- 项目名称:非管理员用户只能从下拉列表中选择项目名称,后台管理员可以手动录入添加,项目名称只能包含数字、字母、下划线和中划线;
- 应用名称:非管理员用户只能从下拉列表中选择应用名称,后台管理员可以手动录入添加,项目名称只能包含数字、字母、下划线和中划线;
- HTTP_PATH:以左斜杠/为前缀,其余字符可为英文、数字、下划线,且路径不能包含右斜杠\;
- 是否配置参数: 该Task是否需要参数;
- 描述:一般为该Task的业务功能描述;
- IP:PORT:可以添加多个,不可重复,每个IP:PORT必须可用(可通过TELNET访问);每次输入一组IP:PORT点击右边的添加,通过后再添加下一个。如果是域名,请保证域名可用(能够PING通)
4.2 查看
点击查看,可查看该Task是否被某个Job引用
4.3 修改Task
点击修改,弹出修改Task界面如图所示:
只能修改手动添加的任务中以下几项:是否配置参数、描述和IP:PORT。
4.4 删除Task
点击删除,可将Task删除,如果Task被Job引用,则不能删除。
4.5 Task连通性
点击连通性进入联通性测试界面,如下图所示:
连通性:对于使用了sia-task-hunter组件,通过标准注解实现自动抓取的Task而言,sia-task-hunter加入了权限控制,不在此权限内的IP不能调用该Task,如需测试该Task是否可以正常工作(仅限POST方式),需在此界面测试,因此称之为连通性。
- 测试地址:该Task的执行器实例集群,可选择其中某一个进行测试;
- 测试参数:该Task的执行器输入参数;
- response: 该Task的执行器返回值
点击测试,观察response值,即可测试该Task连通性
五、JOB管理
Job管理界面提供添加、修改、删除以及针对Job触发相关的操作;
5.1 页面概览
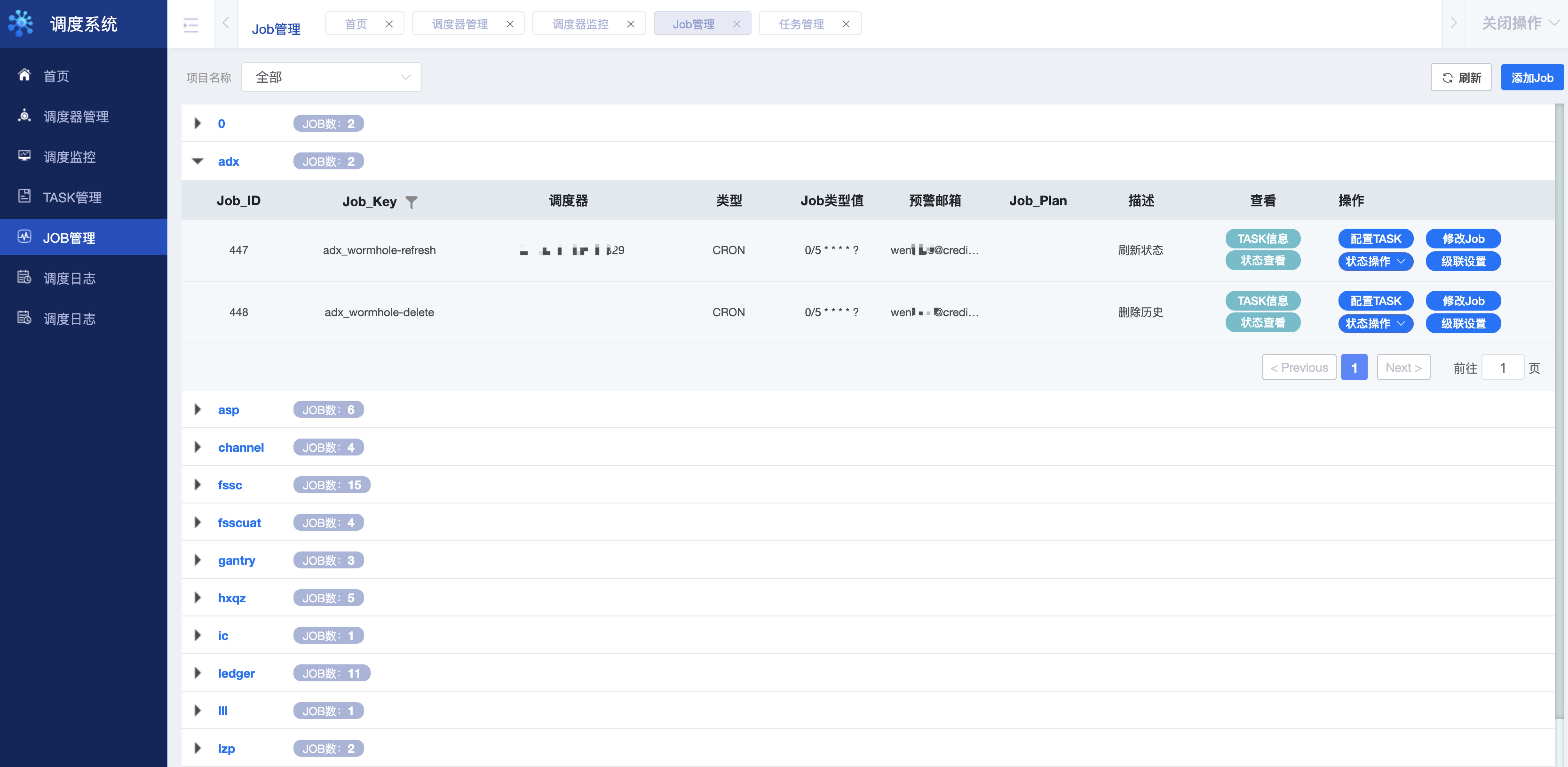
通过点击左侧列表Job管理进入Job管理界面,如下图所示:
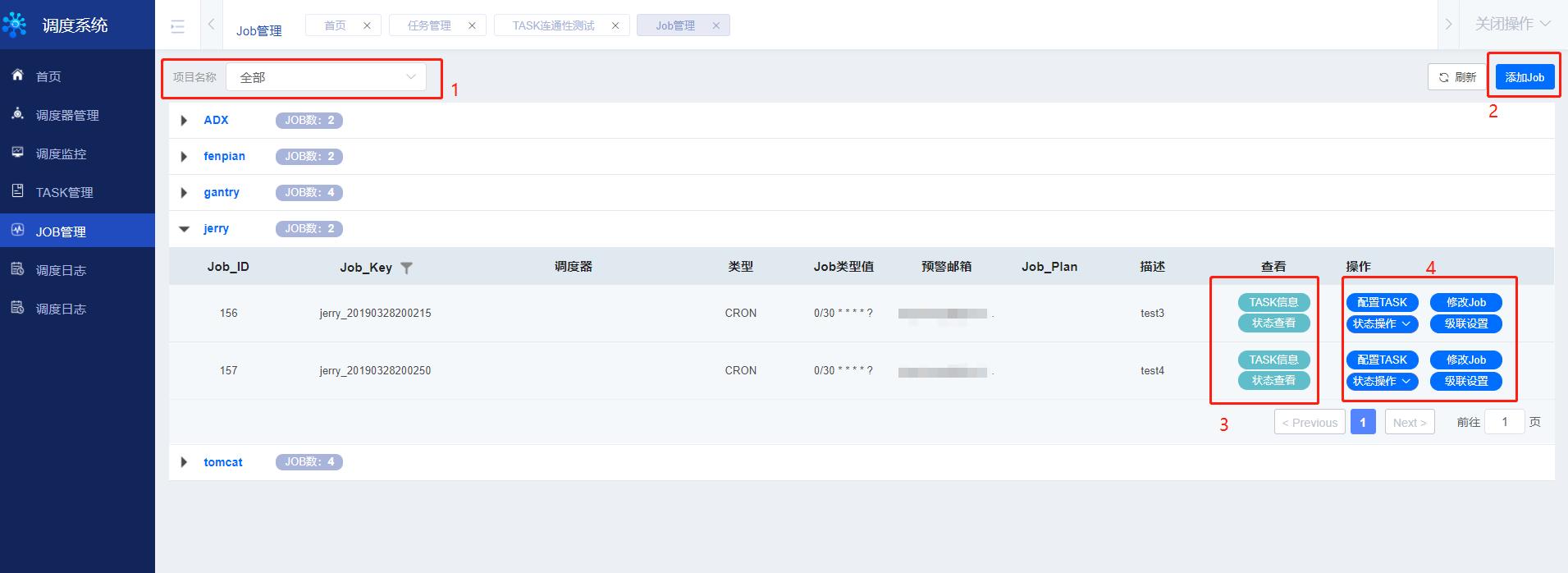
- 标识1:项目名称:假设当前用户拥有多个项目组的使用权限则显示全部(默认显示当前用户所在的项目组),点击下拉列表会显示所拥有的项目组列表,以供筛选/过滤Job使用。
- 标识2:添加Job按钮,用户可通过点击此按钮进行Job的新增配置。
- 标识3:Task信息,通过点击该按钮可查看当前Job的Task配置信息;状态查看:鼠标移至此处则会显示当前Job的运行时状态(状态:已停止/准备中/正在运行/异常停止)。
- 标识4:针对当前Job的相关操作;配置Task:进行Job的Task配置;修改Job:修改Job相关参数;状态操作:该按钮是一个包含多个操作的下拉菜单,可针对当前Job进行相关操作;级联设置:设置不同Job的级联关系。
5.2 新增Job
点击添加Job按钮,页面会弹出如下图示:
- Job_Group :选择Job归属的项目组,可选列表中一般包含多个项目组;默认是随机显示当前用户所拥有权限的项目组其中之一,可通过点击此处进行选择所添加Job的归属。
- Job_Key:Job唯一标识,以Job_Group为前缀;用户可输入自已定义的名称来标识此Job。
- Job类型:Job的类型:当前版本支持两种模式。
- TRIGGER_TYPE_CRON (固定时刻,后续输入CRON表达式);

- TRIGGER_TYPE_FIXRATE :代表任务按约定的时间开始执行,并且可以设置总的执行次数,以及两次执行之间的时间间隔。如果输入次数为0 则代表无穷大。
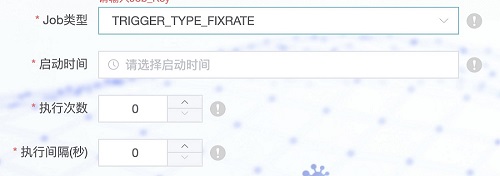
- Job类型值:针对不同的Job类型,输入合理的参数值。
*预警邮箱(前缀):任务失败、任务无法调度等情况,系统自动发邮件通知相关使用方。建议配置成项目组的邮箱,或者使用者的公司邮箱,不建议使用非公司邮箱账户。输入预警邮箱前缀,多个请用邮箱全程并以英文逗号隔开。
- 描述:Job 描述信息;
正确填写上述信息,然后点击 添加 按钮,进行确认。此时再次选择所添加Job的项目组会显示。
5.3 修改Job
可修改Job的类型、类型值,预警邮箱、描述等信息。界面同新增Job一致。当Job处于运行状态时,不可以修改。
5.4 配置Task
5.4.1 添加Task
点击配置Task按钮,页面会弹出如下图示:
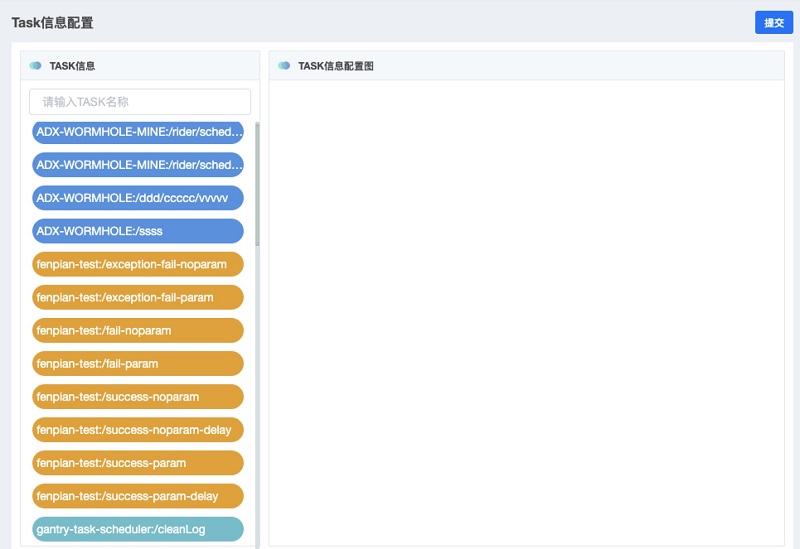
- Task信息:图示左侧列表显示为当前用户权限匹配的Task信息;不同的颜色区分所归属的项目组不同。可通过拖拽的方式选择所需的Task,拖拽至右边空白区域,则代表选择该Task。可以拖拽多个Task。顶部输入框提供Task筛选功能。
5.4.2 移除Task
点击task图标上面的移除按钮即可移除。
5.4.3 配置Task的依赖关系
- Task信息配置图:选择的Task拖拽完成,则可通过连线的方式配置Task的依赖关系。如下图所示:
说明:
(1)起始Task的运行时机为Job触发时进行唤起。
(2)后置Task的运行时机为前置Task运行完成,当存在多个前置Task时,则所有的前置Task均运行完成后才会唤起后置Task。
5.4.4 Task运行时参数配置
- Task运行时参数配置:Task的依赖关系配置完成后,可进一步配置每个Task的运行时参数。
点击红色框图中的编辑按钮,页面会弹出如下图示:
- Task_参数类型:配置Task的参数来源,因部分Task选择的参数类型为FROM_TASK,因此需要在配置Task列表界面中设置Task的参数来自于哪个Task(必须为该Task的前置Task之一);
- Task_参数值:根据 Task_参数类型,进行合理配置对应的参数即可。(Task参数类型选择FROM_UI,输入Task能解析的JSON串,最多255字符)。
- 过期时间(s):设置Task ReadTimeOut的大小,单位为秒。
- Task_选取实例策略:目前支持两种策略 (1)随机(从可选的列表中,随机选择实例,即IP+端口); (2)固定IP(指定实例,随后需要从可选列表中人工指定实例)。
- Task_调用失败策略:目前支持四种策略可供配置 (1)STOP(停止策略,调用失败则整个Job停止,不再执行后续Task); (2)IGNORE(忽略策略,调用失败则跳过该Task,继续执行后续Task); (3)TRANSFER(转移策略,选取该Task的其他实例执行,如果依然失败,则使用停止策略); (4)MULTI_CALLS_TRANSFER(多次调用再转移策略,重复调用该Task多次,如果依然失败,则使用转移策略)。
至此Job的task信息配置完成,点击提交确认。点击Job管理界面的Task信息按钮可查看当前所配置的Task依赖关系信息。
5.5 级联设置
- 级联设置:设置不同Job的级联关系。如果存在两个作业(Task)需要存在逻辑前后关系,同时后置任务也需要一定的时间关系,可使用该功能进行实现。将两个独立的作业(Task)封装为两个Job并设置独立的运行时间。然后对两个Job进行级联设置。
六、调度日志
点击左边栏调度日志,进入调度日志界面,如图所示:
日志管理提供了Job的运行日志相关信息,按项目组分组显示,一条Job日志的关键元素包含:
- 执行状态:表示该Job执行结果;
- 执行时间:表示调度器调度该Job的时间;
- 执行完成时间:表示该Job执行完成的时间;
- 调度信息:表示执行该Job的调度器实例;
- 执行信息:该Job执行的具体信息
并且已实现Job与所引用的Task的执行日志信息的关联,日志默认保存七天。
- 标识1:点击下拉框,选定某一组名,可实现日志分组过滤;
- 标识2:点击级联箭头,可显示出某个项目组的Job运行日志列表;
- 标识3:点击标识3处过滤图标,可实现按Job_Key进行日志过滤;
- 标识4:点击标识4处级联箭头,可现实该Job所引用的Task运行日志,实现Job与所引用Task运行日志的关联,如下图所示:
Task日志中关键元素包含:
- 执行状态:表示该Task执行结果;
- 执行时间:表示该Task执行时间;
- 执行信息:表示该Task的具体执行器实例信息及出参
- endTask:当某个Job所引用的Task均执行成功后,会执行系统自动追加的endTAsk,表示该Job执行完毕
微服务任务调度平台开发指南
1.1 自动抓取任务开发规则
使用分布式任务调度,不管是SpringBoot项目还是Spring项目,请务必做到:
1. 任务(Task)抓取客户端配置
通过POM文件引入 sia-task-hunter,具体如下:
<dependency> <groupId>com.sia</groupId> <artifactId>sia-task-hunter</artifactId> <version>1.0.0</version> </dependency>
2. 配置文件配置
对配置文件中以下属性进行配置:
# 项目名称(必须) # 命名规则:项目组名-项目名-其他 # 命名示例:skytrain-supervise,项目组名为skytrain spring.application.name=spring-3.x-test # 应用端口号(必须) server.port=8080 # zookeeper地址(必须) # zookeeper地址IP配置形式举例:*.*.*.*:2181,*.*.*.*:2181,*.*.*.*:2181 # zookeeper地址域名配置形式举例:域名1:2181,域名2:2181,域名3:2181 zooKeeperHosts=127.0.0.1:2181 # 应用上下文(可选) server.context-path=/spring-3.x-test
关于应用上下文server.context-path的配置:
(1)SpringBoot项目中应用上下文配置在 application.yml 中,添加属性:
server.context-path: /CONTEXT/PATH
(2)Spring项目中应用上下文配置是在TOMCAT的server.xml中添加:
Context path="/CONTEXT/PATH"
为了和SpringBoot项目保持一致,Spring项目需要额外在配置文件(Spring项目能加载到上下文中)添加:
server.context-path=/CONTEXT/PATH(Spring应用)
总之,不管上下文路径怎么配置,只要保证HTTP的访问路径:
IP:${server.port}/${server.context-path}/${类的访问路径}/${方法的访问路径}
能被正常POST访问即可!
3. 扫描路径配置
对sia-task-hunter的扫描路径进行配置:
3.1 在SpringBoot项目中,请确保扫描路径中包含"com.sia"
示例:@SpringBootApplication(scanBasePackages = { "com.sia", "你的项目所在包名称" })
3.2 在Spring项目中,请确保扫描路径中包含"com.sia"
示例:<context:component-scan base-package="com.sia,你的项目所在包名称" ></context:component-scan>
4. 单例单线程配置
通过@OnlineTask注解保证HTTP访问方法是单例单线程
4.1 SpringBoot中的配置
# 是否开启 AOP 切面功能(默认为true) spring.aop.auto: true # 是否开启 @OnlineTask 串行控制(如果使用则必须开启AOP功能)(默认为true)(可选) spring.onlinetask.serial: true # 方法级别的 @OnlineTask 串行控制(如果使用则必须开启之前的AOP功能与串行控制)(默认为true)(可选) @OnlineTask(enableSerial=true)
4.2 Spring中的配置
如需开启AOP切面功能,请添加配置类:
@Configuration
@EnableAspectJAutoProxy
public class EnableAspectJAutoProxyConfig {
//nothing
}
只有开启AOP功能,@OnlineTask串行控制才会生效:
# 是否开启@OnlineTask串行控制(如果使用则必须开启AOP功能)(默认为true)(可选) spring.onlinetask.serial=true # 方法级别的 @OnlineTask 串行控制(如果使用则必须开启之前的AOP功能与串行控制)(默认为true)(可选) @OnlineTask(enableSerial=true)
5. 在线任务标准示例
import java.util.HashMap;
import java.util.Map;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import com.gantry.onlinetask.annotation.OnlineTask;
import com.gantry.onlinetask.helper.JSONHelper;
@RestController
public class OnlineTaskExample {
/**
* OnlineTask示例,标准格式
* <p>
* (1)方法上有@OnlineTask注解,用来标注是否被抓取,可以添加description描述,描述该Task的作用
* <p>
* (2)方法上有@RequestMapping注解,因为OnlineTask必须对外提供HTTP访问
* <p>
* (3)@RequestMapping注解中,请使用value(或path)属性(因为低版本Spring没有path属性,为了兼容,优先抓取value属性的值),且value 以"/"为前缀(减少处理复杂度),路径不能包含"\"(用作替换)
* <p>
* (4)@RequestMapping注解中,method中必须要有POST方法(需要传参),且使用@CrossOrigin支持跨域(POST方法默认不允许跨域)或者使用过滤器(Filter)让Task可以跨域
* <p>
* (5)请使用 @ResponseBody 标注返回值。类上如果使用 @RestController,则 @ResponseBody可选,如果使用@Controller,则@ResponseBody必选
* <p>
* (6)方法返回值是String(JSON),JSON是一个Map,必须有"status" 属性,值为{success,failure,unknown},用于处理逻辑;必须有 "result" 属性,值为HTTP调用的返回值
* <p>
* (7)方法可以无参;若有入参,则只能有一个,且是String(JSON),请使用 @RequestBody 标注
* <p>
* (8)@OnlineTask注解使用了AOP技术,保证调用的方法是单例单线程
* <p>
* (9)OnlineTask的业务逻辑处理请尽量保证幂等
* <p>
* (10)现支持类上使用@RequestMapping注解
* /
*
* @param json
* @return
*/
// (1)方法上有@OnlineTask注解,用来标注是否被抓取,可以添加description描述,描述该Task的作用
@OnlineTask(description = "在线任务示例",enableSerial=true)
// (2)方法上有@RequestMapping注解,因为OnlineTask必须对外提供HTTP访问
// (3)@RequestMapping注解中,请使用value(或path)属性(因为低版本Spring没有path属性,为了兼容,优先抓取value属性的值),且value 以"/"为前缀(减少处理复杂度),路径不能包含"\"(用作替换)
@RequestMapping(value = "/example", method = { RequestMethod.POST }, produces = "application/json;charset=UTF-8")
// (4)@RequestMapping注解中,method中必须要有POST方法(需要传参),且使用@CrossOrigin支持跨域(POST方法默认不允许跨域)或者使用过滤器(Filter)让Task可以跨域
@CrossOrigin(methods = { RequestMethod.POST }, origins = "*")
// (5)请使用 @ResponseBody 标注返回值。类上如果使用 @RestController,则 @ResponseBody可选,如果使用@Controller,则@ResponseBody必选
@ResponseBody
// (6)方法返回值是String(JSON),JSON是一个Map,必须有"status" 属性,值为{success,failure,unknown},用于处理逻辑;必须有 "result"属性,值为HTTP调用的返回值
// (7)方法可以无参;若有入参,则只能有一个,且是String(JSON),请使用 @RequestBody 标注
public String example(@RequestBody String json) {
/**
* TODO:客户端业务逻辑处理
*/
// 返回结果存储结构,请使用Map
Map<String, String> info = new HashMap<String, String>();
// 返回的信息必须包含以下两个字段
info.put("status", "success");// status字段表明此次Task调用是否成功,非 success 都是失败
info.put("result", "as you need");// result字段表示此次Task调用的返回结果(之后可能传递给其他Task) ,其值可能作为其他Task的输入,所以只能是String(JSON)类型
// 返回值也是String(JSON)类型,客户端包里有JSONHelper,可直接使用
return JSONHelper.toString(info);
}
}
1.2 自动抓取任务开发代码示例
1. POM文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<!-- 项目名称配置,请自定义修改 -->
<groupId>com.creditease</groupId>
<artifactId>onlinetask-client</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<!-- 基本配置,开始 -->
<properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spring.boot.version>1.5.11.RELEASE</spring.boot.version>
<spring.cloud.version>Dalston.SR5</spring.cloud.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<!-- Import dependency management from Spring Boot -->
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>${spring.boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<!-- Import dependency management from Spring Cloud -->
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring.cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<!-- 基本配置,结束 -->
<dependencies>
<!-- 基本依赖,开始 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- 基本依赖,结束 -->
<!-- 此处添加个性化依赖 -->
<dependency>
<groupId>com.sia</groupId>
<artifactId>sia-task-hunter</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
<!-- 打包配置 -->
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2. 配置文件
# 项目名称(必须) spring.application.name: onlinetask-client # 应用端口号(必须) server.port: 10086 # zookeeper地址(必须) zooKeeperHosts: *.*.*.*:2181,*.*.*.*:2181,*.*.*.*:2181 # 应用上下文(可选) server.context-path: / # 是否开启 AOP 切面功能(默认为true) spring.aop.auto: true # 是否开启 @OnlineTask 串行控制(如果使用则必须开启AOP功能)(默认为true)(可选) spring.onlinetask.serial: true
3. controller
package com.creditease.online.example;
import java.util.HashMap;
import java.util.Map;
import org.springframework.web.bind.annotation.CrossOrigin;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import com.gantry.onlinetask.annotation.OnlineTask;
import com.gantry.onlinetask.helper.JSONHelper;
@RestController
public class OnlineTaskExample {
/**
* OnlineTask示例,标准格式
* <p>
* (1)方法上有@OnlineTask注解,用来标注是否被抓取,可以添加description描述,描述该Task的作用
* <p>
* (2)方法上有@RequestMapping注解,因为OnlineTask必须对外提供HTTP访问
* <p>
* (3)@RequestMapping注解中,请使用value(或path)属性(因为低版本Spring没有path属性,为了兼容,优先抓取value属性的值),且value 以"/"为前缀(减少处理复杂度),路径不能包含"\"(用作替换)
* <p>
* (4)@RequestMapping注解中,method中必须要有POST方法(需要传参),且使用@CrossOrigin支持跨域(POST方法默认不允许跨域)或者使用过滤器(Filter)让Task可以跨域
* <p>
* (5)请使用 @ResponseBody 标注返回值。类上如果使用 @RestController,则 @ResponseBody可选,如果使用@Controller,则@ResponseBody必选
* <p>
* (6)方法返回值是String(JSON),JSON是一个Map,必须有"status" 属性,值为{success,failure,unknown},用于处理逻辑;必须有 "result" 属性,值为HTTP调用的返回值
* <p>
* (7)方法可以无参;若有入参,则只能有一个,且是String(JSON),请使用 @RequestBody 标注
* <p>
* (8)@OnlineTask注解使用了AOP技术,保证调用的方法是单例单线程
* <p>
* (9)OnlineTask的业务逻辑处理请尽量保证幂等
* <p>
* (10)现支持类上使用@RequestMapping注解
* /
*
* @param json
* @return
*/
// (1)方法上有@OnlineTask注解,用来标注是否被抓取,可以添加description描述,描述该Task的作用
@OnlineTask(description = "在线任务示例",enableSerial=true)
// (2)方法上有@RequestMapping注解,因为OnlineTask必须对外提供HTTP访问
// (3)@RequestMapping注解中,请使用value(或path)属性(因为低版本Spring没有path属性,为了兼容,优先抓取value属性的值),且value 以"/"为前缀(减少处理复杂度),路径不能包含"\"(用作替换)
@RequestMapping(value = "/example", method = { RequestMethod.POST }, produces = "application/json;charset=UTF-8")
// (4)@RequestMapping注解中,method中必须要有POST方法(需要传参),且使用@CrossOrigin支持跨域(POST方法默认不允许跨域)或者使用过滤器(Filter)让Task可以跨域
@CrossOrigin(methods = { RequestMethod.POST }, origins = "*")
// (5)请使用 @ResponseBody 标注返回值。类上如果使用 @RestController,则 @ResponseBody可选,如果使用@Controller,则@ResponseBody必选
@ResponseBody
// (6)方法返回值是String(JSON),JSON是一个Map,必须有"status" 属性,值为{success,failure,unknown},用于处理逻辑;必须有 "result"属性,值为HTTP调用的返回值
// (7)方法可以无参;若有入参,则只能有一个,且是String(JSON),请使用 @RequestBody 标注
public String example(@RequestBody String json) {
/**
* TODO:客户端业务逻辑处理
*/
// 返回结果存储结构,请使用Map
Map<String, String> info = new HashMap<String, String>();
// 返回的信息必须包含以下两个字段
info.put("status", "success");// status字段表明此次Task调用是否成功,非 success 都是失败
info.put("result", "as you need");// result字段表示此次Task调用的返回结果(之后可能传递给其他Task) ,其值可能作为其他Task的输入,所以只能是String(JSON)类型
// 返回值也是String(JSON)类型,客户端包里有JSONHelper,可直接使用
return JSONHelper.toString(info);
}
}
4. 启动类
package com.creditease;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
//务必覆盖扫描包的范围
@SpringBootApplication(scanBasePackages = { "com.sia"})
public class OnlineTaskClientApp {
private static final Logger LOGGER = LoggerFactory.getLogger(OnlineTaskClientApp.class);
public static void main(String[] args) {
SpringApplication.run(OnlineTaskClientApp.class, args);
LOGGER.info("OnlineTaskClient启动!");
}
}
微服务任务调度平台安装部署指南
一. MySQL初始化
- MySQL的安装和配置详见MySQL官方文档
- 微服务任务调度平台SQL初始化脚本
-- ----------------------------
-- database sia_task
-- ----------------------------
create database IF not exists `skyworld_task`;
use skyworld_task;
-- ----------------------------
-- Table structure for skyworld_basic_job
-- job 元数据 手动录入
-- ----------------------------
create table if not exists skyworld_basic_job
(
job_id int auto_increment,
job_key varchar(255) not null comment '除ID外的 唯一标识 KEY',
job_group varchar(100) not null comment '命名空间:name+group组成一个唯一key',
job_triger_type varchar(25) null comment '触发器类型',
job_triger_value varchar(128) null comment '触发器类型值',
job_desc varchar(250) null comment 'job描述信息',
job_alarm_email varchar(100) null comment 'job预警邮箱',
job_create_time datetime not null,
job_update_time datetime not null,
job_parent_key varchar(255) null comment 'job父jobKey',
job_plan varchar(255) null comment 'job级联',
constraint job_id_UNIQUE
unique (job_id),
constraint job_key_UNIQUE
unique (job_key)
)
charset = utf8;
alter table skyworld_basic_job
add primary key (job_id);
-- ----------------------------
-- Table structure for skyworld_basic_task
-- task 元数据 自动获取/手动录入
-- ----------------------------
create table if not exists skyworld_basic_task
(
task_id int auto_increment,
task_key varchar(255) not null comment '唯一键-检索使用(AppName+HttpPath)',
task_group_name varchar(255) not null comment 'task_group_name',
task_app_name varchar(255) not null comment 'app_name',
task_app_http_path varchar(255) not null comment 'task请求路径',
task_app_ip_port varchar(255) null comment 'app实例IP:port',
param_count int(2) default 1 null comment '是否存在入参:0:没有,1:存在',
taskDesc varchar(255) null comment 'task描述',
task_source varchar(45) null comment 'task来源。TASK_SOURCE_UI:手动录入,TASK_SOURCE_ZK:自动抓取',
create_time datetime not null,
update_time datetime null,
constraint task_id_UNIQUE
unique (task_id),
constraint task_key_UNIQUE
unique (task_key)
)
charset = utf8;
alter table skyworld_basic_task
add primary key (task_id);
-- ----------------------------
-- Table structure for skyworld_job_log
-- job—log 日志表,Job 调度日志
-- ----------------------------
create table if not exists skyworld_job_log
(
job_log_id int auto_increment comment '主键ID AUTO_INCREMENT'
primary key,
job_id int not null,
job_trigger_code varchar(45) null comment '调度-结果状态',
job_trigger_msg varchar(2048) null comment '调度-日志',
job_trigger_time datetime null comment '调度-时间',
job_handle_code varchar(45) null comment '执行结果-状态',
job_handle_msg varchar(2048) null comment '执行结果-日志',
job_handle_time datetime null comment '执行-时间',
job_handle_finished_time datetime null comment '执行完成时间',
create_time datetime null
)
charset = utf8;
-- ----------------------------
-- Table structure for skyworld_portal_stat
-- sia-task 统计表,监控使用
-- ----------------------------
create table if not exists skyworld_portal_stat
(
portal_statistics_id int auto_increment
primary key,
scheduler varchar(2048) not null comment '调度器IP:PORT',
job_call_count int not null comment 'JOB调度次数',
task_call_count int not null comment 'task调度次数',
job_exception_count int not null comment 'JOB异常数量',
job_finished_count int not null comment 'JOB已完成数量',
task_exception_count int not null comment 'task异常数量',
task_finished_count int not null comment 'task已完成数量',
last_time datetime not null comment '上次统计时间',
create_time datetime not null
)
charset = utf8;
-- ----------------------------
-- Table structure for skyworld_task_log
-- task-log 日志表,task 调度日志
-- ----------------------------
create table if not exists skyworld_task_log
(
task_log_id int auto_increment
primary key,
job_log_id int not null comment 'task计数;',
job_key varchar(255) null,
task_key varchar(255) not null comment 'task_id',
task_msg varchar(2048) null comment '状态描述信息,如:异常信息,SUCCESS等',
task_status varchar(45) null comment '状态值:ready,running,finished,exception',
task_handle_time datetime null,
task_finished_time datetime null,
create_time datetime null
)
charset = utf8;
-- ----------------------------
-- Table structure for task_mapping_job
-- 编排关系 job-task 关系表
-- ----------------------------
create table if not exists task_mapping_job
(
task_map_job_id int auto_increment
primary key,
job_id int not null,
job_key varchar(255) not null,
job_group varchar(255) not null,
task_id int not null,
task_key varchar(255) not null,
pre_task_key varchar(255) null comment '前置任务',
input_type varchar(255) default 'from_ui' not null comment 'task入参来源:{from_ui,from_task}',
input_value varchar(255) null comment 'task入参参数值',
route_strategy varchar(45) default 'ROUTE_TYPE_RANDOM' null comment '路由策略{ROUTE_TYPE_FIRST,ROUTE_TYPE_RANDOM,ROUTE_TYPE_LAST,ROUTE_TYPE_ROUND}',
failover varchar(45) null comment '失败恢复策略',
fix_ip varchar(45) null comment '预估执行时间',
update_time datetime null comment '更新时间',
create_time datetime not null comment '创建时间',
read_timeout int null comment '接口数据返回超时时间',
constraint uni_ind_job_task_id
unique (job_key, job_group, task_key)
)
charset = utf8;
二. zookeeper安装
zookeeper的安装和配置详见官方文档,至少部署三个节点。
如:A.B.C.2:2181, A.B.C.3:2181, A.B.C.4:2181。
三. 微服务任务调度平台前端部署
微服务任务调度平台采用前后分离模式,前端代码在sia-task-config-display目录下。
环境准备
- node环境安装 => https://nodejs.org/en/download/
- Nginx准备
前端项目打包
进入本地的项目,在~/sia-task/sia-task-config-display目录下执行如下命令进行前端代码打包:
- npm install 或 cnpm install(推荐) cnpm安装命令:npm install -g cnpm --registry=https://registry.npm.taobao.org
- npm run build
1、打包完成在当前目录下面生成dist文件夹,把dist文件夹放在nginx所在机器的app目录下
2、修改前端配置的编排中心应用服务地址:nginx所在机器的app目录下 dist/static文件夹下面的site.map.js为后端服务配置(ip:port形式),根据项目需求自行更改(CESHI_API_HOST参数配置的地址即为编排中心服务地址)
前端项目部署
- nginx的代理配置,进入nginx的目录下nginx.conf,添加如下代理:
server {
listen 8080; // 前端页面监听端口
server_name localhost;
location / {
root app/dist; // 前端包存放目录
index index.html index.htm;
try_files $uri $uri/ @router;
}
location @router {
rewrite ^.*$ /index.html last;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://*.*.*.*:10615; // 后端编排中心服务地址
add_header 'Access-Control-Allow-Origin' 'http://*.*.*.*:8080';
add_header 'Access-Control-Allow-Credentials' 'true';
}
}
四. 任务编排中心和调度中心部署
- 环境要求
- 系统:64bit OS,Linux/Mac/Windows
- IDE:推荐使用IntelliJ IDEA 或 Eclipse
- JDK:JDK1.8+
- 从SIA-TASK工程下获取源代码打包,执行sia-task-build-component目录的mvn命令即可。
- 在~/sia-task/sia-task-build-component目录下,执行如下命令打包:mvn clean install 。
- 打包成功后,会在~/sia-task/sia-task-build-component 目录下出现target文件,target文件中的.zip文件即为项目安装包。
- 打开安装包所在文件夹,将安装包解压,得到task目录,其中包括四个子目录:
- bin:存放sia-task-config和sia-task-scheduler两个工程的jar包及各类shell脚本,如下图所示:
- config:存放sia-task-config和sia-task-scheduler两个工程的配置文件,如下图所示:

- logs:存放日志
- thirdparty:
- 配置文件修改
- 将config文件夹下的sia-task-config工程的配置文件task_config_open.yml,以及sia-task-scheduler工程下的配置文件task_scheduler_open.yml中的zookeeper和Mysql的链接修改为自己的地址。
- 启动sia-task-config工程
sh start_task_config_open.sh
- 启动sia-task-scheduler工程
sh start_task_scheduler_open.sh
- 访问项目
访问sia-task微服务任务调度平台的访问入口(登录页面地址(即为前端配置的编排中心服务地址),如:http://前端部署机器IP地址:8080 )。登录页面如下图所示:
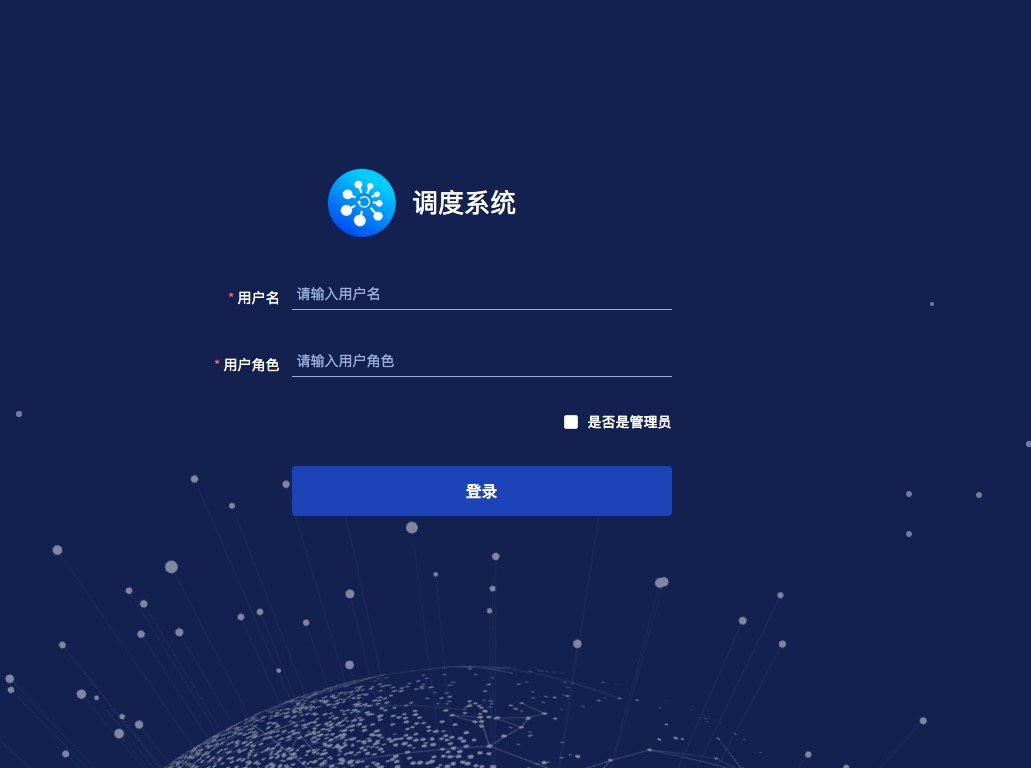
- 输入用户名/用户角色即可登录(开源项目登录页面没做登录限制,输入任意字符串的用户名/用户角色都能登录),用户使用任务调度框架的时候可根据自己的需求做相应的登录权限控制开发.
- 任务调度是按角色(项目组名称)进行权限控制的,接入任务调度的应用必须以角色名称为应用名称前缀(如:角色名为"abc",则,该角色下的应用名必须以"abc"为前缀,应用名称举例:"abc-datadraw"),要求任务名称以角色名称为前缀。
- 登录时选中"是否是管理员"选项后,则会以管理员身份登录。管理员能看到所有的角色的任务,并且能手动录入角色(仅管理员有此操作的权限)。
- 用户登录任务调度系统,只能看到该用户有权限的角色(项目组)下的任务,一个用户可以有多个角色。
微服务任务调度菜单项如下图所示:
在该页面中,即可对SIA-TASK微服务任务调度的功能进行操作。
微服务任务调度平台SIA-TASK入手实践
引言
最近微服务任务调度平台SIA-TASK开源,SIA-TASK属于分布式的任务调度平台,使用起来简单方便,非常容易入手,部署搭建好SIA-TASK任务调度平台之后,编写TASK后配置JOB进行调度,进而实现整个调度流程。本文新建了JOB示例,该JOB关联了前后级联的两个TASK,TASKONE(前置TASK)和TASKTWO(后置TASK),主要阐述一个JOB怎样关联配置两个级联TASK,以及该JOB是如何通过SIA-TASK实现任务调度,最终实现对两个TASK执行器的调用。
任务调度平台主要由任务编排中心、任务调度中心以及ZK和DB等第三方服务构成,搭建SIA-TASK任务调度平台需要的主要工作包括:
1.MySQL的搭建及根据建表语句建表
2.zookeeper安装
3.SIA-TASK前端项目打包及部署
4.任务编排中心(sia-task-config)部署
5.任务调度中心(sia-task-scheduler)部署
从github上clone代码仓库并*载下**源码后,可根据SIA-TASK部署指南,搭建SIA-TASK任务调度平台并启动,详见SIA-TASK部署指南
搭建好SIA-TASK任务调度平台后,下一步就是TASK执行器实例的编写啦
其次,根据开发文档来编写TASK执行器实例并启动:
根据SIA-TASK开发指南,编写了两个TASK示例,TASKONE(前置TASK)和TASKTWO(后置TASK),具体开发规则见SIA-TASK开发指南,TASK示例关键配置即代码如下:
该示例为springboot项目,并且需要通过POM文件引入SIA-TASK的执行器关键依赖包sia-task-hunter来实现task执行器的自动抓取,首先需要将SIA-TASK源码中的sia-task-hunter包用mvn install命令打包为jar包安装至本地仓库,SIA-TASK源码中的sia-task-hunter包如下图示:
然后就可以进行示例的编写,示例主要包括以下几部分:
配置POM文件关键依赖:
<!-- 此处添加个性化依赖(sia-task-hunter) --> <dependency> <groupId>com.sia</groupId> <artifactId>sia-task-hunter</artifactId> <version>1.0.0</version> </dependency>
配置文件主要配置项:
# 项目名称(必须) spring.application.name: onlinetask-demo # 应用端口号(必须) server.port: 10086 # zookeeper地址(必须) zooKeeperHosts: *.*.*.*:2181,*.*.*.*:2181,*.*.*.*:2181 # 是否开启 AOP 切面功能(默认为true) spring.aop.auto: true # 是否开启 @OnlineTask 串行控制(如果使用则必须开启AOP功能)(默认为true)(可选) spring.onlinetask.serial: true
编写TASK执行器主要代码
@Controller
public class OpenTestController {
@OnlineTask(description = "success,无入参",enableSerial=true)
@RequestMapping(value = "/success-noparam", method = { RequestMethod.POST }, produces = "application/json;charset=UTF-8")
@CrossOrigin(methods = { RequestMethod.POST }, origins = "*")
@ResponseBody
public String taskOne() {
Map<String, String> info = new HashMap<String, String>();
info.put("result", "success-noparam");
info.put("status", "success");
System.out.println("调用taskOne任务成功");
return JSONHelper.toString(info);
}
@OnlineTask(description = "success,有入参",enableSerial=true)
@RequestMapping(value = "/success-param", method = { RequestMethod.POST }, produces = "application/json;charset=UTF-8")
@CrossOrigin(methods = { RequestMethod.POST }, origins = "*")
@ResponseBody
public String taskTwo(@RequestBody String json) {
Map<String, String> info = new HashMap<String, String>();
info.put("result", "success-param"+"入参是:"+json);
info.put("status", "success");
System.out.println("调用taskTwo任务成功");
return JSONHelper.toString(info);
}
}
当编写完TASK执行器实例后,启动该执行器所在进程
日志表明该进程正常启动,并且TASK执行器信息正常上传至ZK当中
观察TASK管理界面,
从图中可知,TASK已同步至数据库中
再次,需要进行JOB的创建和JOB对TASK的关联及配置
根据使用指南进行如下操作:
创建JOB,配置参数
在JOB管理界面点击添加Job

选定Job_Group,尽量选定所要关联的TASK所属的Group组名
分别填写Job类型及其他项,Job类型也可以选择FixRate(特定时间点)类型,本例为CRON类型,具体数值为:0/30 * * * * ?,表示从当前时刻开始,每30秒执行一次
点击添加,添加JOB成功
配置TASK
添加JOB成功后,需要为该JOB配置相应的TASK,可配置单个或多个,本例以配置两个级联TASK为例

点击配置TASK后,进入Task信息配置界面
如上图所示,将需要配置的两个TASK均拉取至右侧,点击编辑按钮(铅笔形状),进入TASK参数配置界面
TASKONE参数配置:
TASKTWO参数配置:
按图中编辑完成后,点击添加,成功将TASKONE和TASKTWO配置至JOB中,
添加完毕后,可进行两个TASK的依赖关系配置,如下图所示:
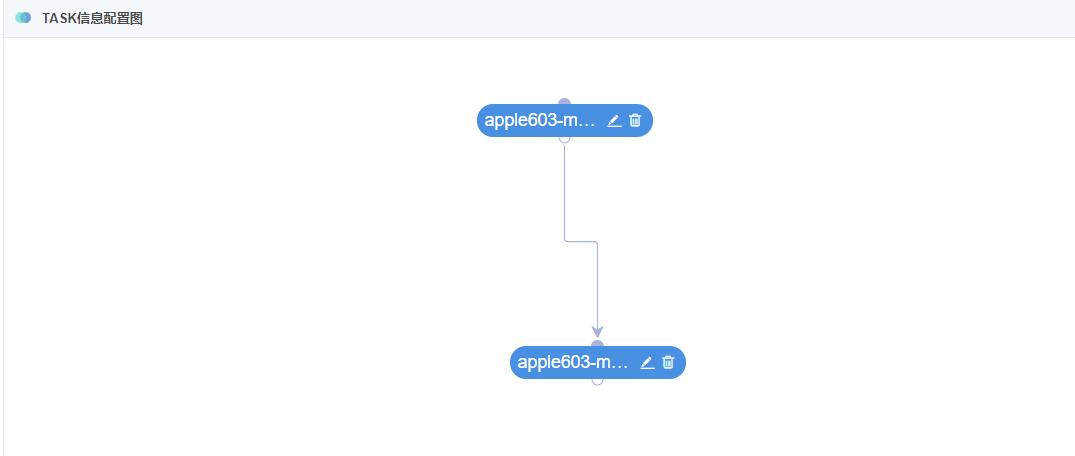
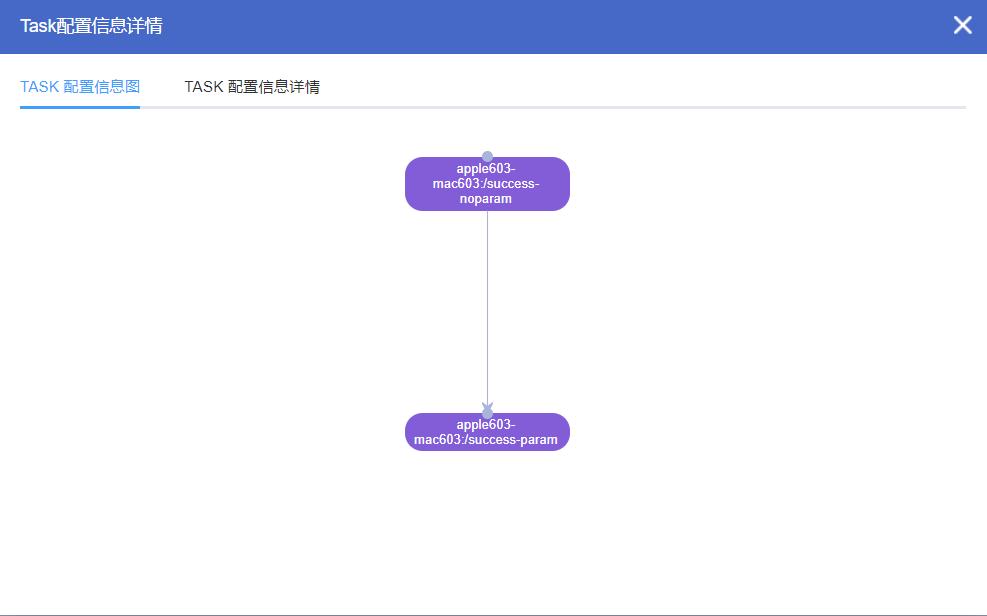
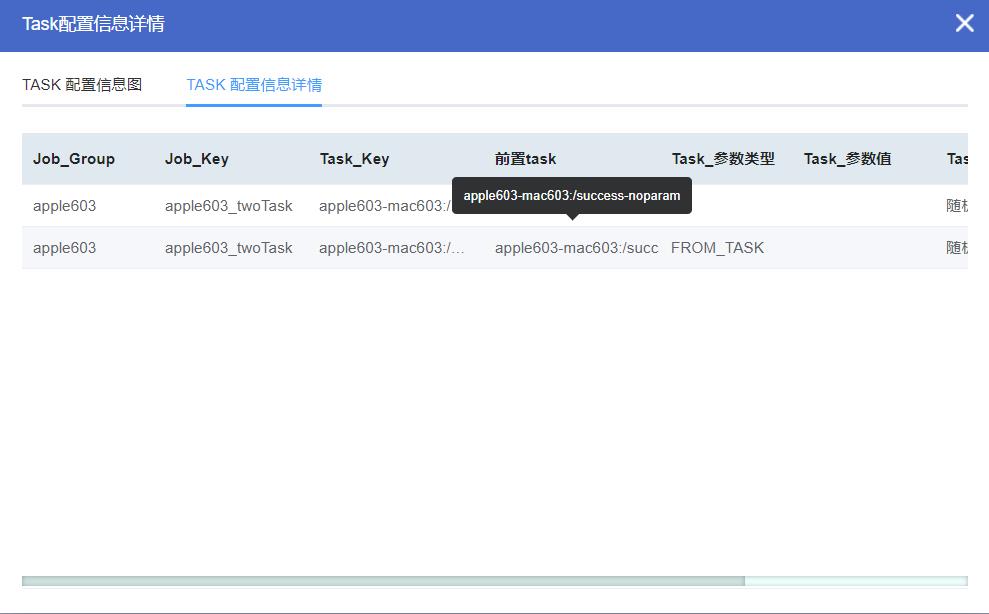
用箭头将TASKONE(前置TASK)指向TASKTWO(后置TASK),即可完成TASK之间的依赖关系设置,点击提交,完成整个JOB的配置,配置完成后,可点击TASK信息按钮,查看TASK配置信息详情,观察该JOB的TASK配置情况
TASK配置信息图:
TASK配置信息详情
最后,激活JOB并观察相应日志
TASK配置成功后,点击状态操作下拉按钮中激活按钮,激活JOB

激活JOB后,刷新该界面,可发现该JOB列表调度器(红框处)出现调度器IP及端口号,表示该JOB激活后被该调度器抢占
先观察管理界面JOB及TASK日志
成功激活JOB后,进入调度日志界面,等待至JOB执行时间后,可查看到该JOB执行日志,如下图示:
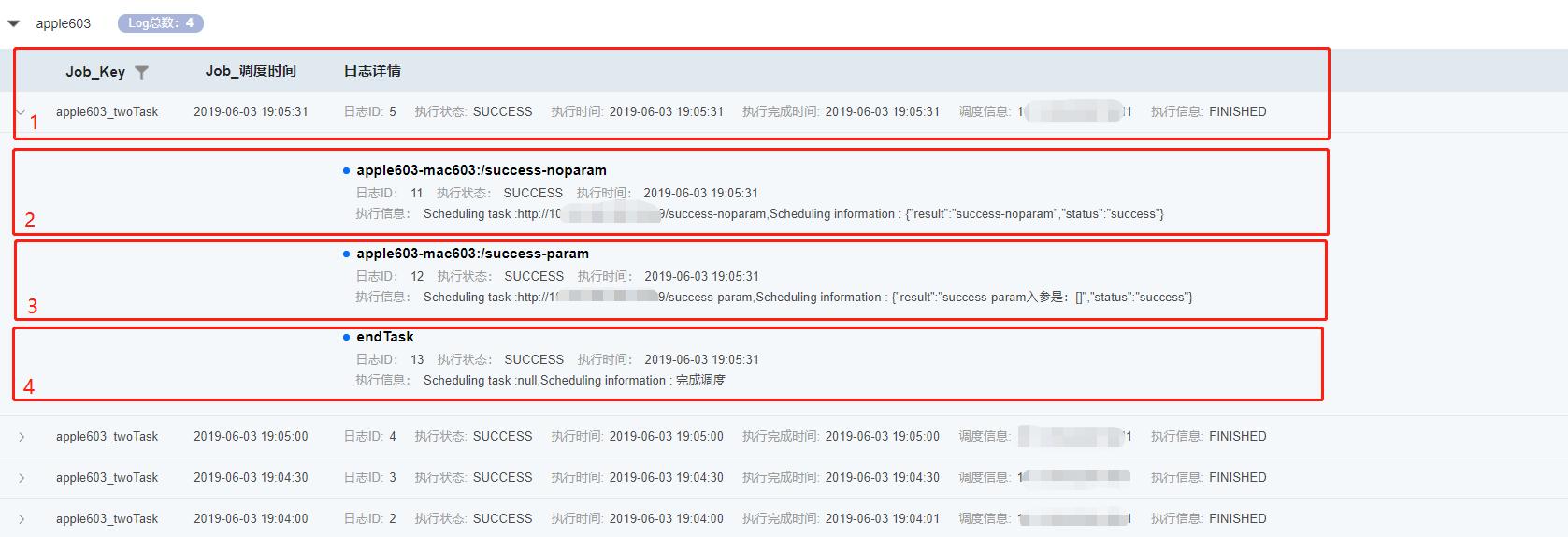
标号1:代表该JOB日志
标号2:代表该JOB所关联的前置TASK(TASKONE)日志
标号3:代表该JOB所关联的后置TASK(TASKTWO)日志
标号4:endTask为系统追加的一个虚拟TASK,仅表示该JOB的一次调度过程完成
同时从执行时间也可观察出,每30秒调度一次
再观察执行器TASK实例日志
还可观察执行器实例TASK日志,验证是否调用成功
从日志可知,确实调用成功,并且每30秒调用一次
停止JOB
当需要停止JOB时,点击状态操作下拉按钮中停止按钮,停止JOB

本文仅是对微服务任务调度平台SIA-TASK的初步实践使用,通过以上描述,可实现SIA-TASK对执行器实例TASK实现任务调度的功能,本文中搭建的示例非常简单,适合快速入手SIA-TASK,当然,SIA-TASK还有更加强大的任务调度功能,可以应对更加复杂的业务场景,大家可以继续深度使用体验,将SIA-TASK的功能点和业务相结合,将其应用至更加复杂的业务场景之下。
私信回复"sia-task"获取链接地址,喜欢的点个关注,一起学习探讨新技术。