近日,国外权威的服务器专业网站ServeTheHome(简称STH)完成了对浪潮高端AI服务器NF5488M5的首发评测,称“浪潮NF5488M5是一款真正独一无二的产品”。凭借优秀的外观设计、超强的性能表现、卓越的散热设计、独特的管理特性等,NF5488M5获得了9.6分的高分评价,一举成为AI服务器的8卡“机王”。

如下是完整评测报告第二部分GPU基板模组概览:
浪潮NF5488M5是一款真正独一无二的产品。尽管许多供应商,都可以宣称拥有搭载8块NVIDIA Tesla V100的系统,但NF5488M5可能是这些系统中,您可以买到的最高端产品。它不仅搭载了8块Tesla V100 SXM3且支持“Volta Next” GPU,TDP达350W以上,并且结构方面也有一定的特别之处。这些GPU利用NVSwitch技术互相连接,这就意味着,每两个GPU之间都有300GB/s的P2P 通信带宽。
在本测评中,我们会比平常多花一些时间讨论硬件,以及它与市场上其他产品完全不同的独特设计。截至2019年4月,浪潮在中国的AI服务器市场份额稳居 51% 以上,而这款产品正是帮助浪潮继续扩大市场份额的创新设计之一。

GPU基板模组可以从主4U服务器机箱中利用滑轨拉出。

它实际上有自己的盖板,并且内部有自己的滑轨系统,甚至还配有侧面闩锁来确保整个模组的安全。实际上,这就像是一个小的服务器滑轨套件,安装于这个单节点4U服务器中。

取下盖板,我们可以看到巨大而坚硬的气流导板穿过整个部分。气流是机箱设计时的一个重要考量,因此这里使用了一块非常耐用的导风板。

移除盖板,我们就可以看到GPU基板。PCIe信号从CPU发出,经过主板,进入 PCIe线缆,再到达Broadcom PEX9797 PCIe交换板,然后通过高密度PCI连接器到达GPU基板,最后在这里被分配给每个GPU。

我们的系统*共中**有八个NVIDIA Tesla V100 32GB SXM3,并且支持在该系统中使用“Volta Next”GPU。像这样的SXM3 GPU专门设计用于在此类54VDC 系统中运行,拥有350W的TDP。我们看到,nvidia-smi测量表明,每个SXM3 GPU空闲时功率约为50瓦。
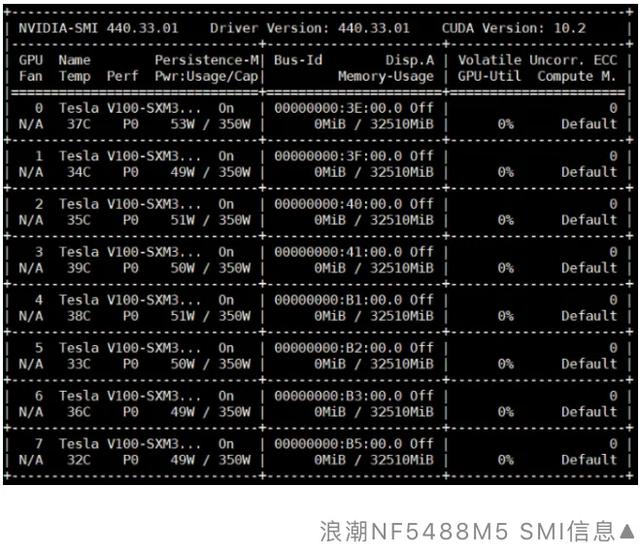
这比PCIe和SXM2版本的Tesla V100要高。尽管它们都被称为“Tesla V100” GPU,其性能差距其实十分显著。
浪潮NF5488M5的另一个关键特性是这块板上的互连情况。几年前,NVIDIA仅仅是使用PCIe连接GPU间的通信便实现了卓有成效的创新。而到了如今的 Pascal (Tesla P100) 一代,NVIDIA在SXM2模块中引入了NVLink。实际上,我们已经撰写过安装使用Tesla P100 的NVIDIA Tesla SXM2 GPU的指南。SXM2系统通常依赖于GPU与GPU间直接连接的拓扑结构,这就对系统的规模造成了限制。NF5488M5是一个带有NVswitch 的SXM3系统。在STH,我们曾讨论了第30届Hot Chips大会上披露的NVIDIA NVSwitch详细信息,当时 NVIDIA公司在大会上详细介绍了它们的工作方式。
在GPU板上总共有六个NVSwitch。通过NVSwitch将GPU进行全互联,NVIDIA可以提供GPU间最高300GB/s的带宽。八个GPU通过NVLink进行P2P通信,这实际上把它们变成了一个256GB HBM2的大型GPU组。

在这些照片中您可以看到,这些NVswitch需要拥有它们自己的热管冷却器。

您可能会注意到上面照片右侧的大型高密度连接器。它们都面向机箱前部,未在这里使用。通过一些调查,我们找到了原因。看到这里的GPU组,我们发现,GPU基板PCB上也有一个NVIDIA徽标。

我们在主板前部看到的高密度连接器是专用于16 GPU系统设计中,在两块HGX-2 基板间通过与NVSwitch相连的NV Bridge进行扩展连接。这是一种非常创新的做法,因为HGX-2对于许多数据中心机架环境来说过于密集,所以系统一般只有一个HGX-2基板。
下面,我们将看最后的机箱部分,然后展示系统拓扑结构,后者对此类服务器而言非常重要。