什么是正则?
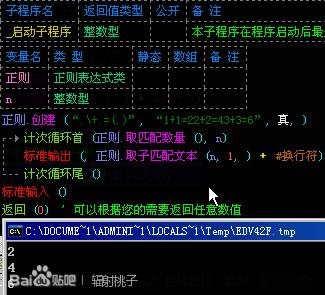
举个例子:我们现在百度一下“易语言”,搜索页面上出现了许多关于易语言的信息,那我们要怎样获取每条信息的标题和链接呢?
这时候我们就可以利用正则表达式从网页源码中寻找(匹配)到我们需要的文本,也就是信息的标题和链接。如下图:
现在,你还不许要了解图中代码的原理,
但是,当你学习完正则表达式后,你就会明白其中的原理了。
本教程共分为四课,共介绍了10多种正则的匹配符号。
第一课:简单的匹配符号“.?*+”
本课教程共介绍4种匹配符号,没错,是4种符号,看不见第一个“.”的请靠近屏幕再次查看。
第一节:单个字符的匹配“.”
“.”可以匹配除换行符之外的任何单个字符。
举个例子:我想把吧务中id是4个字符的全部都匹配出来。
“ e族程序猿
辐射桃子
揰掵佲
Cunxinsoft
易族花神
我要求助V
你问什么我来答
樉
Love2班star
小小小小宝哥
实验室之殇
1127158610
易语言100
鸟人水瓶”这是我们把吧务名单,每个id前后都有一个空格,并且用换行符分割,那么如果id是4个字符,我就可以用“....”,来匹配。
在这里,我讲解一下怎么样在易语言中使用正则表达式。
首先你需要一个正则表达式模块,
*载下**地址:网页链接
把这个模块调入到易语言里后,新建一个变量,类型为模块中正则表达式类,变量名叫正则就行。如图:

下面,使用正则.创建()来创建一个正则表达式。如图:

从图中我们可以看出正则.创建()的第一个参数我们已经想出来的“正则表达式”,第二个参数需要添“需要匹配的文本”,这两个参数都是文本型的。第三个参数,是否区分大小写,默认为不区分大小写。
这时候,我们可以使用正则.取匹配数量()来看看我们匹配到了多少个4个字符的id。如图:

我们匹配到了3个4个字符的id。
那我们怎样获取我们匹配id呢?
我们可以使用正则.取匹配文本()来获取我们匹配的第一个id。如图:
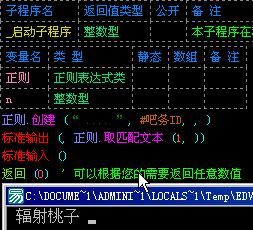
那么其他的id呢?如图:
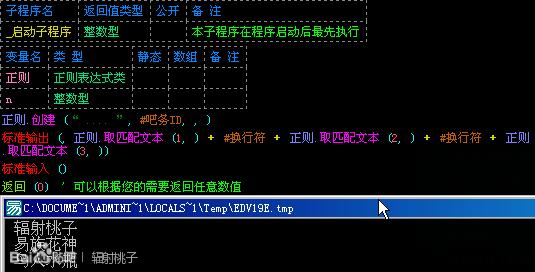
那么,让我来讲解一下的正则.取匹配文本()参数都表示什么。
第一个参数:匹配索引,也就匹配到的文本的序号。在正则中,索引从1开始,和数组的差不多。
既然知道了索引,我们就可以用另一种方法写代码了。如图:
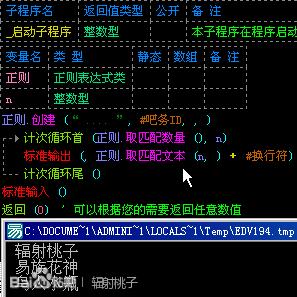
这样,我们就用“....”匹配出了我们想要的结果。
第二节:有或没有的“?”
“?”前面的东西可以有也可以没有。
举个例子:我想把吧务中id是3个或4个字符的都匹配出来。
那么我们就可以用“....?”来匹配了。
我来说明一下这个表达式的含义,我把“?”加在了一个“.”(任意一个)的后面。这就表示“?”前面的“.”可以有也可以没有。也就是说有“.”的时候,我们可以匹配4个字符的id。没“.”的时候,我们就可以匹配3个字符的id了。如图:
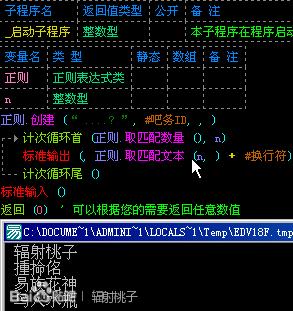
这样,我们就把id是3个字符的“揰掵佲”匹配了出来。
第三节:没有或有很多的“*”和一定有的“+”
为什么我们要把“*”和“+”放到一起讲呢?
因为它们很多时候是可以通用的。那么它们共用的特点是前面的东西可以有很多,而它们的不同点是“*”前面的东西可以没有,而“+”前面的东西必须有。
讲到这里,可能有些吧友还没有了解它们,那么咱们可以分别用“*”和“+”来对比一下。如图:
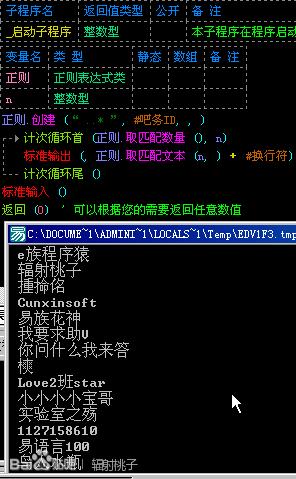
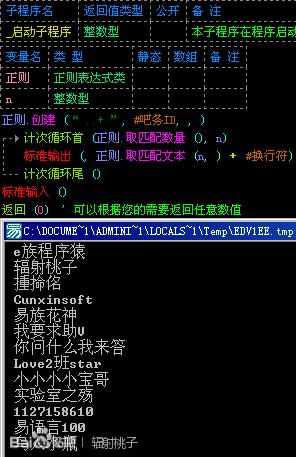
匹配之后,我们会发现“..*”比“..+”多匹配了一个单字符的id“樉”
这是为什么呢?咱们来分析一下吧。
不同之处:
在“..*”中,我们把“*”写在任意一个“.”的后面,表示这个“.”可以没有,也就是说“..*”可以等价与“.”,那么我们就可以到匹配单字符id“樉”了。
在“..+”中,我们把“+”写在任意一个“.”的后面,表示这个“.”必须有,也就是说“..+”至少也要等价与“..”。那么我们就不能匹配单字符id的“樉”了。
相同之处:
在“..*”和“..+”中,“*”和“+”可以前面的东西出现很多次(不包括上述中不同之处的情况)。也就是说他们可以等价与“...”、“....”、“.....”……
所以他们也可以匹配所有的多字符id。
第二课:括号括号括号“()[]{}”
本课教程共介绍3种匹配符号。对,没错,他们都是括号。
第一节:子文本或整体的“()”
“()”的用法有两种。
第一种用法:确定一个子文本,也就是说可以匹配到文本中的部分内容。
那么子文本有什么用呢?
举个例子:在第一课中,我们已经可以取出4个字符吧务id,但是我们取出的是前后包含空格的吧务id,那么我们怎样只把id取出来呢?
我们可以使用“()”把只表示id的4个“.”括起来。也就是说表达式应该变成“(....)”。
然后,我们要用一个新的命令正则.取子匹配文本()进行匹配。如图:
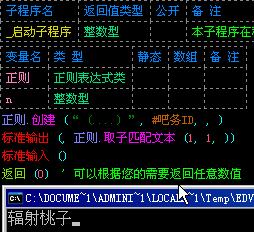
那么,我就来讲解一下正则.取子匹配文本()的参数都代表什么。
第一个参数,匹配到文本的索引,也就是正则.匹配文本()中的索引。
第二个参数,子文本的索引,也就是被括号括起来的东西的序号,比如图中“....”被括起来了,他是第1个被括起来的东西,所以他的索引就是1。
第三个参数一般不使用,在这里不做讲解。
那么,我们同样可以使用循环命令来取出我们匹配到的所有4个字符的id。如图:
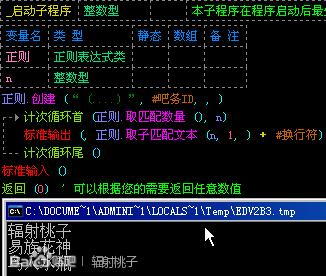
在这里,我们需要用计数器n代替的是匹配索引,而不是子文本的索引。因为我们需要的子文本始终都是第一个括号内的,也就是说索引始终是1。
到这里,“()”的第一种用法已经讲完了。
第二种用法:被“()”括起来的东西表示一个整体。
这种用法可以把很多的个体表示成一个整体。比如:“....?”和“.(...)?”在第一个表达式中,“?”能够影响的只有前面的一个“.”。而第二个表达式中,“?”可以影响到前面的“...”,因为“...”被“()”括起来了,所以说他能被当作一个整体。
在这里,我就要多讲一种字符“|”,因为“|”经常和“()”搭配。
提示:Shift+反斜杠(\)就可以打出来这个符号。
那么怎样组合“()”和“|”呢?
我们可以用“(文本1|文本2|.....|文本n)”来进行匹配“文本1、文本2……文本n”。
举个例子:在第一课中,我们已经可以通过“?”来匹配3个或4个字符的id,那么我们也可以用本节课的知识来写一个新的表达式“(....|...)”。如图:
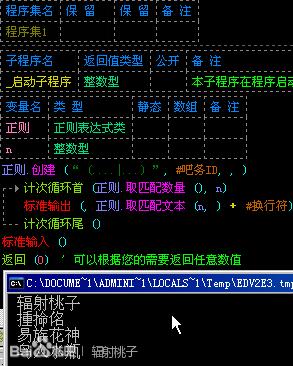
同样的,我们也可以使用“()”表示子文本的用法。如图:
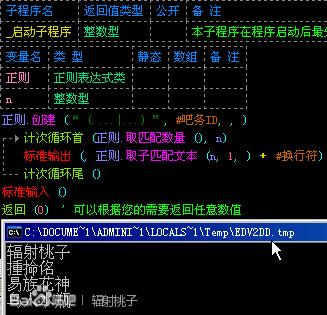
第二节:范围的表达“[]”
在“[]”内输入一个范围,就可以匹配范围内的字符。
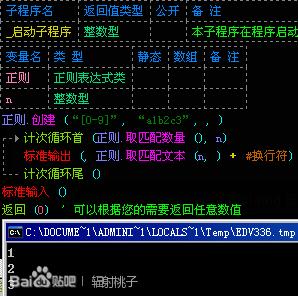
举个例子:“[0-9]”可以匹配所有的数字,我们就可以用“[0-9]”匹配“a1b2c3”中的“1”、“2”和“3”。如图:
我们还可以通过一个字符“^”来过滤范围中的字符。
举个例子:“[^0-9]”可以匹配不是数字的任何字符,也就是说它可以匹配“a1b2c3”中的“a”、“b”和“c”。如图:

同样的我们还可以用“[a-z]”匹配小写字母、“[A-Z]”匹配大写字母,如图:
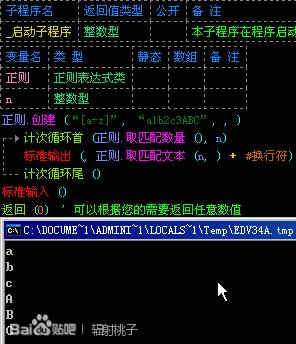
咦?我明明输入的表达式“[a-z]”是用来匹配小写字母的,为什么大写字母也会被匹配呢?
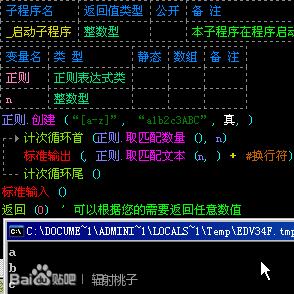
还记得我们讲第一课的时候说过正则.创建()的第三个参数“是否区分大小写”吗?这个参数默认为假,也就是说“[a-z]”在无视大小写的情况下可以等价与“[A-Z]”,所以我们才可以用“[a-z]”匹配到大写字母。正确的情况,如图:
第三节:数量的表达“{}”
有的时候,我们可能会碰到这样的问题:
有这样一段文本“a=8asa;a=as47;a=vd;a=dsf;”,我想匹配“8asa”、“as47”、“vd”和“dsf”。然后我就写了这样一串表达式“a=(.*);”,然后用正则.取子匹配文本(),结果....我却匹配到了这样的结果:“8asa;a=as47;a=vd;a=dsf”。如图:
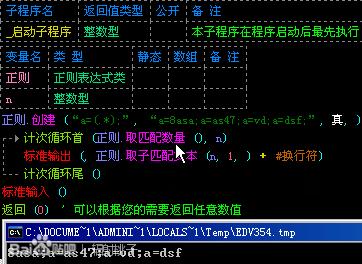
我仔细一想:也对...我这样写表达式的确可以匹配出来这样的结果,但是这并不是我想要得结果。
那么我们该怎么办呢?
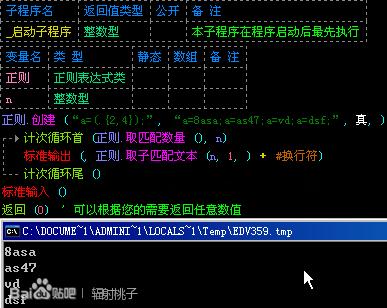
问题的原因就出在我们没有限定“.”出现次数的范围,这时候我们就可以使用“{}”来确定前面的东西出现的次数。用法:“{n}”前面的东西出现n次。“{n,}”前面的东西至少出现n次。“{n,m}”前面的东西出处先n~m次。
然我们回到刚才的问题,这下,我们要用“{}”来限制“.”出现2~4次,表达式为“a=(.{2,4});”。
这样我们就可以达到我们的要求了。如图:
第三课:位置的确定“^$\b\B”
本课教程共介绍2种匹配符号。他们可以对文本的位置做出限定。
第一节:后面的东西再开头“^”
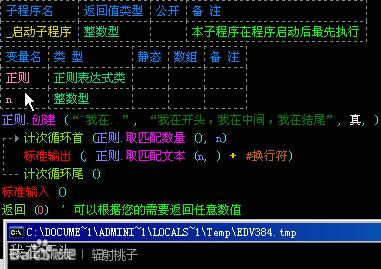
“^”后面的东西必须在在每行的开头。
举个例子:我有一段文本“我在开头,我在中间,我在结尾”,我现在想把开头的“我在哪”取出来,我就可以用“^我在..”。如图:
第二节:前面的东西在结尾“$”
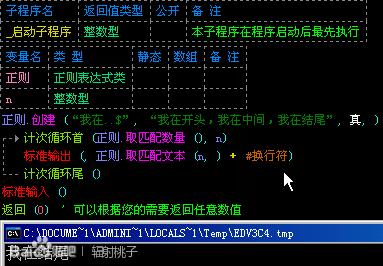
“$”前面的东西必须在在每行的结尾。
我们继续刚才的例子:
我如果想把文本结尾的“我在哪”取出来的话,我们就可以用“我在..$”。如图:
第三节:表示字母在不在单词边界的“\b\B”
这两个匹配字符好像比较特殊,因为经过我的测试,他跟中文好像不怎么搭,只能应用于字母、数字和下划线,所以说这个符号我们一般不太常用。
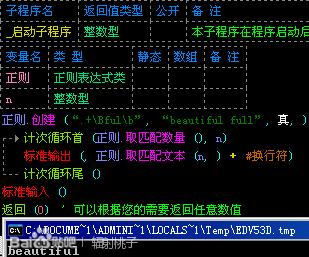
“\b”可以表示字母在单词的边界,“\B”可以表示字母不在单词的边界。
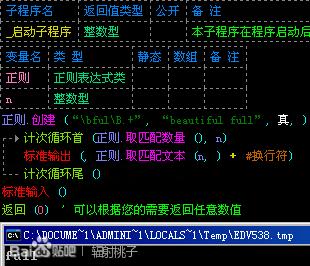
举个例子:“\B.+ful\b”就能匹配到“beautifulfull”中的“beautiful”。如图:
“\bful\B.+”就能匹配到“beautifulfull”中的“full”。如图:
第四课:指定种类的匹配“\d\D\w\W\s\S”以及转义符“\”
本课教程共介绍好多种匹配符号。但是没有几个是我们常用的。
第一节:“\d\D\w\W\s\S\b\B”
哎呦,这一大串都是什么呀?我一节课要学这么多东西?
不,这些东西你只需要了解就可以,因为很多时候我们都用不到他们。
那么他们都分别代表什么呢?
我只告诉大家和他们功能一样的表达式,然后简单的说明一下。
“\d”等价与“[0-9]”匹配数字。
“\D”等价与“[^0-9]”匹配不是数字的字符。
“\w”等价与“[a-zA-Z_]”匹配字母和下划线。
“\W”等价与“[^a-zA-Z_]”匹配不是字母和下划线的字符。
“\s”等价与“[\f\n\t\t\v]”匹配换页符、换行符、回车符、水平制表符和垂直制表符。
“\S”等价与“[^\f\n\t\t\v]”匹配不是换页符、换行符、回车符、水平制表符和垂直制表符的字符。
前四个都很好理解,但是后两个...什么这个符哪个符的...你可以理解为“空白的字符”也就是说没有实际意义的字符。
第二节:转义符“\”
恢复匹配符号的本意。
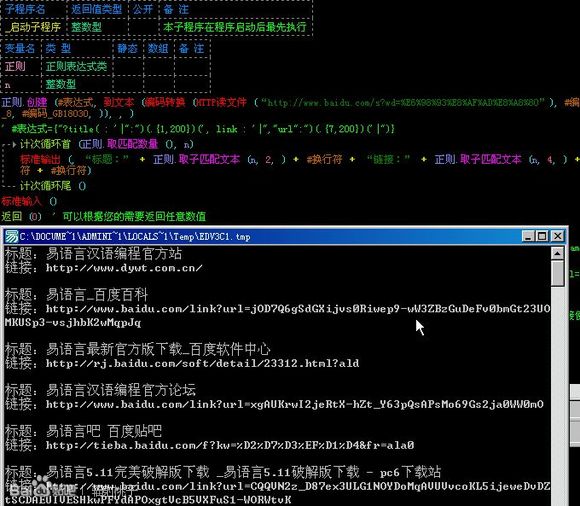
这个字符的用途可很广泛呀,比如说我想在“1+1=22+2=43+3=6”匹配个全部的答案,也就是说匹配“2”、“4”和“6”。
我就开动脑筋,写了个表达式“.+.=(.)”然后用正则.取子匹配文本()来匹配,但是出现问题了,为什么我匹配到了“6”?如图:
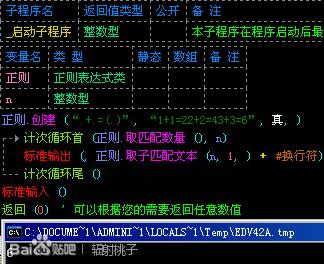
原来,“+”也是一个匹配符号,我们在第一课的时候学过的,表示前面的东西一定有或有很多,也就是说我们这个表达式可以等价与“.............=6”,也就是说他把整个文本都匹配到了。
那么我们怎样让这个“+”恢复本意变成普通的字符呢?
我们就可以用“\”来影响“+”,那么新的表达式就是“.\+.=(.)”。如图: