Kubernetes1.14 监控系统 Prometheus-operator 部署实战
Operator
Operator是由CoreOS公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识,比如创建一个数据库的Operator,则必须对创建的数据库的各种运维方式非常了解,创建Operator的关键是CRD(自定义资源)的设计。
CRD是对 Kubernetes API 的扩展,Kubernetes 中的每个资源都是一个 API 对象的集合,例如我们在YAML文件里定义的那些spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operator是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
资源:对象的状态定义
控制器:观测、分析和行动,以调节资源的分布
Prometheus-Operator 架构图

上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
关于 Prometheus-Operator 四种资源对象的解释
- Prometheus 是控制创建Prometheus server 集群,在k8s中表现为pod
- ServiceMonitor 是exporter的各种抽象,exporter是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的
- alertmanager 是控制创建alertmanager 集群
- PrometheusRule 用来定义报警规则文件
安装
采用helm chart 安装
创建ingress tls
kubectl create secret tls prometheus-yun-cn-tls --cert=yun.cer --key=yun.key -n monitoring
修改 Prometheus chart value.yaml
helm fetch stable/prometheus-operator --untar
vim value.yaml
# 开启prometheus 的数据落地
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: rook-ceph-block
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 5Gi
# 修改prometheus-ser 和 AlertManager 的replicas 开启高可用
replicas: 3
# 修改grafana 登录密码
grafana:
enabled: true
defaultDashboardsEnabled: true
adminPassword: admin@123
# 开启 grafana alertmanager prometheus ingress
$ [K8sDev] grep -w "ingress:" values.yaml -A 32|grep -vE "#|^$"
ingress:
enabled: true
annotations:
kubernetes.io/ingress.class: public-nginx
labels: {}
hosts:
- alertmanager.yun.cn
paths:
- /
tls:
- secretName: prometheus-yun-cn-tls
hosts:
- alertmanager.yun.cn
--
ingress:
enabled: ture
annotations:
kubernetes.io/ingress.class: public-nginx
labels: {}
hosts:
- grafana.yun.cn
path: /
tls:
- secretName: prometheus-yun-cn-tls
hosts:
- grafana.yun.cn
--
ingress:
enabled: ture
annotations:
kubernetes.io/ingress.class: public-nginx
labels: {}
hosts:
- prometheus.yun.cn
paths:
- /
tls:
- secretName: prometheus-yun-cn-tls
hosts:
- prometheus.yun.cn
部署
kube-state-metrics 的作用是采集k8s集群监控指标的,部署阶段拉取镜像可能会有问题,可以事先在每个node上拉取阿里云的镜像,然后tag
docker pull registry.aliyuncs.com/google_containers/kube-state-metrics:v1.5.0 && docker tag registry.aliyuncs.com/google_containers/kube-state-metrics:v1.5.0 k8s.gcr.io/kube-state-metrics:v1.5.0 kubectl create ns monitoring helm install --name prometheus-operator -f values.yaml . --namespace monitoring # 查看pod kubectl get pod -n monitoring NAME READY STATUS RESTARTS AGE alertmanager-prometheus-operator-alertmanager-0 2/2 Running 0 14m alertmanager-prometheus-operator-alertmanager-1 2/2 Running 0 14m alertmanager-prometheus-operator-alertmanager-2 2/2 Running 0 14m prometheus-operator-grafana-5d74ccd7bd-zvzm9 2/2 Running 0 16m prometheus-operator-kube-state-metrics-5d7558d7cc-hgbdr 1/1 Running 0 6m5s prometheus-operator-operator-58f46454f8-nxrns 1/1 Running 0 16m prometheus-operator-prometheus-node-exporter-8vvgk 1/1 Running 0 16m prometheus-operator-prometheus-node-exporter-dzh88 1/1 Running 0 16m prometheus-operator-prometheus-node-exporter-fbmtj 1/1 Running 0 16m prometheus-operator-prometheus-node-exporter-ln5jk 1/1 Running 0 16m prometheus-operator-prometheus-node-exporter-p56xb 1/1 Running 0 16m prometheus-prometheus-operator-prometheus-0 3/3 Running 1 14m prometheus-prometheus-operator-prometheus-1 3/3 Running 1 14m # 查看 service ingress kubectl get service,ingress -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 60m service/prometheus-operated ClusterIP None <none> 9090/TCP 60m service/prometheus-operator-alertmanager ClusterIP 10.100.184.96 <none> 9093/TCP 62m service/prometheus-operator-grafana ClusterIP 10.100.93.41 <none> 80/TCP 62m service/prometheus-operator-kube-state-metrics ClusterIP 10.98.180.207 <none> 8080/TCP 62m service/prometheus-operator-operator ClusterIP 10.103.61.39 <none> 8080/TCP 62m service/prometheus-operator-prometheus ClusterIP 10.97.234.73 <none> 9090/TCP 62m service/prometheus-operator-prometheus-node-exporter ClusterIP 10.106.114.236 <none> 9100/TCP 62m NAME HOSTS ADDRESS PORTS AGE ingress.extensions/prometheus-operator-alertmanager alertmanager.yun.cn 80, 443 20m ingress.extensions/prometheus-operator-grafana grafana.yun.cn 80, 443 20m ingress.extensions/prometheus-operator-prometheus prometheus.yun.cn 80, 443 20m
Hosts 绑定
10.6.201.174 alertmanager.yun.cn 10.6.201.174 grafana.yun.cn 10.6.201.174 prometheus.yun.cn
访问测试

ServiceMonitor
监控etcd
修改ectd启动参数
helm 安装的 prometheus 会自动创建servicemonitor 去监控etcd,但是kubernetes1.14中的etcd版本是3.3.10,3.3.10以后的metrics 和 health接口已经配置通过一个独立的配置项--listen-metrics-urls 开放出来,所以要修改etcd的yaml来重新启动etcd
# 在command 追加,大概1min左右etcd就会重启完毕 vim /etc/kubernetes/manifests/etcd.yaml - --listen-metrics-urls=http://192.168.137.102:2381
创建serviceMonitor
helm 已经自动为etcd创建了一个serviceMonitor
kubectl get servicemonitors.monitoring.coreos.com -n monitoring prometheus-operator-kube-etcd -o yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: creationTimestamp: 2019-05-23T01:46:55Z generation: 1 labels: app: prometheus-operator-kube-etcd chart: prometheus-operator-5.0.11 heritage: Tiller release: prometheus-operator name: prometheus-operator-kube-etcd namespace: monitoring resourceVersion: "28021953" selfLink: /apis/monitoring.coreos.com/v1/namespaces/monitoring/servicemonitors/prometheus-operator-kube-etcd uid: a5284d89-7cfc-11e9-97f1-fa163e92035a spec: endpoints: - bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token port: http-metrics # 匹配service port jobLabel: jobLabel namespaceSelector: matchNames: - kube-system selector: matchLabels: app: prometheus-operator-kube-etcd # 匹配service labels release: prometheus-operator # 匹配service labels
创建service/endpoints
serviceMonitor 监控 应用是通过selector 匹配 lable监控pod的service的/metrics接口来获取监控数据的
所以现在我们要为etcd 创建service、endpoints,serviceMonitor才能拿到监控数据
vim prometheus-etcdService.yaml apiVersion: v1 kind: Service metadata: name: etcd-k8s namespace: kube-system labels: app: prometheus-operator-kube-etcd release: prometheus-operator spec: selector: component: etcd type: ClusterIP clusterIP: None ports: - name: http-metrics port: 2381 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: name: etcd-k8s namespace: kube-system labels: app: prometheus-operator-kube-etcd release: prometheus-operator subsets: - addresses: - ip: 192.168.137.102 # master 主机ip nodeName: master-102 # master 主机名 ports: - name: http-metrics port: 2382 protocol: TCP kubectl create -f prometheus-etcdService.yaml
查看prometheus--->targets 页面 发现etcd状态已经是UP了

查看grafana 就可以看到etcd的监控数据了
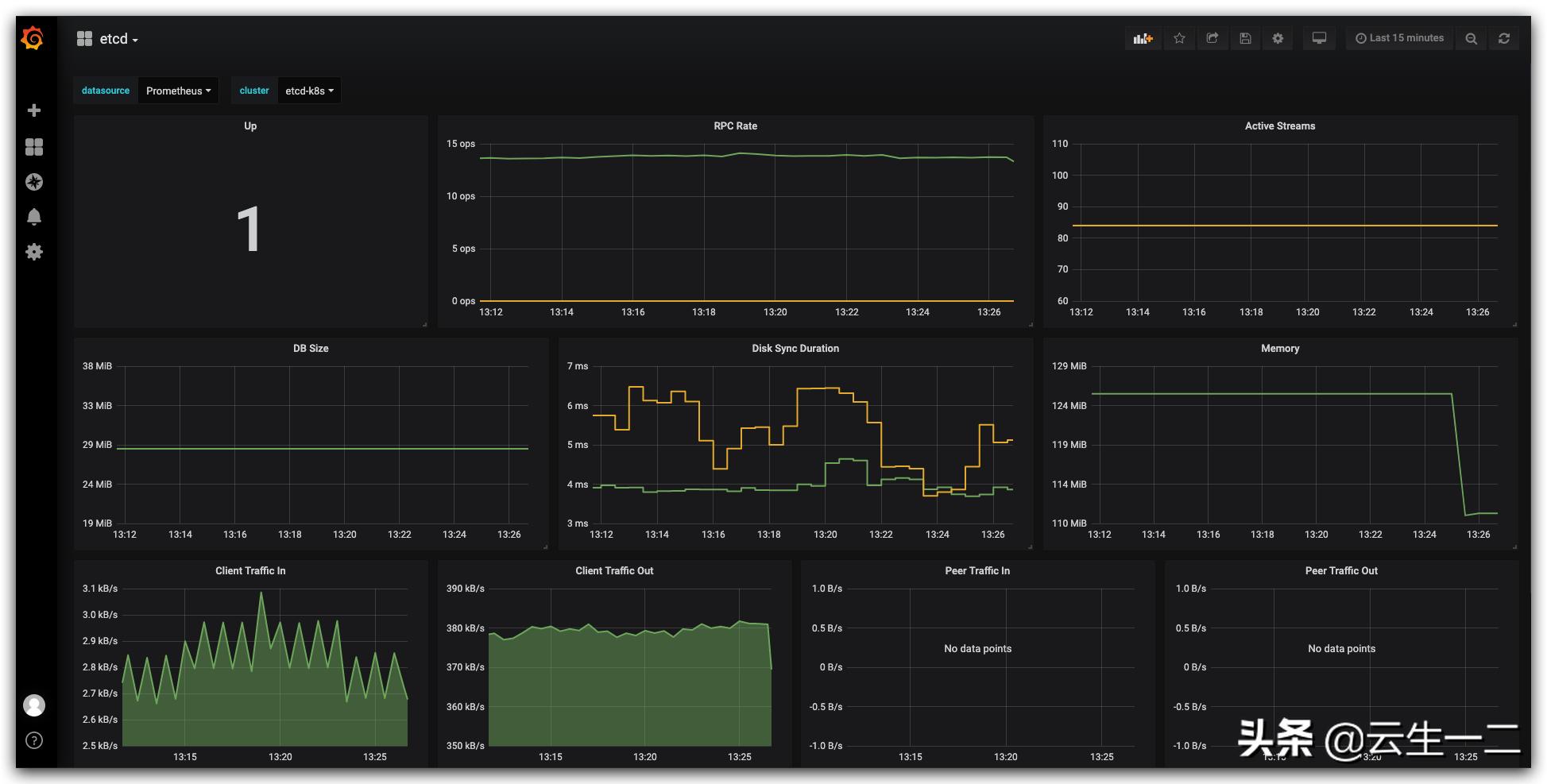
Grafana 配置
grafana 基本不需要配置,operator 已经把我们用到的监控模板内置了
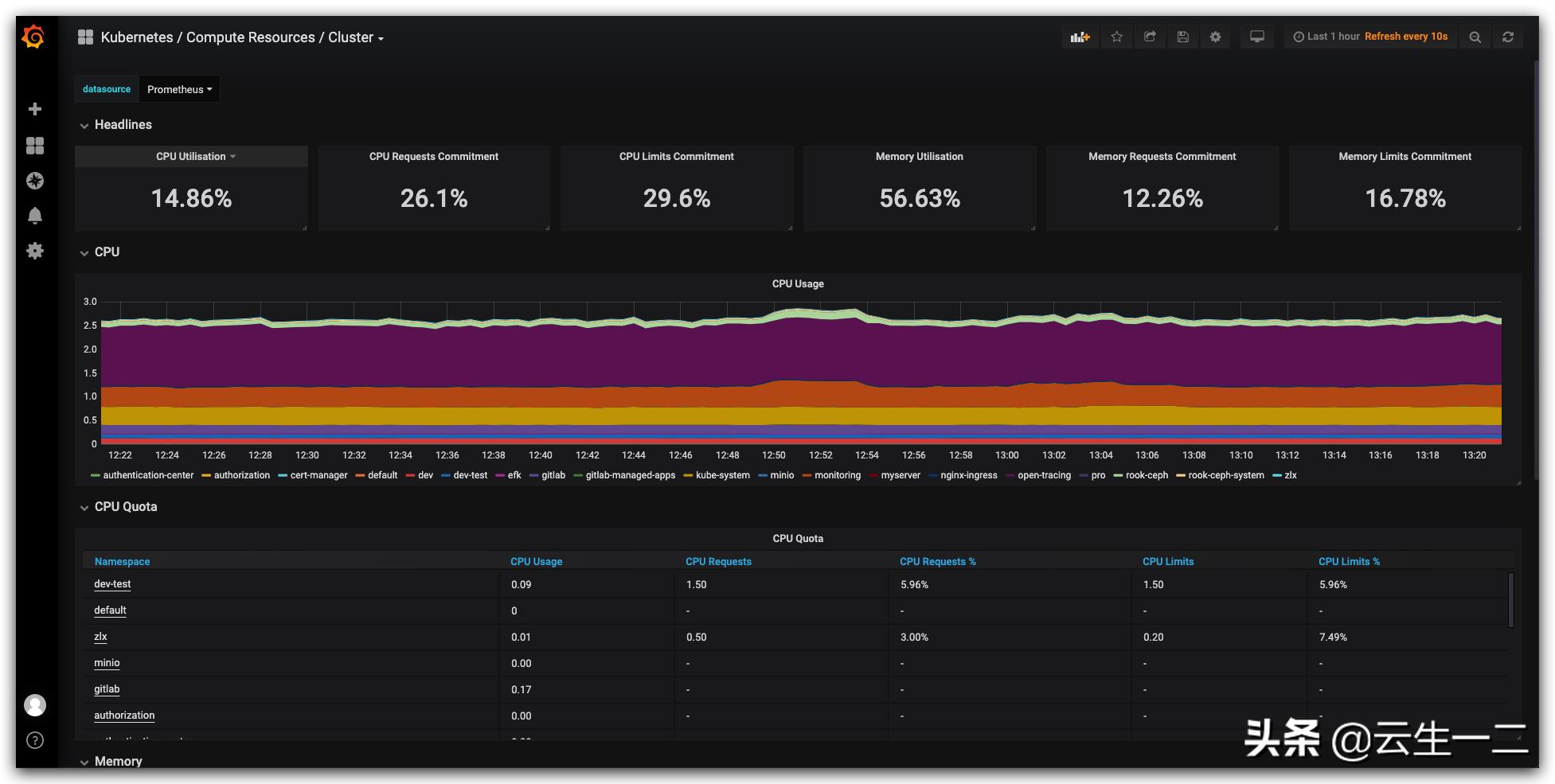
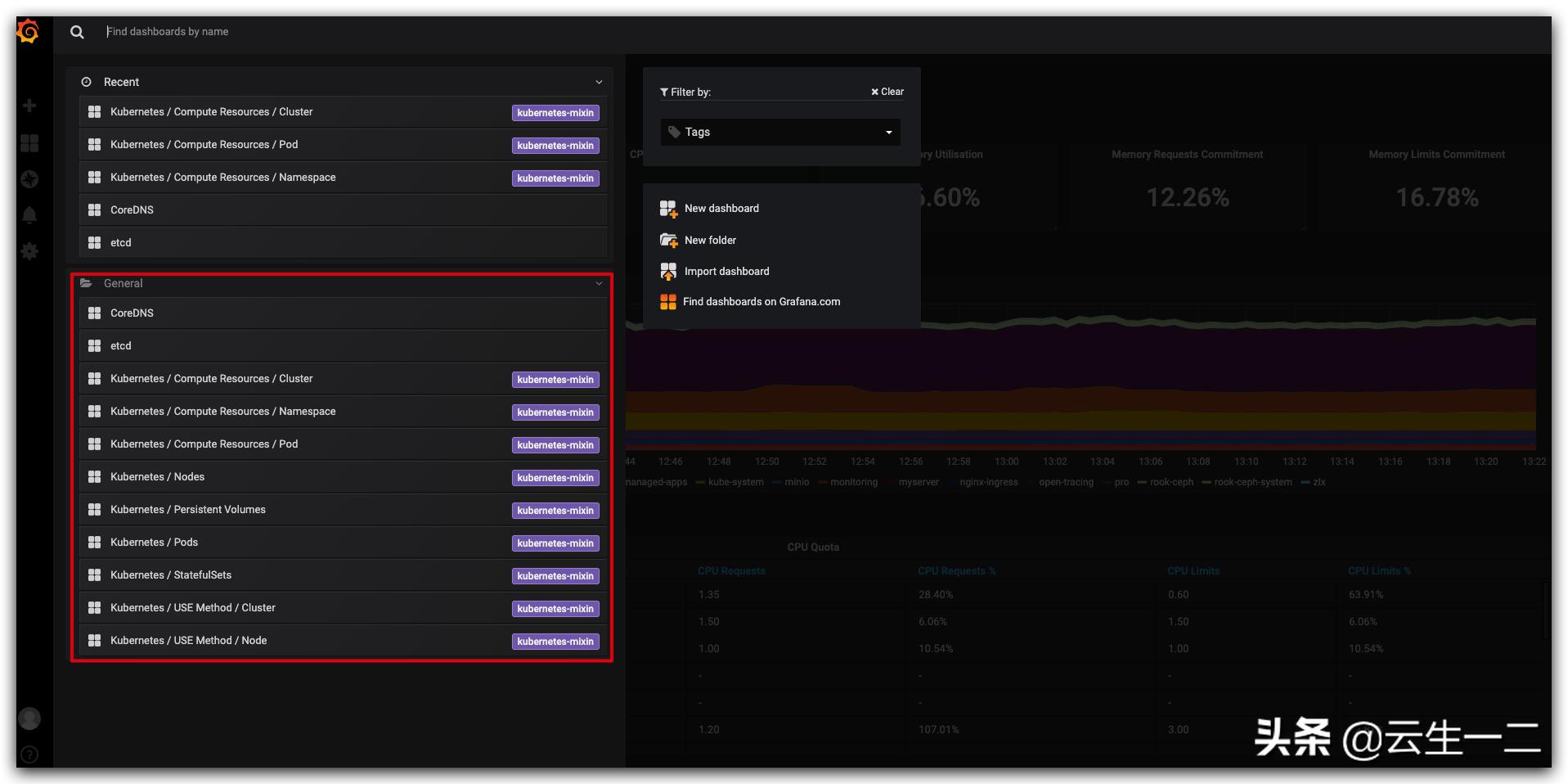
配置监控报警接收
查看secret
- alertmanager 报警接收者的信息是配置在secret 中,所以我们要找到这个secret
$ [K8sDev] kubectl get secrets -n monitoring NAME TYPE DATA AGE alertmanager-prometheus-operator-alertmanager Opaque 1 3h58m default-token-fjqg7 kubernetes.io/service-account-token 3 4h2m prometheus-yun-cn-tls kubernetes.io/tls 2 3h33m prometheus-operator-alertmanager-token-rtrwt kubernetes.io/service-account-token 3 3h58m prometheus-operator-grafana Opaque 3 3h58m prometheus-operator-grafana-token-pllv5 kubernetes.io/service-account-token 3 3h58m prometheus-operator-kube-state-metrics-token-x7qs4 kubernetes.io/service-account-token 3 3h58m prometheus-operator-operator-token-sxn65 kubernetes.io/service-account-token 3 3h58m prometheus-operator-prometheus-node-exporter-token-m7twt kubernetes.io/service-account-token 3 3h58m prometheus-operator-prometheus-token-5gt5m kubernetes.io/service-account-token 3 3h58m prometheus-prometheus-operator-prometheus Opaque 1 3h56m
- 可以看到第一个secret alertmanager-prometheus-operator-alertmanager 应该就是,输出看下
$ [K8sDev] kubectl get secrets -n monitoring alertmanager-prometheus-operator-alertmanager -o yaml apiVersion: v1 data: alertmanager.yaml: Z2xvYmFsOgogIHJlc29sdmVfdGltZW91dDogNW0KcmVjZWl2ZXJzOgotIG5hbWU6ICJudWxsIgpyb3V0ZToKICBncm91cF9ieToKICAtIGpvYgogIGdyb3VwX2ludGVydmFsOiA1bQogIGdyb3VwX3dhaXQ6IDMwcwogIHJlY2VpdmVyOiAibnVsbCIKICByZXBlYXRfaW50ZXJ2YWw6IDEyaAogIHJvdXRlczoKICAtIG1hdGNoOgogICAgICBhbGVydG5hbWU6IFdhdGNoZG9nCiAgICByZWNlaXZlcjogIm51bGwiCg== kind: Secret metadata: creationTimestamp: 2019-05-23T01:46:54Z labels: app: prometheus-operator-alertmanager chart: prometheus-operator-5.0.11 heritage: Tiller release: prometheus-operator name: alertmanager-prometheus-operator-alertmanager namespace: monitoring resourceVersion: "28021773" selfLink: /api/v1/namespaces/monitoring/secrets/alertmanager-prometheus-operator-alertmanager uid: a4c7b6fe-7cfc-11e9-97f1-fa163e92035a type: Opaque
- base64 解密data
$ [K8sDev] echo "Z2xvYmFsOgogIHJlc29sdmVfdGltZW91dDogNW0KcmVjZWl2ZXJzOgotIG5hbWU6ICJudWxsIgpyb3V0ZToKICBncm91cF9ieToKICAtIGpvYgogIGdyb3VwX2ludGVydmFsOiA1bQogIGdyb3VwX3dhaXQ6IDMwcwogIHJlY2VpdmVyOiAibnVsbCIKICByZXBlYXRfaW50ZXJ2YWw6IDEyaAogIHJvdXRlczoKICAtIG1hdGNoOgogICAgICBhbGVydG5hbWU6IFdhdGNoZG9nCiAgICByZWNlaXZlcjogIm51bGwiCg==" |base64 -D global: resolve_timeout: 5m receivers: - name: "null" route: group_by: - job group_interval: 5m group_wait: 30s receiver: "null" repeat_interval: 12h routes: - match: alertname: Watchdog receiver: "null"
- 在界面上查看alertmanager 配置,发现和解密出的基本一致

- 修改secret
- 将上面解密出来的数据保存到文件"alertmanager.yaml",并修改
global: resolve_timeout: 5m smtp_smarthost: 'smtp.163.com:25' smtp_from: 'chulinx@163.com' smtp_auth_username: '<email>' smtp_auth_password: '<邮箱授权码>' smtp_hello: '163.com' smtp_require_tls: false route: group_by: ['job', 'severity'] group_wait: 30s group_interval: 5m repeat_interval: 12h receiver: default receivers: - name: 'default' email_configs: - to: '547571608@qq.com' send_resolved: true
- 重新创建secret
kubectl delete secrets -n monitoring alertmanager-prometheus-operator-alertmanager kubectl create secret generic alertmanager-prometheus-operator-alertmanager --from-file=alertmanager.yaml -n monitoring
- 界面查看,已经生效
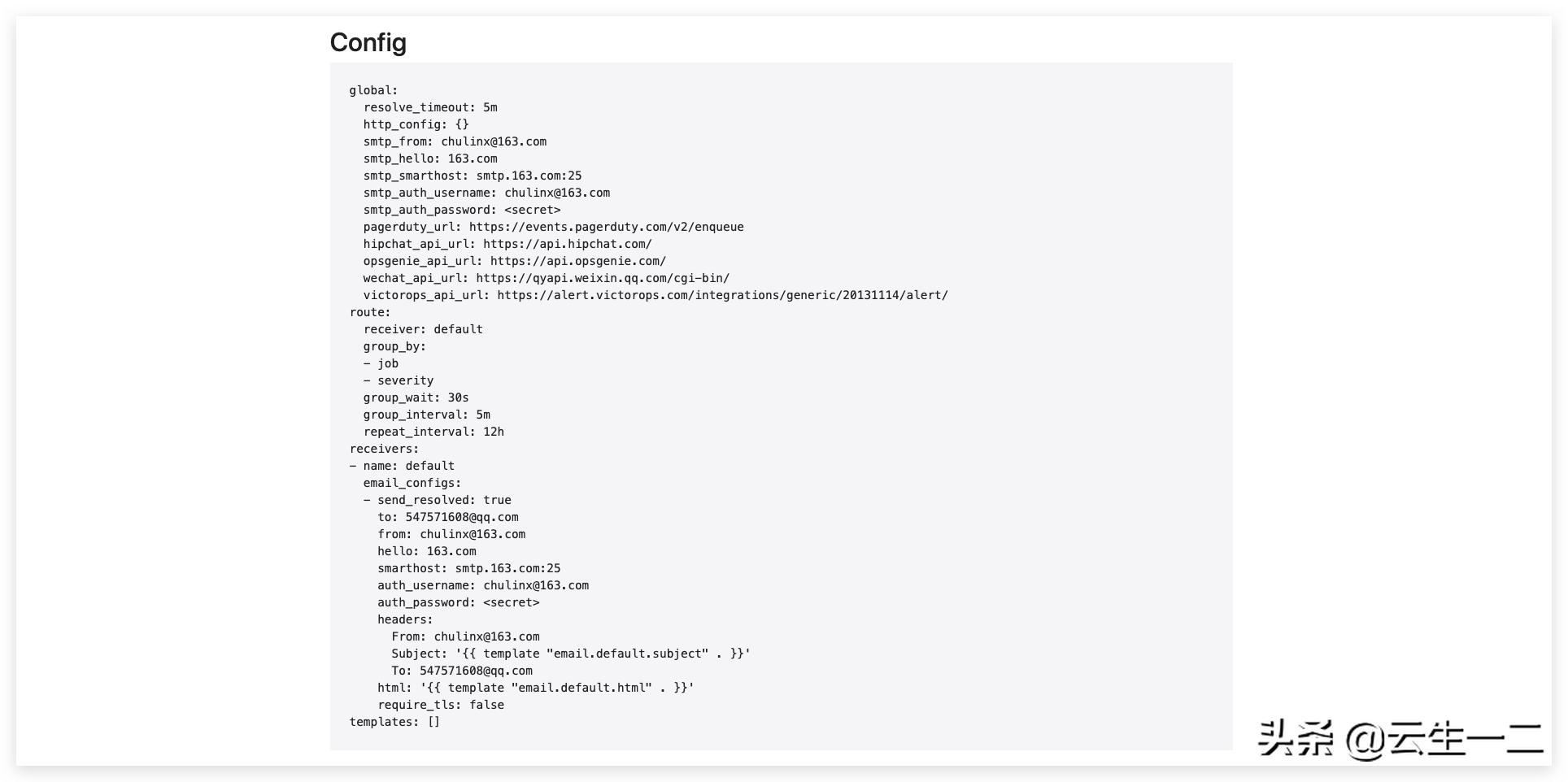
查看报警
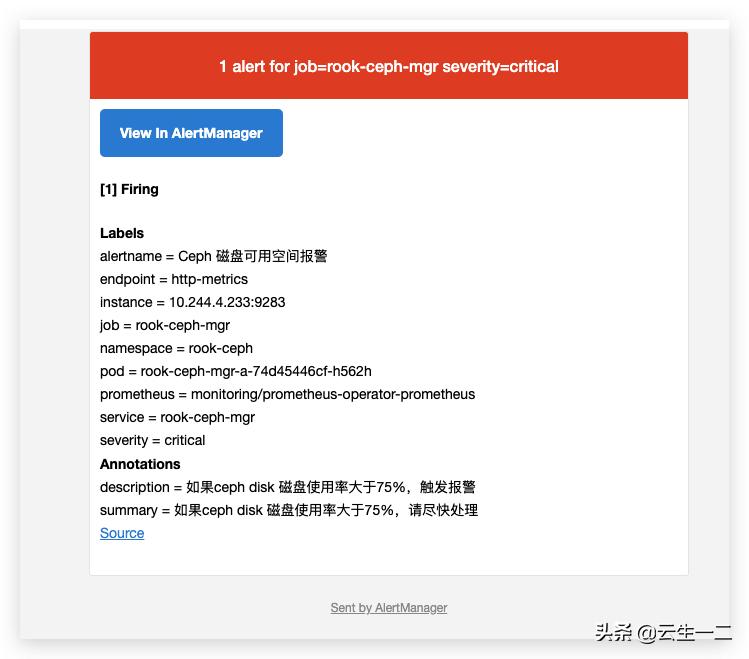
- 登录邮箱查看报警邮件
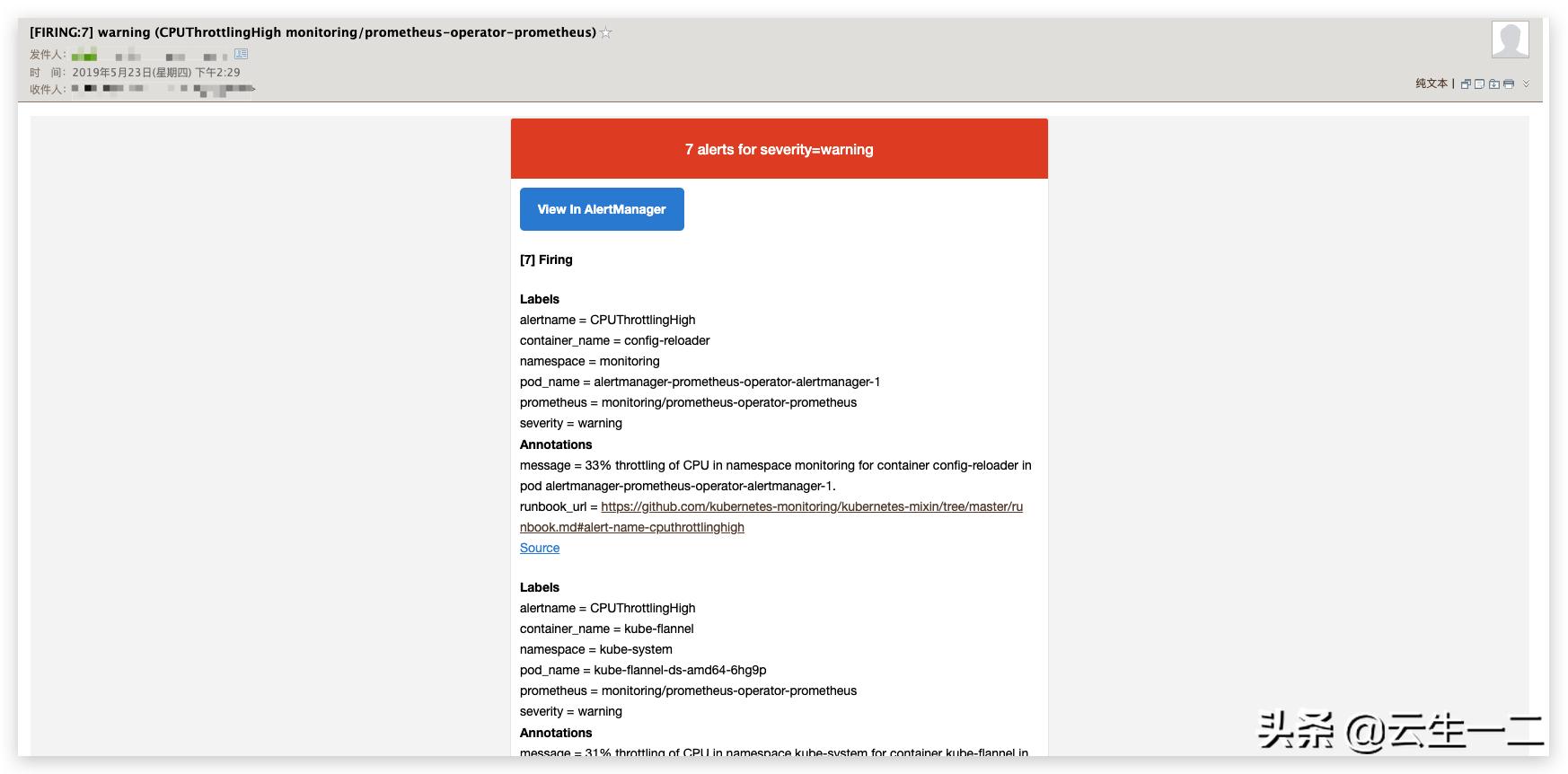
rook-ceph监控
创建service、endpoints
rook 也是原生支持prometheus的,metrics 是由mgr暴露的,安装rook的时候已经给我们创建了service/endpoints
kubectl get endpoints,svc -n rook-ceph NAME ENDPOINTS AGE endpoints/rook-ceph-mgr 10.244.4.233:9283 141d endpoints/rook-ceph-mgr-dashboard 10.244.4.233:443 141d endpoints/rook-ceph-mon-a 10.244.1.70:6790 141d endpoints/rook-ceph-mon-c 10.244.3.179:6790 141d endpoints/rook-ceph-mon-d 10.244.4.232:6790 96d NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/rook-ceph-mgr ClusterIP 10.103.95.20 <none> 9283/TCP 141d service/rook-ceph-mgr-dashboard ClusterIP 10.107.244.166 <none> 443/TCP 141d service/rook-ceph-mon-a ClusterIP 10.104.65.218 <none> 6790/TCP 141d service/rook-ceph-mon-c ClusterIP 10.111.140.231 <none> 6790/TCP 141d service/rook-ceph-mon-d ClusterIP 10.103.72.214 <none> 6790/TCP 96d
创建serviceMonitor
vim prometheus-serviceMonitorRook.yaml apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitor metadata: name: rook-ceph-mgr namespace: monitoring labels: app: prometheus-operator-rookceph chart: prometheus-operator-5.0.11 heritage: Tiller release: prometheus-operator app: rook-ceph-mgr rook_cluster: rook-ceph spec: jobLabel: rook-app endpoints: - port: http-metrics interval: 30s selector: matchLabels: app: rook-ceph-mgr rook_cluster: rook-ceph namespaceSelector: matchNames: - rook-ceph
查看endpoint

导入rook 监控模板
- ROOK 官方推荐的三个dashboards
- Ceph - Cluster
- Ceph - Pools
- Ceph - OSD

PrometheusRule
Prometheus-Operator 把AlertManager 的监控规则抽象为一个k8s中的crd,这个crd就是PrometheusRule,我们来看下如何指定一个监控规则(PrometheusRule)
自定义rook-ceph 磁盘使用率报警
vim prometheus-rookCephRules.yaml apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: app: prometheus-operator # lables 安装operator 已经创建的rule来写,operator会根据lables选择 chart: prometheus-operator-5.0.11 heritage: Tiller release: prometheus-operator name: rook-ceph-rules namespace: monitoring spec: groups: - name: rook-ceph rules: - alert: Ceph 磁盘可用空间报警 annotations: summary: 如果ceph disk 磁盘使用率大于75%,请尽快处理 description: 如果ceph disk 磁盘使用率大于75%,触发报警 expr: | (ceph_cluster_total_used_bytes/ceph_cluster_total_bytes)*100 > 75 for: 3m labels: severity: critical kubectl create -f prometheus-rookCephRules.yaml
Prometheus Alerts 页面可以看到我们定义的 rule

模拟故障发送报警邮件
将阈值调整到10,触发报警
apiVersion: monitoring.coreos.com/v1 kind: PrometheusRule metadata: labels: app: prometheus-operator # lables 安装operator 已经创建的rule来写,operator会根据lables选择 chart: prometheus-operator-5.0.11 heritage: Tiller release: prometheus-operator name: rook-ceph-rules namespace: monitoring spec: groups: - name: rook-ceph rules: - alert: Ceph 磁盘可用空间报警 annotations: summary: 如果ceph disk 磁盘使用率大于75%,请尽快处理 description: 如果ceph disk 磁盘使用率大于75%,触发报警 expr: | (ceph_cluster_total_used_bytes/ceph_cluster_total_bytes)*100 > 10 for: 3m labels: severity: critical kubectl apply -f prometheus-rookCephRules.yaml