AHP
AHP:解析分层进程(analytic hierarchy process),层次分析法。
它为我们提供了一种强有力的工具,这种工具能够在涉及多个目标的情况下做出决策。
例如:
(1)在选择购买手机的过程中,你可能主要考虑手机的下列因素:
因:素1:价格
因素2:屏幕大小
因素3:手机的品牌
因素4:手机的存储空间
因素5:手机处理器性能
(2)在选择接受哪一份工作的时候,你可能主要考虑以下几个目标:
目标1:对工作的兴趣
目标2:工作的薪资水平
目标3:工作所带来的生活质量
目标4:离家远近
(3)在考察干部的时候,要对多名干部考察排序,组织部门要从“德、能、勤、绩、廉”几个方面对考察对象进行综合评价,结果将作为干部选聘的重要依据之一。
诸如此类的问题实质就是个多目标决策的问题。
然而,当多个目标对决策者都很重要的时候,决策者可能很难作出选择。
例如,在求职的时候,一份工作可能薪资水平相对高,但是离家远,工作带来的生活质量不高;在考察干部的时候,“德、勤、廉”评价都很好,但是被考察对象的能力一般,业绩平平。在这样的情况下,决策者就很难在多个目标或者因素中进行选择。
在这样的场景下,AHP为我们提供一种解决这类问题的科学方法。
AHP基本思路
对被选对象在多个目标下计算综合评分。根据每个对象的最终得分,确定最满意的选择。
综合得分=目标权重*被评价对象在每个目标上的相对分值
例如:
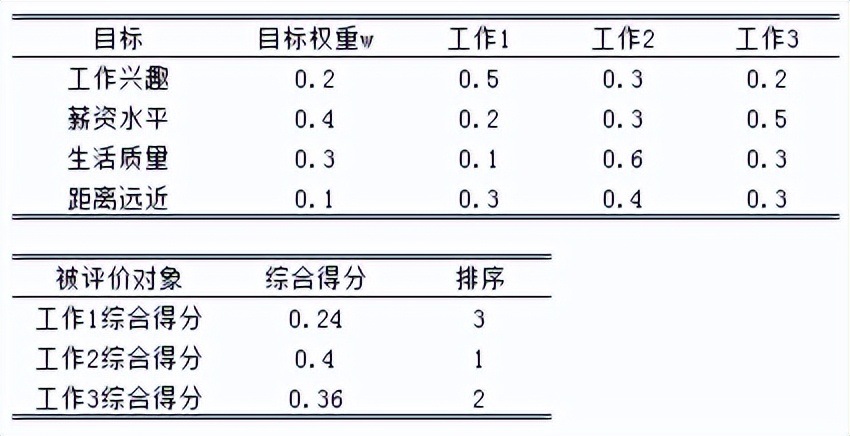
显然,工作2的综合得分最高,理性的选择下,应该接受工作2。
AHP计算程序
通过上面的举例,我们要计算出被评价对象的综合得分,需要知道目标因素的权重值,同时需要知道每个工作在同一个目标下的相对得分值。
然而,这两项数值如何得出呢?
我们试想,其实人的决策过程就是在每个对象针对每个目标的相对重要程度的判断和比对,越重要您可能越在意,“因为它很重要,所以我必须要考虑”,“因为它对我很有意义,所以我非常珍惜”,“我更喜欢前者”......诸如此类的心理纠结过程正是表达出该目标相对其他目标更重要。
为此,我们可以将所有目标因素做两个比较,形成一个成对比较矩阵。矩阵里的数据做如下约定:

每一个被评价对象针对每一个目标依然可以采用这样思路来进行“数字化”,把相对比较转化为成对比较矩阵。
显然,目标1如果相对目标2的重要性得分为3的话,目标2相对目标1的重要性得分就应该为1/3,它们之间互为倒数关系。因此,成对比较矩阵将是一个“反对称矩阵”。
反对称阵是否表征出一致的重要性
通过上面的思考和分析,我们知道表征重要性程度的矩阵一定是一个“反对称阵”,那么是不是只要是反对称矩阵就一定能正确表征出重要性程度呢?我们先看个例子:
假设有下面的表征重要性程度的成对比较矩阵:

不妨做如下推导,看看会得出什么结论:
(1)该矩阵是成对比较“反对称阵”;
(2)factor1=2*factor2,factor2=1/2*factor3
故:factor1= factor3
又:原矩阵中,factor1=3*factor3,显然与之产生了矛盾。
这样的矛盾,我们称之为“数据不一致性”,如果成对比较反对称阵数据不一致,将会导致严重的问题。
通常在理论上通过“一致性指数”在检验数据的一致性。关于一致性指数,后边介绍。
权重的计算
假设有n个目标,wi表示给定目标i的权重。同时给出的成对比较矩阵是完全一致的。

我们先做如下计算:
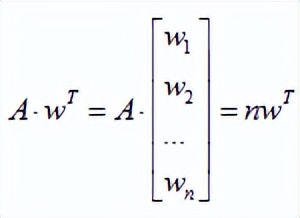
根据《线性代数》有关线性方程求解的理论可知:
A是n阶方阵,若存在数λ和非零向量X,使得:AX=λX,则:
(1)λ是A的一个特征值
(2)x是A的对应特征值λ的特征向量
显然,我们可以得出以下结论:
(1)n是A的一个特征值
(2)w是A的对应于 n的特征向量
故此,要求出w只需求出A的特征值和特征向量即可。
判断矩阵一致性的度量
一致性判断矩阵A(反对称可逆方阵)具有如下性质:
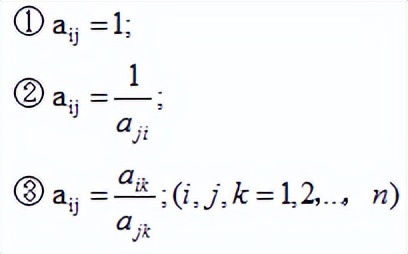
如果矩阵A是严格一致的判断方阵(一致性判断反对称阵)那么w就是与n对应的特征向量值。
遗憾的是,人们在评价的时候不总是人人都能做到一致性判断,往往给出的判断都有一定程度的“矛盾”因此,在运用该矩阵理论求解得出的结论会有一定程度的偏差,但偏差程度如果在人们可接受的范围,则我们依然认为解是有效的,即w有效。
如何在度量这种偏差的程度呢?查阅相关文献资料可知,引入一个指标,即一致性指数CI(consistency index),用它来度量偏差的大小,并且查阅到了平均随机一致性指标,平均随机一致性指标是几百,几千次,几万次重复进行随机判断矩阵特征根计算之后取算术平均得到的。通过CI与RI(random index)对比值CR(consistency ratio)大小确定是否为可接受该偏差。
下面给出CI的计算式,以及RI值(random index):
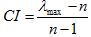
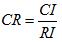
显然,如果所有条件均满足的话(指理论的理想状态),λ=n,CI=0。
如果λ越偏离n,则CI值就越偏离0,我们要追求尽可能接近λ=n的解,这样CI才会越接近0,也就是结论就越对决策有效。
当CR<0.1时,我们认为判断矩阵具有可以接受的一致性。否则,就需要调整和修正判断矩阵,使其满足给阈值条件。
因为这样才越接近理论,伟大的线性代数理论指导工程实践。使得实践有了理论保证,结论可靠。
MatLab求解特征值与特征向量(权重)
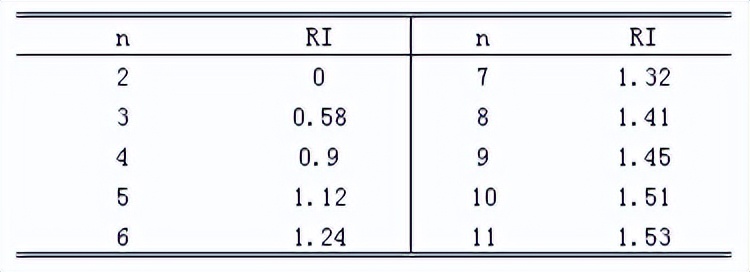
例如:计算如下的判断矩阵A的特征值和特征向量(权重)。
% matlab代码
% A:判断矩阵,反对称方阵
A = [1, 5, 2, 4;
1/5, 1, 1/2, 1/2;
1/2, 2, 1, 2;
1/4, 2, 1/2, 1]
% x:特征向量
% y:对应的特征值
[x,y] = eig(A)
eigvalue = diag(y)
lmda = eigvalue(1)
eigvect = x(:,1)
% 归一化处理
w = eigvect(:,1)/sum(eigvect(:,1))
% CI
CI = (lmda-size(A,1))/(size(A,1)-1)


显然,CR<0.1,用判断矩阵A不会表现出严重的不一致性。结果可靠可接受。
求目标选择的分数
上述我们已经分析了多个目标的权重确定,然而仅有目标的权重还不能确定排序,还需要确定各个方案满足各个目标的程度,即各个方案针对每一个目标的评分。要确定这些分数,我们需要构造每个方案在某一个目标下的成对比较矩阵。其分析与计算过程与上述分析计算过程是同理的,因此,只需要套用上述原理即可求解出目标选择分数。
例如:
对于所有的决策变量,工作1,工作2,工作3的成对比较矩阵为:
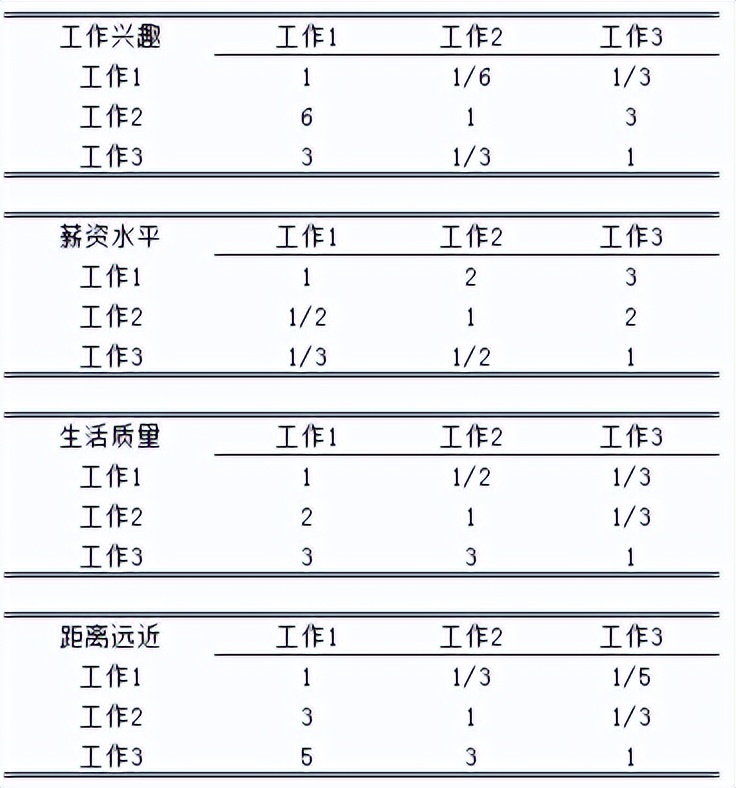
通过上述计算可得:
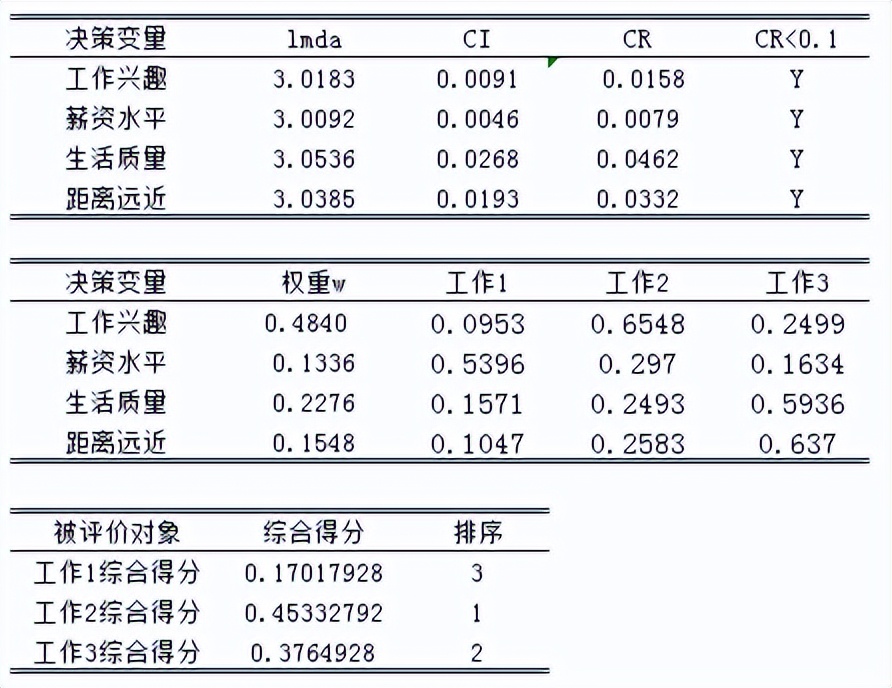
理性的您,是不是一定会选择工作2呢?(为什么,留给大家思考......)
附带给出AHP的python实现
# -*- coding: utf-8 -*-
"""
Created on Sat Feb 19 19:51:23 2022
@author: zgr
"""
def total(matrix, num_of_params):
'''
total function sums the column of matrix and returns a 1d-array
Args:
matrix: It is the pairwise comparison matrix after taking user input
num_of_params: Number of factors taken for comparison
'''
total = np.full((num_of_params), 0, dtype=float)
for i in range(num_of_params):
for j in range(num_of_params):
total[i] = total[i] + matrix[j, i] # sum column individual
return(total)
def normalization(sum_of_column, matrix, num_of_params):
''''
normalization function computes the matrix with ouput from total function and returns matrix
Args:
sum_of_column: It is the sum of each column of pariwise comparison matrix and also a output from total function
matrix: It is the pariwise comparison matrix after taking user input
num_of_params: Number of factors taken for comparison
'''
norm = np.full((num_of_params, num_of_params), 1, dtype=float)
for i in range(num_of_params):
for j in range(num_of_params):
norm[i, j] = matrix[j, i]/sum_of_column[i]
norm_t = norm.transpose().round(4)
return (norm_t)
def weight(normalized_matrix, num_of_params):
'''weight function computes the weight of each factor
Args:
normalized_matrix: It is the matrix from normalization function which has normalized value computed from sum of column
num_of_params: Number of factors taken for comparison'''
w = []
for i in range(num_of_params):
wt = np.sum(normalized_matrix[[i]])/num_of_params
w.append(round(wt, 4))
return(w)
def consistency_check(total, weight, num_of_params):
'''consistency_check function checks the set of judgements to determine their reliability
total: It is the sum of each column of pariwise comparison matrix and also a output from total function
weight: Weight of each factors derived from the weight function
num_of_params: Number of factors taken for comparison
'''
lmda = 0
for i in range(num_of_params):
lmda = lmda + total[i] * weight[i]
# Consistency Index
CI = (lmda-num_of_params)/(num_of_params-1)
for x in random_index:
if (x==str(num_of_params)):
RI = random_index[x]
# Consistency Ratio
CR = CI/RI
to_return = {
"lmda:":round(lmda,2),
"Consistency Index(CI): ": round(CI,4),
"Random Index(RI): ": RI,
"Consistency Ratio(CR=CI/RI): ": round(CR,4)
}
if(CR < 0.1):
to_return["Consistency(CR < 0.1): "] = True
else:
to_return["ConsistencyCR > 0.1: "] = False
return (to_return)