点击上方关注,All in AI中国
作者:Yoel Zeldes
在本系列的第一篇文章中,我们讨论了可能影响模型的三种不确定性:数据不确定性、模型不确定性、测量不确定性。在第二篇文章中,我们具体讨论了处理模型不确定性的各种方法。然后,在我们的第三篇文章中,我们展示了如何利用模型的不确定性在推荐系统中鼓励探索新项目。
如果我们能够使用一个统一的模型以原则的方式处理所有三种类型的不确定性,那不是很好吗?在这篇文章中,我们将展示如何在Taboola如何实现一个神经网络,通过这个神经网络来估计项目与用户相关的概率,以及该预测的不确定性。
让我们深入探索
在某种情况下,这是我们使用的模型。该模型由多个模块组成。我们将解释每一个模块的目标,然后让图片将变得更清晰......
(1)项目模块
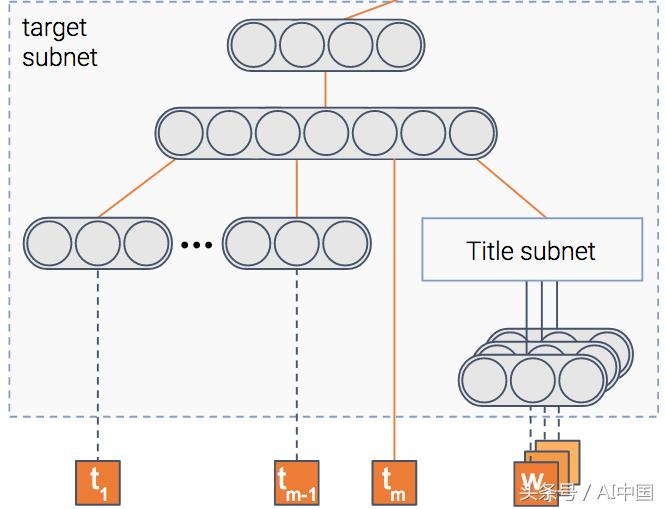
该模块试图预测项目被点击的概率,即点击率(CTR)。为此,我们有一个模块可以将项目的功能(如标题和缩略图)作为输入,并输出密集的表示,如果你愿意的话,可以输出数字向量。
一旦该模型被训练,这个向量将包含从项目中提取的重要信息。
(2)场景模块
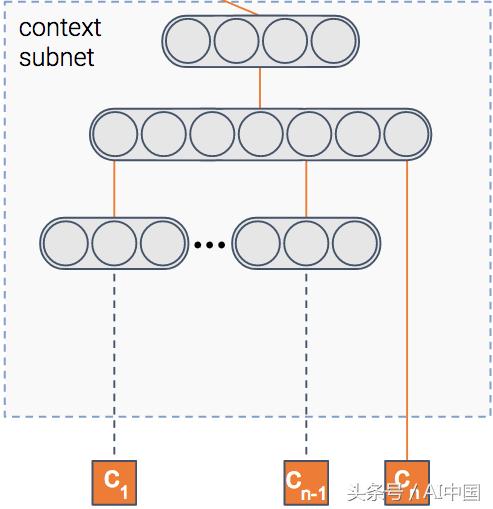
我们说模型预测点击某个项目的概率,对吗?但是在哪个场景中显示的项目?
场景可以表示许多事情,如发布者、用户、一天中的时间等。该模块将场景的特征作为输入,然后它输出场景的密集表示。
(3)融合模块

因此,我们可以从项目和场景中提取信息。当然,这两者之间存在一些互动。例如,与财务出版商相比,关于足球的项目可能在体育出版商中具有更高的点击率。
该模块将两个显示融合为一个,以类似的方式协同过滤。
(4)估计模块
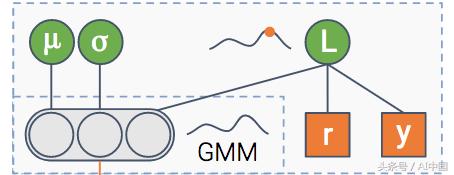
最后,我们还有一个模块,其目标是预测点击率。此外,它还估计了点击率(CTR)估计的不确定性。
大多数人不了解这个模块是如何工作的,所以让我们对它进行一些说明。
我们将向介绍所提到的三种不确定性,并展示我们的模型如何处理每种不确定性。首先,让我们来解决数据的不确定性。
(1)数据不确定
让我们采用一些在回归任务上训练的通用神经网络。一个常见的损失函数是MSE -均方误差(Mean Squared Error)。这种误差很直观,你可能希望最小化误差。但事实证明,当最小化均方误差时,隐含地最大化了数据的可能性,在此假设标签正常分布且具有固定的标准偏差σ。而σ是数据中固有的噪声。
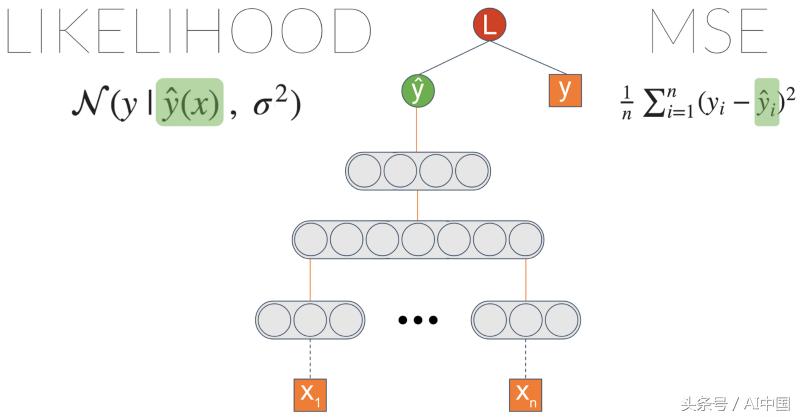
我们可以做的一件事是通过引入一个称之为σ的新节点来明确地最大化可能性。将其插入似然方程中,并允许梯度传播,使该节点能够学习输出数据噪声。
我们得到了与初始的基于均方误差(MSE)的模型相同的结果。但是,现在我们可以引入从最后一层到σ的链接:
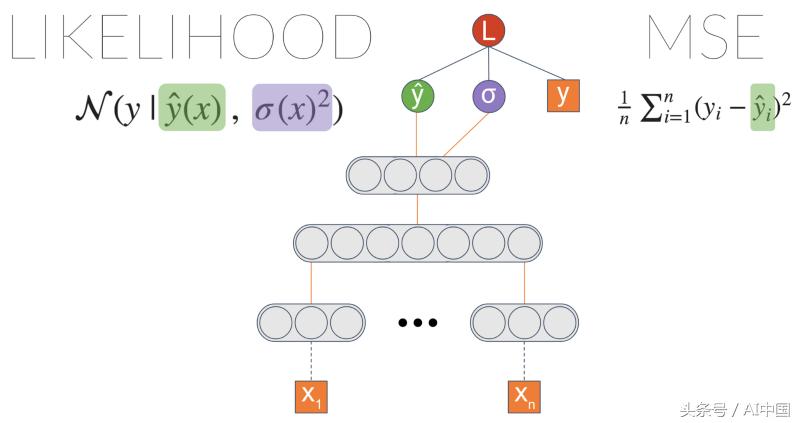
现在我们开始做一些有趣的事情了。σ现在是输入的函数。这意味着该模型可以学习将不同级别的数据不确定性与不同的输入相关联。
我们可以使模型更加强大。我们可以估计高斯分布的混合,而不是估计高斯分布。我们投入的高斯分布的混合越多,模型的容量就越大,而且越容易过度拟合,所以要小心。
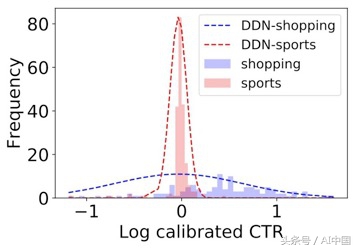
这种架构称为MDN(混合密度神经网络)。它由Bishop等人在1994年提出的。这是一个它捕获的例子:
我们有两组相似的项目 - 一组关于购物,另一组关于体育。

事实证明,购物项目的点击率往往更高,这可能是由于时尚性更令人关注。实际上,如果我们要求模型估计每个组中一个项目的不确定性(图中的虚线图),那么与体育项目相比,购物项目会获得更高的不确定性。
因此,我们已经了解了数据不确定性。那么下一步是什么?
(2)测量不确定度
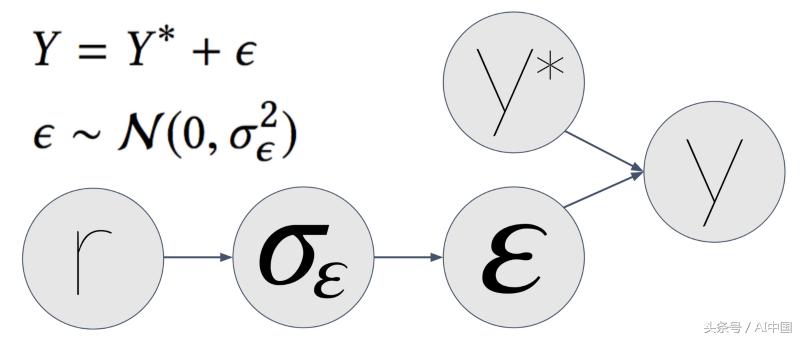
这个有点棘手。在第一篇文章中,我们解释说有时测量可能会很嘈杂。这可能会导致噪音特征甚至噪音标签。在我们的例子中,我们的标签y是项目的经验性点击率(CTR),它是到目前为止被点击的次数除以它显示的次数。
假设项目的真实点击率为y *,也就是说,没有测量噪音。如果我们在场景中无限次显示该项目,那就是点击率(CTR)。但时间有限(至少是我们得到的时间),所以我们只展示了有限的时间。我们测量了观察到的y的点击率(CTR)。这个y有测量噪声,我们用ε表示。
接下来,我们假设ε以正常分布,其中σε为标准偏差。σε函数r ,这是我们显示项目的次数。 r越大,σε越小,y越接近y *。
在结束时,将从数学细节中解脱出来,我们得到了这个似然方程式:
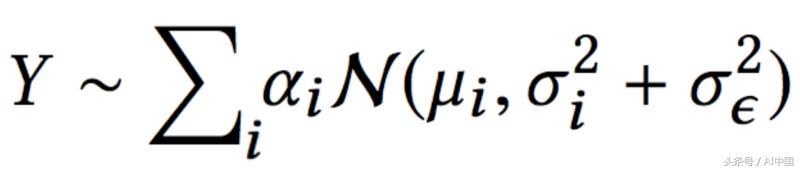
这与我们在高斯混合的MDN(混合密度神经网络)架构中的可能性相同,只有一个区别,其误差项被分成两个:
•数据不确定性(σi)
•测量不确定度(σε)
既然该模型能够使用不同的术语解释每个不确定性,数据不确定性不会受到测量不确定性的影响。
除了能够以更好的方式解释数据之外,这还允许我们在训练过程中使用更多数据。这是因为在这项工作之前我们过滤掉了噪音太大的数据。
最后但并非最不重要的事情
在之前发布的文章中,我们讨论了如何处理模型不确定性。我们描述的方法之一是在推理时使用dropout。
能够估计模型不确定性,这使我们能够更好地理解模型由于缺乏数据而不知道的内容。所以让我们进行测试吧!
让我们看看独特的标题是否与高度不确定性相关联。我们将训练集中的每个标题映射为密集表示(例如,word2vec嵌入),并期望模型对于唯一标题不太确定,这是由于标题被映射到嵌入空间的稀疏区域。
为了测试它,我们通过计算KDE(核密度估计)来计算稀疏区域和密集区域。这是一种估算空间PDF(概率密度函数)的方法。接下来,我们要求模型估计与每个标题相关的不确定性。事实证明,该模型确实在稀疏区域具有更高的不确定性!
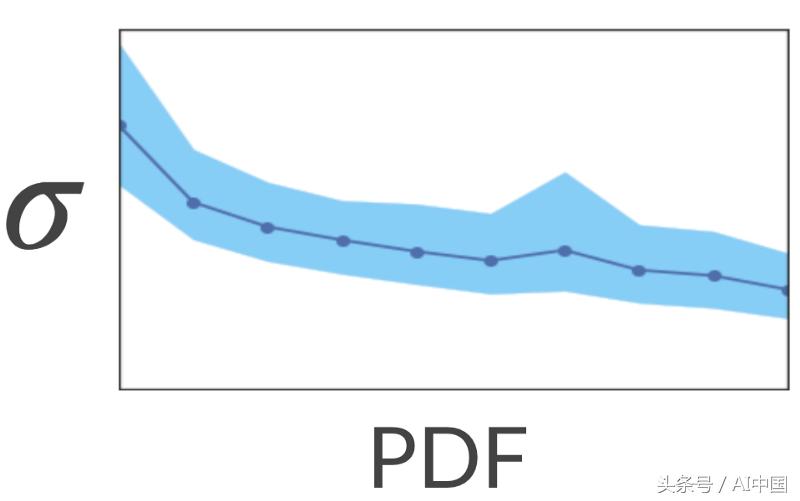
这很好......如果我们从稀疏区域展示模型更多的标题会怎么样?这些区域会更加确定吗?让我们来测试一下!
我们采取了一系列关于汽车的类似标题,并从训练集中删除它们。实际上,它改变了他们在空间从密集到稀疏的区域。接下来,我们估计这些标题的模型不确定性。正如预期的那样,不确定性很高。
最后,我们只将一个标题添加到训练集中并重新训练模型。令我们满意的是,现在所有这些项目的不确定性都在减少。
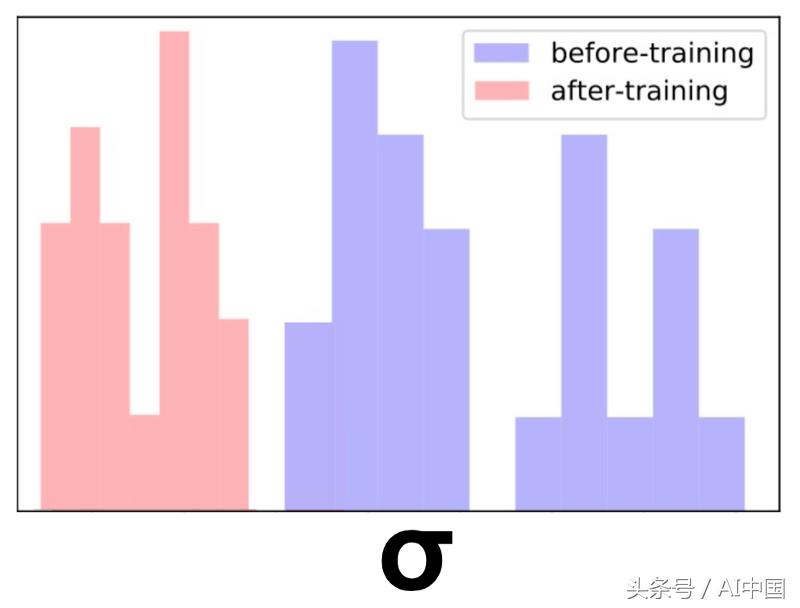
正如我们在很多文章中所看到的关于勘探开发的内容,我们可以鼓励探索这些稀疏区域。在这样做之后,不确定性将减少。这将导致该地区勘探的自然衰变。
最后的想法
在这篇文章中,我们详细阐述了如何使用一个统一的模型以原则的方式对所有三种类型的不确定性(数据、模型、测量)进行建模。
我们也希望大家思考一下如何在应用程序中使用不确定性。即使你不需要在预测中明确地模拟不确定性,也可以在训练过程中使用它——如果模型可以更好地理解数据的生成方式,以及不确定性有哪些影响,它可能会得到改善。
这是与我们今年KDD会议研讨会上发表的一篇论文相关系列文章的第四篇:深度密度神经网络和推荐系统的不确定性。(https://arxiv.org/abs/1711.02487)
第一篇文章可以在这里找到。
(https://engineering.taboola.com/using-uncertainty-interpret-model)
第二篇文章可以在这里找到。
(https://engineering.taboola.com/neural-networks-bayesian-perspective)
第三篇文章可以在这里找到。(https://engineering.taboola.com/recommender-systems-exploring-the-unknown-using-uncertainty/)
这篇文章最初由我和Inbar Naor在engineering.taboola.com上发布。
