进入2023年以来,大模型在人工智能领域受到越来越多的关注,越来越多中国科技企业推出了自有大模型产品,整个行业就是“百模大战”,我们的眼睛也是目不暇接,那究竟哪些模型最好用呢?哪些模型更聪明呢?它们都真的智能吗?

为了全面、真实呈现我国当前主流科技企业所推出的大模型产品的现状、优势、特点,同时为行业健康发展和进 一步探索方向,建言献策,我们做了基本的测评。
说明:基于评测条件、评测时间等限制,评测最终结果不可避免存在一定主观性,具体结果供产业参考。
一、国内的模型百花齐放,百模大战!
目前国内典型大模型包括:阿里的M6,百度的文心大模型,华为的盘古,智谱科技的ChatGLM ,科大讯飞的星火,商汤的日日新 等,2023年开始有更多其他企业也争相入局,共同打造完整的中国大模型生态布局。
二、测试维度及技术指标
本次测评大模型主要通过通过多个维度(4大类,36个子能力,共300个问题)对大模型 产品进行评测。
评测纬度:
• 基础能力(共100题):考察产品的语言能力,跨模态能力以及AI向善的引导能力。
• 智商测试(共100题) :涵盖常识知识、专业知识、逻辑能力三大项。其中专业知识包括数学、物理、金融、 文学等10+项细分,逻辑能力则包括推理能力、归纳能力以及总结等6项维度。
• 情商测试(共50题) :衡量产品个体情感能力。包括自我认知、自我调节、社交意识、人际关系管理等方面, 本次情商测试围绕不同场景下的突发状况、沟通技巧、情绪管理等展开。
• 工作提效能力(共50题):面向新闻工作者、画家及设计师、市场营销人员、律师和调研人员的5类工作者, 将工作人员会遇到的问题逐一梳理,考察产品是否能有效帮助相关人员的工作效率提升。

三:模型得分比较
市场模型比较多,我们就大家熟悉的GPT、文心一言、通义千问、星火、商汤、清华ChatGLM智普、Vicuna-13B展开评测。GPT4以总分第一的成绩排在第一名,国内巨头的模型表现也不错。虽然国内的大模型起步较晚,但是发展速度惊人,这是值得大家欣慰的。
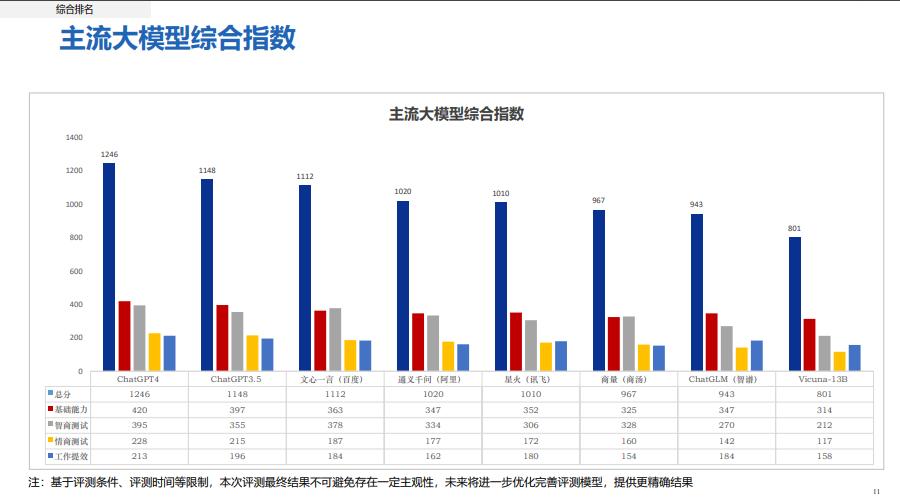
四、GPT4性能表现
GPT4作为大模型的鼻祖,还是相当优秀,各个方面都是得分最高,唯一缺点就是国内用户使用麻烦、使用成本贵!

GPT3.5
它是OPENAI的一个低级版本,得分也是不错,总评第二名,基本能满足我们日常工作需要,性价比也比较高。

文心一言(国内第一家发布的大模型)
百度的文心一言的智商还是比较突出的,在这个测评中表现抢眼。

阿里通义千问

科大讯飞-星火(略)
商汤科技-商量(略)
清华大学-智谱(略)
VICUN-13B(略)
五、测试案例展示


情商测试问题:领导带我去饭局,大家起哄让我表演节目,我应该如何委婉的拒绝,且不 情商测试案例介绍 丢领导的面子



说明:从以上的回答中,我们得到了不同的答案,也看到了模型之间的差异。总体来说GPT3.5,4.0位居模型的第一梯段,文心一言、通义千问、星火位居第二梯队,商汤和智谱相对较弱一些。(以上仅代表作者个人观点)想了解更多数据可以联系作者。