在之前的推送中,我们向大家介绍了中国农业大学小麦研究中心(WGGC)开发的数据库系统模型 ——SnpHub(开源项目主页:http://guoweilong.github.io/SnpHub)的功能模块(拿什么迎接你:即将到来的海量重测序数据?)。本次推送将继续介绍基于 SnpHub 搭建的公共分析平台门户 ——Wheat-SnpHub-Portal(网址:http://wheat.cau.edu.cn/Wheat_SnpHub_Portal/)(一千零一技 | Wheat-SnpHub-Portal数据库介绍及使用示例),以2019年发表在Genome Biology上的数据集(【一作解读】基因组重测序揭示六倍体普通小麦的遗传多样性来源于频繁的种内和种间杂交)为例,详细介绍SnpHub的VarTable模块。
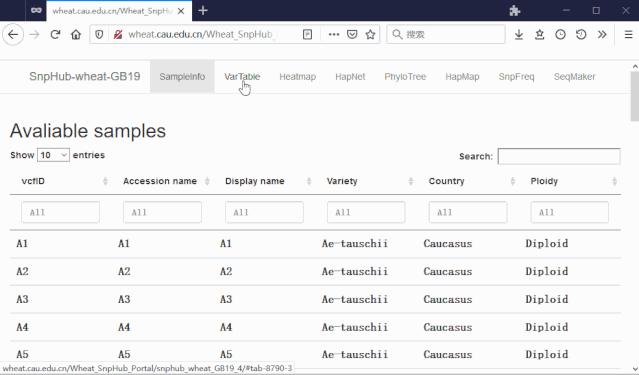
图1. VarTable使用示例(动图)
在VarTable模块中,用户可以对不同样本(组)和不同区间的变异情况进行简单查询。区间既可以是简单的形如“chr:from-to”形式,也可以是基因名形式。同时,查询结果还可以多种方式保存至本地。
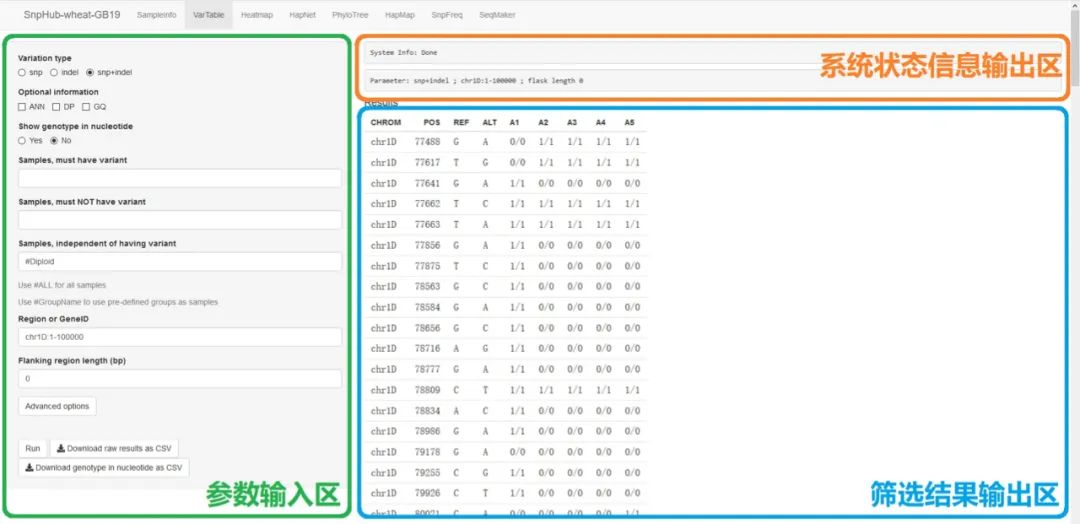
图2. 基因型查询页面
在VarTable模块中,位于左侧的是参数输入区,用户在这里输入筛选的条件;位于右上的是系统状态信息区,筛选是否正常返回、出错时的详细信息以及当前筛选结果所对应的参数都将在这里显示;右下则是筛选结果输出区,筛选结果将以表格形式呈现在这里。接下来,我们将向您一一介绍可输入的参数及其作用。
1. 变异类型选择
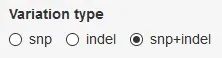
图3. SNP/INDEL选项
变异类型分为SNP(Single-nucleotide polymorphism,单核苷酸多态性)和InDel(Insertion/Deletion,插入/缺失突变)两大类。VarTable模块提供了两种变异类型的过滤。如果选中“snp”,则结果中只会显示SNP类型的变异,而默认的“snp+indel”则会把两种变异类型都呈现在结果中。
2. 可选的元数据输出
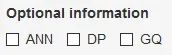
图4. Meta-information选项
这里的三个复选框支持对保存在VCF(源数据文件)中的一些元数据的输出。其中,勾选ANN代表输出SnpEff对变异位点的注释内容,勾选DP代表输出read depth信息,勾选GQ代表输出genotype quality信息。下图为同时勾选了DP和GQ的变异数据示例,对于每个样本,“0/0”、“1/1”分别代表“未发生变异”和“纯合突变”;突变类型之后用冒号隔开的数,是read depth信息;用冒号隔开的第三个数则是genotype quality信息。

图5. 含有meta-information的基因型输出示例
3. 将输出结果显示为基因型

图6. “基因型输出格式”选项
如果觉得“0/0”的形式不够直观怎么办呢?勾选这里的“Yes”,就能直接把“0/0”、“1/1”中的“0”、“1”,替换成对应的核苷酸类型。

图7. 输出示例
4. 输入参与筛选的样本

图8. 查询样本列表输入框
这里的三个输入框,自上而下分别代表了“筛选该样本列表中发生变异的位点”、“筛选该样本列表中未发生变异的位点”和“显示该样本列表中所有位点”。通过参数输入,就能轻松实现“A样本出现变异,而B样本没有变异”的筛选。
样本列表有两种形式,第一种是直接由样本的Accession Name构成的列表。Accession Name可以通过SampleInfo模块进行查询。多个Accession Name之间,使用英文逗号进行连接,例如“sample1,sample2,sample3”。
第二种是通过预先定义的样本组实现快速输入。预定义的样本组同样可以通过SampleInfo模块进行查看,且这些样本组由系统管理员进行维护(也就是说,对于自己搭建的SnpHub实例,管理员可以将常用的分组预先输入到SnpHub中,以便用户进行输入)。通过在组名前加井号(#),即可实现基于预定义样本组的样本列表输入,例如“#PredefinedGroup1,#PredefinedGroup2”。
此外,上述两种输入方法可以混用,例如“sample1,#PredefinedGroup1, sample2,#PredefinedGroup2”。在组名前加井号正是为了避免混用时,组名与样本名产生冲突。
5. 选择筛选的区间

图9. 查询基因/区间输入框
筛选区间的选择,可以是形如“chr:from-to”的格式,也可以是基因名的形式。以本实例为例,基因“TraesCS1A02G001800”位于 “chr1A:1144333-1145934”。采用“TraesCS1A02G001800”作为输入,效果等同于输入“chr1A:1144333-1145934”。
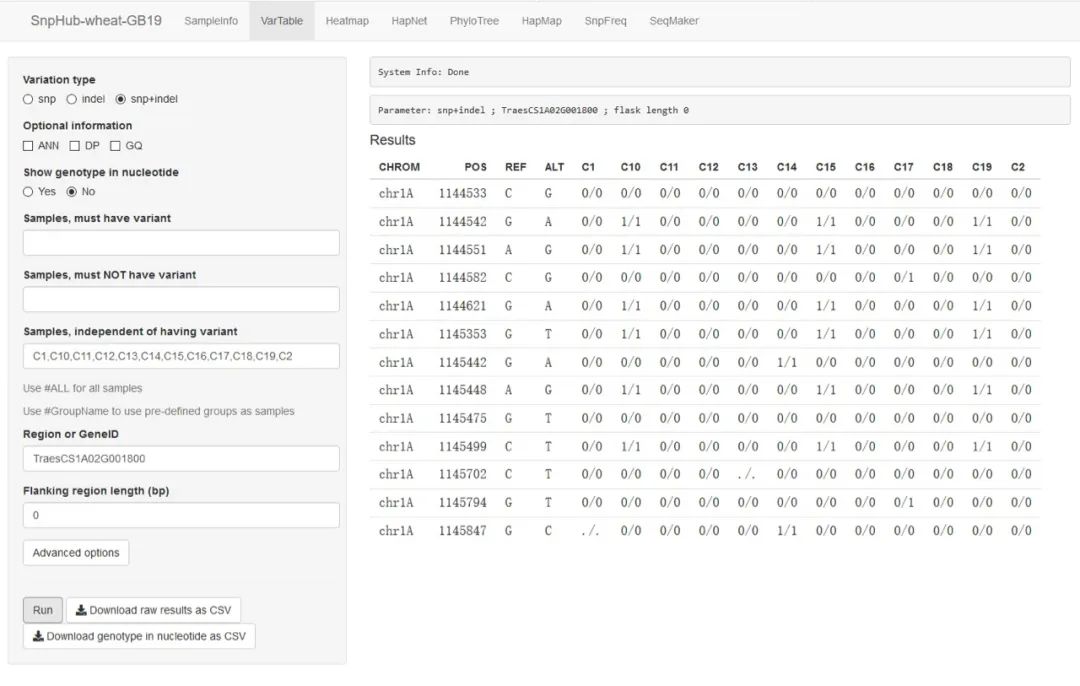
图10. 输出示例
6. 对筛选区间加以延长

图11. 查询基因/区间的侧翼区间延伸参数
当采用基因名作为输入的时候,还想查看上下游的变异情况怎么办呢?在这里,可以输入一个正整数值,来对之前输入的区间加以延长。
7. 高级选项
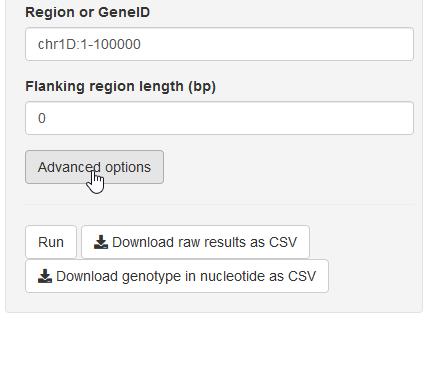
图12. 高级输出选项
点击“Advanced options”按钮,就能使用高级选项进行进一步筛选。当高级选项为折叠状态时,即使之前对其进行了修改,也不会生效。
8. 高级选项:MAF过滤

图13. MAF过滤选项
MAF(Minor allele frequency)是指给定群体中,第二常见的allele出现的频率。本参数可以对MAF的最小值进行过滤,小于给定阈值的结果将被过滤掉而不再显示。其取值区间为0~1,0表示不筛选。
9. 高级选项:仅显示双等位基因位点
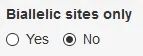
图14. “二态型”选项
与biallelic(双等位基因)相对应的,是multiallelic(复等位基因)。双等位基因位点指在一个基因座(locus)中,仅观测到两个等位基因(如果将其中一个定名为参考基因,则另一个为变异基因);复等位基因位点则是在一个基因座中同时观察到多个等位基因的位点。通常,SNP是双等位基因,而InDel多属于复等位基因。勾选“Yes”,将筛掉结果中的复等位基因位点。(参考阅读:论SNP的“二态性”)
10. 高级选项:最大缺失率过滤

图15. 数据缺失比例筛选参数
例如,最大缺失率设为0.2将过滤掉具有超过20%的样本为缺失的位点。默认情况下,此阈值为0,表示不过滤。
11. *载下**
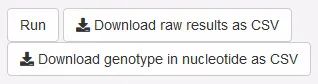
图16. 表格*载下**按钮
*载下**功能可以将当前筛选的结果*载下**为CSV格式,以供用户进一步传递给下游软件做其他分析。其中,点击“*载下**原数据”按钮,会将变异类型*载下**为“0/0”、“1/1“的形式,而点击”*载下**基因型数据“会将变异类型*载下**为”A/A“、”G/G“的形式。
限于篇幅,本次推送仅对SnpHub平台的“VarTable“模块展开介绍。之后还将推出其他功能的参数选择、技术细节和使用技巧。欢迎各位专家、同行、朋友的关注和反馈!
(WANG Wenxi: wangwenxi20@gmail.com;
GUO Weilong: guoweilong@cau.edu.cn)
附相关网址:
SnpHub主页:http://guoweilong.github.io/SnpHub/SnpHub
使用指南:https://esctrionsit.github.io/snphub_tutorial/
Wheat SnpHubPortal网址: http://wheat.cau.edu.cn/Wheat_SnpHub_Portal/
Cite:Wenxi Wang*, Zihao Wang*,et al.. SnpHub: an easy-to-set-up web server framework for exploring large-scale genomic variation data in the post-genomic era with applications in wheat,bioRxiv, 626705. https://doi.org/10.1101/626705参考阅读:拿什么迎接你:即将到来的海量重测序数据?
一千零一技|Wheat-SnpHub-Portal数据库介绍及使用示例
理清SNP、SNV、CNV等一些概念
论SNP的“二态性”
「博客翻译」SNP过滤教程
利用snpEff对SNP进行注释
小麦多组学网站上线小麦重测序数据了
【总结】小麦多组学网站介绍
山农35个野生二粒小麦的重测序数据|小麦多组学网站
【一作解读】基因组重测序揭示六倍体普通小麦的遗传多样性来源于频繁的种内和种间杂交
