在网上关于CAP理论的探讨很多,有的讲历史,有的将原理,有的讲争论,其实对于一个资深程序员或者架构师来说,最核心的还是要理解他的概念原理和应用,我们先看下面的一幅图,来揭开它的神秘面纱.
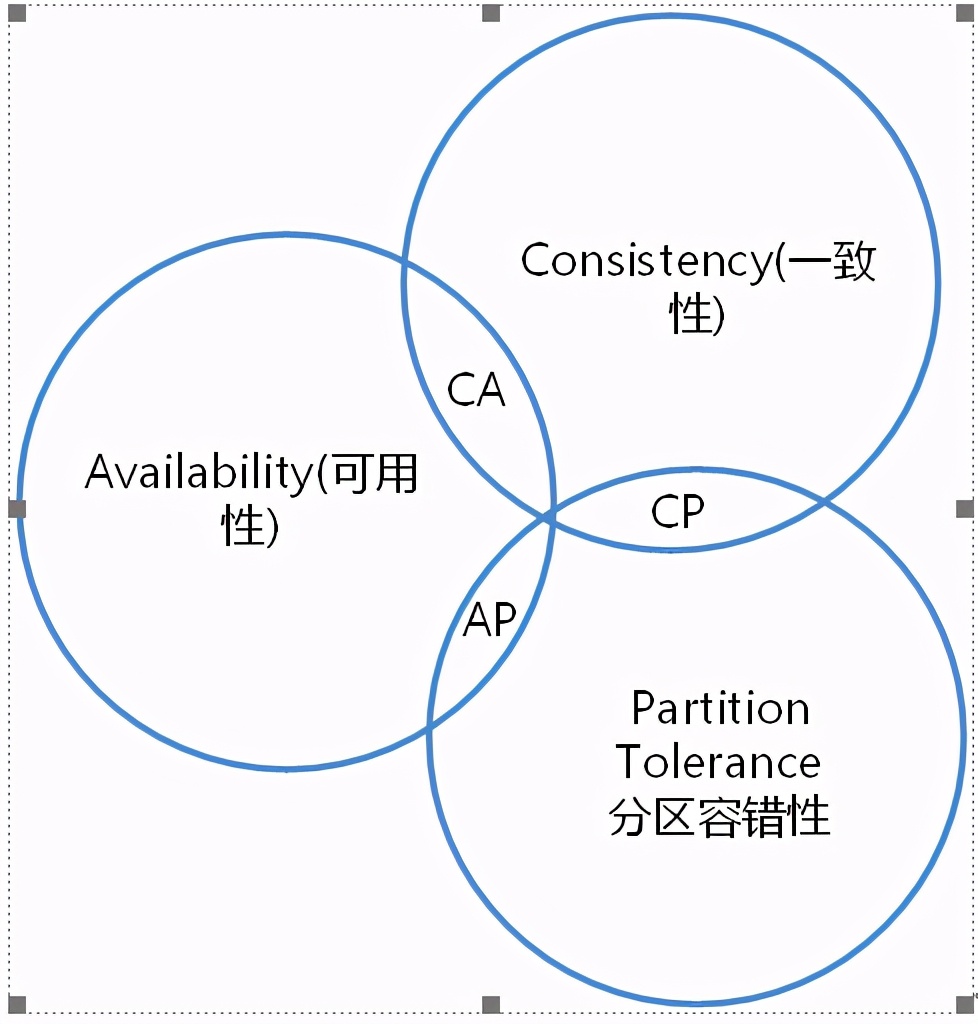
一、 什么是一致性(C)、可用性(A)、分区容错性(P)
首先只有分布式系统中,才有可能探讨CAP,否则则没有探讨的必要;现在我们假设在分布式系统中有2个节点,分别是N1和N2;客户端有2个分别为C1和C2,下面我们解开它们神秘的面纱。
1. 一致性:在分布式系统中的其中一个节点写入数据,在其它节点读取到的应该是刚写入的值 ,这就叫做一致性。例如客户端C1在N1节点设置A=1,则在C1写入完成后,C2在N2节点读取A的值,也应该是1,否则则为违反了一致性.
2. 可用性:分布式系统提供的任何服务,客户端都可以正常访问并且能够得到正常响应。例如在分布式系统里面提供了接口“/web/s1.json”,客户端在任何时候都应该能访问并且返回http200.
3. 分区容错性:分布式系统中的多个节点,任何一个节点出现了故障或者宕机,系统仍然可以对客户端提供服务,也就是说部分故障不影响整体使用。
二、 为什么CAP三者不可兼得
1. 假设我们保证了“分区容错性”,也就意味着在分布式系统里面有一个节点网络出现了故障导致数据同步没有成功,整个系统还可以对外提供访问,我们看下面的流程图(假设变量A的初始值为0)
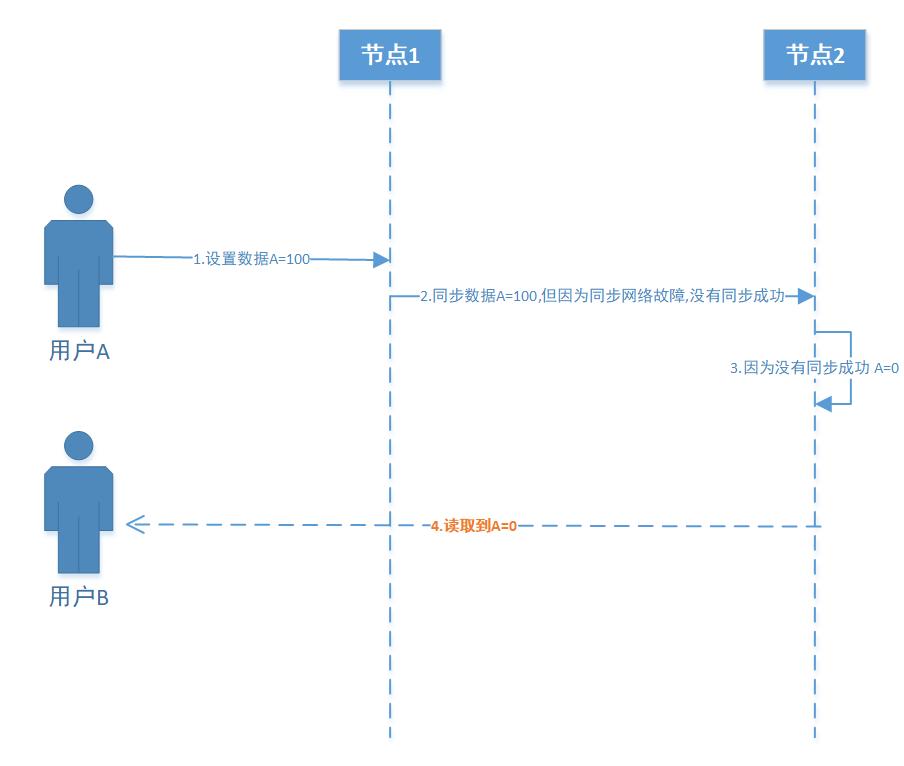
1) 假设节点1和节点2变量A的初始值为0
2) 用户A访问节点1,并且设置变量A=100
3) 节点1同步数据A=100到节点2,但因为网络故障,导致没有同步成功
4) 因为没有同步成功,节点2的值A=0
5) 导致用户B通过节点2读取变量A的值为0(即使通过节点1读取,A的值也应该是0,因为没有同步成功)
6) 这时候无疑问用户B获取了错误数据,因为正确数据应该是A=100,这就出现了数据不一致的情况了.
总结:由上面可见,满足了可用性,失去了一致性
2. 假设我们保证了“强一致性”,也就意味着在分布式系统里面有一个节点出现了故障,整个系统则不能对客户端继续提供访问,我们看下面的流程图(假设变量A的初始值为0)
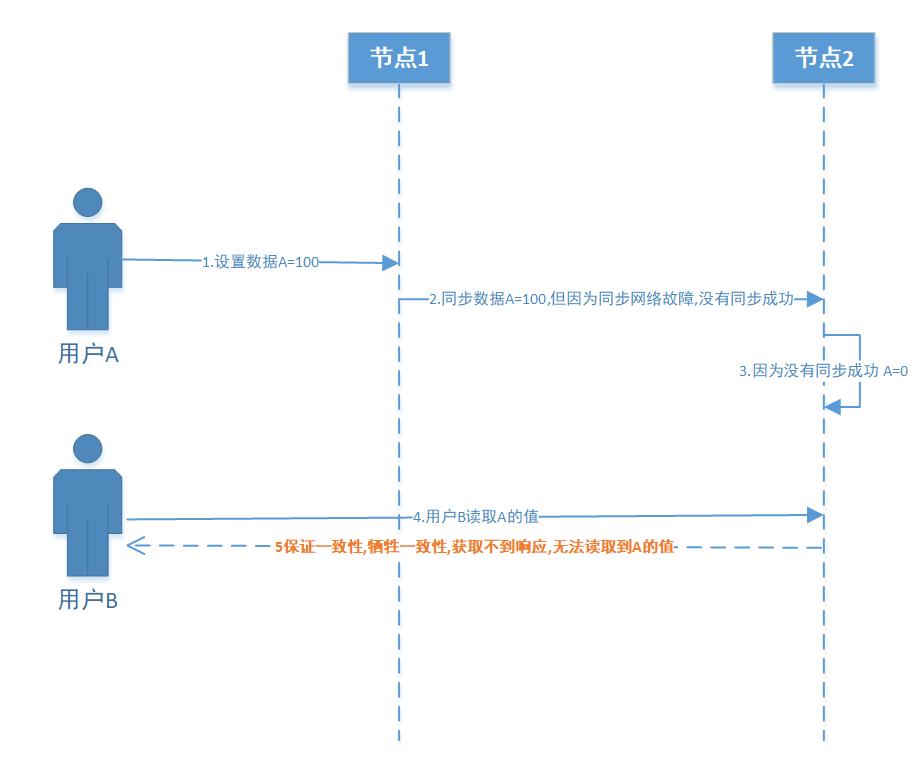
1) 假设节点1和节点2变量A的初始值为0
2) 用户A访问节点1,并且设置变量A=100
3) 节点1同步数据A=100到节点2,但因为网络故障,导致没有同步成功
4) 因为没有通过成功,节点2的值A=0
5) 用户B通过节点2读取变量A的值,如果我们保证一致性,则节点2则不能响应用户B的请求,只有这样才能保证了一致性,但保证了一致性,却又牺牲了可用性(即使通过节点1读取,也不能响应请求)
总结:由上面可见,满足了一致性,失去了可用性.
三、 CAP三者应该如何取舍
1) CA: 优先保证一致性和可用性,放弃分区容错。 这也意味着放弃系统的扩展性,系统不再是分布式的,有违设计的初衷。
2) CP: 优先保证一致性和分区容错性,放弃可用性。在数据一致性要求比较高的场合(譬如:zookeeper,Hbase) 是比较常见的做法,一旦发生网络故障或者消息丢失,就会牺牲用户体验,等恢复之后用户才逐渐能访问。
AP: 优先保证可用性和分区容错性,放弃一致性。NoSQL中的Cassandra 就是这种架构。跟CP一样,放弃一致性不是说一致性就不保证了,而是逐渐的变得一致