背景

本系列已经覆盖了 神经元、基础神经网络、过拟合、激励函数、反向传递等,也涵盖了比较著名的监督学习神经网络框架 CNN(卷积神经网络) 和 RNN(循环神经网络)等。大家可能知道机器学习可以分为三个体系:监督学习、非监督学习和强化学习。而这一期开始给大家介绍一下强化学习内容。强化学习不同于监督学习等,有些内容比较绕,所以本文有准备一个代码例子,除此之外本期还有准备一个视频版本的讲解,已经上传到我的B站账号:繁林林与机器学习,后续也会传到微信公众号。
需要特殊注明的是本文章的图片来源于Medium的作者Anubhav Singh,部分公式及内容也翻译于其文章。
强化学习介绍
在本文章中呢,会给大家介绍强化学习的基础概念和专有名词。在本文章的最后会给大家介绍一个简单的例子
什么是强化学习
强化学习是机器学习的一种分支,在该分支中 计算机agent学习如何在 特定环境中 采取某些动作,最终获取最高的回报。它是通过利用试错过程中学到的知识来达成这一点的。(对于强化学习的定义翻译可能并不准确,所以保留英文原文)
Reinforcement learning in formal terms is a method of machine learning wherein the software agent learns to perform certain actions in an environment which lead it to maximum reward. It does so by exploration and exploitation of knowledge it learns by repeated trials of maximizing the reward.
强化学习vs其他
机器学习的方法都在下图中展示。
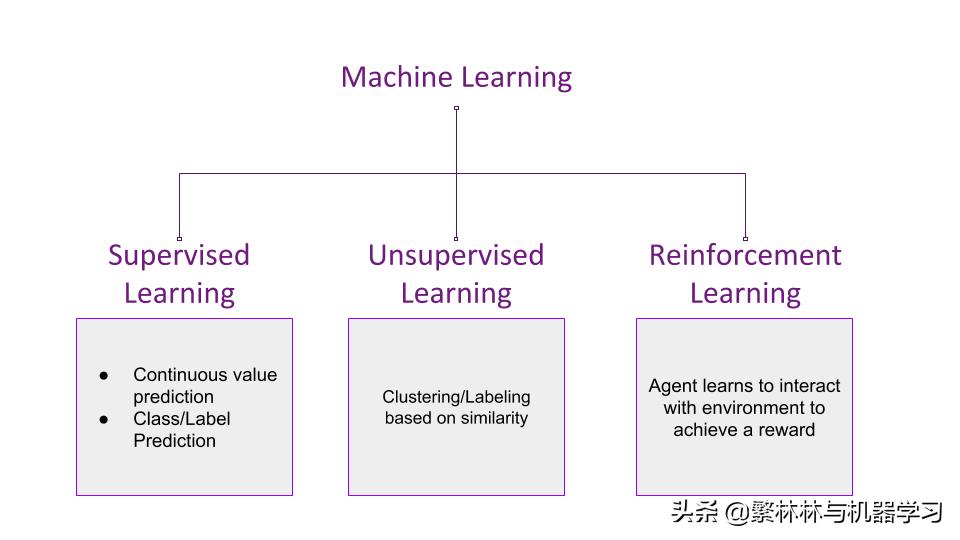
监督学习(supervised learning)是通过学习它所受到的训练样本,预测连续的值 或者 预测分类及标签。而非监督学习(unsupervised learning)是希望基于样本的相似性来 进行族群分类。
而强化学习则是非监督学习下的一种非常特殊的类型。它主要利用了“因果关系”
强化学习的直观理解
让我们来通过一个简单的例子来理解之前比较拗口的定义。
假设,我们需要在一个漆黑的夜晚,并且没有火炬的情况下,通过一个位置的领地。在领地中间可能有坑 或者是石头。有一个简单的规则,如果你掉进坑里或者撞了一块石头,那么你需要从起点重新来过。
- 你从起点向前走,同时记录 你走的步数。在X步后,你掉进了一个坑。你的reward(奖励)是X分,因为你向前走了X步;
- 你重新从起点出发,但是在X步之后,你向 左/右转之后,再向前进。你在y步之后,撞到了石头。这次你的reward(奖励值)是y,当然y比x大。而且你决定下次再走这个路线,并且需要更加小心;
- 当你再次出发时,你在X步时,进行转弯;在y步时,再次转弯。然后在Z步时掉进了另一个坑。这次奖励值是Z分,当然Z比Y大,并且你决定下次还走这个路径;
- 你再次上路,在X、Y、Z步时都进行转弯,并且成功的穿过这块未知的区域。 即,你在没有光的情况下,学会了怎样穿过这篇领域;
这个例子中强化学习,学的是什么呢? 其学的是在一个未知的领域中怎么样完成最终的任务。 这个学习的过程也是不断试错的过程。接下来会用一个强化学习典型的例子和代码来展示强化学习。
基础概念和专有名词
基础概念
在上述例子中,你是某个主体。你希望通过某个区域,这个区域就是你所处的环境。行走 就是 主体 在该 环境 中所采取的动作。而距离是该主体采取动作所取得的奖励。
而主体需要采取使得奖励最大化的动作。这就是强化学习的基础概念。
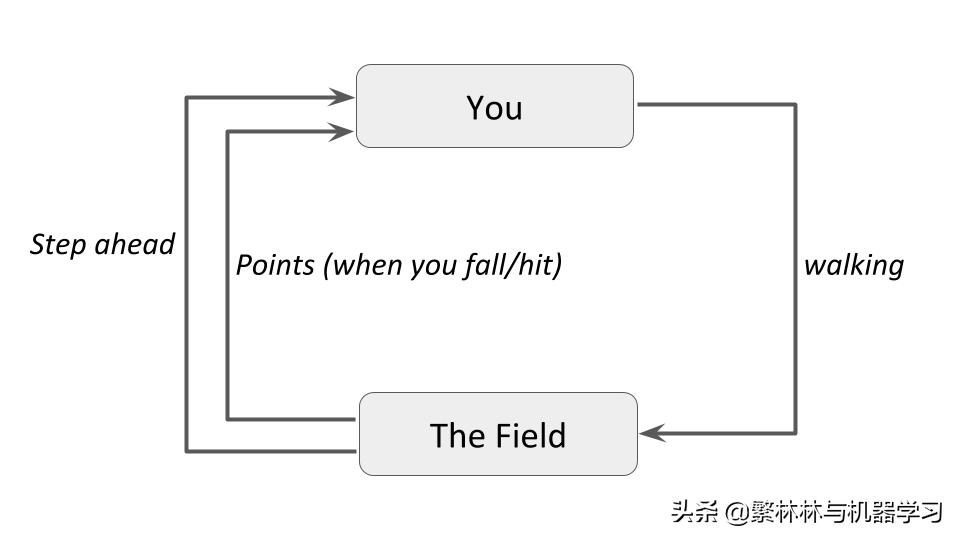
上图是该过程的一个概念图。如果更tech一点的话就是下图
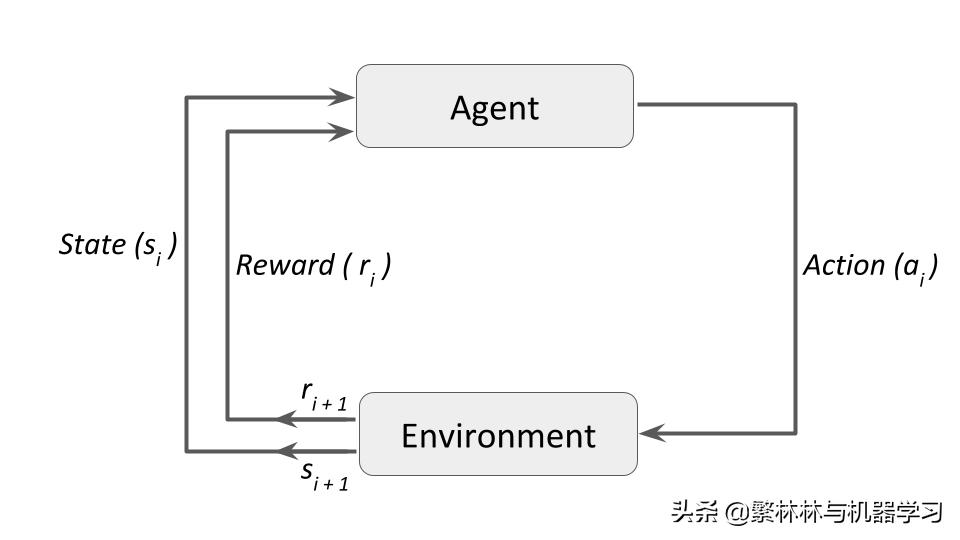
专有名词:
一些重要的与强化学习相关的专有名词如下:
Agent-主体:一个假设的实体,该实体在环境中采取动作并获取奖励;
Action(a)动作:所有主体能够采取的动作;
Environment(e)环境:主体面对的环境;
State(s)状态:目前环境所反馈的情景;
Reward(R)奖励:在采取某动作之后,即可由环境所反馈的奖励制,由于评价主体所采取的上一动作;
Policy(π)策略:该主体基于目前状态选择下一动作的策略;
Value(V)价值:折现后的期望长期回报,相对于短期的奖励制R。Vπ(s),目前状态S下 在策略π 的长期期望回报;
Q-value or action-value (Q):Qvalue 类似于Value,但是不同点在于 Value代表着一个策略的长期回报,而Qvalue代表着当前动作的长期回报;
上面的名词和概念可能不太容易接受,下面通过一个简单的例子来让大家有一个强化学习的概念。
一个简单的例子
强化学习有一个非常经典的例子-Multi-Armed Bandit(类似于游戏厅的摇杆赌博机)。大家可能没听过,不过没有关系。 假设,你在一个*场赌**,有很多摇杆赌博机。比如,你面对一排 10台赌博机。每台摇杆赌博机会给你 0~10元的回报,但是每台赌博机有不同的平均回报值。所以,你必须在最短的时间找到最大平均回报的机器。机器的样子类似下图。
再解释下:每次摇杆机器都会产生一个随机值给你,但是不同的是每台机器有一个平均回报值。也就意味着,某台机器第一次摇杆可能表现良好,但是实际上长期平均值较低。
我们也可以换个角度理解这个例子,其实找到平均值最简单的方法就是实验一定数量。比如每台机器都先摇1000次,然后我们就能知道每台机器的平均值了。但是很明显,这样做的效率并不高。

ϵ (epsilon)-greedy algorithm
应对这个问题一个非常著名的方法是ϵ (epsilon)-greedy算法。其中,有ϵ的概率会选择动作a 纯随机,剩余概率1-ϵ 你会选择目前已知的最佳动作。所以,大部分时间你Greedy的选择最佳解法,但是有时你也会选择一个随机的动作。
import numpy as np
import random
import matplotlib.pyplot as plt
#%matplotlib inline
np.random.seed(5)
首先import必要的lib
n = 10
arms = np.random.rand(n)
print(arms)
eps = 0.1 #probability of exploration action
我们面对的是10组摇杆机器,所以n=10, arms是10组随机数,分别代表着每台机器的“平均回报率”
def reward(prob):
reward = 0
for i in range(10):
if random.random() < prob:
reward += 1
return reward
接下来define reward 奖励值公式,其中 prob 来源于上面代码的arms。那也就是random.random 小于 prob时,reward +1 。 这样循环10次,每次if ture 则reward+1,最终得出 0~10的数值。
#initialize memory array; has 1 row defaulted to random action index
av = np.array([np.random.randint(0,(n+1)), 0]).reshape(1,2) #av = action-value
#greedy method to select best arm based on memory array
def bestArm(a):
bestArm = 0 #default to 0
bestMean = 0
for u in a:
avg = np.mean(a[np.where(a[:,0] == u[0])][:, 1]) #calculate mean reward for each action
if bestMean < avg:
bestMean = avg
bestArm = u[0]
return bestArm
下一个公式是定义你的Greedy策略,选择目前最佳的摇杆机。这个公式输入一个数组,该数组储存了历史上所有的动作和其奖励。它是一个 2 * K 矩阵,每一行第一个值代表着 你选择的第几个摇杆机(第一个值),和其奖励值(第二个值)。例如,如果数组中的一行显示的是【2,8】,它代表着 选择了第二个摇杆机 并且奖励值是8.
plt.xlabel("Number of times played")
plt.ylabel("Average Reward")
for i in range(500):
if random.random() > eps: #greedy exploitation action
choice = bestArm(av)
print(choice)
thisAV = np.array([[choice, reward(arms[choice])]])
av = np.concatenate((av, thisAV), axis=0)
else: #exploration action
choice = np.where(arms == np.random.choice(arms))[0][0]
thisAV = np.array([[choice, reward(arms[choice])]]) #choice, reward
av = np.concatenate((av, thisAV), axis=0) #add to our action-value memory array
#calculate the mean reward
# print(av)
print('++++++')
runningMean = np.mean(av[:,1])
plt.scatter(i, runningMean)
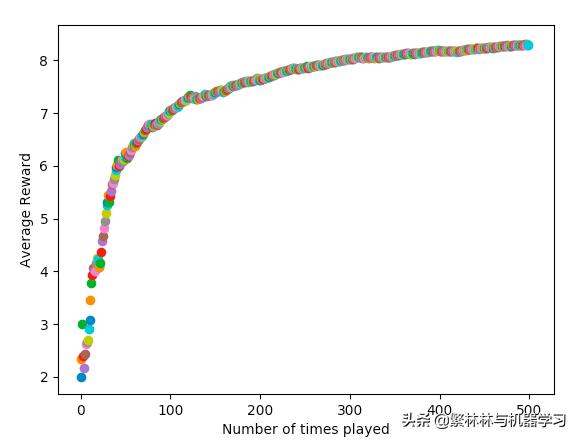
接下来就是我们的main loop,他将基于策略摇杆500次。最终将累计平均奖励值画出来,如下图。大家能看到最终500次摇杆之后,累计的平均收益已经超过8.
下面的数值是 随机生成的10组数,代表着每个摇杆机自身的平均回报,大家能看到500次累计平均值已经越来越接近最高解 0.91
[0.22199317 0.87073231 0.20671916 0.91861091 0.48841119 0.61174386
0.76590786 0.51841799 0.2968005 0.18772123]
强化学习的思考
一个非常重要的问题是,强化学习学的是什么?它是怎么学的?
要回答这个问题,需要先回到摇杆机的例子。它的任务是 最大化奖励值,也就是说要尽快找到最优的摇杆机;
而,大家通过代码可以知道,我们记录下来了每一次摇杆的记录。并且通过历史记录的平均值,我们知道当时的最优摇杆;
当然这还不够,因为仅仅是这样,电脑会将第一次使用的摇杆机作为最优解。所以也就有了一个exploration vs exploitation的矛盾,也就是我们到底是应该探索新的选项(通过随机选择)还是应该选择现有记录的最大值呢? 当然在这个例子中我们比较直接的选择了0.1 这个比例;
所以再回到我们的问题,摇杆机这个例子中我们到底学的是什么?
是在与环境(10台摇杆机)不断的交互尝试中,我们一直在计算每台摇杆机的平均奖励值。与此同时,我们90%的概率选择当前的最优摇杆机;10%的概率随机选择。这样就能避免,当某台 比较差的摇杆机 人品爆发的概率。
最终强化学习学到的是每台摇杆机的平均奖励值。
从过程中大家可以看出,主体在摇杆之前对于每个摇杆机一无所知,但是其在经历一定数量之后学到了每个摇杆机的属性,这就是从零开始学习的过程。这也是为什么叫做强化学习的原因。