知识图谱与图数据库
近些年,随着大数据时代的到来,知识图谱得到了快速发展。知识图谱作为一个大规模语义网络,计算和存储一直是一个热门的讨论话题。知识图谱的数据主要分为三类:实体、属性、关系,整个知识图谱其实是一个拓扑图,实体为图中的节点,关系为图中的边。因此,怎么方便存储和查找数据,对于知识图谱至关重要。
在知识图谱开发的初期,多数人会选择采用传统关系型数据库来存储数据。关系型数据库上手简单,对于两度以内的存储关系,查询效能比较好,对于度数较高的关系查询,关系型数据库的查询效率低下,并且SQL语言也越发复杂,因此,图形数据库应运而生。图形数据库是一种非关系型数据库,它应用图形理论存储实体之间的关系信息,它在描述、存储、查询知识图谱的关联关系,具有天生的优势。目前,常用的图形数据库有Neo4j,JanusGraph,Giraph,Dgraph, TigerGraph等。其中Neo4j由于采用自己的存储方式,性能优势突出,但是社区版不支持集群,可扩展性比较差;JanusGraph支持Cassanda、Hbase、Google Cloud Bigtable等作为底层存储,支持Elaticsearch、Apache Solr、Apache Lucene作为底层索引,实现tinkerpop标准图框架,可扩展性较强。
JanusGraph简介
1. JanusGraph架构
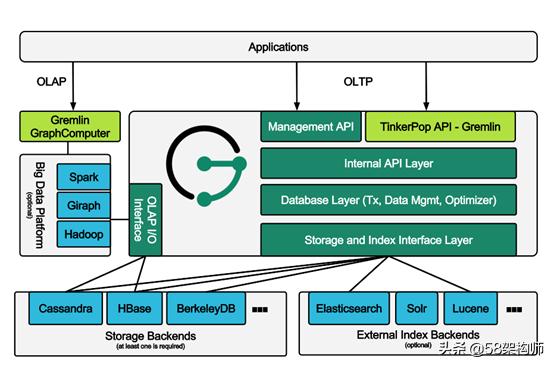
JanusGraph通过原生支持图计算框架Apache TinkerPop来提供图数据库(OLTP)和图分析系统 (OLAP)的能力。通过集成可插拔的索引后端来支持地理位置、数字和全文检索等查询类型,支持Elasticsearch,Apache Solr,Apache Lucene等查询引擎。在后台存储上,JanusGraph可以与Apache中现有的大数据处理框架相结合,如Apache Cassandra、Apache Hbase,也可以与外部数据库完美结合,如Google Cloud Bigtable、Oracle Berkeley DB,同时也支持基于内存的存储方式,基于图提供强大的大数据分析、统计报告能力。
2. JanusGraph数据模型与Schema
JanusGrap*图h**数据库的数据有顶点(vertex)、边(edge)和属性(property)组成,在图谱逻辑中,vertex描述为每个单独的实体,edge作为连接vertex的桥梁,描述为实体实体之间的关系,而property依附在vertex或edge上,为该实体或边上的属性。
Schema作为描述数据的元数据,在JanusGraph中包含有vertex label,edge label,property key三种类型。Vertex label描述的是vertex的语义,每个vertex可以选择添加不同的vertex label,就像是概念名称,用来区分不同的vertex;edge label用于描述edge的名称和多重性(Multiplicity),edge可以有MULTI,SIMPLE,MANY2ONE,ONE2MANY,ONE2ONE共5种Multiplicity,用于指定不同的关系类别;property key用来定义属性的类型和属性的名称,并绑定到vertex label或edge label上,property的类型有String,Boolean,Integer,Double等共12种,property的值可以是单值(SINGLE),列表(LIST),去重列表(SET)。Edgelabels和property keys本质上都是一种关系类型,在JanusGraph中都用relation type描述,因此要注意,edge labels和property keys不能重名。
举例如下,房产领域图谱所示,共有3个vertex label:地铁站,商圈,小区;2种edge label:邻近,相似;5种property key:经纬度,线路,城市,年代,别名,其中“别名”为SET列表,每个小区可以有多个别名。
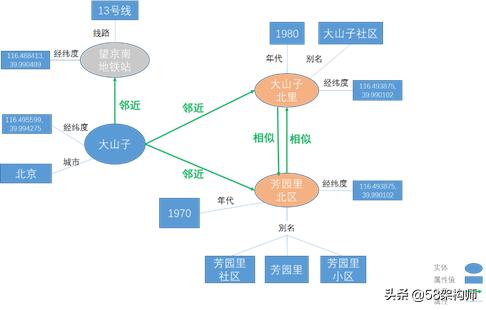
每个JanusGraph都有一个schema,该schema由JanusGraph显式或隐式创建,推荐用户采用显式定义的方式。JanusGraph的schema是可以在使用过程中修改的,而且不会导致服务宕机,也不会拖慢查询速度。
3. 图遍历语言Gremlin
与一般计算类似,图计算分为结构(structure)和过程(process)。图的structure是由vertex、edge、property拓扑定义的数据模型,图的process是分析结构的手段。图形处理的典型形式称为遍历(traversal)。TinkerPop在图形计算中的作用是为图形提供者和用户提供适当的API接口,使他们能够通过图形的结构和过程与图形交互,因此API主要分为两类,structure API和process API。一般来说,structure API是针对实现TinkerPop接口的图提供者的,而process API是针对使用图提供者的图系统的最终用户的。JanusGraph作为graph提供者,实现了TinkerPop结构和structure api,因此用户可以使用TinkerPop提供的process API来对JanusGraph中的图形进行交互。
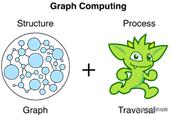
处理图的主要方法是通过图遍历(traversal)。TinkerPop process API的重点是允许用户以一种语法友好的方式创建图形traversal。traversal是根据图数据结构中显式的引用结构遍历图元素的算法。Gremlin就是Apache TinkerPop 框架下的traversal语言。
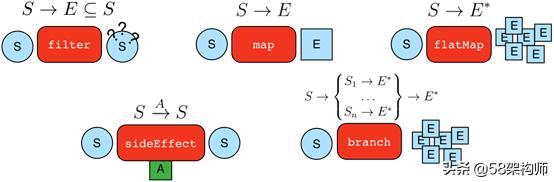
Gremlin是一种函数式数据流语言,可以使得用户使用简洁的方式表述复杂的属性图(propertygraph)的遍历或查询。每个Gremlin遍历由一系列步骤(可能存在嵌套)组成,每一步都在数据流(datastream)上执行一个原子操作。Gremlin主要包括五种通用类型的操作,filter,map,flatMap,sideEffect,branch,至于每种类型的step,在此不再展开讲述,有兴趣的话,可以从tinkerpop官网上进行学习了解。
4. JanusGraph使用方式
应用程序可以通过两种方式与JanusGraph交互:
- 嵌入方式。将JanusGraph嵌入到应用程序中, Gremlin查询、查询缓存和事务处理都发生在相同的JVM中,但是存储后端检索数据可以是本地的,也可以是远程链接。
- 连接JanusGraph Server。通过向服务器提交Gremlin查询,与本地或远程JanusGraph实例进行交互。
JanusGraph实践
以下围绕之前举例的房产领域图谱完成一个JanusGraph数据库的搭建。主要内容涉及JanusGraph部署,schema设计,数据导入,traversal查询。
1. JanusGraph Server部署
a. 采用JanusGraph Server方式,部署服务端的JanusGraph Server。从社区*载下**JanusGraph安装包(https://github.com/JanusGraph/janusgraph/releases),并解压到linux环境中。作为demo的演示,存储采用的是包中自带的Cassandra,索引也采用包中带的Elaticsearch,最大程度减少学习成本,直奔主题。
b. 进入bin目录下,可以看到各种启动脚本,JanusGraphServer的启动脚本为gremlin-server.sh,但是,在执行gremlin-server.sh脚本之前,要保证运行环境的正确性,例如,如果使用hbase作为底层存储,需要部署好hadoop和hbase,或者在远程服务器上部署。由于demo采用的是包内自带的存储和索引,因此采用janusgraph.sh来配置Cassandra和Elaticsearch。
c. 打开janusgraph.sh,可以看到内部在启动完Cassandra和Elaticsearch后,会执行gremlin-server.sh脚本,并且配置文件为conf/gremlin-server/gremlin-server.yaml,打开gremlin-server.yaml文件,找到graphs的定义,里面定义了每个graph的配置文件,注意,存储模块和索引模块的定义都在graph配置文件中。在此,使用默认的配置,不再修改。

d. 执行janusgraph.sh脚本,依次启动Cassandra、Elaticsearch、Janusgraph Server
2. 创建Schema
JanusGraph通过gremlin语句来创建Schema,可以在gremlin命令窗口执行,也可以嵌入到java中执行,原理其实一样,都是将gremlin语句发送到JanusGraph Server上,解析命令,执行并返回结果。不过需要注意的是,用java嵌入的方式,目前不支持直接使用java语句的方式来创建schema,需要通过org.apache.tinkerpop.gremlin.driver.Client类来将gremlin语句拼接为string的形式发送到server。创建房产领域图谱schema的命令如下:
a. 创建Property keys
JanusGraphManagement management= graph.openManagement(); PropertyKey pk1=management.makePropertyKey(“name”).dataType(“String.class”).cardinality(org.janusgraph.core.Cardinality.SINGLE).make(); PropertyKey pk2=management.makePropertyKey(“经纬度”).dataType(“String.class”).cardinality(org.janusgraph.core.Cardinality.SINGLE).make(); PropertyKey pk3=management.makePropertyKey(“线路”).dataType(“String.class”).cardinality(org.janusgraph.core.Cardinality.SINGLE).make(); PropertyKey pk4=management.makePropertyKey(“城市”).dataType(“String.class”).cardinality(org.janusgraph.core.Cardinality.SINGLE).make(); PropertyKey pk5=management.makePropertyKey(“年代”).dataType(“Integer.class”).cardinality(org.janusgraph.core.Cardinality.SINGLE).make(); PropertyKey pk6=management.makePropertyKey(“别名”).dataType(“String.class”).cardinality(org.janusgraph.core.Cardinality.SET).make();
b. 创建Vertex labels
VertexLabel vl1=management.makeVertexLabel(“地铁站”).make(); VertexLabel vl2=management.makeVertexLabel(“商圈”).make(); VertexLabel vl3=management.makeVertexLabel(“小区”).make();
c. 创建Edge labels
EdgeLabel el1=management.makeEdgeLabel(“邻近”).make(); EdgeLabel el2=management.makeEdgeLabel(“相似”).make();
d. 创建Vertex labels的Property keys
management.addProperties(vl1, pk1, pk2, pk3); management.addProperties(vl2, pk1, pk2, pk4); management.addProperties(vl3, pk1, pk2, pk5, pk6);
e. 创建Vertex labels和Edge labels的关系
management.addConnection(el1, vl2, vl1); management.addConnection(el1, vl2, vl3); management.addConnection(el2, vl3, vl3);
f. 提交事务
management.commit();
3. 数据导入
数据可以通过OneTimeBulkLoader或者IncrementBulkLoader的方式批量导入,不同的是,OneTimeBulkLoader为一次批量导入数据,不会保存源图中的数据,导入数据不会开启事务;IncrementBulkLoader为增量导入数据,基于源图中的数据,增加或者修改源图数据的值。当然数据也可以通过java嵌入方式,逐条进行插入,不同于创建schema,数据的导入和查询可以直接采用java语句方式执行,如下:
Vertex v1=graph.traversal().addV(“地铁站”).property(“name”,”望京南地铁站”).property(“线路”,”13号线”).property(“经纬度”,” 116.488413,39.990489”).next(); Vertex v2=graph.traversal().addV(“商圈”).property(“name”,”大山子”).property(“城市”,”北京”).property(“经纬度”,” 116.495599, 39.994275”).next(); Vertex v3=graph.traversal().addV(“小区”).property(“name”,”大山子北里”).property(“年代”,1980).property(“别名”,”大山子社区”).property(“经纬度”,”116.493875,39.990102”).next(); Vertex v4=graph.traversal().addV(“小区”).property(“name”,”芳园里北区”).property(“年代”,1970).property(“别名”,”芳园里社区”). property(“别名”,”芳园里”). property(“别名”,”芳园里小区”).property(“经纬度”,” 116.493875,39.990102”).next(); Edge e1=graph.traversal().V(v2).as(“in”).V(v1).addE(“邻近”).from(“in”).next(); Edge e2=graph.traversal().V(v2).as(“in”).V(v3).addE(“邻近”).from(“in”).next(); Edge e3=graph.traversal().V(v2).as(“in”).V(v4).addE(“邻近”).from(“in”).next(); Edge e4=graph.traversal().V(v3).as(“in”).V(v4).addE(“相似”).from(“in”).next(); Edge e5=graph.traversal().V(v4).as(“in”).V(v3).addE(“相似”).from(“in”).next();
4. Traversal遍历
Traversal遍历一般是从一个vertex或者edge入手,通过一系列有序的步骤,逐层逐步查询相关联的节点和边,并汇总遍历路径和遍历结果。Traversal有五种通用类型操作,如下表:

traversal还有一些终止步骤,如hasNext(),next(),toList(),toSet()等,除此之外,traversal还有功能强大的谓语步骤,如As,By,And等等,官网上都有详尽的介绍,可以查阅学习。
结语
本文简要的介绍了知识图谱和图数据库的关系,并根据应用场景引入了JanusGraph,对JanusGraph做了简单的介绍,并通过“房产领域图谱”例子来演示如何创建一个JanusGrap*图h**数据库,目的是抛砖引玉,带领大家进入图数据库的世界。当然,JanusGraph功能强大,Gremlin查询复杂多样,本文没有深入解析,后续会对专门针对JanusGraph的索引,存储,以及Gremlin的查询做详尽的调研分析,欢迎大家一起交流。
参考资料
JanusGraph社区文档:
https://docs.janusgraph.org/latest/index.html
TinkerPop官网文档:
http://tinkerpop.apache.org/docs/current/reference/#_tinkerpop_documentation
欢迎大家关注“58架构师”微信公众号,定期分享云计算、AI、区块链、大数据、搜索、推荐、存储、中间件、移动、前端、运维等方面的前沿技术和实践经验。