近些年,像英雄联盟、绝地求生、多塔2这样的在线多玩家游戏成为一种主流。
在这些游戏中,平衡是非常重要的,这里的平衡包括角色对角色、技能对技能的平衡。毕竟,如果一个角色可以完爆其他所有角色,其他的角色又有什么意义呢。
为了保证游戏的平衡,游戏测试者与开发者会不断地对游戏进行修正:
- 测试者试玩游戏
- 开发者根据反馈对游戏进行修正
- 步骤1和2反复重复,直到开发者与测试者均对游戏的平衡满意
这个过程往往是非常耗时的。与此同时,使用人力的测试可能是不完美的。随着游戏变得越来越复杂,角色越来越多,操作越来越多,使用人力的测试,可能无法发现游戏潜在的一些缺陷,也就是说,游戏可能无法达到真正的平衡。
为此,谷歌提出了一种基于机器学习的游戏测试方法,训练人工智能成为游戏玩家,体验游戏,并为游戏体验提供反馈。
这个方法被率先用在了游戏Chimera(译:合成兽)中,通过数以万计的游戏以及数据收集的过程,人工智能可以帮助游戏开发者高效地提高游戏的平衡性能,让游戏变得更加有趣。
Chimera游戏
游戏Chimera的本身,就极大地依赖于机器学习技术。比如,玩家可以随意合并两种生物,以生成合成兽,合成兽和合成兽之间也可以进一步合并。下图给出了很多可爱的合成兽们。

值得注意的是,在这样任意合并的设定下,合成兽的数量是非常巨大的。假设有100种基本生物,允许最多10个生物依次合并,那么最终可能的合成兽有17310309456440种!
这就意味着,开发者和测试者可能都不了解所有可能的合成兽的种类。当不同的合成兽被赋予不同的技能值,这对测试者来说简直是一种灾难。
同时,玩家可以对(由合成兽构成的)卡牌进行不同的操作,如放置在不同的板块、执行咒语等等,这样多样的操作更为测试者带来困难。

训练机器来玩游戏
对于这张几乎有无限多种可能的卡牌游戏Chimera来说,人类是无法测试的。
为此,我们可以借助机器的力量,使用卷积神经网络,来预测给定游戏状态下,不同玩家的胜率。
这个过程非常的直观且有效。最初,机器会被给予随机的游戏策略,之后,重新建立一个新的机器(智能体,agent),目的是打败前一个机器,并在游戏中反复的收集数据。这些新的数据会被用于训练另一个新的机器。
这个过程会不断反复。在这个过程中,数据的质量之间提升,机器也越来越会玩游戏。

横坐标:机器的版本,纵坐标:胜率
在这个过程中,如何表征游戏在某一时刻的状态?有至少两种方式。其一,游戏的数据,如多少个合成兽,这些合成兽是什么,有多少个板块等。其二,游戏的图像,即当前时刻游戏的画面是什么样的。
有趣的是,第二种方式,直接由游戏图像来表征游戏状态,会有更好的效果。这些图像会被输入到卷积神经网络当中,同时,这里卷积神经网络非常简单(即神经元少、层数少),这使得电脑可以实时处理,同时,可以实现神经网络的快速传输。
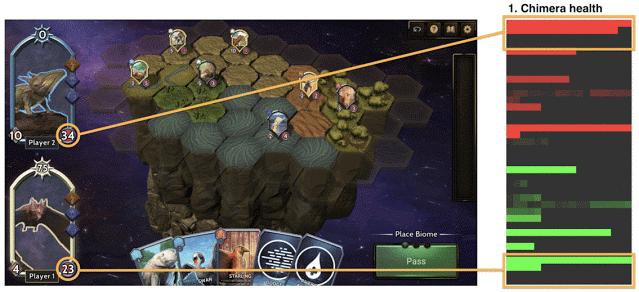
这个方法可以迅速地仿真百万次的游戏过程,通过那些最优秀的机器玩家的游戏数据,我们可以发现玩家*牌套**之间不平衡的地方。
比如,在Chimera测试过程中,游戏开发者发现了这些不平衡点:
- 进化合成兽永远是有利的,当一个玩家比另一个玩家进化了更多次合成兽,他非常有可能获得胜利。相应的胜率也可以被量化,由于测试的次数数以百万计,这其中几乎没有误差。
- 有些生物的能力过高,当这些生物被使用,玩家极有可能获胜。在人工智能测试员的帮助下,高的程度也可以被量化。
根据这些不平衡点,游戏开发可以进一步优化游戏体验。值得注意的是,像Chimera这样有数以百万计可能性的游戏来说,用人力找到上述不平衡点,几乎是不可能的。
参考文献:
- Ji Hun Kim and Richard Wu, “Leveraging Machine Learning for Game Development”, https://ai.googleblog.com/2021/03/leveraging-machine-learning-for-game.html,accessed on March 18, 2021.
- "Empowering game developers with Stadia R&D (Google Games Dev Summit)", https://www.youtube.com/watch?t=239&v=hMWjerCqRFA,accessed on March 18, 2021.
遗憾的是,暂时没找到游戏和算法的代码。
愿生活充满干货。一个认真科普的90后女博士,每周分享通信、计算机、网络及经济学最新最有趣的干货。喜欢的话,记得点赞、收藏和关注哟。欢迎留言及评论。