缓存是一个非常通用的概念,维基百科中的定义是 a store of things that will be required in the future, and can be retrieved rapidly ,缓存在前端页面、服务端、甚至CPU中都有各自的缓存。 本文主要介绍服务端中的缓存架构和应用,缓存是服务端开发中最常用的中间件之一。
为什么使用缓存
一、性能好、性价比高
数据库读写性能有限,写入qps达到一定量级(一般不到10w)就可能出现比较严重的主从延迟。 增加数据库的读性能一般通过增加从节点,但是数据库的机器CPU内存配置一般都要求比较高。 而redis、memcached等缓存单机能够提供几十万甚至百万级别的读写能力。
因此分布式缓存一般能够提供比数据库更高的读写性能,并且具备更高的性价比
二、延迟低、减少下游调用量
相比于数据库,缓存的读写处理速度往往更快。另外一些数据缓存起来可以减少处理的耗时,例如我们访问一个第三方的http接口来获取天气数据,则可以在接口外加一层缓存,一方面可以减少后面请求的延迟,另一方面可以降低http接口的调用量。 如果数据量比较小或者数据的热点分布非常明显,我们还可以使用进程内的本地缓存,进一步降低请求延迟。
三、 使用灵活、操作方便
数据库在使用时,需要提前定义表结构,要使用sql语句操作相关数据字段。而缓存kv操作比较灵活,并且redis中也提供了很多常用数据结构支持。
总结就是缓存使用灵活方便,在很多场景能够提供非常好的性能和延迟。
缓存相比数据库的劣势
一般没有事务能力(ACID),这也都是数据库的优势所在。
缓存如果命中率较低可能并不能起到很好的效果,反而可能带来系统额外的依赖、数据不一致问题
缓存常用术语
数据源: 要被缓存的数据,例如数据库中的数据、第三方的接口数据等 回源: 从数据源中加载数据并放到缓存中 Cache key: 缓存可以理解为一个Map结构,缓存中的数据就是一条一条的key到value的映射,一个key唯一确定了一条数据的查询参数。 Cache Hit: 命中缓存,如果从缓存中查询到了对应的key的值,则说明缓存中存在这个数据,这次查询命中了缓存 Cache Miss: 查询时没有命中缓存 Hit Ratio: 命中率,命中次数除以查询总数 Eviction(淘汰、逐出): 缓存的空间一般是有上限的,达到上限后就需要进行数据的淘汰、逐出,一般常用的是LRU等淘汰策略 Expiration: 过期,过期是一种保证数据一致性的方法,也可以把不访问冷数据淘汰出缓存。 热点数据: 访问次数最集中的一些数据
缓存分类
本地缓存(进程内) 分布式缓存
本地缓存
本地缓存中最常用的是LoadingCache,LoadingCache可以理解成一个ConcurrentHashMap,但是增加了几个功能
- 缓存淘汰,因为本地缓存在进程中,进程内存受限于服务器内存是有上限的,所以需要有内存淘汰策略避免内存占用过多导致gc问题甚至oom。
- 另外为了保持LoadingCache中的数据和数据源中的一致性(弱一致性),LoadingCache还有提供了过期、刷新机制
LoadingCache通常可以用 guava 或 caffeine
以guava为例,代码示例如下
创建LoadingCache
LoadingCache<String, String> loadingCache = CacheBuilder.newBuilder()
// 并发度,和JDK1.7的ConcurrentHashMap一样,guava的cache内部使用分段Segment加锁降低锁冲突
// gauva会使用最小的>=concurrencyLevel的值作为segment数组的数量
.concurrencyLevel(64)
// 最大保存的数量,超过后会逐出,注意这个是一个预估值,guava内部的逐出是以segment维度实现的,所以
// 可能出现Cache整体数量没超过这个值的情况下就出现了逐出
.maximumSize(1000)
// 如果某个key已经2秒没有访问(访问包括读取get、写入put、替换put或refresh等)则会从cache中删除
.expireAfterAccess(Duration.ofSeconds(2))
// 如果某个key距离创建或替换后已经超过10秒,则会从cache中删除
.expireAfterWrite(Duration.ofSeconds(10))
// 如果某个key距离创建或替换后已经超过5秒,则
.refreshAfterWrite(Duration.ofSeconds(5))
// 开启命中率等数据统计
.recordStats()
.build(new CacheLoader<>() {
@Override
public String load(String key) {
return doGetValue(key);
}
@Override
public ListenableFuture<String> reload(String key, String oldValue) {
// 一般线程池需要定制参数,这里仅做示例展示
return Futures.submit(() -> load(key), Executors.newCachedThreadPool());
}
/**
* 批量请求,在LoadingCache.getAll调用的时候会触发
*/
@Override
public Map<String, String> loadAll(Iterable<? extends String> keys) {
return Streams.stream(keys).map(this::load)
.collect(Collectors.toMap(Function.identity(), Function.identity(), (o, n) -> n));
}
});
使用LoadingCache,注意是使用get和getAll等方法
// 从loadingCache中获取"a"对应的值,如果没有或过期会触发load
loadingCache.get("a")
// 批量获取方法
loadingCache.getAll(ImmutableList.of("a", "b"));
LoadingCache的常见应用场景
- 存在热点的数据,例如某个用户的个人资料内容,用户可能会集中访问大V这样的少量热点用户的个人资料
- 某些不经常变化且数据量不大的数据,例如缓存新闻热榜数据
LoadingCache的一些其他变种
在一些情况下,我们的数据并不希望过期,而是在合适的时候刷新,虽然通过expireAfterWriter或refreshAfterWriter也能实现数据的刷新,但是这样的方式有一些缺点
因为我们难以判断数据什么时候会变化,所以过期/刷新时间配置太短会导致数据加载请求过于频繁,如果配置太长又可能导致数据更新不及时。
// TODO加一个图说明 所以我们需要一种在缓存数据源数据变化时主动更新Cache的机制。例如通过长连接通信,当数据源数据发生变化的时候,通过长连接通知到所有的缓存,调用refresh更新数据。
本地缓存的使用注意事项
- 各个机器实例缓存内容可能短时间内不一致(因为加载数据时间不同),导致接口数据一致变化
- 注意监控缓存大小、命中率、淘汰、加载数据失败等指标
- 缓存大小可以通过 sizeOf 等工具获取,避免影响GC。
- 如果命中率比较低,则可能说明热点不集中、过期参数、maximumSize参数不合适等问题。
分布式缓存
分布式缓存是指部署在其他机器上的缓存服务,并且通常能横向扩展来提高整体可以支持qps和内存容量,并且相比本地缓存也提供了更好的一致性(解决各个机器加载数据可能不一致的问题)。 常见的分布式缓存是redis, memcached以及其他的分布式缓存实现(包含自动扩缩容能力的新一代缓存)。
redis
redis 是一种很实用的缓存,内置了很多 数据结构 (string, sorted set等)
举一些redis各个数据结构可以实现的功能
redis string
string可以用来保存kv结构数据。应用例子: 保存一个文章的内容,key是文章id,value是文章内容,文章内容可以通过各种方式编码 另外string还能实现计数功能,并且有incr, decr等原子增减操作。应用例子:保存文章的阅读量、作者的粉丝数。 计数配合上过期时间还能实现限流功能,比如限制一个用户只能发帖10次,
redis sorted set
加一个图
zset(也称为sorted set)是一种有序的set,也就是每个key对应的是一个set,这个集合中每个Entry包含了一个member表示集合的元素的值,并且每个Entry也有一个score用来实现排序。
zset是非常常用的功能,因为列表是业务开发中最常出现的组件,有列表就有排序、去重、翻页等需求,这些需求zset都能满足
比如用户积分排行榜功能,把用户积分作为score,用户id作为member,就可以使用zset的ZREVRANGEBYSCORE命令获取积分的倒序排序列表。 再比如关注用户列表功能,一般会按照关注时间倒序展示自己的关注用户,把关注这个用户的数据库写入时产生的自增id(递增)作为score(为什么不使用时间戳呢,因为相同时间戳的数据有可能有很多,在翻页时会不方便,而id是唯一的不会有这个问题),把关注的用户id作为member,通过ZREVRANGEBYSCORE可以获取关注列表,通过 zscore 命令可以判断我是否关注了一个用户 再比如评论列表功能,评论一般也是按照时间倒序展示,则可以把评论的id(严格递增)作为score,评论id作为member。
redis hash
每个key对应的是一个hash(也就是map)结构,相当于两层映射。 可以实现存储一个用户的信息,hash的key作为用户的各个属性。
redis list,set
set保存无序集合,list保存插入顺序列表。 list保存可以实现队列功能,例如微信群红包,可以保存一个红包拆分的小红包到队列中,抢红包的操作就是pop操作,通过redis的原子性保证数据安全性。
hyperloglog,bloomfilter
hyperloglog用比较少的数据空间,保存一个集合的计数(可能丢失一定精度),例如文章阅读数,视频*放播**数,能够去重。 bloomfilter 提供的是判断是否在集合内的能力。
时间复杂度 score相同时翻页的问题 score的精度
Redis Client
Redis sdk一般使用 lettuce 或 jedis lettuce使用NIO(netty),jedis是bio链接模型需要使用连接池保证线程安全性,lettuce通过nio可以实现异步操作,在高并发场景下更建议用lettuce
Redis的注意事项
Redis6.0之前的版本的Redis使用一个主线程负责连接管理、socket io读写、数据解析、请求命令处理,在QPS非常高时,io读写可能成为瓶颈,导致CPU单核打满。
所以使用Redis时要注意
- 注意请求热点,即使部署了Redis集群,如果某些key存在明显热点,可能导致请求不均,导致个别Redis实例CPU打满,影响同实例上的其他请求
- 注意操作的时间复杂度、注意数据大小,很多操作的时间复杂度不是O(1)的,比如ZREVRANGEBYSCORE是O(log(N)+M),ZADD是O(log(N)),那么当数据量变大时,对CPU的开销就会更大,因此要注意控制缓存中数据的数量,比如zset保存最近1w个,超过1w个之后的查询降级到数据库查询。
- 在能批量操作时尽量使用批量操作,但是注意批量大小也不要太大。使用redis pipeline机制或者lettuce的异步非阻塞io都能提高客户端调用整体的吞吐率(不用等待前面的操作完成再执行后面的操作,有数据依赖的比如获取前面get的值作为下次调用的参数的除外)。
Redis的高可用
分布式系统需要考虑高可用,高可用是当机器故障时,如何保证服务的可用性、数据的可用性,Redis的一种高可用架构如下
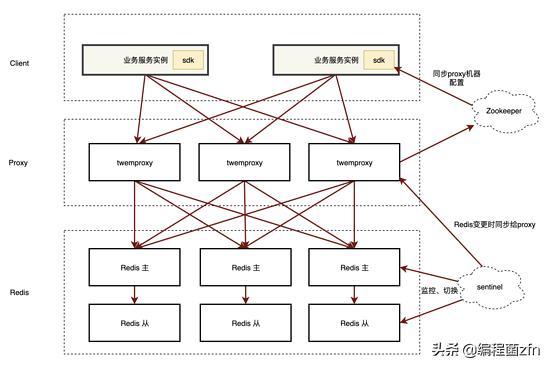
- 调用客户端内通过zk封装集群到redis proxy的列表的数据,有变化时触发客户端链接变化,proxy故障切换或扩缩容时不再需要修改客户端配置重启。
- twemproxy 是中间的代理层, twemproxy的作用一是减少到Redis实例的连接数,当Redis连接数过多时,Redis在处理链接上消耗过多CPU会导致性能下降,并且twemproxy通过pipelining提升整体的吞吐量,另外一个作用是提供Parition功能,twemproxy通过一致性hash等hash方法提供集群功能,对于客户端屏蔽掉多个Redis的路由规则等细节。
- Redis实例层通过 redis sentinel 实现故障切换,切换后会同步到proxy层更新twemproxy配置。
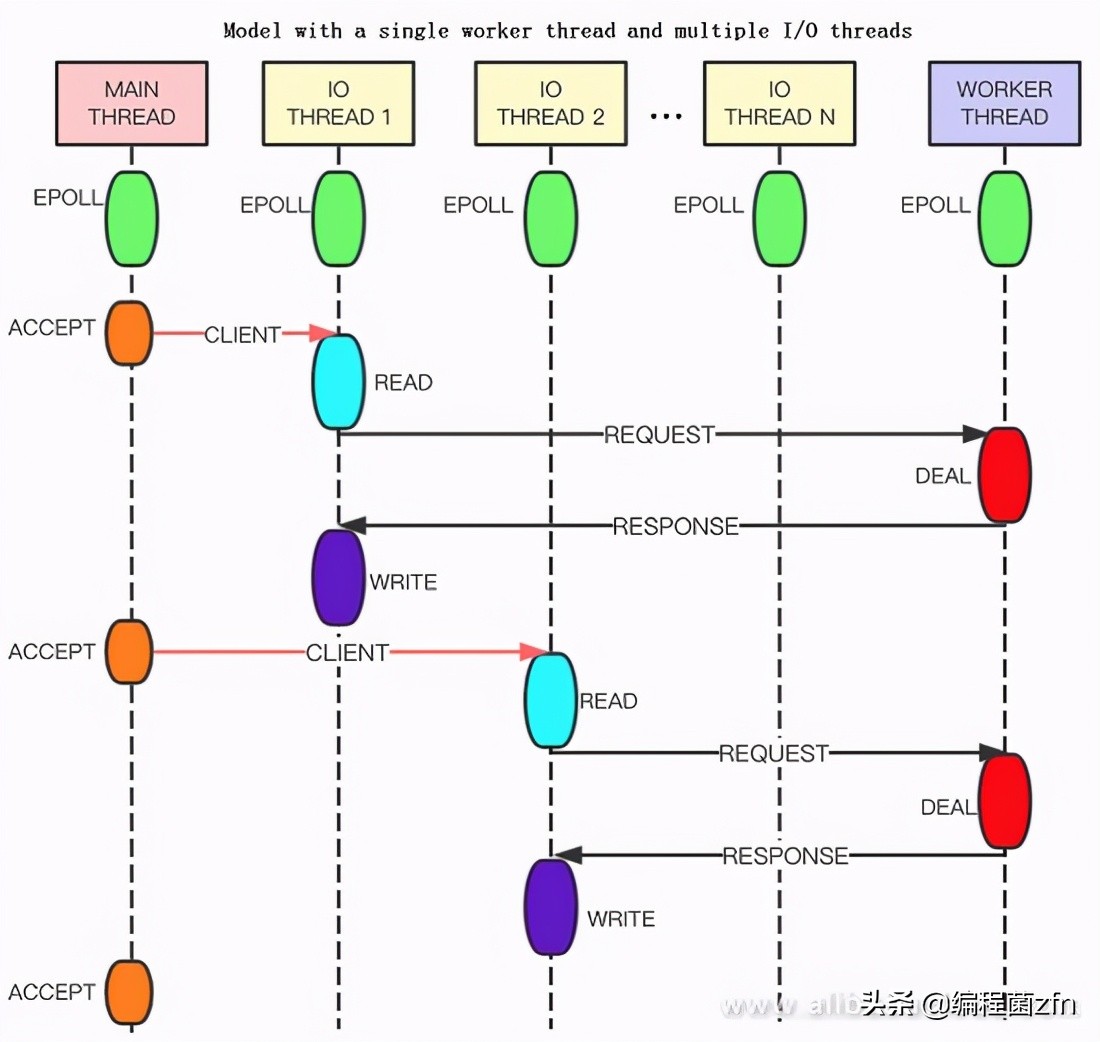
Redis多线程
Redis 6.0提供了IO多线程支持,把IO读写分配到N个单独的IO线程中处理,在一定程度上提升了Redis的QPS。
Memcached
Memcached的使用
Memcached是另一个高性能的多线程缓存服务,提供了kv、cas等功能。
那么什么情况下使用Redis、什么情况下使用Memcached呢?
Memcached的客户端一般使用spymemcache,也通过zk控制memcached服务连接配置。目前我们使用的是spymemcached客户端的一致性hash,当然也可以使用 tewmproxy做partition。
Memcached的高可用
memcached因为没有Redis的aof复制机制,所以集群不具备副本功能,在机器宕机后,便无法对外提供服务,qps非常大的情况下可能出现缓存穿透(即使有一致性hash)导致db回源压力变大。 因此目前一种memcached的高可用方式是客户端维护多副本数据,在部署memcached集群时,部署相同的两套服务,在写入缓存时,同时写到两个集群中,读取时,随机从其中一个读取,没有再读取另一个集群,如果可以主动同步数据到另一个集群(可选,可能导致数据不一致问题)

Redis和Memcache的选择
如果有特别高的热点qps或者整体qps非常大的场景,建议使用memcached,一方面是因为memcached多线程能够支持更高的热点请求,在整体qps比较大的情况下,memcached相比Redis具备更高的性价比。 在其他情况下,比如qps不高或者要利用zset这样的数据结构,使用Redis更方便。
缓存一致性
缓存一致性的保证是一个经常遇到的问题,因为我们把数据储存在了数据源和缓存两个地方,并且数据也可能会变的,保证它们的一致性就需要一定的技巧了。
涉及缓存一致性的解决方案,关键在于缓存什么时候由谁负责写入和删除,缓存和数据源产品不一致的主要原因是因为出现了多个修改缓存的调用点,导致出现并发问题。
Cache aside模式的问题
// read value
v = cache.get(k)
if (v == null) {
v = sor.get(k)
cache.put(k, v)
}
// write value
v = newV
sor.put(k, v)
cache.put(k, v)
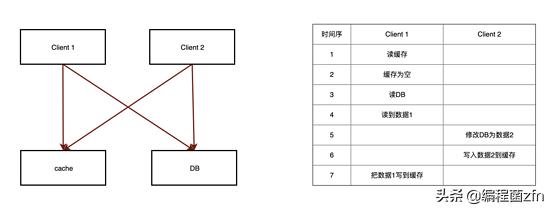
cache aside模式下由于存在多个写入缓存的调用点,所以可能出现并发时序问题导致的缓存新数据被旧数据覆盖的情况,一种可能的问题如下图所示,展示的是一种可能导致缓存不一致的调用时序。
cache aside模式适用于对数据一致性要求不高的场景,这种使用方式也最为简单。
Read through
Read through模式对外封装了缓存的一致性同步过程,对外提供的是统一的缓存读取接口,调用方不用关心如何从数据源回源数据写入缓存这样的底层逻辑。
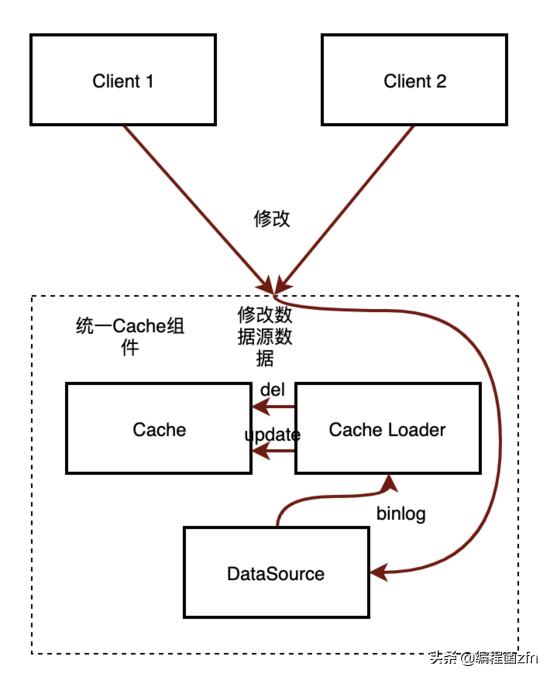
在Read through模式中,有一个额外的Cache Loader角色,当从缓存查询不到数据时,会调用Cache Loader来负责加载数据到缓存中,Cache Loader会通过加锁等方式 保证每个key的并发请求的数据读取和缓存写入的顺序性保证。Cache Loader会从数据库中读取数据然后写入到缓存中。例如可以把Cache Loader实现成一个RPC服务,通过一致性Hash或定制化的路由规则保证同一个key的请求都请求到一个RPC server进程内,然后在进程内通过加锁等并发控制保证相同key的数据加载缓存写入不出现并发时序问题。

上面流程中展示了缓存的加载流程,那么缓存是如何更新的呢?
缓存更新的触发原因是数据库产生了变更,数据库变更时会产生binlog,我们通过消费binlog来进行缓存的删除或更新即可。
如果在binlog消费中删除、更新同样也要调用Cache Loader来保证更高的一致性,在Cache Loader中去协调一个缓存key的并发操作。
如果一致性不是特别高,可以在binlog中直接调用缓存删除或缓存更新,缓存删除后下次读取由Cache Loader加载到缓存中。 对于删除缓存这种处理模式,要小心一些隐含的数据不一致的出现情况,比如消费的主库的binlog时,主从延迟,Cache Loader读取从库则可能读到旧数据。 另外由于mysql binlog发送是在事务commit前一步发生的,所以即使Cache Loader读取主库仍然存在一定的概率读到旧数据。如果要解决这个极端case,可以考虑延迟几秒消费binlog数据,等待事务commit完成。 另外如果内存比较大还可以搭配数据轮刷任务定期把数据库中的数据全部刷到缓存中再做一次一致性保证。 如果是在binlog消费中去更新数据,要注意mysql binlog的消费线程也要注意保证有序消费,可以通过创建一个线程数组,然后把处理的数据的key hash之后映射到数组上,保证同一个key的多个mysql binlog事件处理是串行的。
分布式缓存 codis tidis titan tair
sdk client配置
多机房架构
缓存一致性问题
https://www.ehcache.org/documentation/3.8/writers.html
缓存回源服务、binlog清理/设置缓存
先修改数据库,再修改缓存 先修改数据库,再删除缓存 修改数据库,由binlog触发缓存删除 修改数据库,由binlog修改数据
顺序消费,同一个数据的修改,保证顺序性,比如创建一个线程数组,用id hash来选择线程执行任务。
常见缓存应用、架构模式
缓存跨机房同步
有些企业会有异地多活需求,比如有A、B两个机房,一个数据库的主库会在其中一个机房,然后通过binlog同步到另一个机房,那么在每个机房部署一套CacheLoader和binlog服务以及相同的缓存集群,就能够实现跨机房的数据同步。
除了binlog方式的数据同步,还可以通过客户端sdk双写的方式实现,比如sdk内双写两个机房的数据,或者把数据修改命令封装成kafka发送到另一个机房消费。
多级缓存
虽然分布式缓存相比数据源已经够快也能支持更高的qps操作,但是分布式缓存也有网络开销、也有cpu瓶颈,所以在一些热点数据的访问中还可以添加本地缓存进一步降低分布式缓存的请求量,并且可以解决一些热点问题。
缓存在常见业务场景中的应用模式
在Redis数据结构中我们提到了一些数据结构的应用场景,下面我们以一个典型的app场景介绍一下缓存的设计和使用。
假设我们现在在仿照开发一款知乎这样的app软件,一款app中会有很多功能,我们选取一些典型的缓存应用场景来介绍。 功能不一定完全一样,可能和知乎略有变化
发回答、查看回答(阈值计数服务、hyperloglog、本地缓存)
用户可以在一个问题下面发布自己的回答,为了防止我们的新app被不法分子攻击,例如通过调用接口频繁发表回答,我们需要限制每个用户每天能够发表的回答上限,比如每个用户每天只能发布100个回答。
实现每天100个回答的限制功能:
我们利用incr和expire实现时间段的,incr会返回加之后的结果,当结果<=100时,说明用户发布次数没有超过上限,否则超过了上限返回回答次数太多异常。 在执行incr后,通过ttl查询一下是否有设置过expire,如果返回-1,则通过expire设置一下过期时间,因为是自然日的限制次数所以expire参数为当前时间到24点之间的秒数。
问答内容通过redis的string保存,或者保存到memcached中
避免并发回答请求,为了防止用户快速点击发布回答导致发出两个请求发出了两个相同的回答请求,或者因为我们的写入回答流程中有一些不能让用户维度的请求并发的逻辑,比如回答次数限制逻辑,我们再对发布回答流程加一个用户维度锁,避免并发写回答,可以通过redis实现简单的分布式锁,这里通过setnx 以及过期时间即可实现。
实现回答阅读数功能 每个回答要统计自己的阅读数,同一个用户多次查看一个回答是不做重复计数的,为了判断用户有没有看过一个回答而添加一个查看回答记录表是稍微比较麻烦的,而通过hyperloglog就很简单了,每个回答维护一个hyperloglog,用户阅读时,通过PFADD命令添加userId,PFCOUNT查看回答的阅读数
解决回答查看热点问题
我们的app内大V的回答阅读的qps可能会非常大,假如使用的是redis,可能导致redis出现热点问题,我们通过在调用服务中添加一层LoadingCache本地缓存,解决回答Redis缓存的热点问题。
粉丝关注、信息流关注页
app里用户之间可以互相关注,然后在app的关注页就可以看到关注的人的回答动态了。 关注之后,用户能在关注列表中找到刚刚关注的人,被关注的用户也能查看自己的粉丝列表,由于数据可能比较多所以需要翻页。
关注粉丝我们可以把关注列表数据和粉丝列表数据保存到数据库中,同时通过binlog消费删除更新以及Cache Loader等方式同步到Redis 缓存中, Redis使用zset数据结构,key是当前用户id,member为关注的人的用户id(关注缓存)或粉丝id(粉丝缓存),
在查看一个回答时,会展示我们和这个回答作者的关系,比如如果我关注了这个用户,会显示已关注,否则未关注,怎么判断有没有关注过一个用户呢,通过关注列表缓存zset的ZSCORE命令即可判断。
由于粉丝可能数量非常多比如几百万几千万,所以不能全部放在zset中,当粉丝超过一定值时(比如1w),我们把尾部的数据进行截断。 查看粉丝列表翻页翻到1w之后的请求量非常少,这些请求由数据库来处理也能应对。
回答评论、评论数
用户可以在问题回答下面进行评论,评论按照时间倒序排序,并且回答中会展示评论数量。 首先我们使用一个Redis zset来保存一个回答下的评论id列表,member是评论id,score也是评论id(id递增)。 评论的翻页通过zset的ZREVRANGEBYSCORE命令实现,同样id列表也和粉丝列表一样保存最近的1w个id。 有了评论id我们还需要评论内容,评论内容通过redis 的string数据结构或memcached kv来存储。 评论计数通过redis的string incr或memcache cas计数来实现。
问题每日热榜(排行榜、高性能计数器)
热度值实现
我们把问题的热度定义为问题下今天创建的所有回答的每天的点赞数阅读数的总和
我们实现一个高并发的计数服务来统计每天的新增热度值。计数服务需要实现计数增加和查询计数的功能。 数据服务的数据分为几部分,首先数据库中保存每个回答的热度值(热度值存储为bigint字段), 然后我们把热度值变化同步到Redis缓存中,缓存回源使用Cache Loader。 因为部分热点数据的热度值变化是非常频繁的,因此可能对数据库缓存的压力都比较大,因此我们采取批量汇总的优化方法, 计数增加通过kafka发送给kafka消费者统一写入数据库,在kafka消费者总,把计数先在内存中汇总,比如放到一个Map<Long, LongAdder>中,key为 问题id,value为热度值,然后在用一个ScheduledThreadPoolExecutor定期获取map总的数据并对LongAdder进行重置(sumThenReset),然后批量写入都数据库中。数据库的操作为insert into hot_count (id, day, count) values (:id, :day, :count) on duplicate key update count = count + :count; 这个sql在并发较高时会有不少的锁冲突,如何优化可以留作思考题。 更新count后,binlog接收到count变化,更新缓存。缓存我们通过redis string或memcached保存,因为已经通过写入db时的批量缓冲减少了qps,所以缓存的热点写入压力不会很大,整体qps可以通过横向扩容提升。 如果没有先写数据库而是直接写缓存,除了批量之外,还有一种解决热点的方案是shard,也就是把一个热点的计数分散到N个key上,这样N个key就可以分散到多个缓存实例,读取的时候再把这N个实例都读取出来加和,类似LongAdder中的shard思想。
热榜实现
有了热力值的数据统计之后,我们就要实现问题热力榜的功能了。 热力榜是一段时间内热力值最大的N(比如50)个问题的列表。 我们维护一个每天的热力值的数据,使用Redis zset数据结构,每天对应一个redis key,key为”yyyyMMdd”,member是问题id,score是热度值。 当zset长度超过一定值时,我们进行截断,截断时进行一定的冗余,例如我们希望zset保存最大的100个数据,则在zset达到200时我们才截断,删除第100到200之间的数据,可以避免频繁的截断。 如果我们要获得今天的热力榜,就可以通过把今天的key对应的zset通过ZREVRANGEBYSCORE来获取最热的问题。因为热榜的访问量非常高且对数据的总量不大、实时性要求不高,所以我们对热帮忙整体加一个本地缓存。
高并发、高可用缓存模式总结
- shard: redis或memcached的partition分片提升整体qps和内存,当有热点的时候,可以考虑在key维度继续shard减少热点。
- 多副本: memcached没有复制所以以来多副本双写保证高可用,多副本也提升了整体的读性能。
- 批量: 批量在很多情况下能够提升吞吐
- 多级缓存: 利用本地缓存和分布式缓存的结合能够解决很多热点问题
- 打散、预热: 一些秒杀场景可以通过适当的时间分散让用户请求来打散;有些情况下需要考虑缓存数据的预热
- 常见通用策略: 限流、降级、熔断、隔离,做好监控报警